Ambient Diffusion Update
Jan 21, 2026
Adam Wei
Agenda
1. Book keeping items
2. Real-world results
3. Motion planning experiments
4. Conditioning and ambient in the multi-task setting
Book-keeping Items
- Planned to submit RSS... bailed on deadline
- Goal is to arxiv by end of Feb, submit to Corl in Apr/May
Distribution Shifts in Robot Data
- Sim2real gaps
- Noisy/low-quality teleop
- Task-level mismatch
- Changes in low-level controller
- Embodiment gap
- Camera models, poses, etc
- Different environment, objects, etc
robot teleop
simulation


Open-X

Immediate Next Direction
- Sim2real gaps
- Noisy/low-quality teleop
- Task-level mismatch
- Changes in low-level controller
- Embodiment gap
- Camera models, poses, etc
- Different environment, objects, etc
Open-X
Immediate Next Direction
Open-X
Variant of Ambient Omni
Cool Task!!
Cool Demo!!
Open-X Embodiment
Open-X
Magic Soup++: 27 Datasets
Custom OXE: 48 Datasets
- 1.4M episodes
- 55M "datagrams"
Table Cleaning
Ambient policy on OOD objects. (2x speed)
Table Cleaning: Evaluation


Task completion =
0.1 x [opened drawer]
+ 0.8 x [# obj. cleaned / # obj.]
+ 0.1 x [closed drawer]
Question: How to compute error bars?
\(\sigma=0\)
\(\sigma=1\)
"Clean" Data
Clean Only
Co-train
\(\sigma=0\)
\(\sigma=1\)
"Corrupt" Data
"Clean" Data
