Learning From Out-of-Distribution Data In Robotics
April 10, 2026
Adam Wei
Agenda
- Reviewing the Ambient Algorithm
- Properties of Robot Data
- Motion planning experiments
- Bin Sorting Experiments
- Real-World Experiments
- Concluding Thoughts
Part 1
Reviewing the Ambient Algorithm

Open-X

Learning Algorithm
In-Distribution Data
Policy
\(\pi(a | o, l)\)
What are principled algorithms for learning from out-of-distribution data sources?
simulation



Colab w/ Giannis Daras
Our approach: Ambient Diffusion Policy
\(p\)
\(q\)
Out-of-Distribution Data
Distribution Shifts in Robot Data
- Sim2real gaps
- Noisy/low-quality teleop
- Task-level mismatch
- Changes in low-level controller
Open-X
In-Distribution Data
simulation
Out-of-Distribution Data
- Embodiment gap
- Camera models, poses, etc
- Different environment, objects, etc
Data Filtering: Pro
CC12M: 12M+ image + text captions


"Corrupt" Data:
Low quality images
"Clean" Data:
High quality images
Pro: Protects the final sampling distribution

Data Filtering: Con
There is still value and utility in OOD data!
... we just aren't using it correctlty
Goal: to develop principled algorithms that change the way we use low-quality or OOD data
Open-X
In-Distribution Data
simulation
Out-of-Distribution Data
Diffusion Training
\(\sigma=0\)
\(\sigma=1\)
"Clean" Data
For all \(\sigma \in [0,1]\): train \(h_\theta(A_\sigma, O, \sigma) \approx \mathbb{E}[A_0 \mid A_\sigma, O]\)
Co-training
\(\sigma=0\)
\(\sigma=1\)
"Corrupt" Data
"Clean" Data
For all \(\sigma \in [0,1]\): train \(h_\theta(A_\sigma, O, \sigma) \approx \mathbb{E}[A_0 \mid A_\sigma, O]\)
Co-training
\(\sigma=0\)
\(\sigma=1\)
"Clean" Data
\(p^{train} = \alpha\) \(p\)\(+(1-\alpha)\) \(q\)
For all \(\sigma \in [0,1]\): train \(h_\theta(A_\sigma, O, \sigma) \approx \mathbb{E}[A_0 \mid A_\sigma, O]\)
\(\alpha\)
\(1-\alpha\)
\(p^{train}\) contains \(q\) \(\implies\) This is the wrong objective
"Corrupt" Data
Ambient
\(\sigma=0\)
\(\sigma=1\)
For all \(\sigma \in [0,1]\): train \(h_\theta(A_\sigma, O, \sigma) \approx \mathbb{E}[A_0 \mid A_\sigma, O]\)
\(\sigma > \sigma_{min}\)
"Clean" Data
\(\sigma_{min}\)
\(p_\sigma\) \(\not\approx\) \(q_\sigma\)
\(p_\sigma\) \(\approx\) \(q_\sigma\)
Gaussian Noise As Contraction
\(p_0\)
\(q_0\)
\(p_\sigma\)
\(q_\sigma\)
\(D(p_\sigma, q_\sigma) \to 0\) as \(\sigma\to \infty\)
\(\implies \exists \sigma_{min} \ \mathrm{s.t.}\ D(p_\sigma, q_\sigma) < \epsilon\ \forall \sigma > \sigma_{min}\)
Noisy Channel
\(Y = X + \sigma Z\)
\(D(p_0, q_0)\)
\(D(p_\sigma, q_\sigma)\)
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
How to choose \(\sigma_{min}\)?
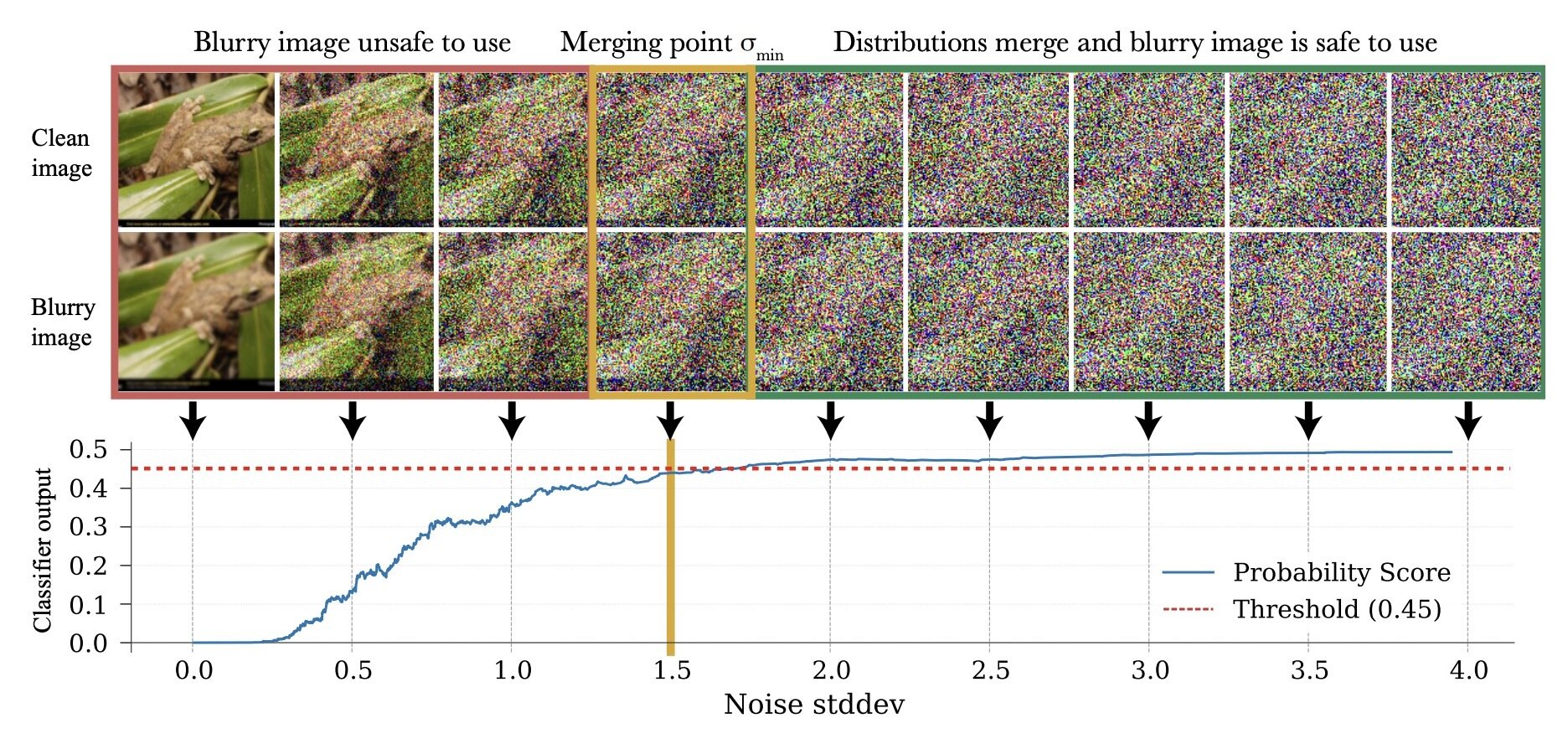
\(\sigma_{min}= \inf\{\sigma\in[0,1]: c_\theta (x_\sigma, \sigma) > 0.5-\epsilon\}\)
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
How to choose \(\sigma_{min}\)?
* assuming \(c_\theta\) the best possible classifier
Original claim*: this bounds \(TV(p_{\sigma_{min}}, q_{\sigma_{min}})\)
\(\sigma_{min}\)
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
How to choose \(\sigma_{min}\)?
* assuming \(c_\theta\) the best possible classifier
Original claim*: this bounds \(TV(p_{\sigma_{min}}, q_{\sigma_{min}})\)
Corrected claim* [Kerem]: this bounds \(\Delta (p_{\sigma_{min}}, q_{\sigma_{min}})\)
\(\geq TV (p_{\sigma_{min}}, q_{\sigma_{min}})^2\)
\(\sigma_{min}\)
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
How to choose \(\sigma_{min}\)?
poor classifier performance at \(\sigma_{min}\)\(\implies p_{\sigma} \approx q_{\sigma} \quad \forall \sigma > \sigma_{min}\)
Key Takeaway:
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
How to choose \(\sigma_{min}\)?
Increasing granularity
Assign \(\sigma_{min}\) per datapoint
Assign \(\sigma_{min}\) per dataset
Run the classifier per dataset
Run the classifier per datapoint
Can do in-between... ex. last long talk
Theory [from original paper]
\(p_{\sigma_{min}} \approx q_{\sigma_{min}}\)
For \(\sigma > \sigma_{min}\):
but \(p_{\sigma_{min}} \neq q_{\sigma_{min}}\)
\(\mathrm{MSE}(h_\theta) = \mathrm{bias}(h_\theta) + \mathrm{var}(h_\theta)\)
... so training on \(q_\sigma\) still introduces bias!
[Informal] Theorem: For all \(\mathcal{D}_p\) and \(\mathcal{D}_q\), there exists \(\sigma_{min}\) sufficiently high s.t. training on \(\mathcal{D}_q\) for \(\sigma > \sigma_{min}\) improves distribution learning for \(p\)
* happens in co-training as well...
*
Ambient
\(\sigma=0\)
\(\sigma=1\)
For all \(\sigma \in [0,1]\): train \(h_\theta(A_\sigma, O, \sigma) \approx \mathbb{E}[A_0 \mid A_\sigma, O]\)
"Corrupt" Data
"Clean" Data
\(\sigma_{min}\)
\(\sigma > \sigma_{min}\)
\(p_\sigma\) \(\approx\) \(q_\sigma\)
Ambient + Locality
\(\sigma=0\)
\(\sigma=1\)
For all \(\sigma \in [0,1]\): train \(h_\theta(A_\sigma, O, \sigma) \approx \mathbb{E}[A_0 \mid A_\sigma, O]\)
"Corrupt" Data
"Clean" Data
\(\sigma_{min}\)
\(\sigma > \sigma_{min}\)
\(\sigma \leq \sigma_{max}\)
"Locality"
More on this later...
\(p_\sigma\) \(\approx\) \(q_\sigma\)
\(\sigma_{max}\)
Loss Function (for \(x_0\sim q_0\))
\(\mathbb E[\lVert h_\theta(x_t, t) + \frac{\sigma_{min}^2\sqrt{1-\sigma_{t}^2}}{\sigma_t^2-\sigma_{min}^2}x_{t} - \frac{\sigma_{t}^2\sqrt{1-\sigma_{min}^2}}{\sigma_t^2-\sigma_{min}^2} x_{t_{min}} \rVert_2^2]\)
Ambient Loss
Denoising Loss
\(x_0\)-prediction
\(\epsilon\)-prediction
(assumes access to \(x_0\))
(assumes access to \(x_{\sigma_{min}}\))
\(\mathbb E[\lVert h_\theta(x_t, t) - x_0 \rVert_2^2]\)
\(\mathbb E[\lVert h_\theta(x_t, t) - \epsilon \rVert_2^2]\)
\(\mathbb E[\lVert h_\theta(x_t, t) - \frac{\sigma_t^2 (1-\sigma_{min}^2)}{(\sigma_t^2 - \sigma_{min}^2)}x_t + \frac{\sigma_t \sqrt{1-\sigma_t^2}\sqrt{1-\sigma_{min}^2}}{\sigma_t^2 - \sigma_{min}^2}x_{t_{min}}\rVert_2^2]\)
Could be wrong! (see paper for correct results)
Part 2
Why Ambient and Robotics
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
When Does Ambient Work?
1. Data is scarce


+ 5 years
=
~100,000 solved protein structures
200M+ protein structures
Criteria
Robotics?
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
When Does Ambient Work?
1. Data is scarce
Criteria
Robotics?
✅
(short-term)
2. Data quality and sources are heterogeneous
✅
Open-X
simulation
Out-of-Distribution Data
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
When Does Ambient Work?
1. Data is scarce
Criteria
Robotics?
