Using YugabyteDB with Hasura to scale your GraphQL API globally
Software Architect & consultant
Web / Mobile / VR / AR / IoT / AI
GDE, author, engineer
CTO & Co-founder
creating a robust, performant, and feature-rich online conferencing experience
Microservices architecture
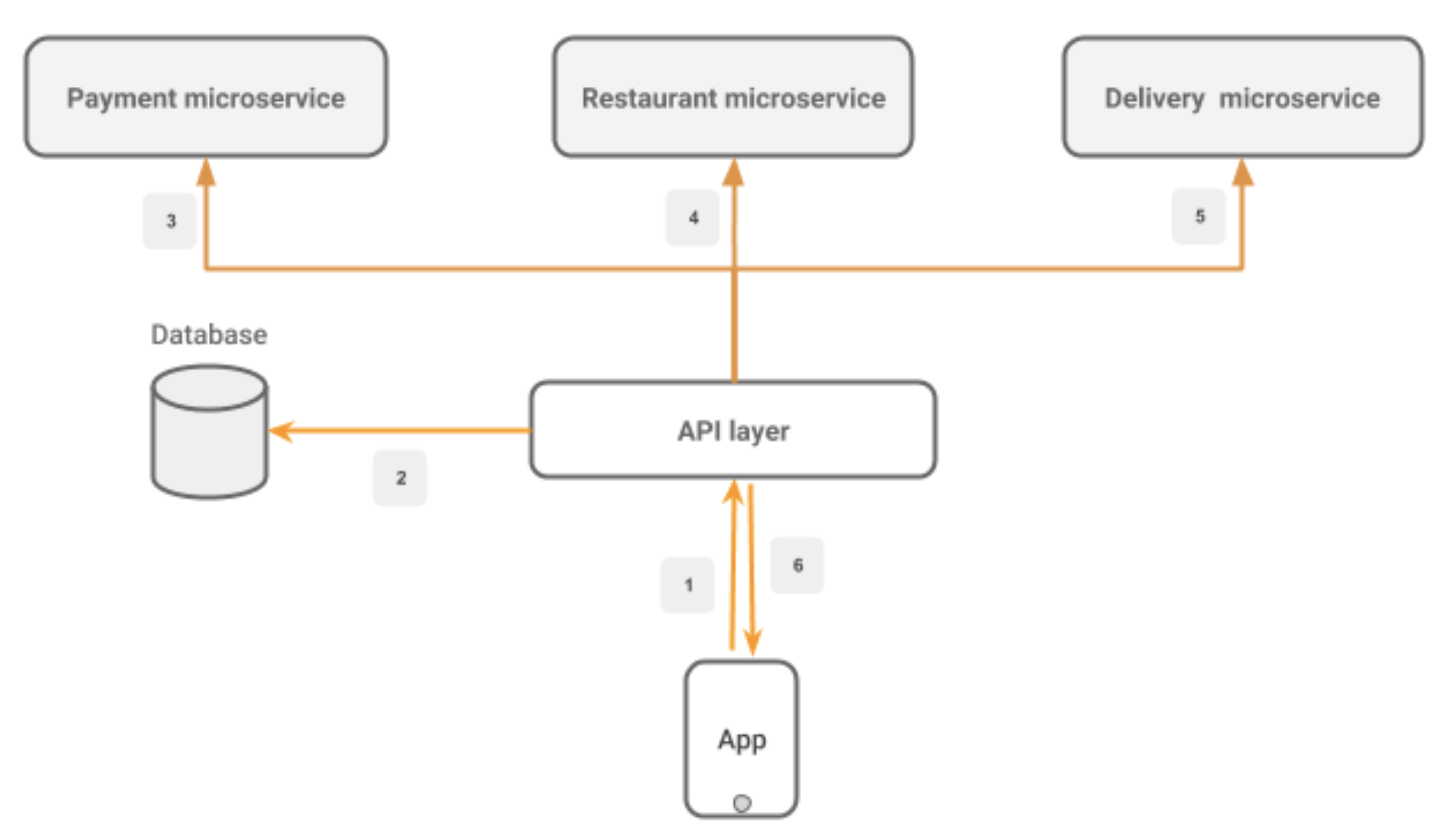
3factor.app Architecture

GraphQL
A query language for your API

What is Hasura
open source and free engine that gives you auto-generated real-time GraphQL API on top of new or existing Postgres database
Features
- Can be deployed to any cloud or run locally
- Compatible with all Authentication solutions
- Can run on top of new or existing Postgres database
- Supports Postgres addons (PostGIS, TimescaleDB)
- Auto-generates GraphQL api
- GraphQL queries are compiled to performant SQL statements using native Postgres features
Features
- Comes with hasura-cli which has awesome tools like migrations and more
- Can work with custom SQL statements
- Has configurable access controls for data
- Can be connected to your own GraphQL server (does schema stitching)
- Has eventing system which enables to trigger serverless functions
Let's see it in action
we will run Hasura locally

What about scaling
What about some numbers?
| Single instance configuration | No. of active live queries | CPU load average |
|---|---|---|
| 1xCPU, 2GB RAM | 5000 | 60% |
| 2xCPU, 4GB RAM | 10000 | 73% |
| 4xCPU, 8GB RAM | 20000 | 90% |
Postgres is under about 28% load with peak number of connections being around 850


What is YugabyteDB

open-source, high-performance distributed SQL database for powering global, internet-scale applications.
What is YugabyteDB
Built using combination of
- high performance document store
- per-shard distributed consensus replication
- multi-shard ACID transactions (inspired by Google Spanner)
cloud-native database!
- public/private clouds
- Kubernetes environments
What is YugabyteDB
What it brings:
- PostgreSQL-compatible SQL API
- low-latency read performance
- globally distributed write scalability
Let's see it in action:
I will use local Mac install

./bin/yb-ctl create --rf 3 --tserver_flags "ysql_suppress_unsupported_error=true"Create Yugabyte cluster
Cluster Admin UI (localhost:7000)

Run Hasura on top of YugabyteDB
docker run -d -p 8080:8080 -e \
HASURA_GRAPHQL_DATABASE_URL=postgres://postgres:@host.docker.internal:5433/yugabyte \
-e HASURA_GRAPHQL_ENABLE_CONSOLE=true hasura/graphql-engine:latestNote that port number is 5433
Now let's access Hasura console and see it in action
Run Hasura on top of YugabyteDB
docker run -d -p 8080:8080 -e \
HASURA_GRAPHQL_DATABASE_URL=postgres://postgres:@host.docker.internal:5433/yugabyte \
-e HASURA_GRAPHQL_ENABLE_CONSOLE=true hasura/graphql-engine:latestNote that port number is 5433
Now let's access Hasura console and see it in action
Let's simulate downtime
./bin/yb-ctl stop_node 2subscriptions will keep running and everything will work as expected
./bin/yb-ctl stop_node 32 failed nodes with Replication factor 3


Replication factor is 3 so one infrastructure failure is fine
failures that it can tolerate are:
- disk
- network
- availability zone
- cloud region/datacenter
- entire cloud
Why one failure is fine, but two are not?
Takeaways
Hasura auto-generate GraphQL API for you
YugabyteDB takes care of high availability of your DB
YugabyteDB global distribution brings the data close to users for multi-region and multi-cloud deployments
Hasura and YugabyteDB are open-source
Start using it today!
Thank You
@VladimirNovick
consulting/remote workshops/mentoring
Event Loop