... with some mixing ratio \(\alpha\)
Ambient
\(\sigma=0\)
\(\sigma=1\)
\(\sigma_{min}\)
\(\sigma > \sigma_{min}\)
"Clean" Data
"Ambient"
Locality
\(\sigma=0\)
\(\sigma=1\)
\(\sigma_{max}\)
\(\sigma \leq \sigma_{max}\)
"Clean" Data
"Locality"
Ambient + Locality
\(\sigma=0\)
\(\sigma=1\)
\(\sigma_{max}\)
\(\sigma \leq \sigma_{max}\)
"Clean" Data
"Locality"
\(\sigma > \sigma_{min}\)
"Ambient"
\(\sigma_{min}\)
Ambient [OLD SLIDE]
Even the best policy right now is mediocre...
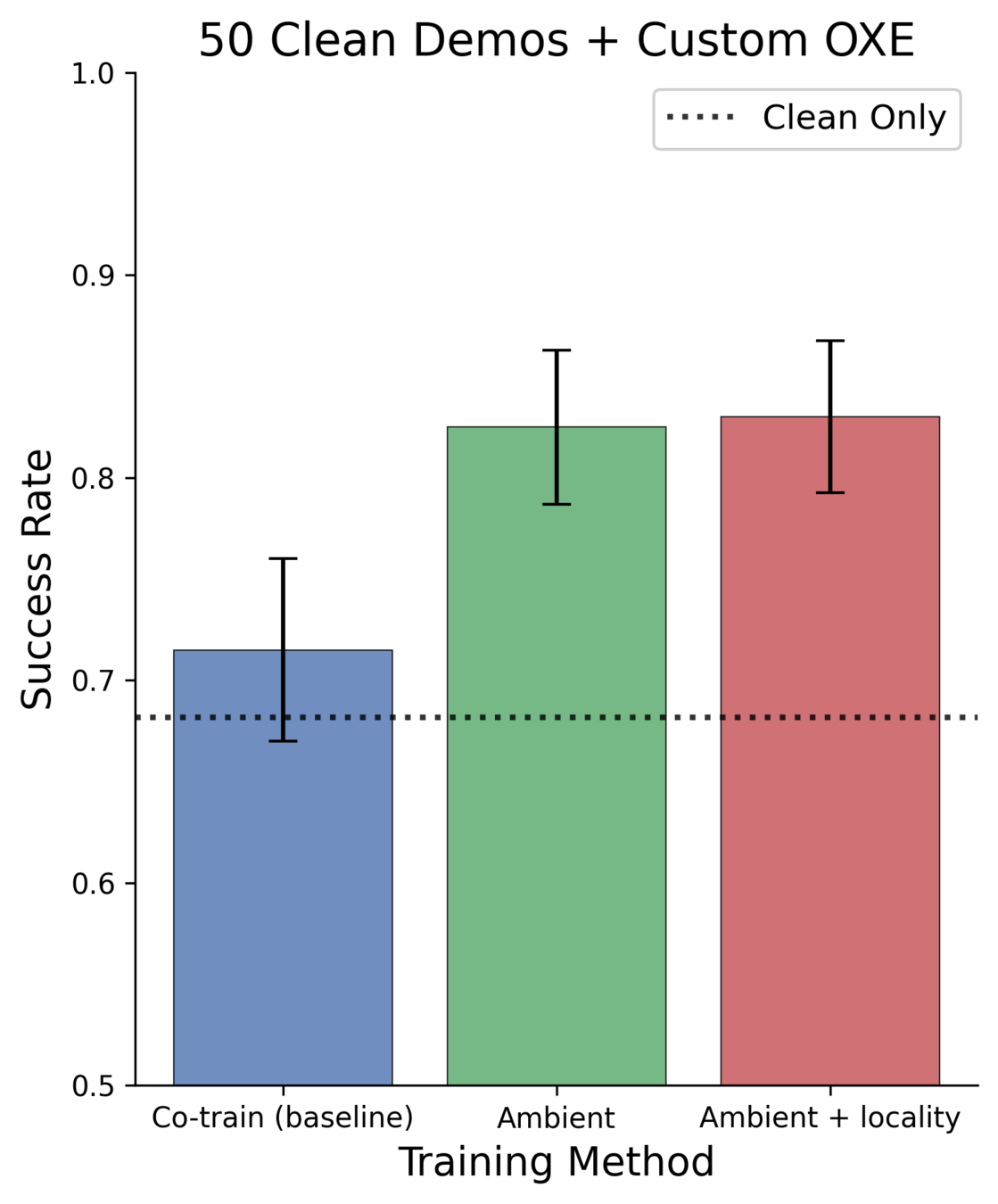
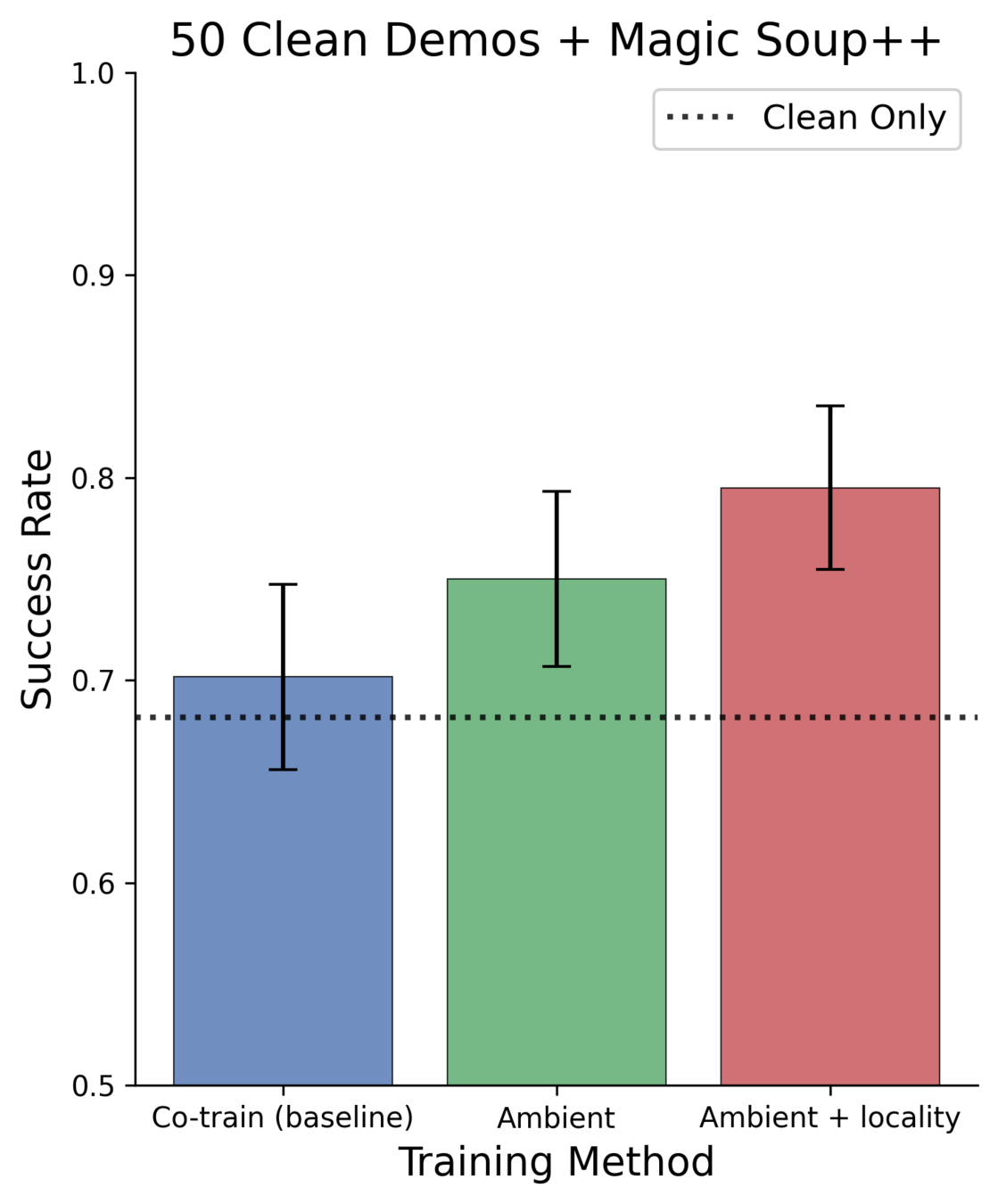
Results: 50 Clean Demos
Results: 150 Clean Demos
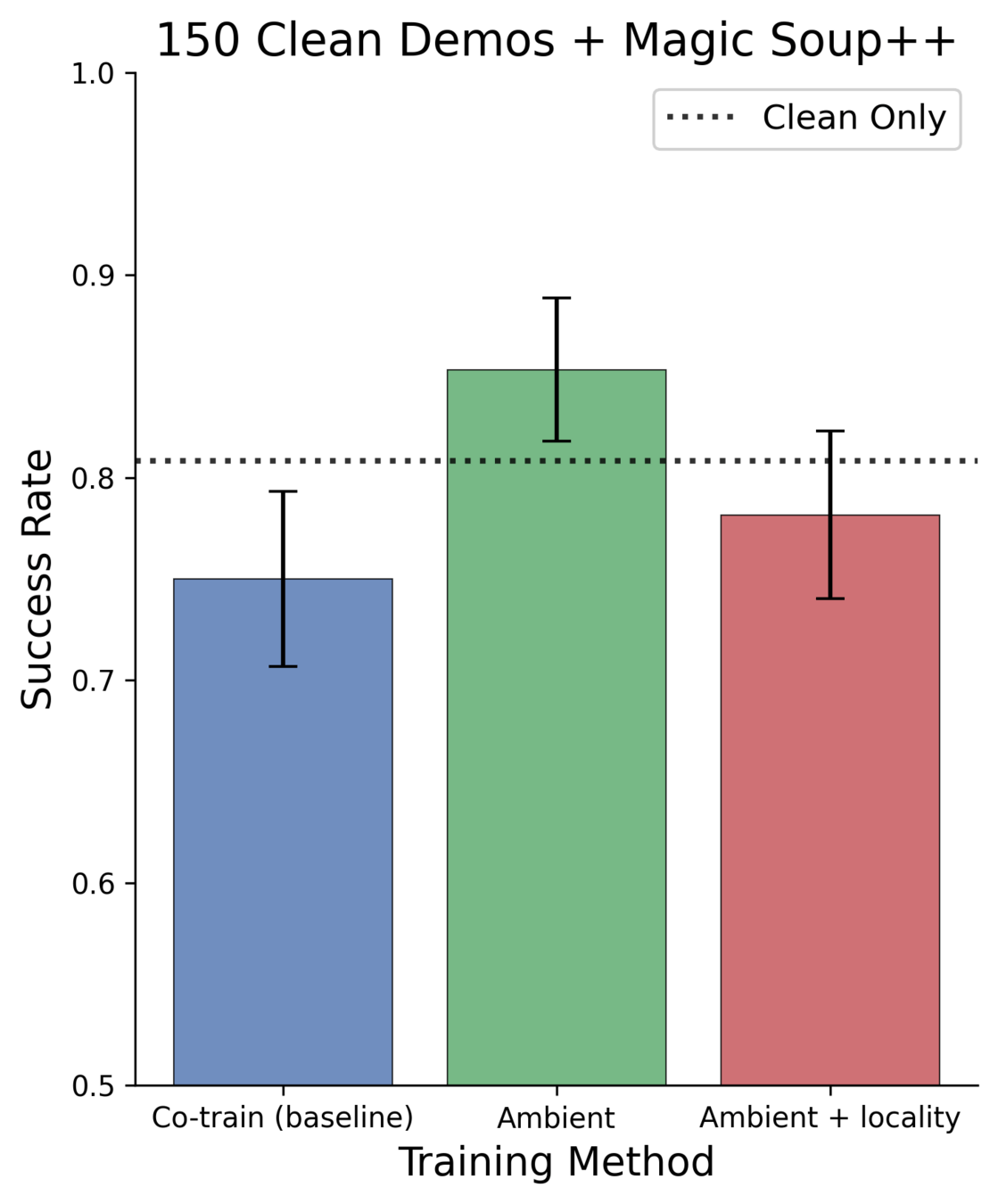