✅
(short-term)
2. Data quality and sources are heterogeneous
✅
3. Data exhibits certain structure
- Spectral Decay
- Locality
✅
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
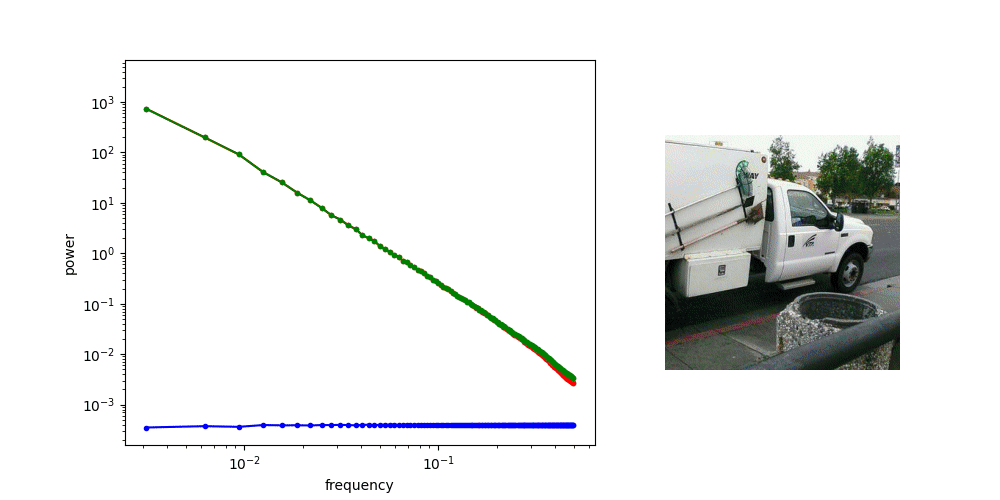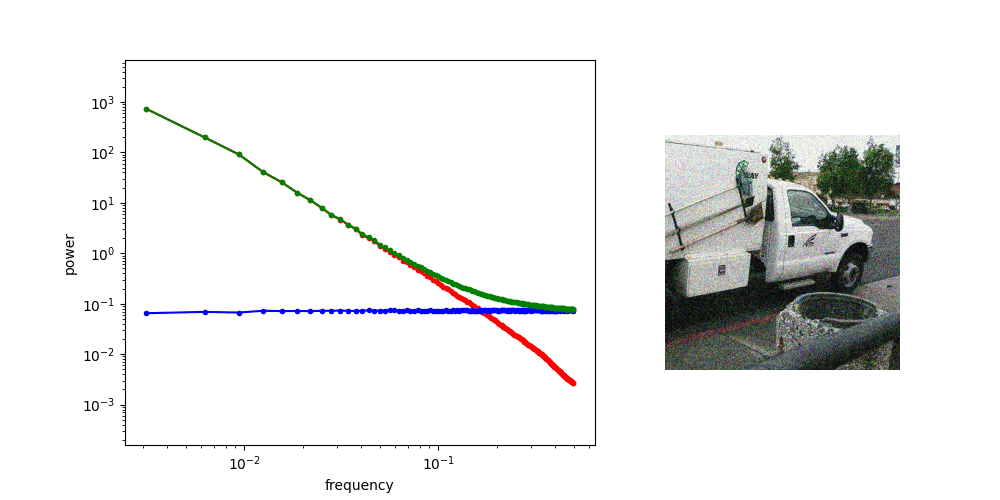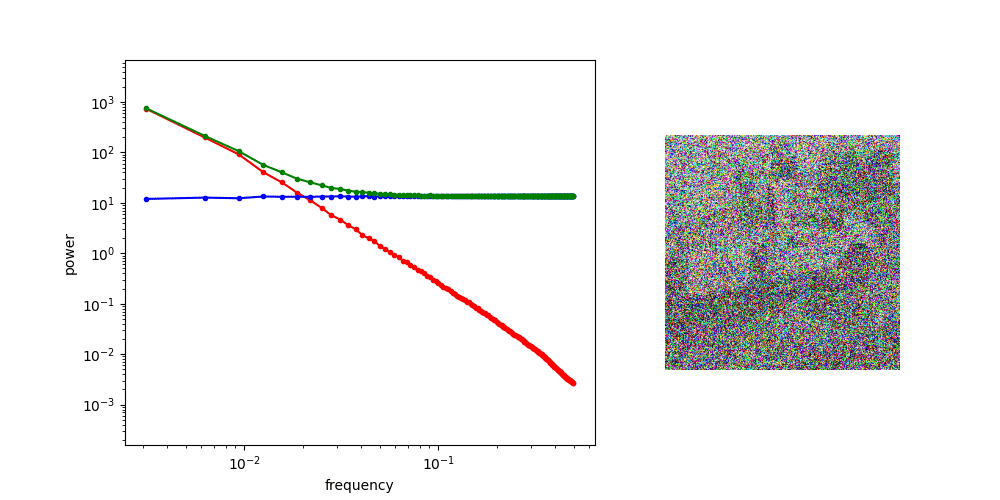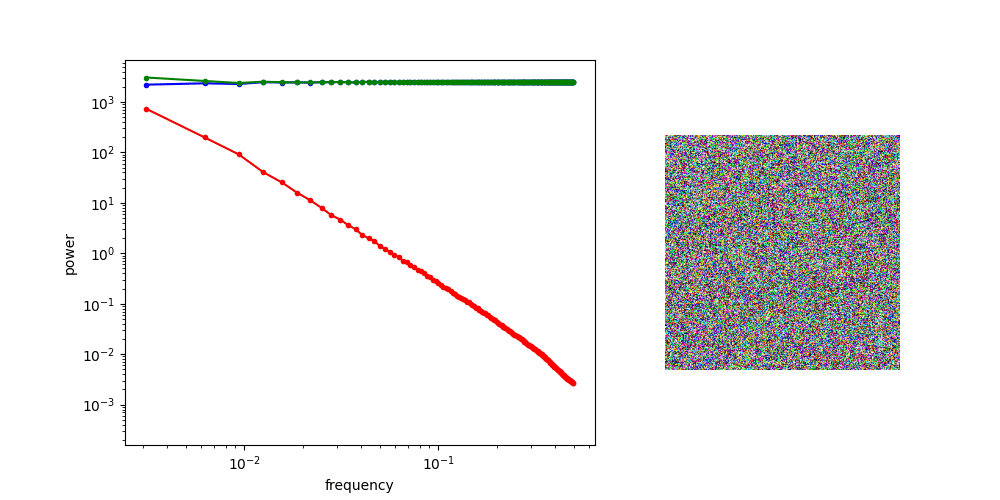
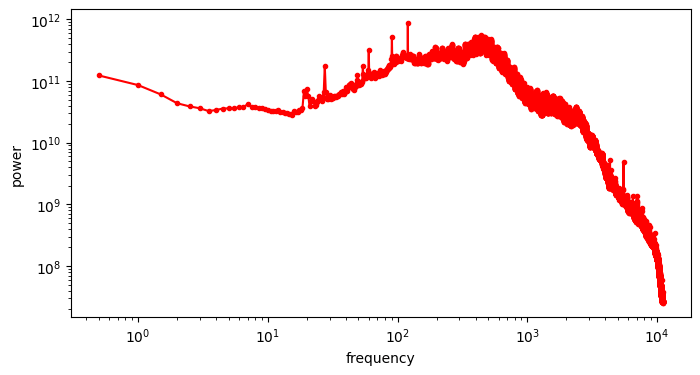
Images: Power Spectral Density (PSD)

By Sander Dieleman
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Images: Power Spectral Density (PSD)
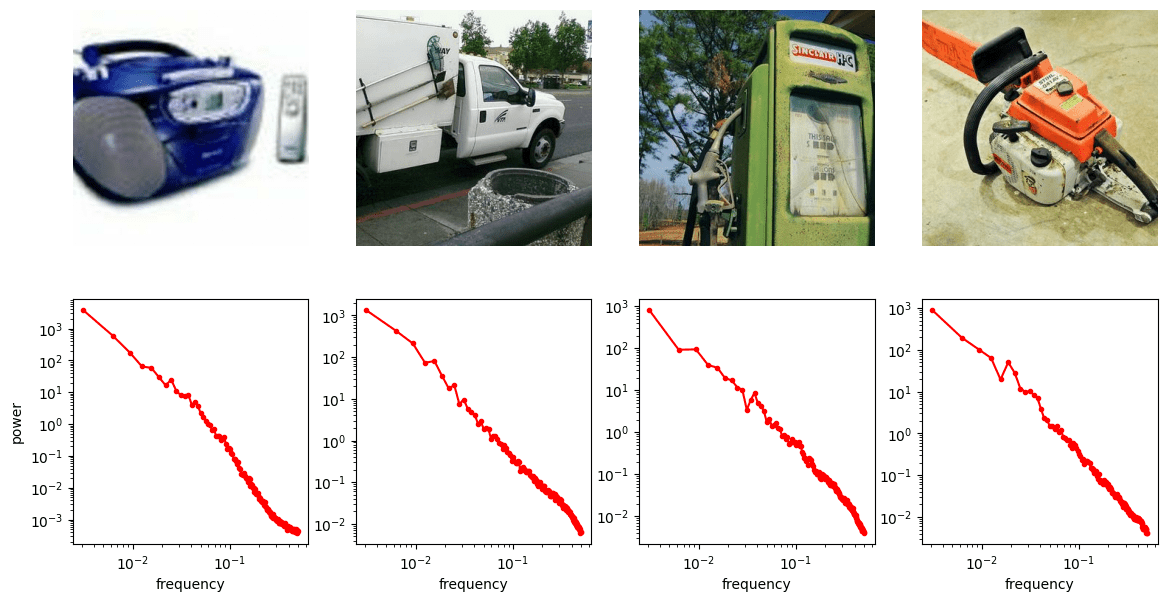
"Radially Averaged" PSD of the green channel
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Images: Noisy Image PSD
"Radially Averaged" PSD of the green channel
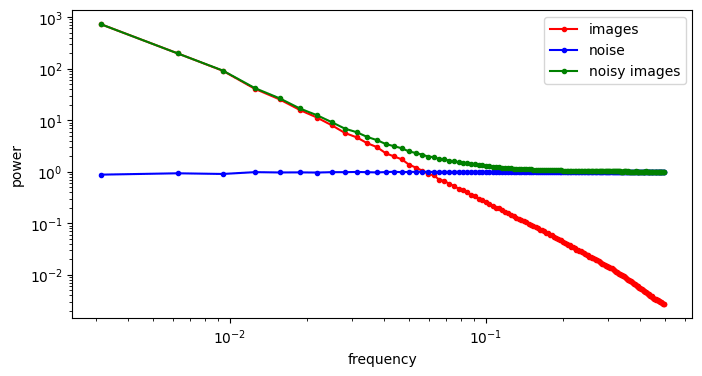
High SNR
Low SNR
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Diffusion Process PSD
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Implications for Image Diffusion
\(\sigma=0\)
\(\sigma=1\)
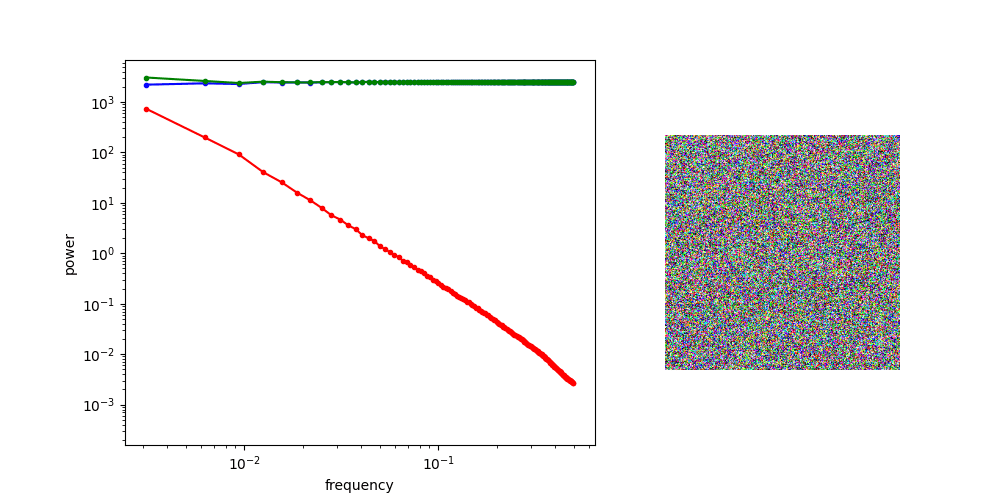
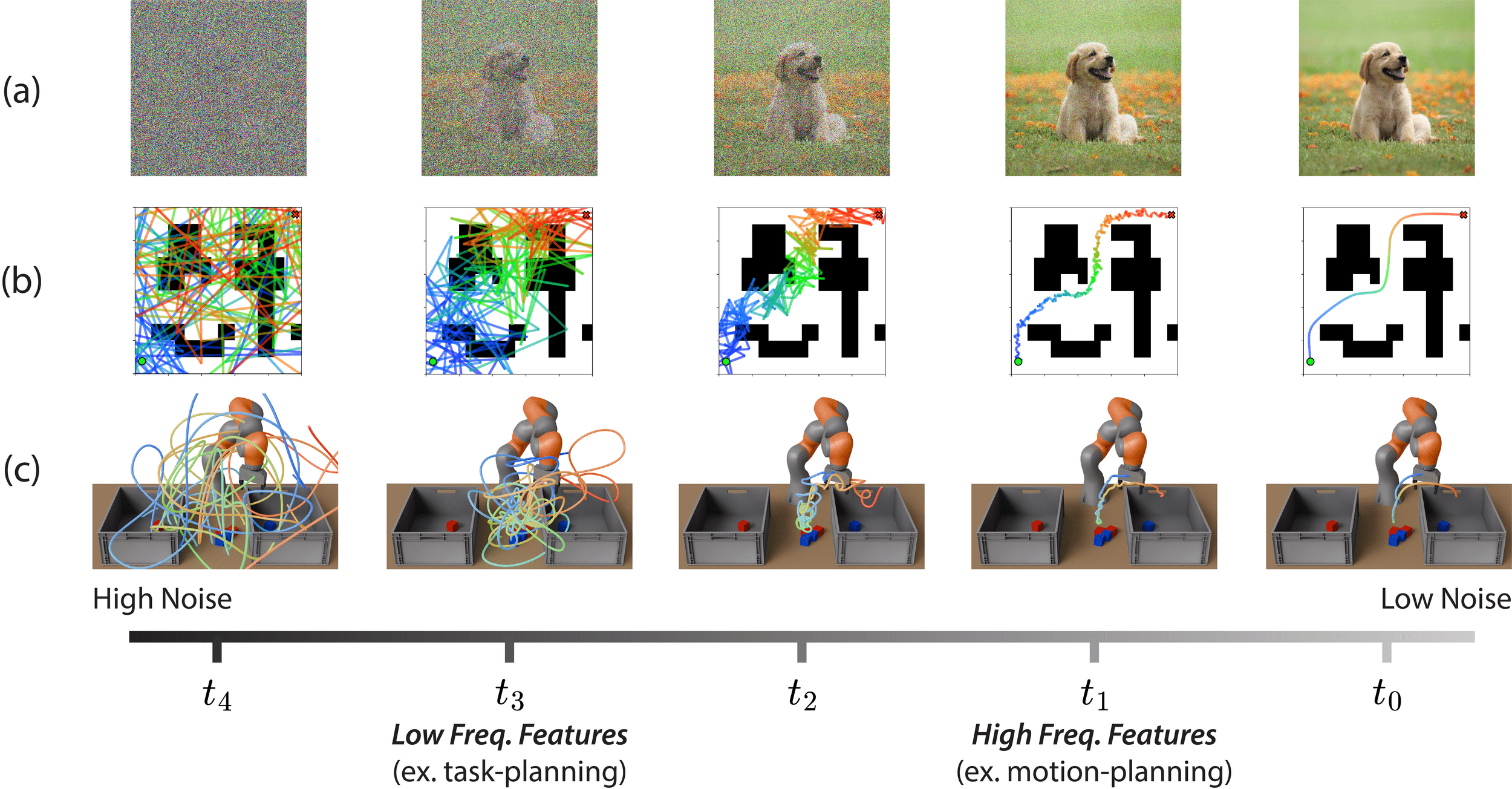
at high noise, generate low frequency features
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Implications for Image Diffusion
\(\sigma=0\)
\(\sigma=1\)
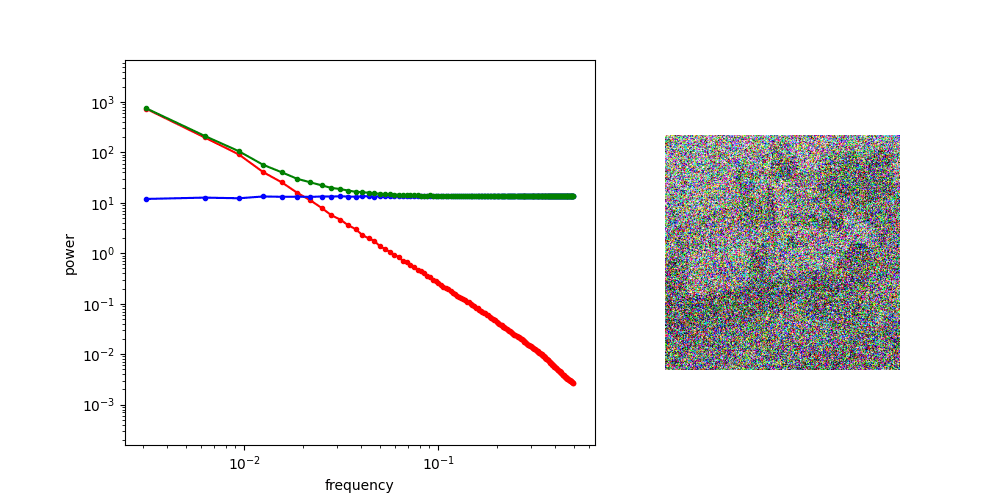
at high noise, generate low frequency features
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Implications for Image Diffusion
\(\sigma=0\)
\(\sigma=1\)
at high noise, generate low frequency features
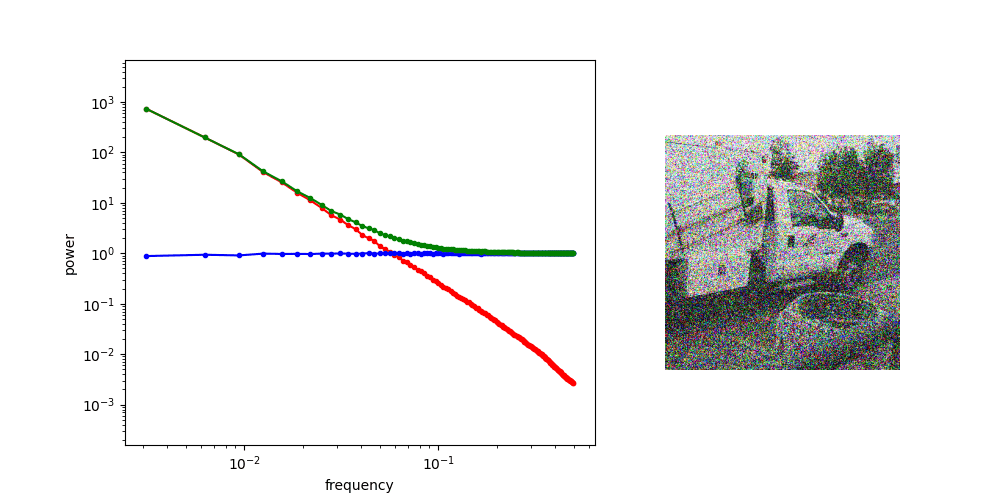
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Implications for Image Diffusion
\(\sigma=0\)
\(\sigma=1\)
at low noise, generate high frequency features
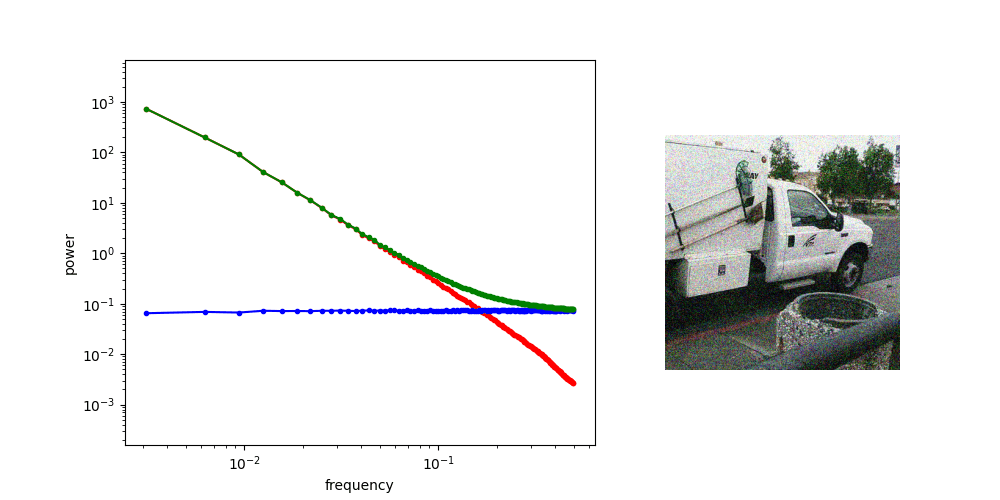
