For review. Please do not distribution.
Anonymous Submission CoRL 2026
Ambient Diffusion Policy
Imitation Learning From Suboptimal Data in Robotics

Open-X

Diffusion Policy
In-Distribution Data
Policy
\(\pi(a | o, l)\)
simulation


\(p\)
\(q\)
"Suboptimal" / OOD Data
- Sim2real gaps
- Noisy/low-quality teleop
- Task-level mismatch
- Changes in low-level controller
- Embodiment gap
- Camera models, poses, etc
- Different environment, objects, etc
Open-X
Diffusion Policy
In-Distribution Data
Policy
\(\pi(a | o, l)\)
simulation
\(p\)
\(q\)
"Suboptimal" / OOD Data
What are principled algorithms for learning from suboptimal data sources?
Diffusion Policy
\(t=0\)
\(t=T\)
"High-quality" Data
For all \(t \in [0,T]\): train \(h_\theta(A_t, O, t) \approx \mathbb{E}[A_0 \mid A_t, O]\)
Co-train
"Suboptimal" Data
"High-quality" Data
Policy learns to sample from a mixture of \(p\) and \(q\)
\(t=0\)
\(t=T\)
For all \(t \in [0,T]\): train \(h_\theta(A_t, O, t) \approx \mathbb{E}[A_0 \mid A_t, O]\)
Ambient Diffusion Policy
\(t_{\min}\)
\(t> t_{\min}\)