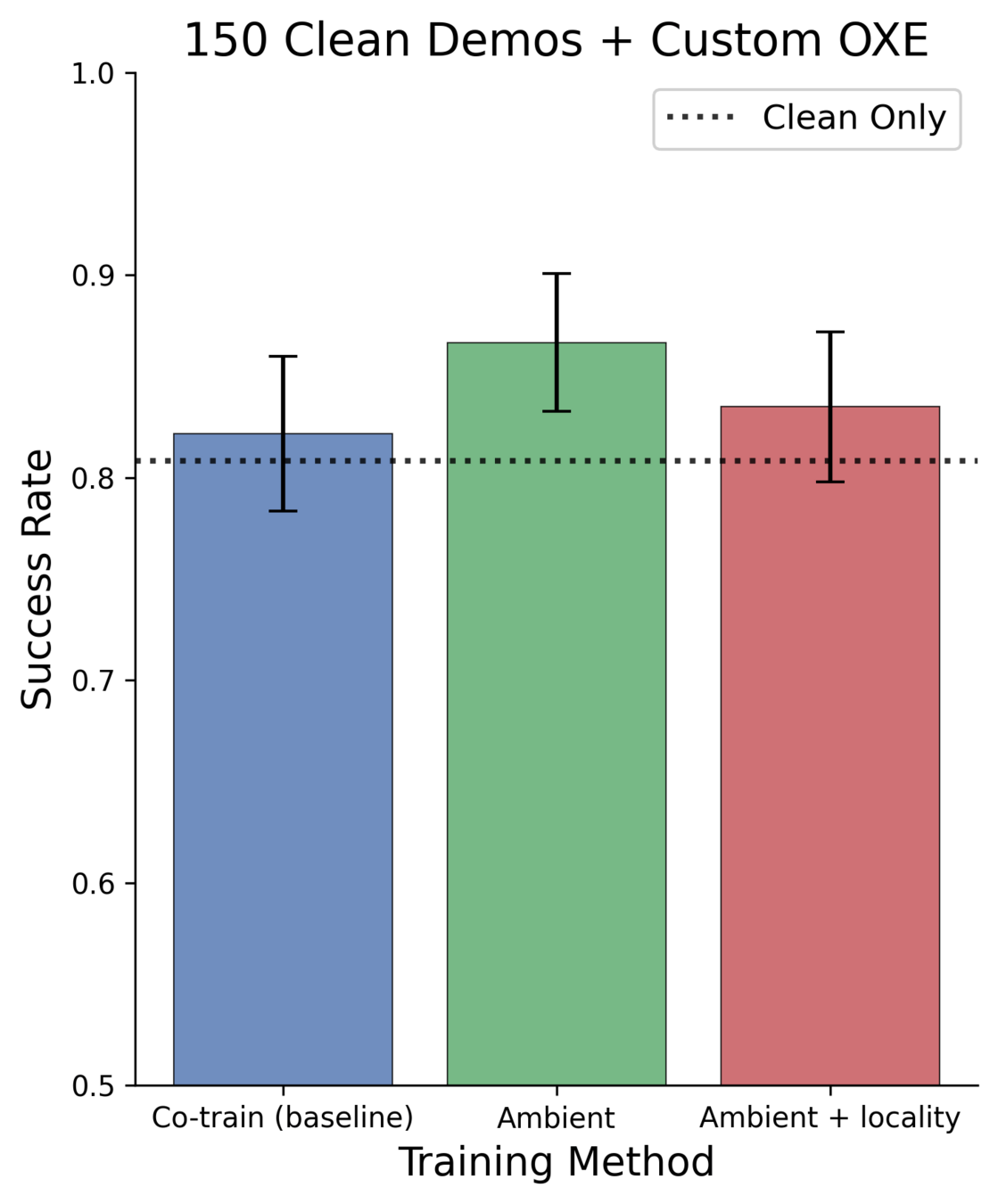
Results: 150 Clean Demos
Best 50 demo policy: 83.0%
150 clean demos: 80.8%
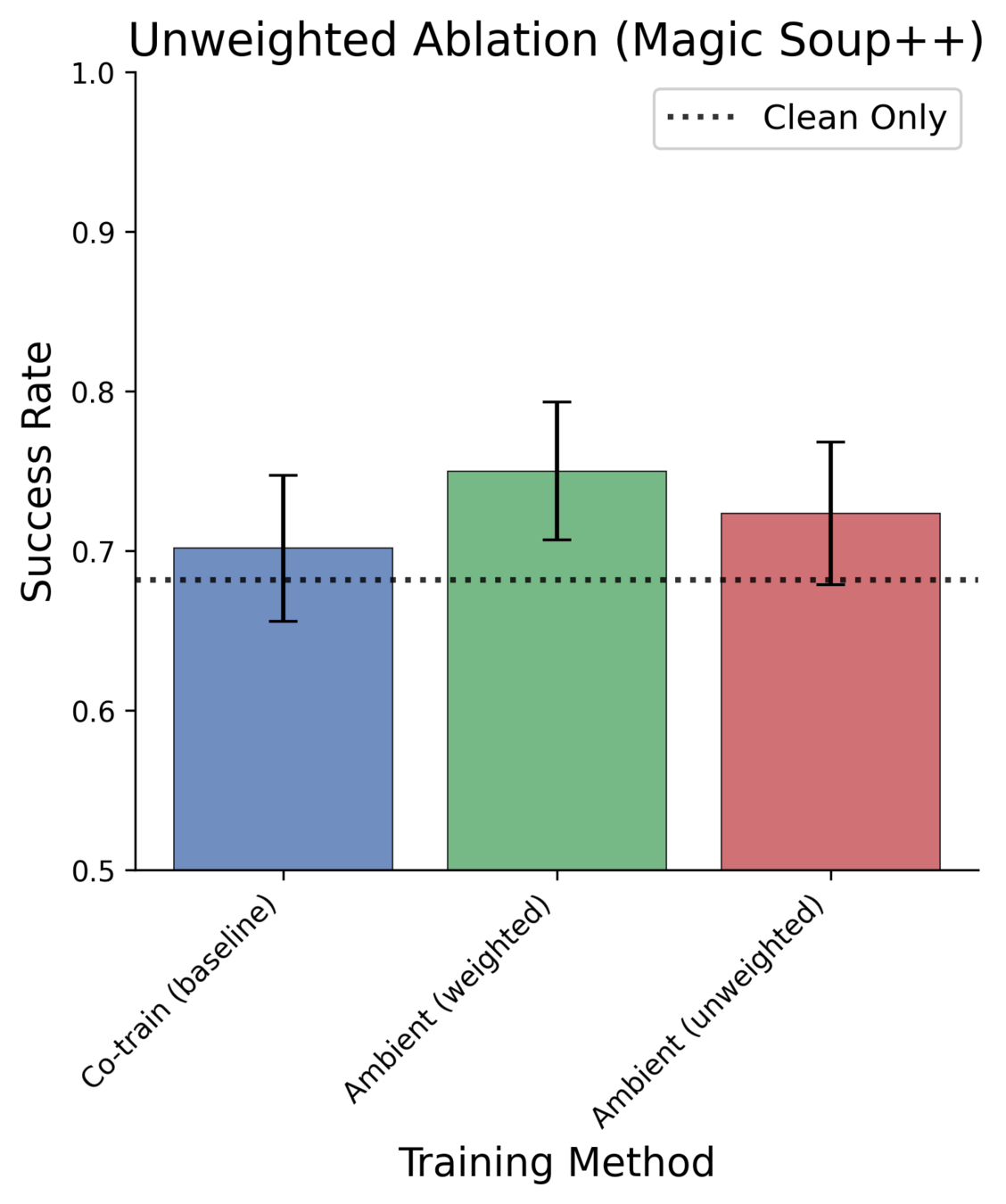
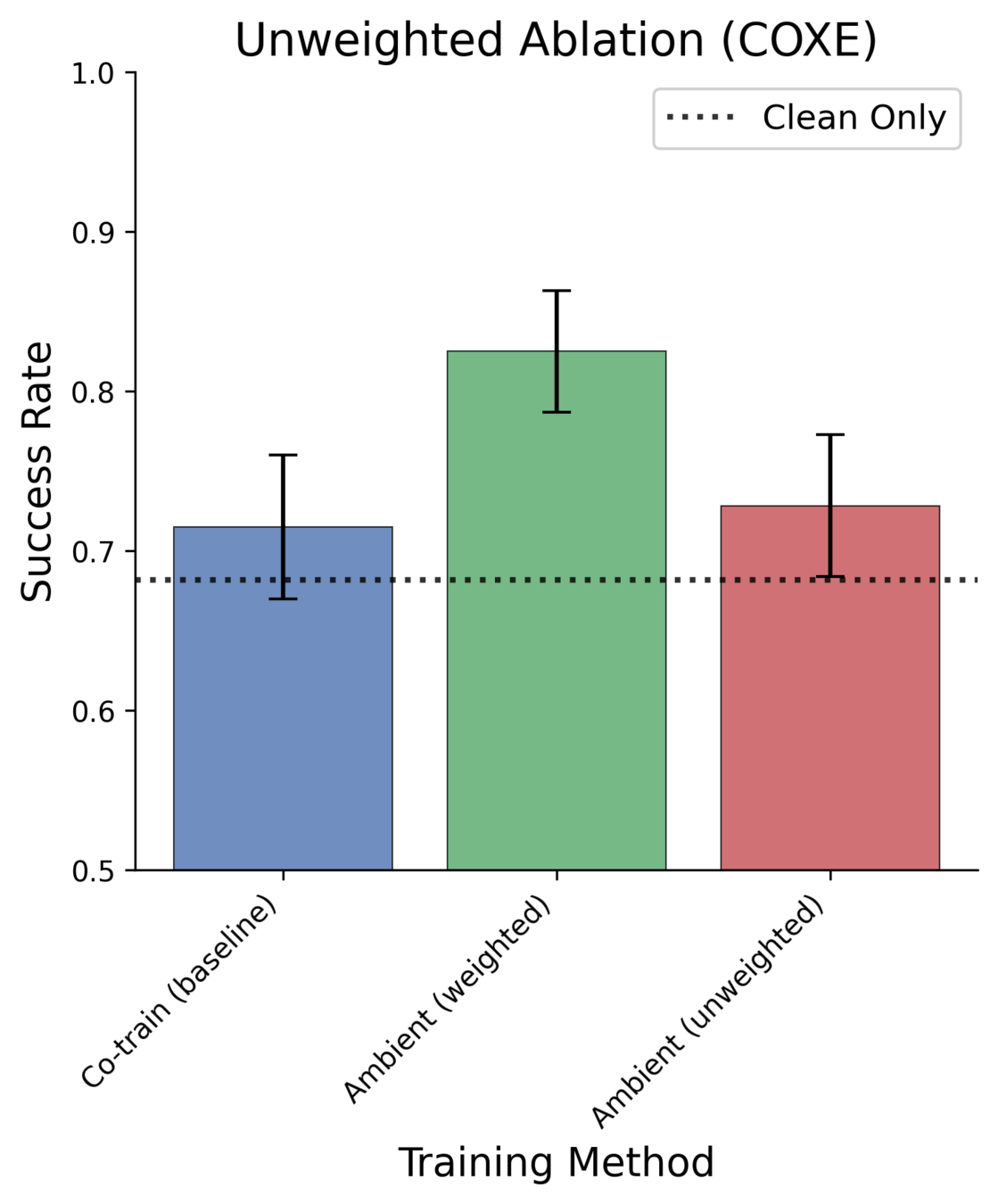
Ex. Reweights vs Unweighted


Reweighted
(sample clean 50%)
Unweighted
(sample clean 0.06%)
Ablations: Unweighted vs Weighted
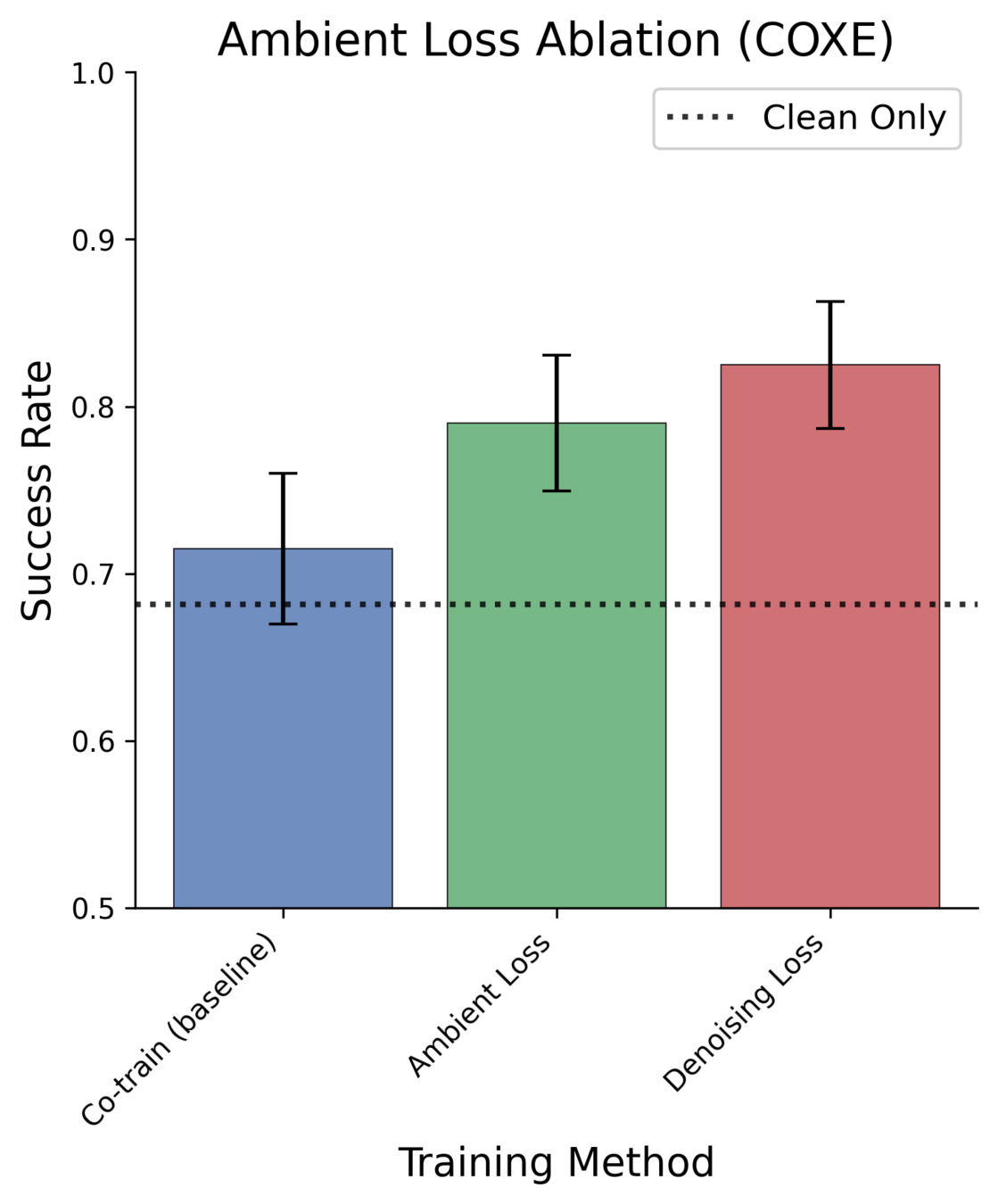
Ablations: Ambient Loss vs Denoising Loss
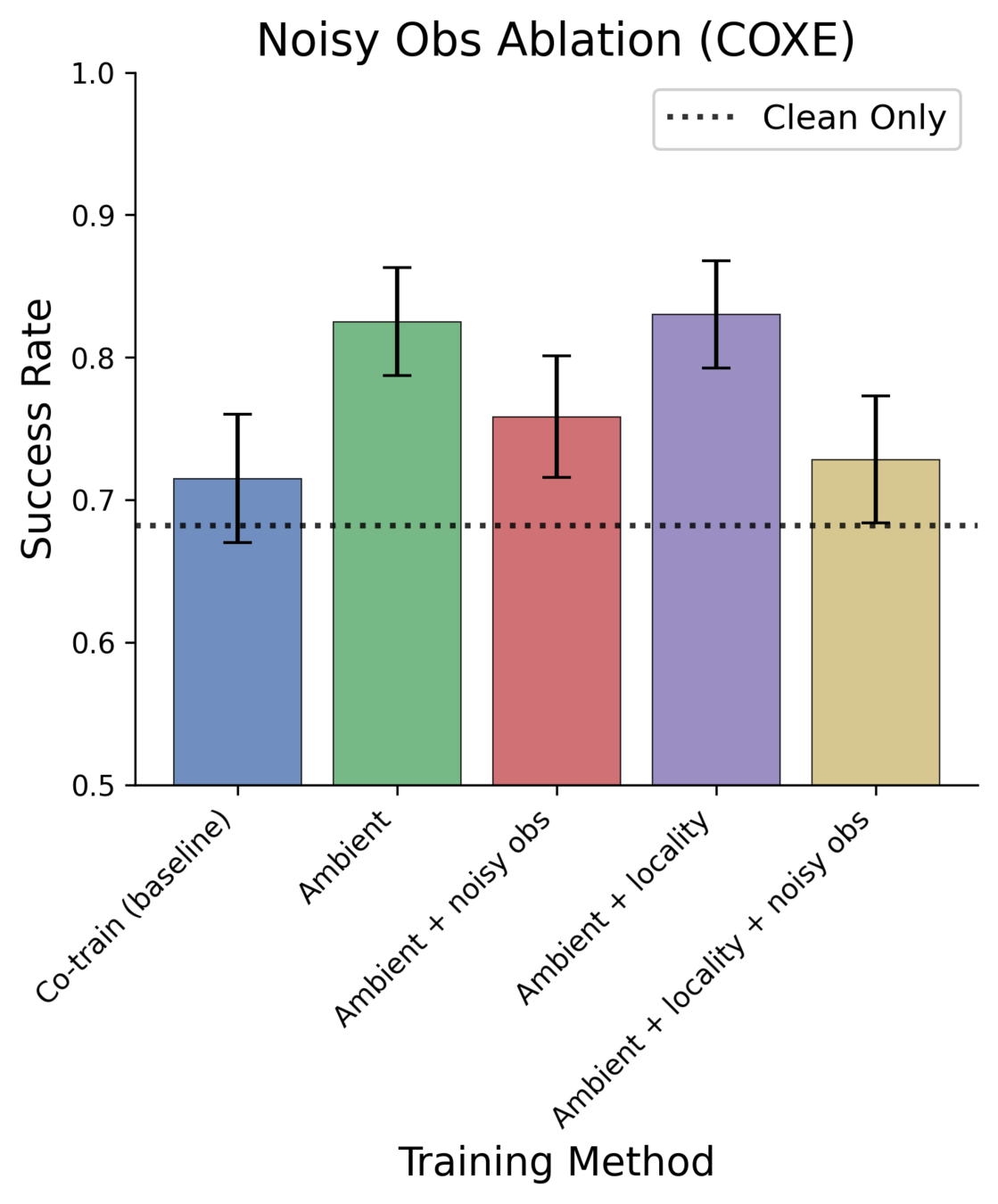
Ablations: Noisy Observations
\(\sigma=0\)
\(\sigma=1\)
\(\sigma_{min}\)
\(\sigma > \sigma_{min}\)
"Clean" Data
"Ambient"
Noise observation w.p. \(p\)
Produce model with noise level of observation