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Implications for Image Diffusion
\(\sigma=0\)
\(\sigma=1\)
at low noise, generate high frequency features
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Implications for Ambient
Ambient uses noise as a high-freq. mask
\(\implies\) ambient is best for high-freq corruptions
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
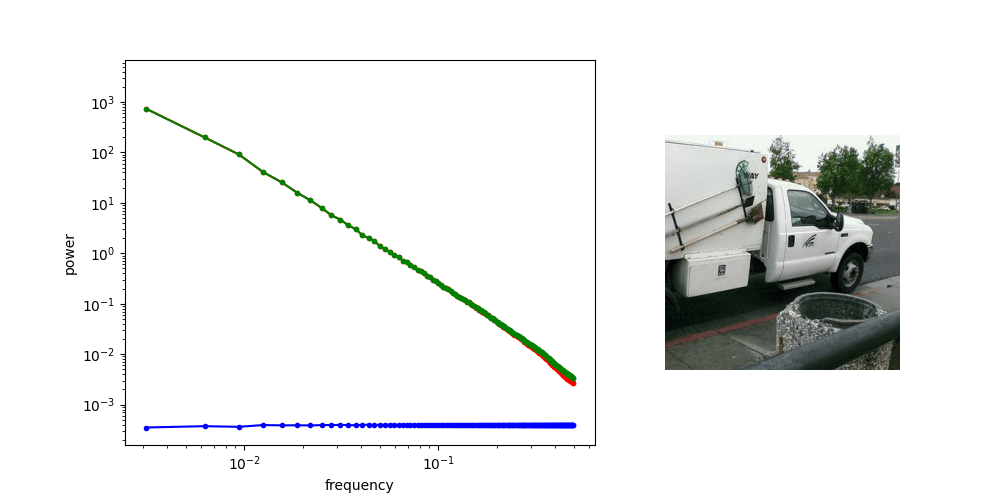
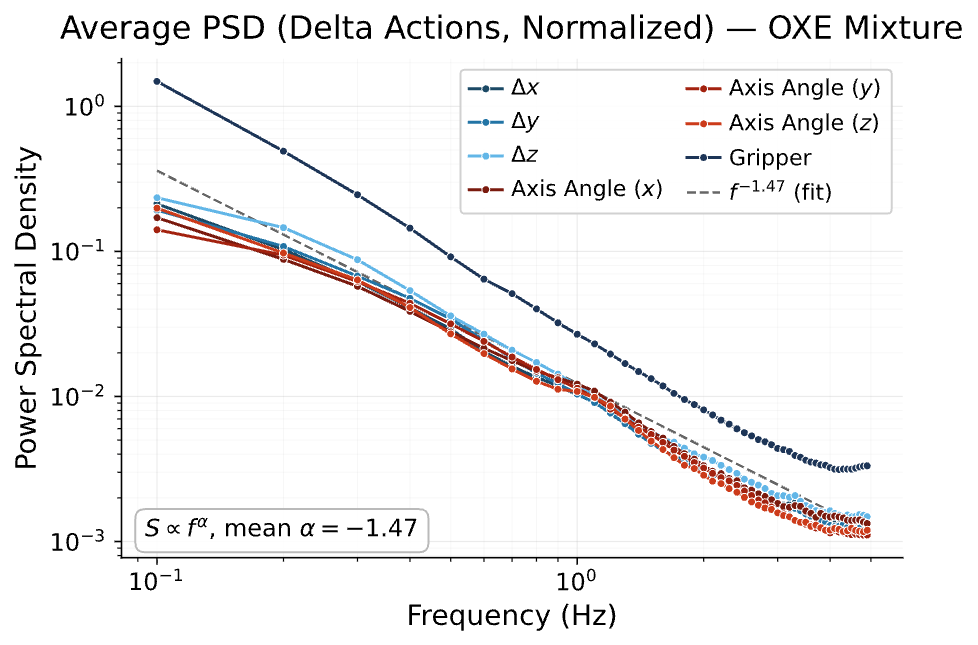
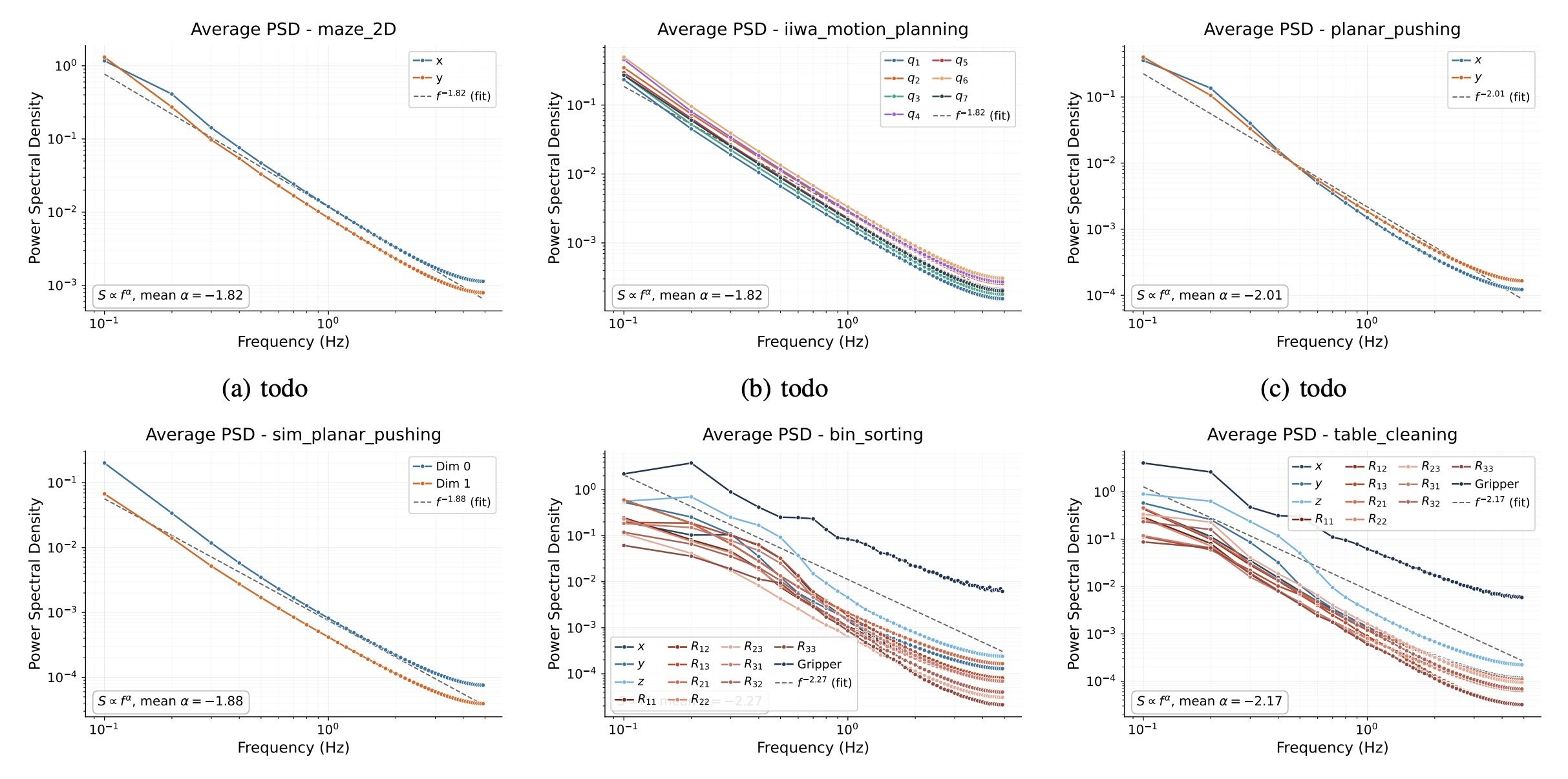
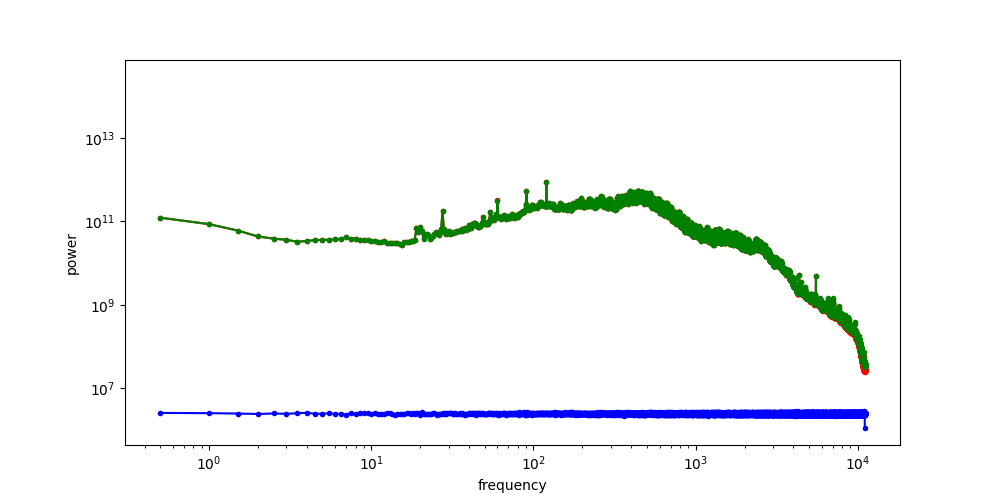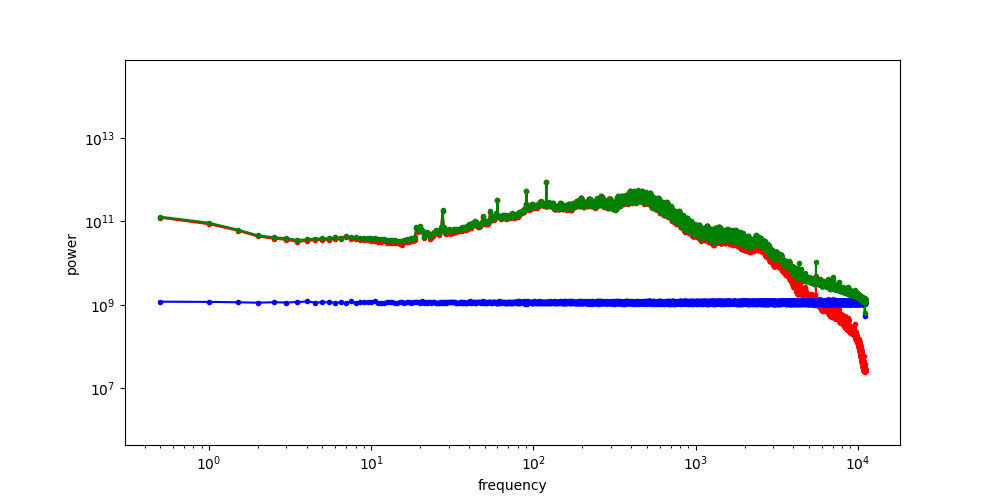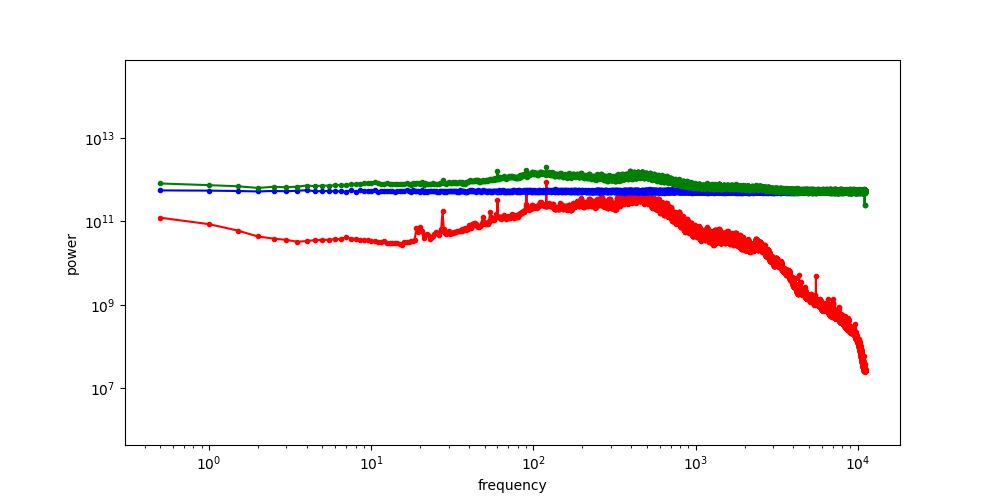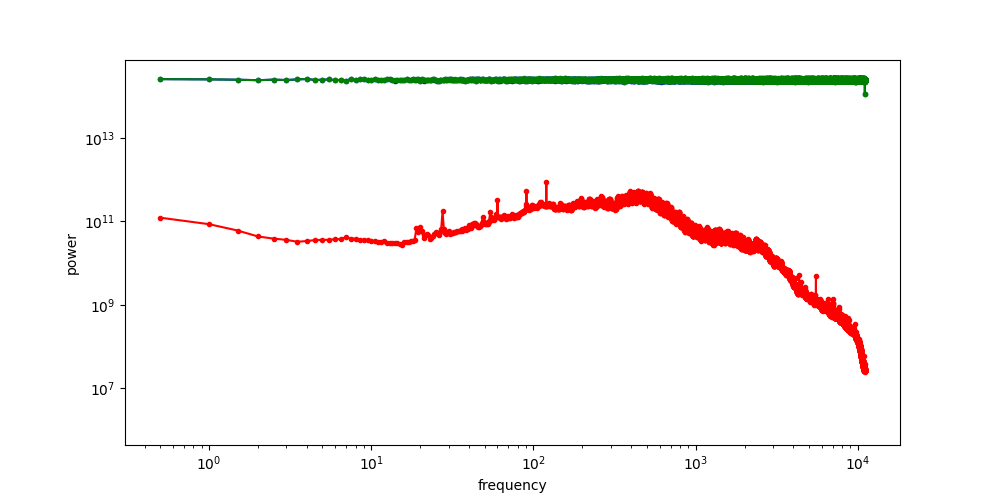
Robot Data: PSD
Punch line: Robot data exhibits spectral decay,
and many robot corruptions are "motion-level" (high freq)
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Robot Data: PSD
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Robot Data: PSD
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Implications for Robotics
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Implications for Robotics
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Implications for Robotics
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Implications for Ambient in Robotics
If action corruption is motion-level, then Ambient will work well
Low Freq: high-level (task) planning and decision making
High Freq: low-level motion primitives (ex. how to grasp, smoothness)
ex. cross-embodiment, sim2real, noisy-teleop, etc
\(\sigma=0\)
\(\sigma=1\)
"Corrupt" Data
"Clean" Data
\(\sigma_{min}\)
\(\sigma > \sigma_{min}\)
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Implications for Ambient in Robotics