"High-quality" Data
\(p_t\) \(\not\approx\) \(q_t\)
\(p_t\) \(\approx\) \(q_t\)
Consequence of the data processing inequality
\(t=0\)
\(t=T\)
For all \(t \in [0,T]\): train \(h_\theta(A_t, O, t) \approx \mathbb{E}[A_0 \mid A_t, O]\)
Ambient Diffusion Policy
\(t> t_{\min}\)
"High-quality" Data
At low noise levels, action denoising only depends on local actions
\(t<t_{\max}\)
\(t_{\max}\)
"Locality"
\(p_t\) \(\approx\) \(q_t\)
\(t_{\min}\)
\(t=0\)
\(t=T\)
For all \(t \in [0,T]\): train \(h_\theta(A_t, O, t) \approx \mathbb{E}[A_0 \mid A_t, O]\)
Arbitrary Types of Suboptimality
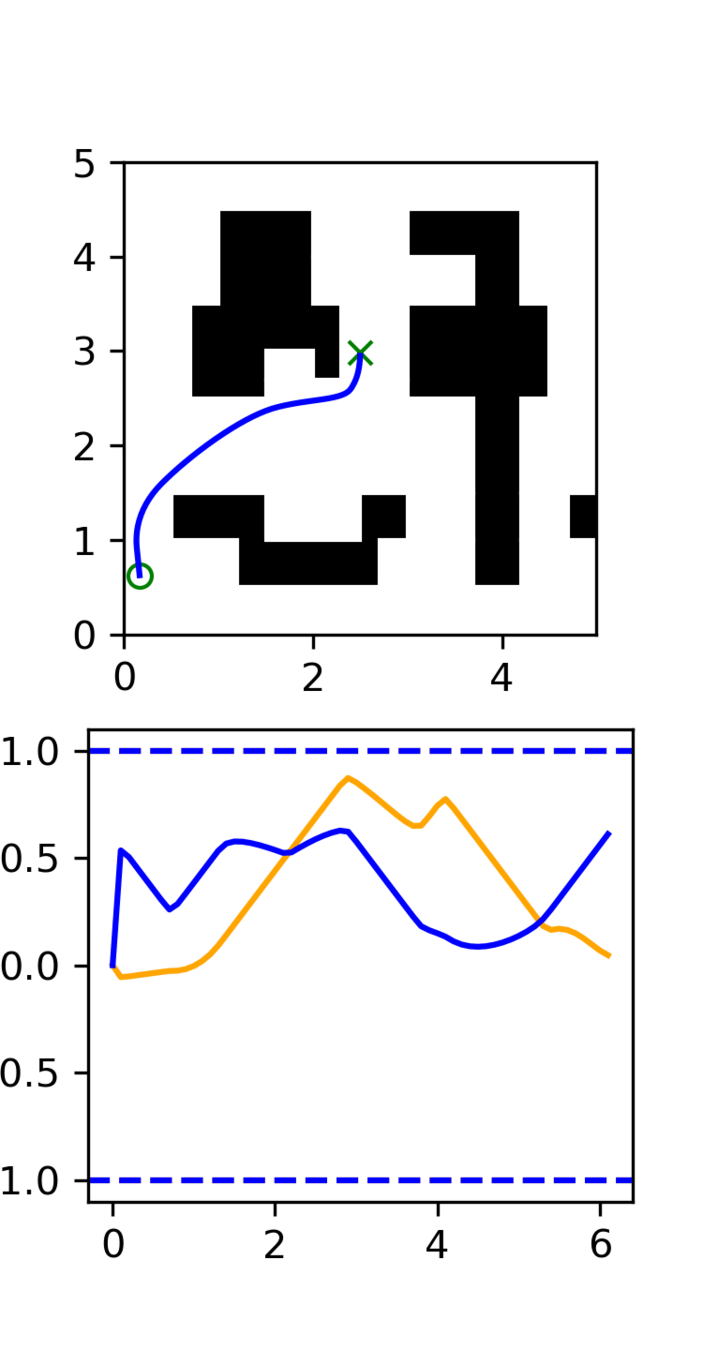
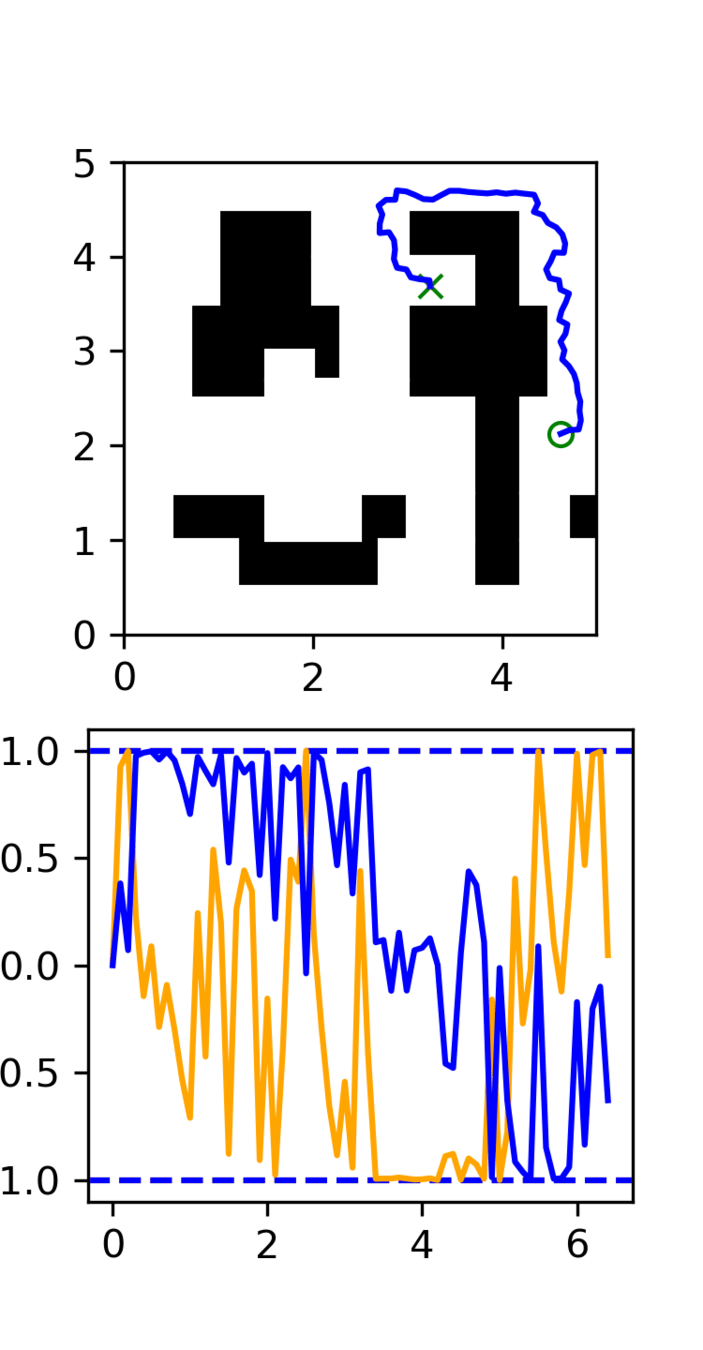

Noisy Trajectories: 2D Maze
Noisy Trajectories: 7-DoF arm
Sim2real: Planar Pushing
Task Mismatch: Block Sorting
Scaling to Real-World Datasets
Open-X
Diffusion Policy
In-Distribution Data
Policy
\(\pi(a | o, l)\)
\(p\)
\(q\)
"Suboptimal" / OOD Data
- cross-embodied
- diff. teleoperators
- sim data
- mislabeled data
- diff tasks, environments, camera
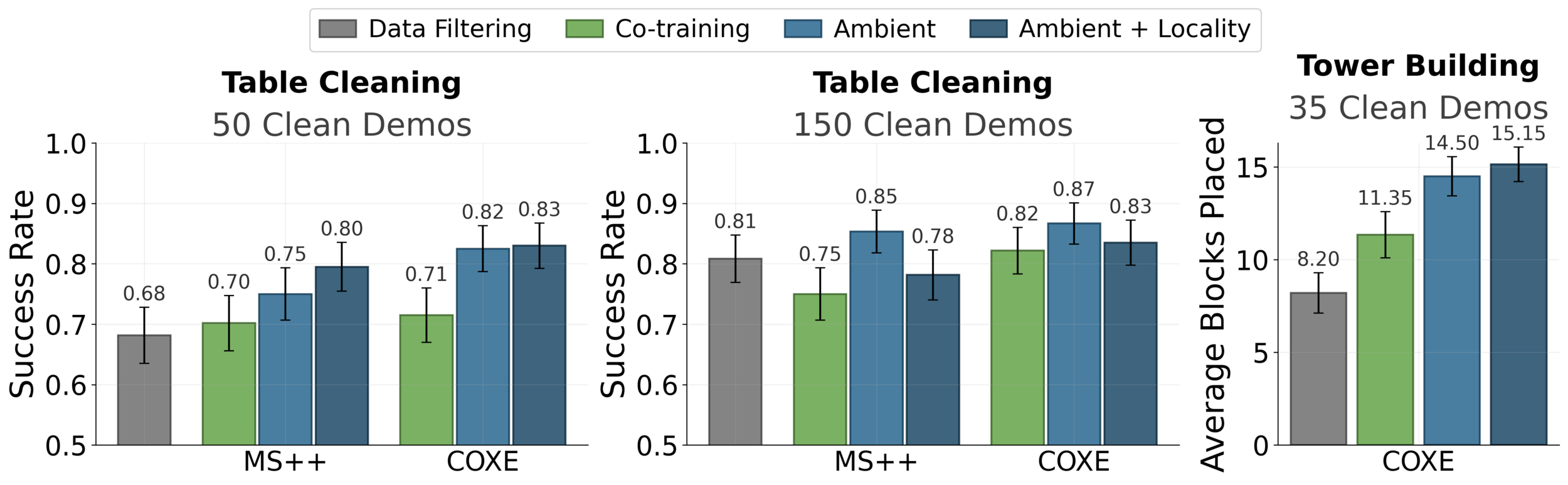