Ablations: Noisy Observations
\(\sigma=0\)
\(\sigma=1\)
\(\sigma_{min}\)
\(\sigma > \sigma_{min}\)
"Clean" Data
"Ambient"
Noise observation w.p. \(p\)
Produce model with noise level of observation
Inference time: set noise level of observations to 0
Ablations: Noisy Observations
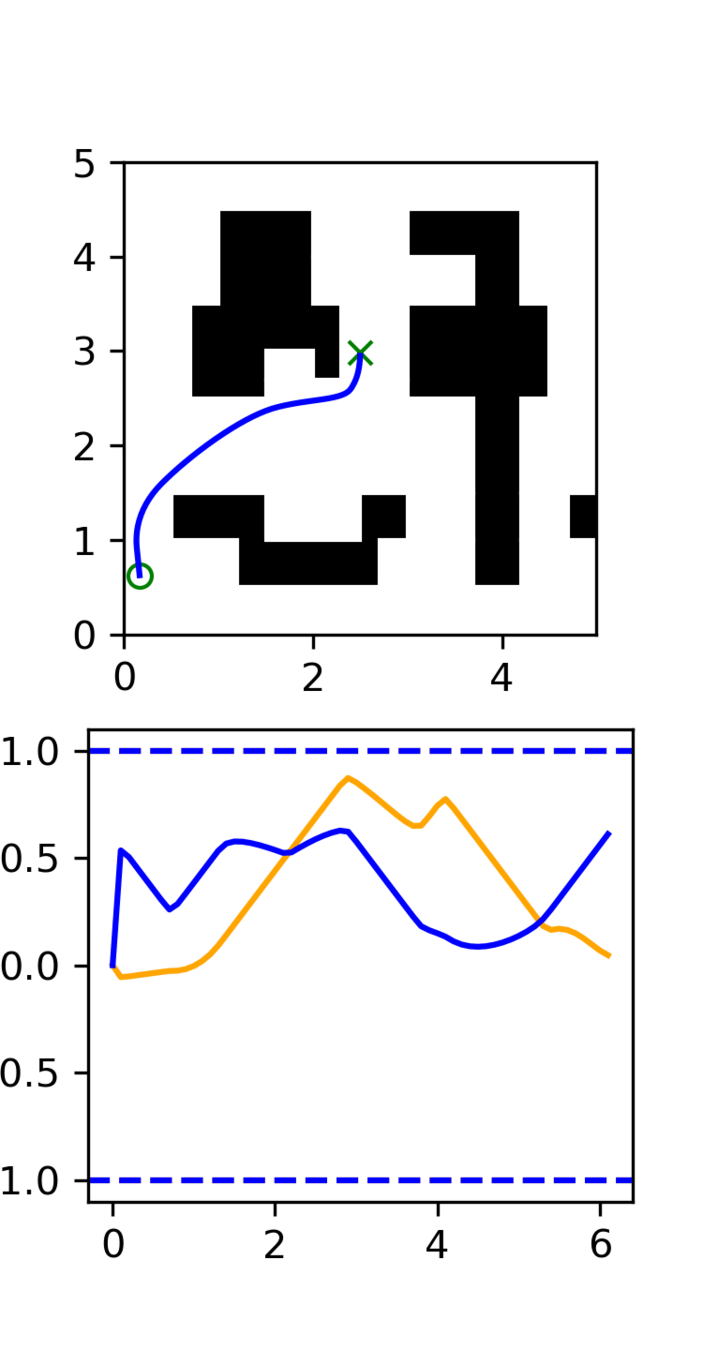
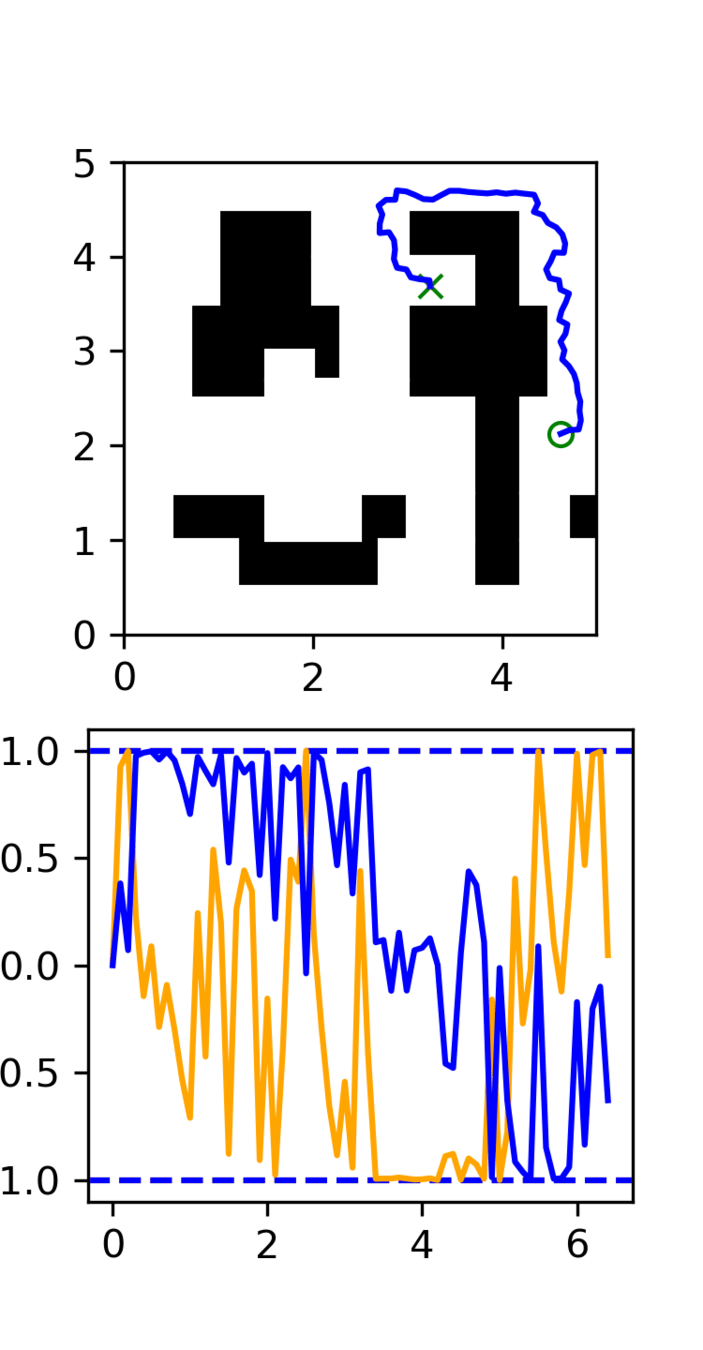
Motion Planning
Distribution shift: Low-quality, noisy trajectories
High Quality:
100 GCS trajectories
Low Quality:
5000 RRT trajectories
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Motion Planning Results
GCS
Success Rate
(Task-level)
Avg. Jerk^2
(Motion-level)