Concern: task and motion planning means something very specific...
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Implications for Ambient in Robotics
Concern: task and motion planning means something very specific...
Possible experiment:
Show that a classifier can predict the task variables at high noise
\(a_{\sigma(t_2)}\) sufficient to predict task variables?
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Task-level Corruptions
What if the action corruption is task-level?
Red \(\rightarrow\) Left
Blue \(\rightarrow\) Right
Red \(\rightarrow\) Right
Blue \(\rightarrow\) Left
(out-dated video...)
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
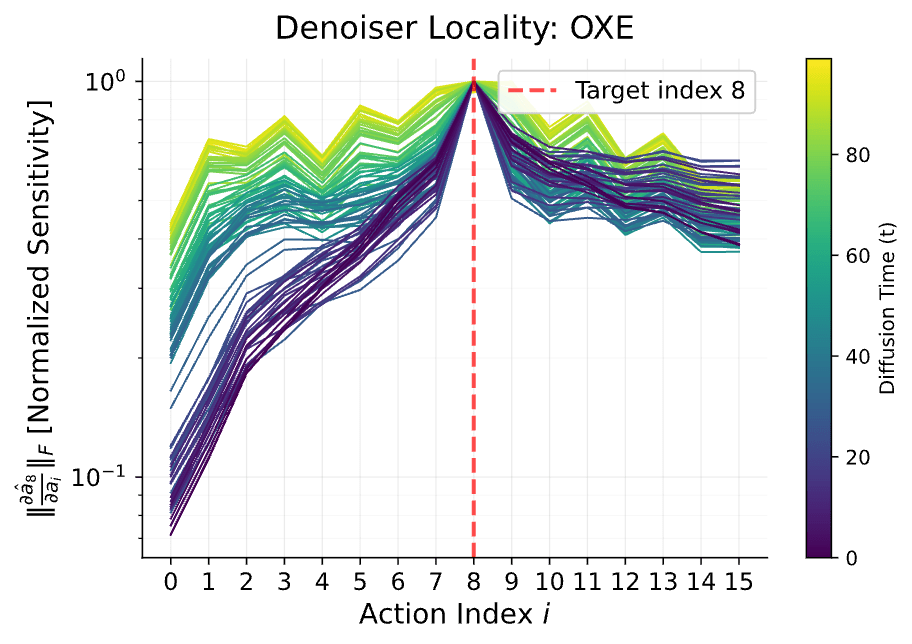
Locality
Sensitivity of \(\hat a_0^{(8)}\) to \(a_\sigma^{i}\) at different noise levels
\(\lVert \frac{\partial h_\theta^{(8)}(a_\sigma)}{\partial a_\sigma^{(i)}}\rVert\) vs action index \(i\)
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Locality
Sensitivity of \(\hat a_0^{(8)}\) to \(a_\sigma^{i}\) at different noise levels
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Locality
At low-noise the denoiser does not attend to distant actions (i.e. ignores low-frequencies)
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Locality
At low-noise the denoiser does not attend to distant actions (i.e. ignores low-frequencies)
\(\implies\) can use data with task-level distribution shift at low-noise
\(\sigma=0\)
\(\sigma=1\)
"Corrupt" Data
"Clean" Data
\(\sigma_{min}\)
\(\sigma > \sigma_{min}\)
\(\sigma \leq \sigma_{max}\)
"Locality"
\(p_\sigma\) \(\approx\) \(q_\sigma\)
\(\sigma_{max}\)
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
When Does Ambient Work?