Table Cleaning & Tower Building
Table Cleaning
Tower Building
*both videos are autonomous rollouts from Ambient Diffusion Policies at 2x speed
Scaling to Real-World Datasets
84%
33%
In-Distribution Data
Open-X
simulation
Suboptimal / OOD Data
- Robot data: spectral power law, global-to-local hierarchy, locality
- Theory: rigorously justifies our algorithm; see appendix
- Experiments: demonstrate its generality and the scalability
- 4 types of suboptimality and 6 tasks
Ambient Diffusion Policy
a principled algorithm for learning from arbitrary suboptimal data
Contributions
Robot Data: Spectral Power Law
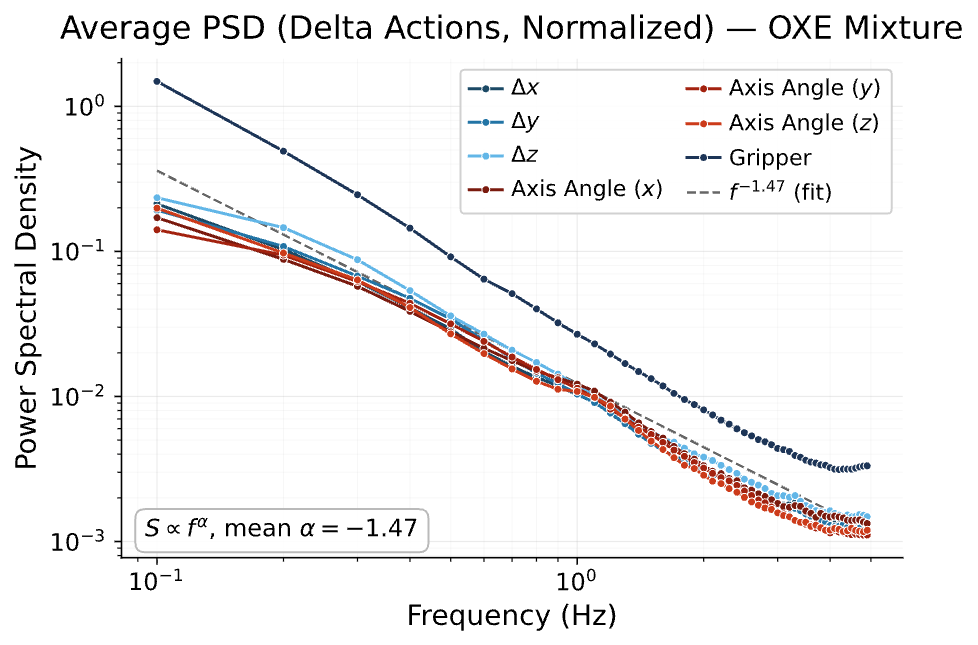
Global-to-Local Hierarchy
Spectral Power Law
\(\implies\)
global-to-local hierarchy in Diffusion Policy
High noise: Diffusion Policy learns global planning
Low noise: Diffusion Policy learns local motion primitives
Global-to-Local Hierarchy
Global-to-Local Hierarchy
Spectral Power Law \(\implies\)Locality
Locality at low noise:
The optimal denoiser has a small receptive field.