RRT
GCS+RRT
(Co-train)
GCS+RRT
(Ambient)
50%
Policies evaluated over 100 trials each
100%
7.5k
17k
91%
14.5k
98%
5.5k
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Motion Planning: 7-DoF Robot Arms


Generate good (expensive) and bad (cheap) motion planning data in 20,000 environments
Goal: generate high-quality, collision-free trajectories in new environments
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Too hard :(
Set up
- 10k trajopt trajectories
- 100k shortcut + RRT trajectories
- 6 RGB views
Results
- Doesn't work, tons of collisions
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Experiment Goal
Primary Goal: To provide intuition for ambient diffusion in a simple environment
- Effect of \(\sigma_{min}\)
- Ambient loss
- Learning
- Generating good trajectories from bad data: i.e. learn only the task structure from bad data
Secondary Goal: General neural motion planner
- There are entire papers on this...
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Memorize Single Environment

Clean data:
- 100k trajopt trajectories
Corrupt data
- 500k RRT trajectories
- 500k RRT + shortcut trajectories
Observation space: proprioception, target joint position
Action space: joint position commands
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
[Preliminary] Results
Trajopt
Success Rate
(Task-level)
Avg. Length
(Motion-level)
RRT
Trajopt + RRT
(Co-train)
Trajopt+RRT(Ambient)
30.9%
Policies evaluated over 1000 trials each
?
5.97
?
24.1%
Avg. Acc^2
(Motion-level)
2.75
?
11.24
7.32
38.5%
6.72
3.57
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Next Steps
- Answer to Russ' multi-task question
- Remaining experiments
- Finish neural motion planning
- LBM Eval
- Lu's cross embodiment data
- Tower-building task (real-world)
- Write paper
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Cross Embodied Data
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Cross Embodied Data