1. Data is scarce
Criteria
Robotics?
✅
(short-term)
2. Data quality and sources are heterogeneous
✅
3. Data exhibits certain structure
- Spectral Decay
- Locality
✅
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Misconceptions
"Coarse" to "Fine" is a property of diffusion
"Coarse" to "Fine" is a property of the data
✅
❌
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Example: Audio
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Example: Audio
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Misconceptions
"Coarse" to "Fine" is a property of diffusion
"Coarse" to "Fine" is a property of the data
Spectral Decay is required for diffusion
Diffusion (and Ambient) work regardless of PSD
- ex. Diffusion still works for audio
- Spectral decay provides nice interpretation
✅
❌
❌
✅
Part 3
Motion Planning Experiments
Question break!
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
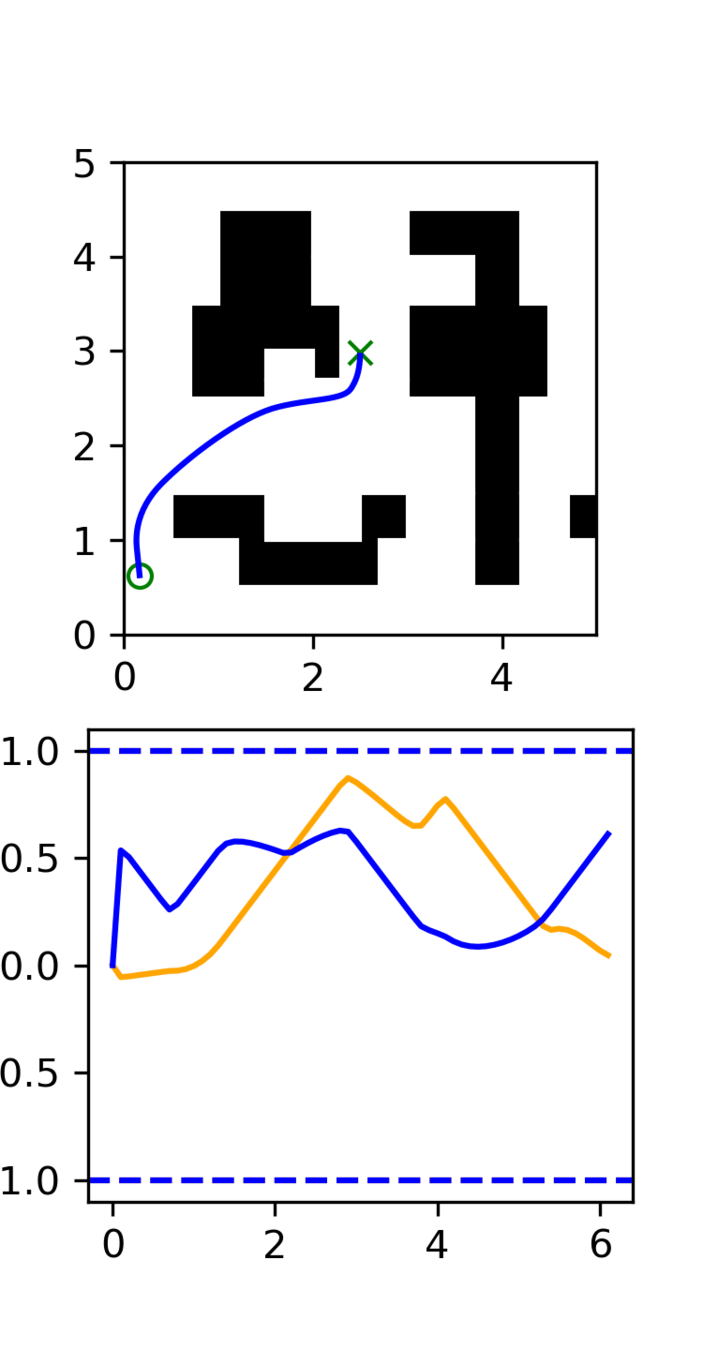
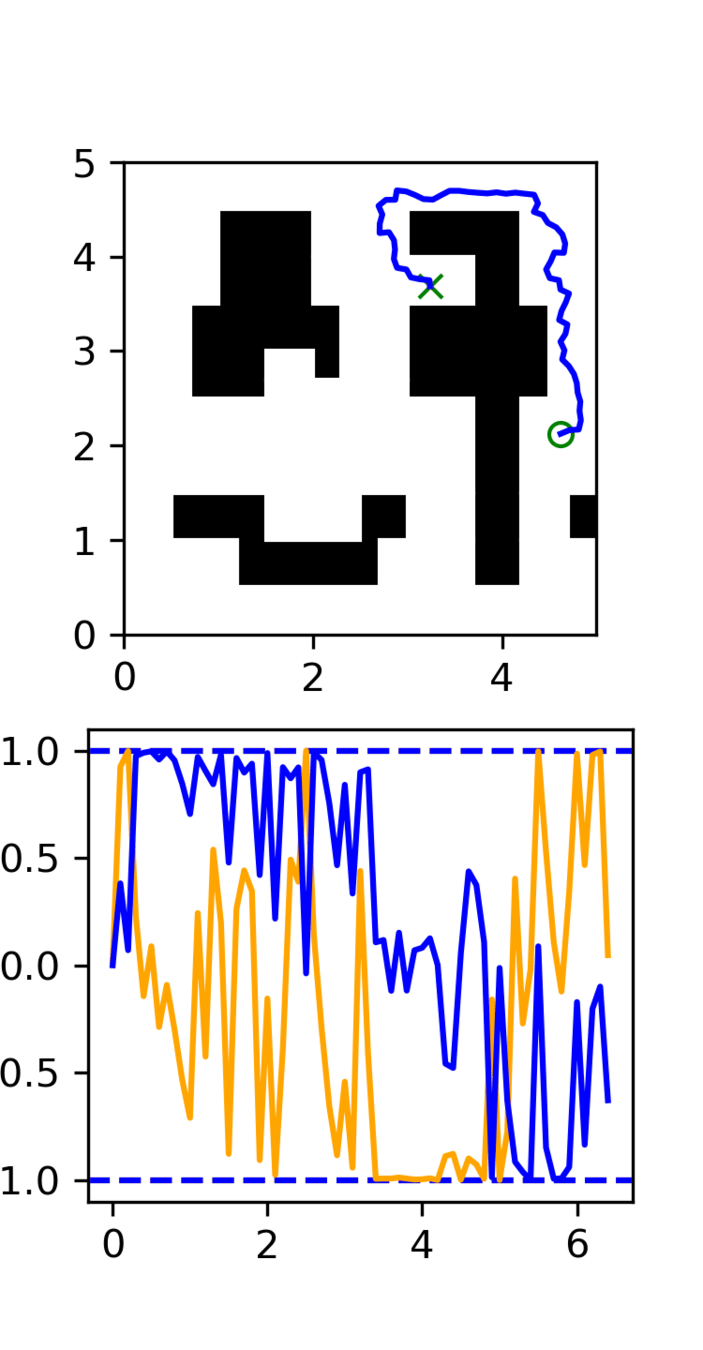
Motion Planning Experiments
Distribution shift: Low-quality, noisy trajectories
High Quality:
100 GCS trajectories
Low Quality:
5000 RRT trajectories
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Task vs Motion Level
Distribution shift: Low-quality, noisy trajectories
\(\sigma=0\)
5000 RRT Trajectories
\(\sigma_{min}\)
\(\sigma=1\)
100 GCS Trajectories
Task level:
learn the maze structure
Motion level:
learn smooth motions
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Implications for Robotics
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
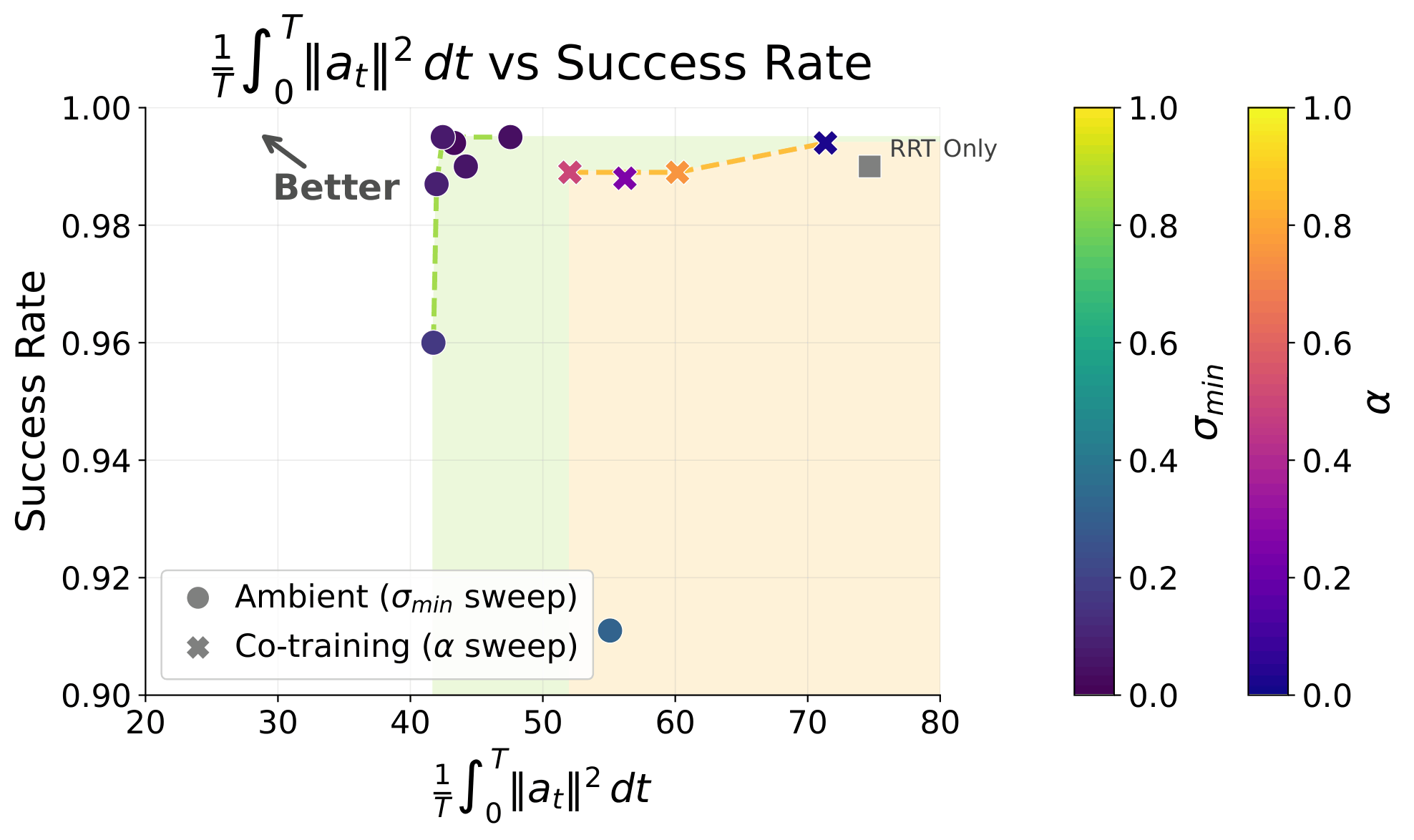
Results
GCS
Success Rate
Avg. Acc^2
(Motion-level)
RRT
GCS+RRT
(Co-train)
GCS+RRT
(Ambient)
57.5%
Swept for best \(\sigma_{min}\) per dataset
Policies evaluated over 1000 trials each
99.0%
141.65
74.8
99.4%
62.2
99.5%
30.9
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Qualitative Results
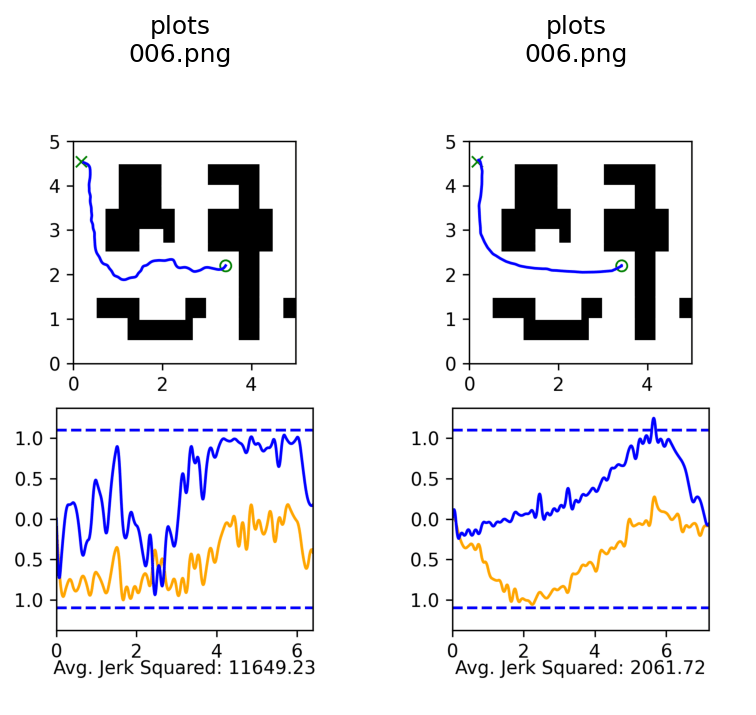
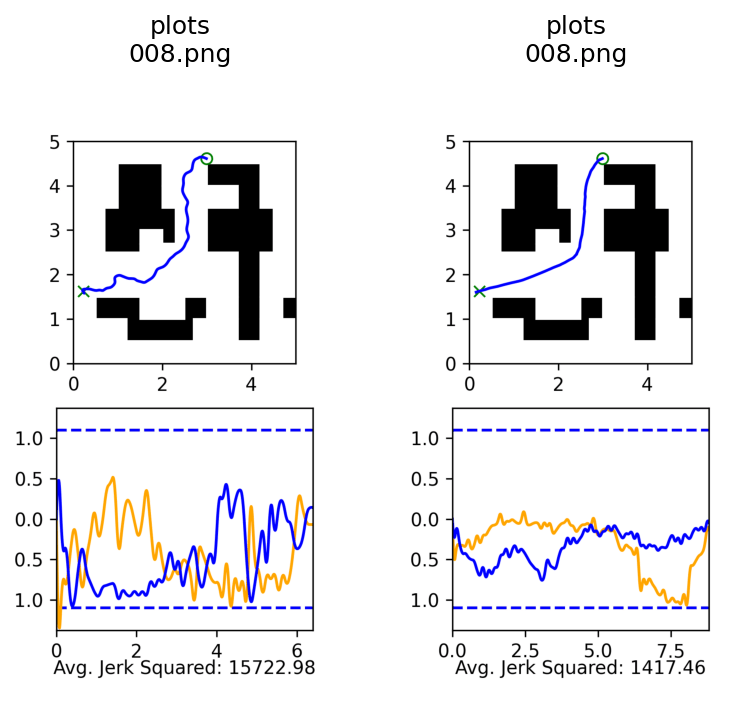
Co-trained
Ambient
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Pareto Front
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
7-DoF Motion Planning
Clean data:
- 100k trajopt trajectories
Corrupt data:
- 1M RRT trajectories
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
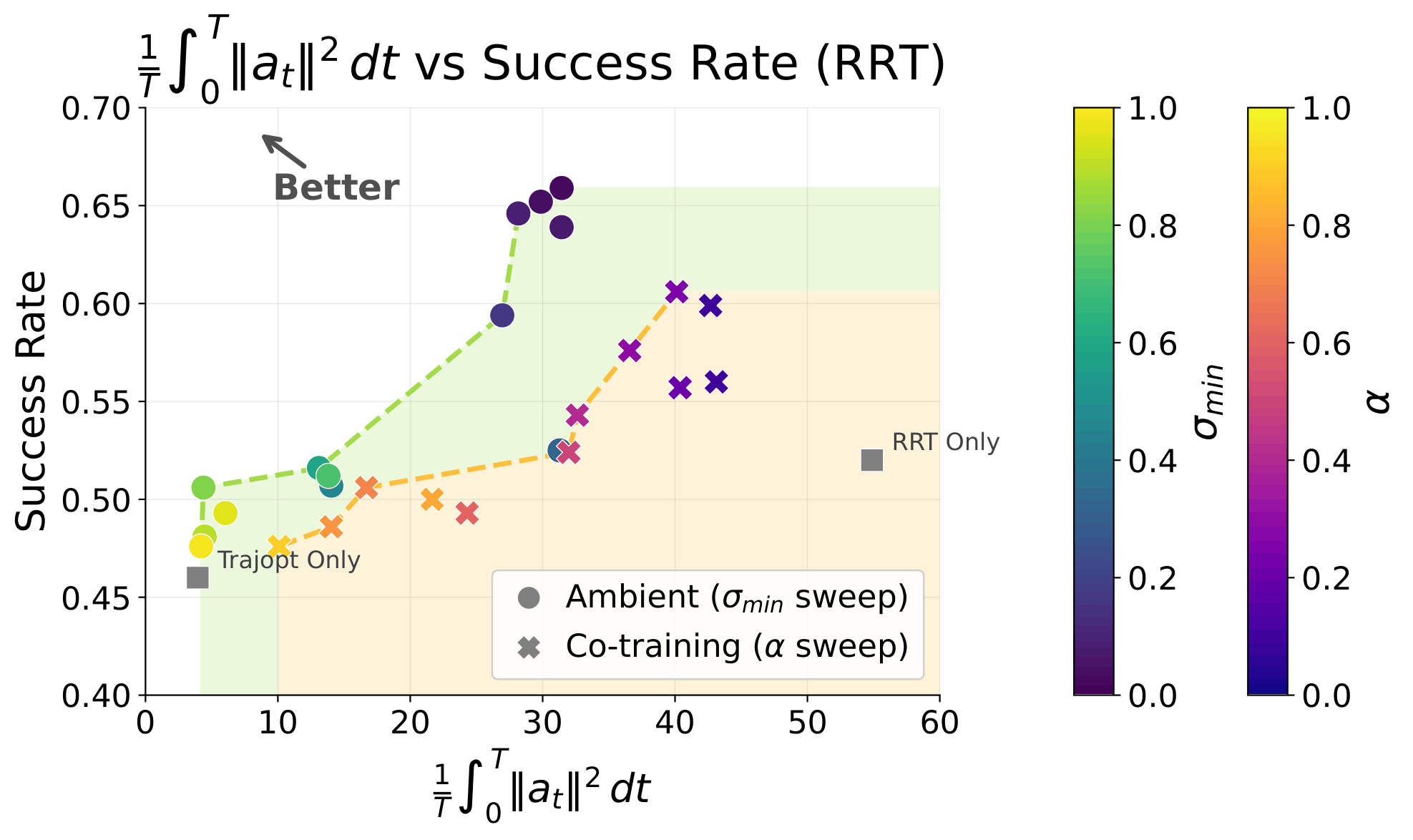
Results
Trajopt
Success Rate
Avg. Acc^2
(Motion-level)
RRT
Trajopt+RRT
(Co-train)
Trajopt+RRT
(Ambient)
46.0%
Swept for best \(\sigma_{min}\) per dataset
Policies evaluated over 1000 trials each
52.0%
3.9
54.9
59.9%
42.7
65.9%
31.4
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
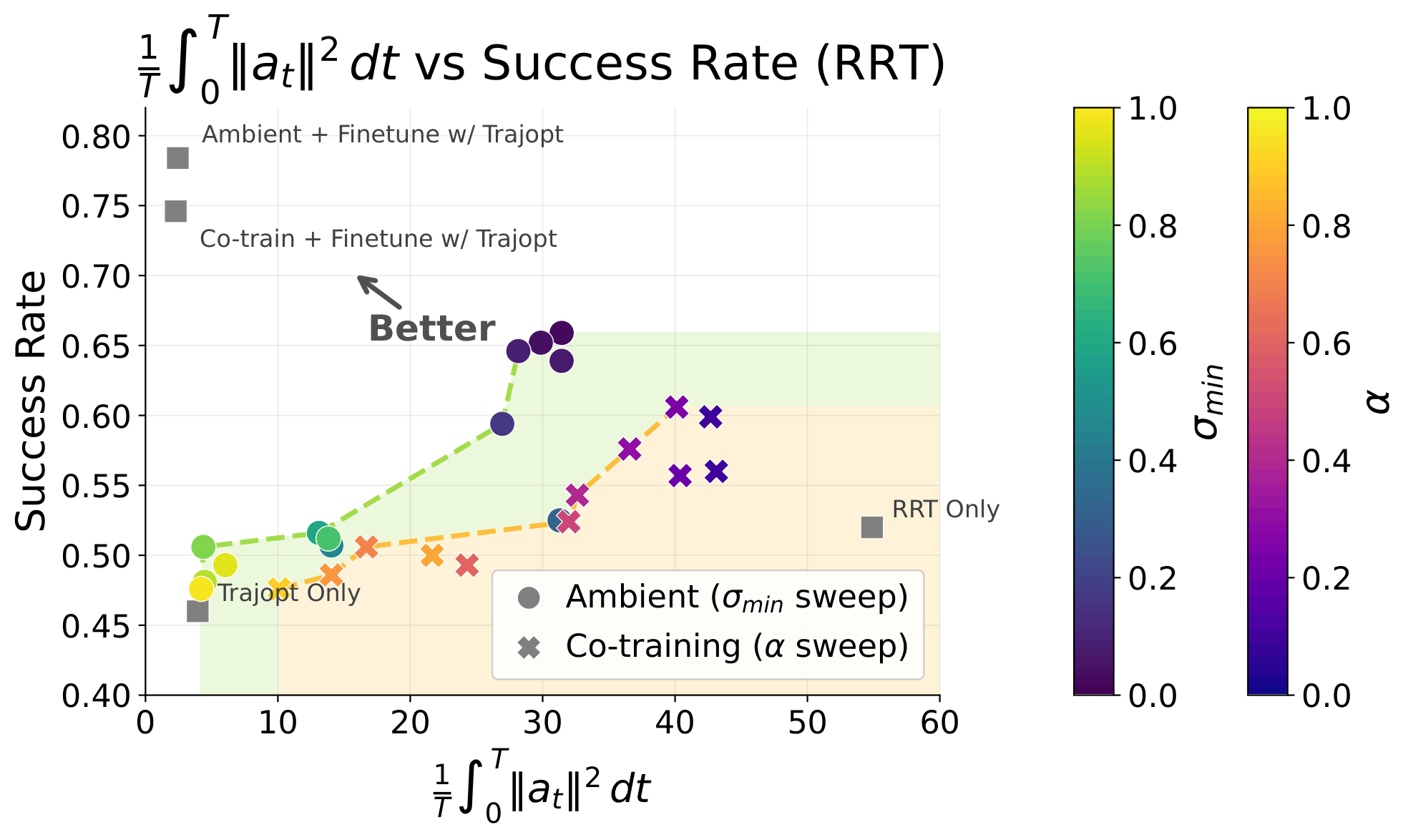
Pareto Front
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Pareto Front
Part 3.5
Sim-and-Real Cotraining
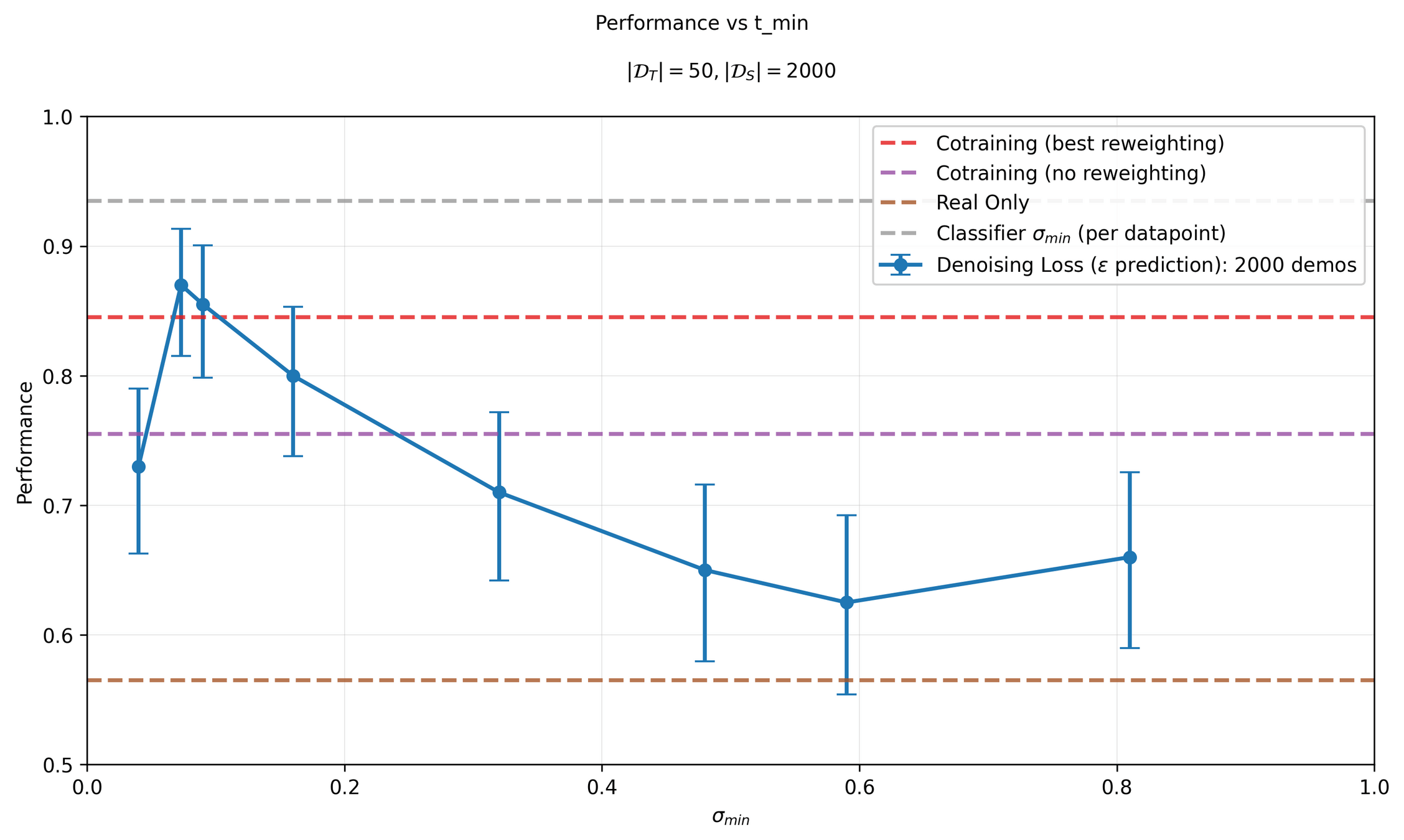
It works!