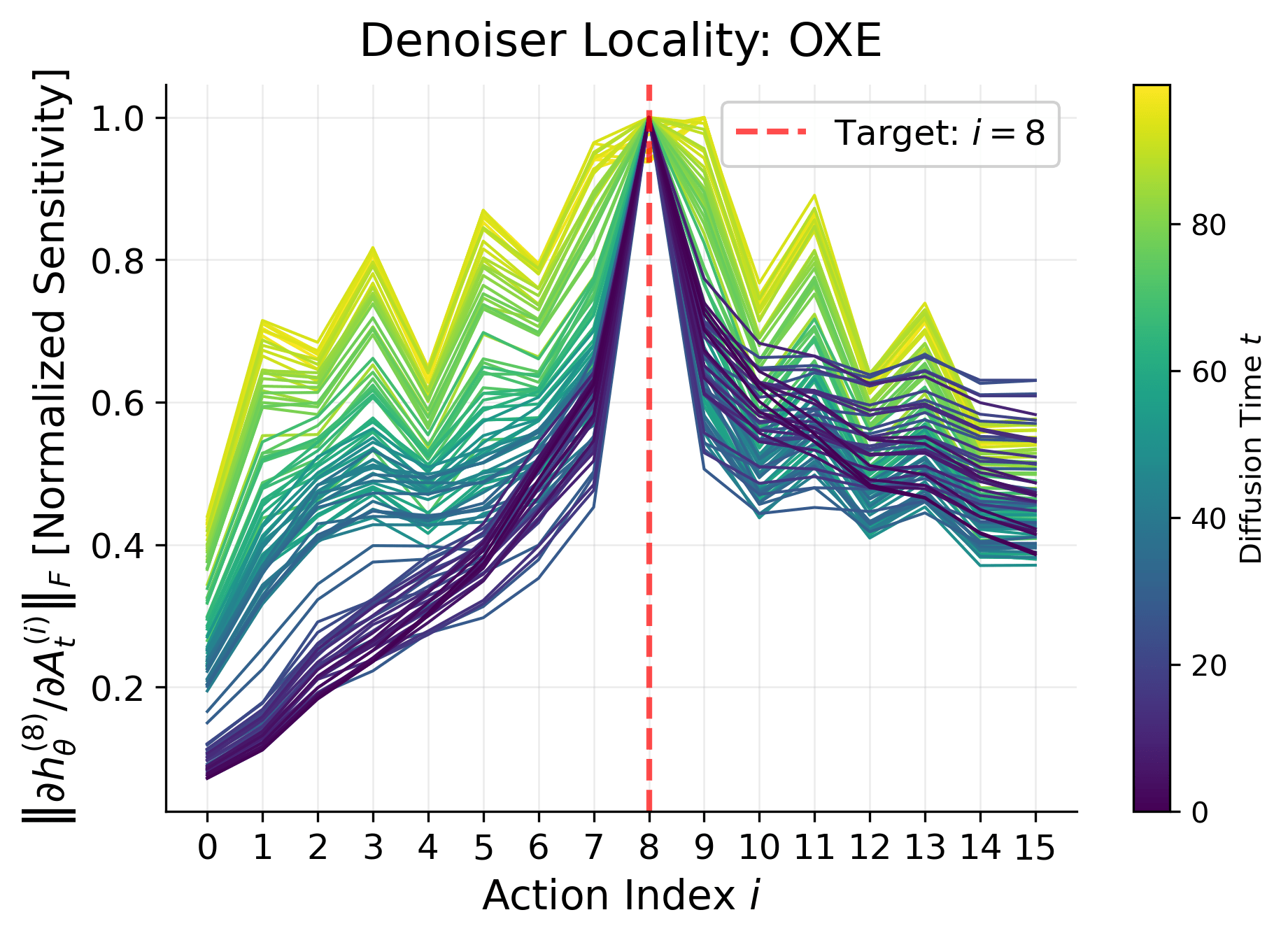
i.e. it ignores global features