Best co-trained policy (IROS): 84.5%
Best Ambient policy (CoRL?): 93.5%
Sim & Real Cotraining
Distribution shift: sim2real gap
In-Distribution:
50 demos in "target" environment
Out-of-Distribution:
2000 demos in sim environment
Results
Part 4
Bin Sorting (Locality)
Algorithm Reminder
\(\sigma=0\)
\(\sigma=1\)
"Corrupt" Data
"Clean" Data
\(\sigma_{min}\)
\(\sigma > \sigma_{min}\)
\(\sigma \leq \sigma_{max}\)
"Locality"
\(p_\sigma\) \(\approx\) \(q_\sigma\)
\(\sigma_{max}\)
Locality Only
\(\sigma=0\)
\(\sigma=1\)
"Clean" Data
\(\sigma \leq \sigma_{max}\)
"Locality"
\(\sigma_{max}\)
Goal: isolate the effect of locality in robotics
Example: Bin Sorting
Distribution shift: task level mismatch, motion level correctness
In-Distribution:
50 demos with correct sorting logic
Out-of-Distribution:
200 demos with incorrect sorting
2x
2x
Metics
Robot needs to learn two things:
1. Motion Planning
2. Logic
\(\frac{\#\ blocks \ in \ any \ bin}{total \ blocks}\)
\(\frac{\# \ blocks \ in \ correct \ bin}{\# \ blocks \ \ in \ any bin}\)
Goal: learn motion planning from the bad data, but not the task planning
Success rate:
\(\frac{\# \ blocks \ in \ correct \ bin}{\# \ total \ blocks}\) = (motion planning) x (logic)
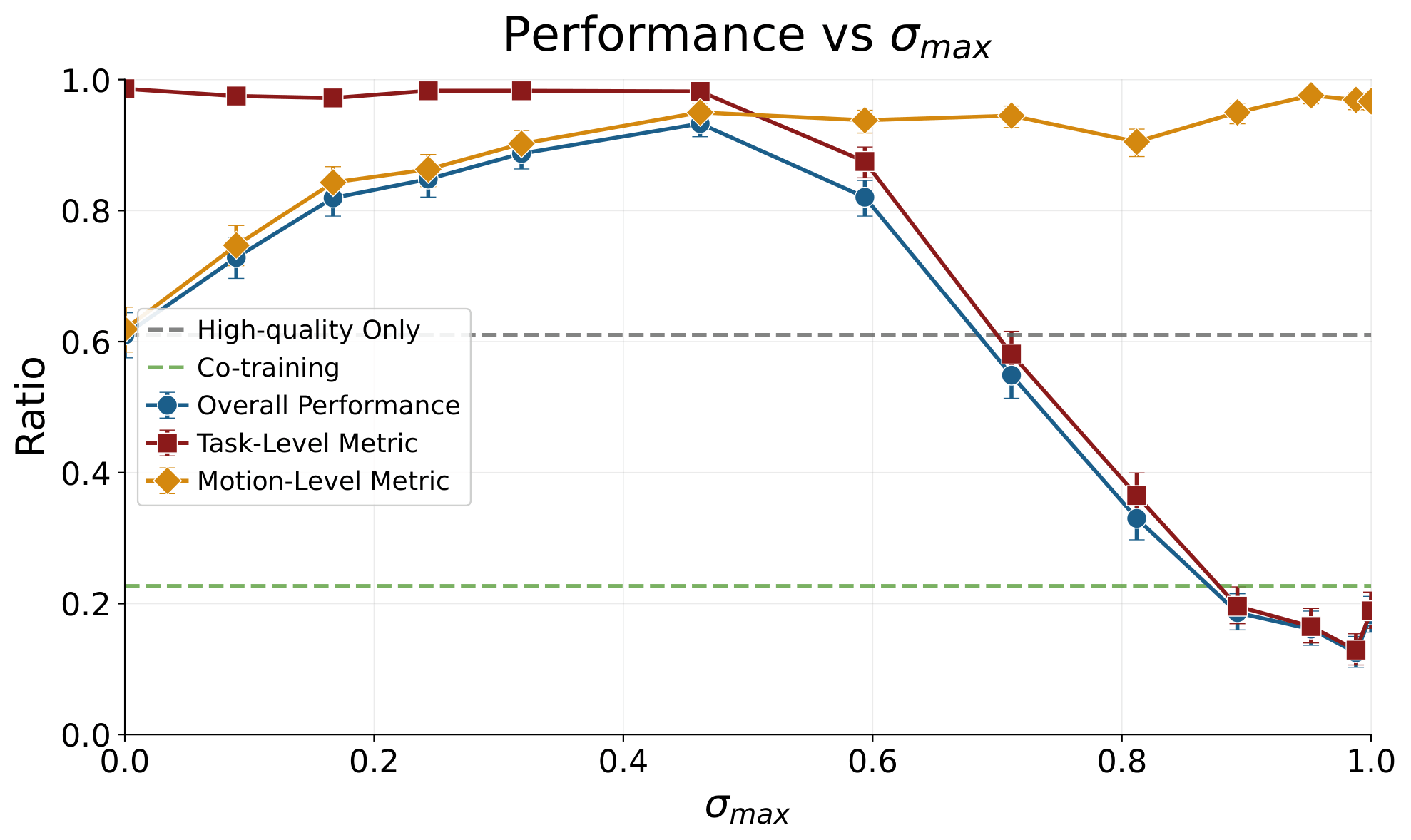
Results
Diffusion
Success Rate
Logic Metric
Cotrain
Motion Metric
Locality
61.0%
61.9%
98.6%
22.7%
87.2%
26.0%
93.3%
95.0%
98.2%
Task Planning
Motion Planning
Pareto Front
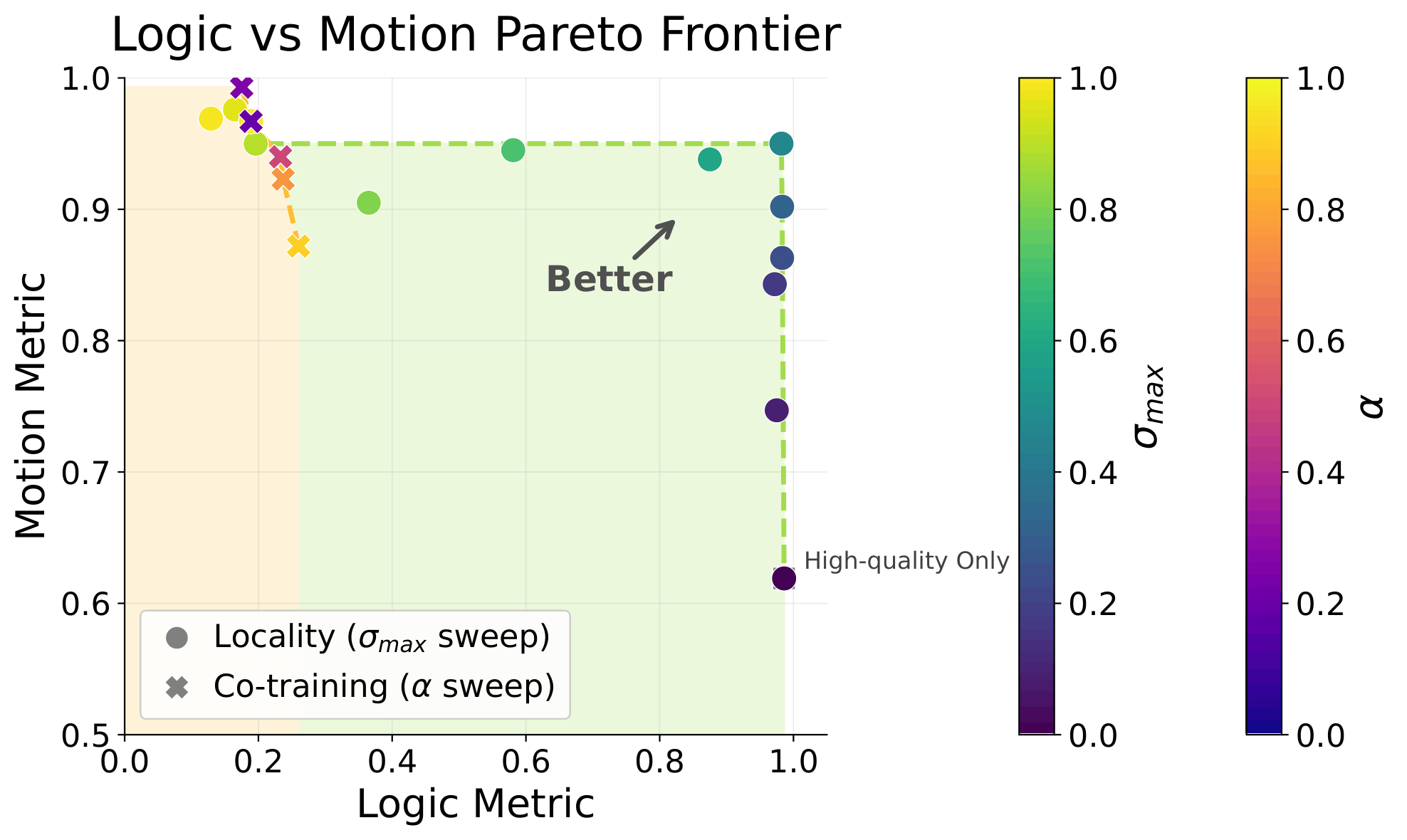
Task Conditioning
Success Rate
Logic Metric
Cotrain
(with task condition)
Motion Metric
Locality
90.3%
91.5%
98.6%
93.3%
95.0%
98.2%
Locality
(with task condition)
92.8%
94.2%
98.5%
Corrupt-only below \(\sigma_{max}\)
\(\sigma=0\)
\(\sigma=1\)
"Clean" Data
\(\sigma \leq \sigma_{max}\)
"Locality"
\(\sigma_{max}\)
Corrupt-only below \(\sigma_{max}\)
Ablation Results
Success Rate
Logic Metric
Ablation
Motion Metric
Locality
91.9%
93.8%
97.9%
93.3%
95.0%
98.2%
Part 5
Real-World Experiments
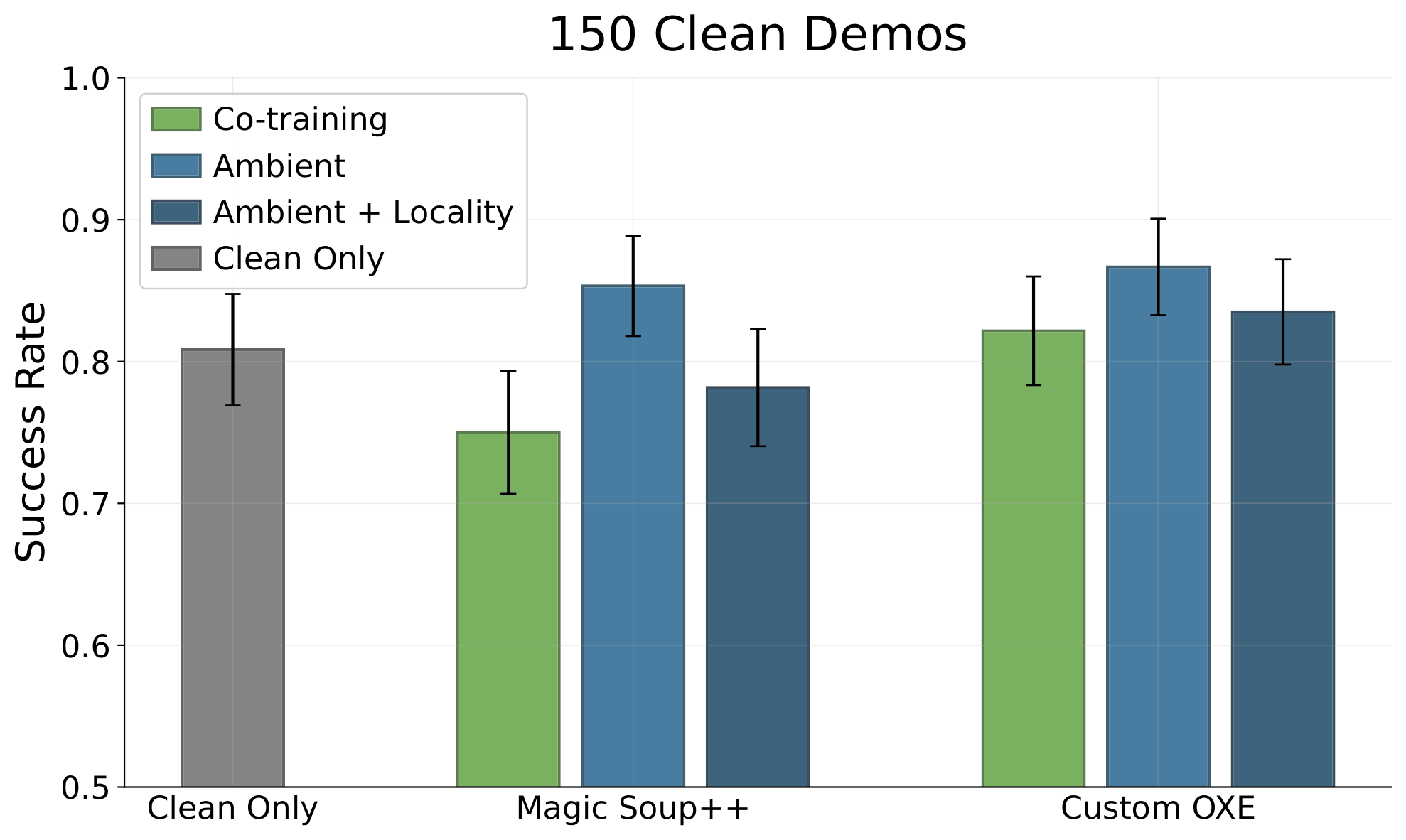
Scaling to Real-World Datasets
Goal: move objects from the table into the drawer
\(\mathcal{D}_{clean}\): 50 in-distribution demos
\(\mathcal{D}_{corrupt}\): Open-X Embodiment
Can we learn from unstructure distribution shifts in large real-world datasets?
Open-X
- cross-embodied
- diff. teleoperators
- sim data!
- mislabeled data
- diff tasks, environments, camera
Task: Table Cleaning
Open-X
Magic Soup++: 27 Datasets
Custom OXE: 48 Datasets
- 1.4M episodes
- 55M "datagrams"
Algorithm
\(\sigma=0\)
\(\sigma=1\)
"Clean" Data
\(\sigma_{min}\)
\(\sigma > \sigma_{min}\)
"Ambient"
"Ambient
+ Locality"
"Clean" Data
\(\sigma_{min}\)
\(\sigma > \sigma_{min}\)
\(\sigma \leq \sigma_{max}\)
\(\sigma_{max}\)
Task: Table Cleaning


Task completion =
0.1 x [opened drawer]
+ 0.8 x [# obj. cleaned / # obj.]
+ 0.1 x [closed drawer]
Results
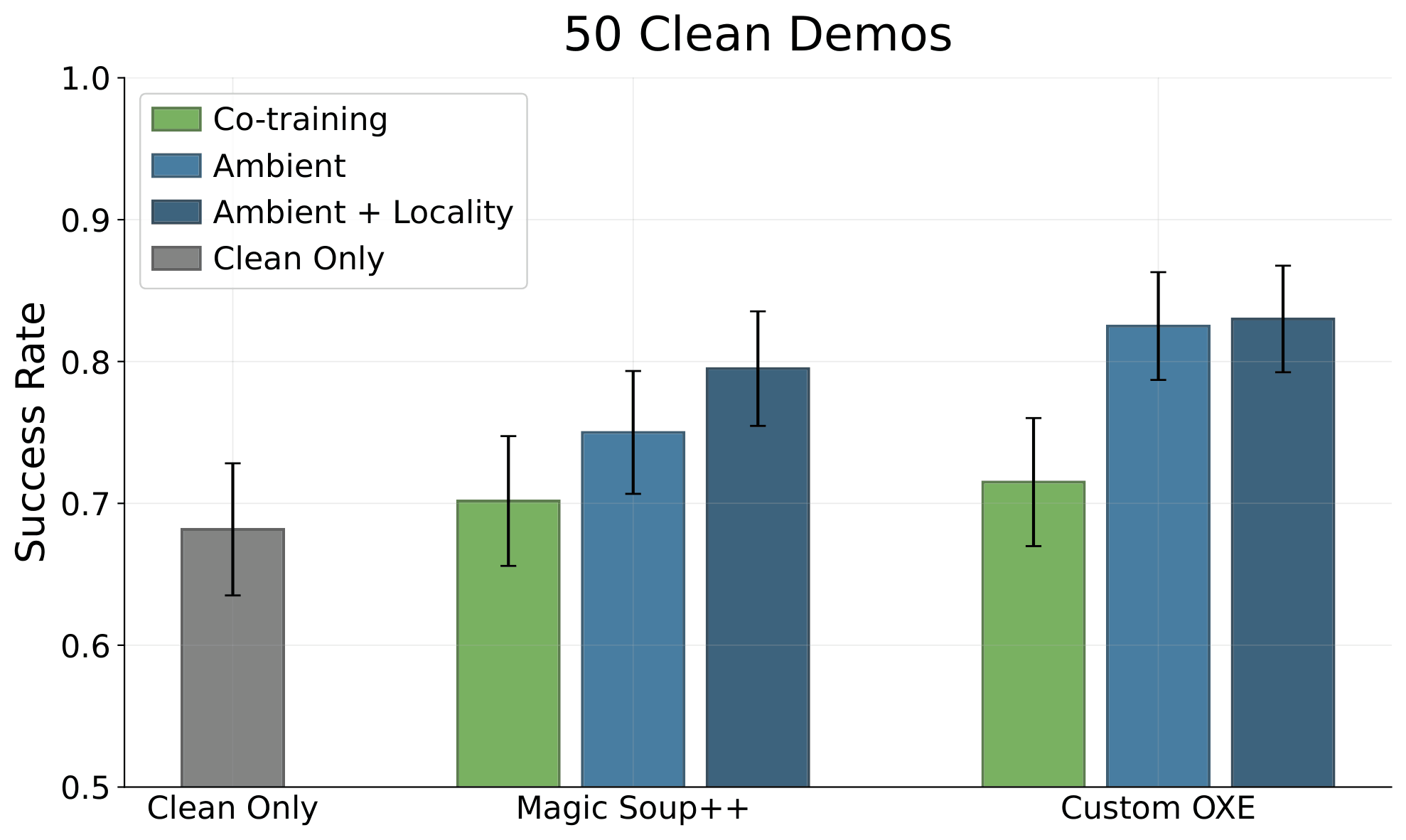
Results
Ablations: Reweighting
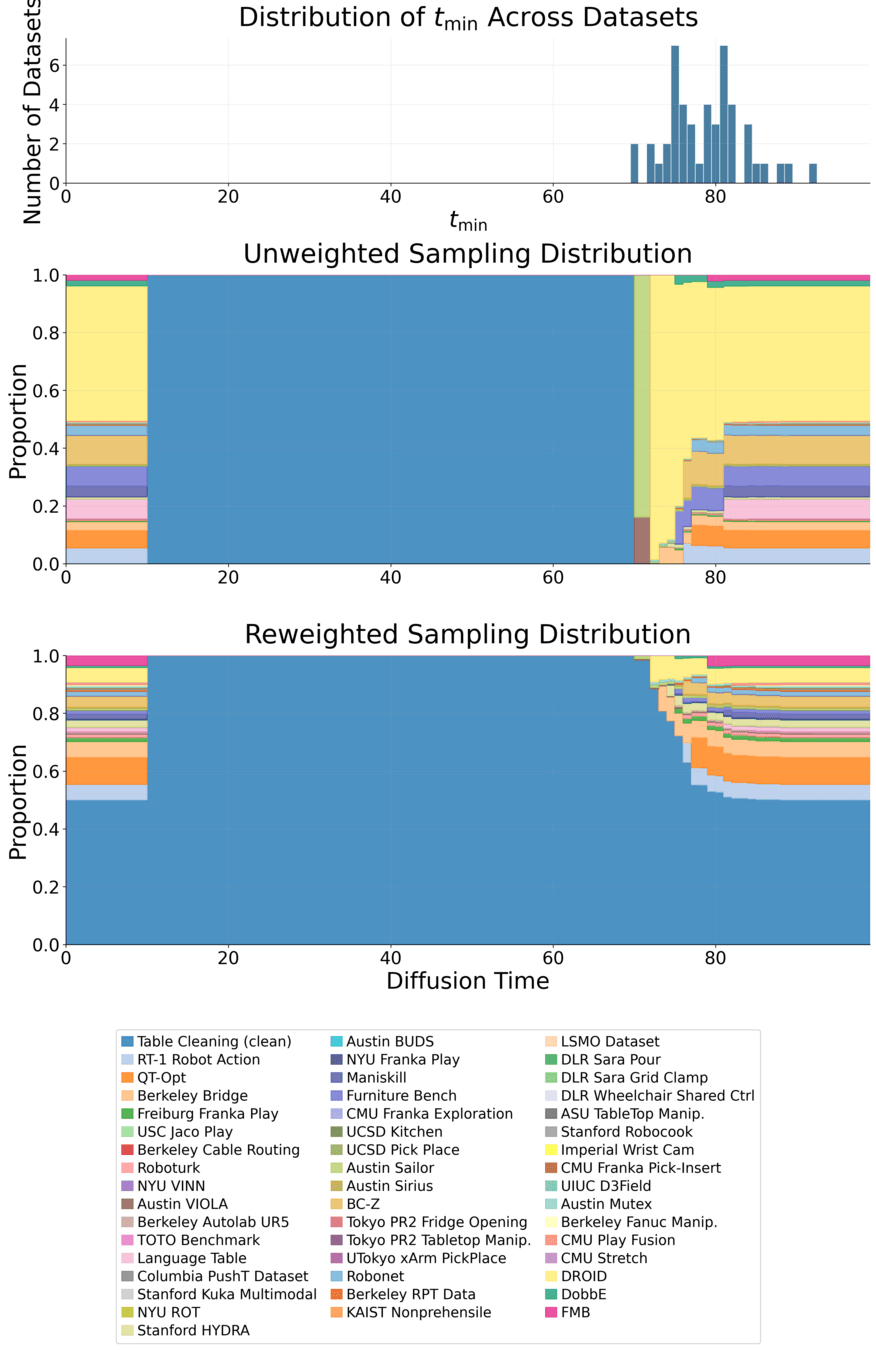
Ablations: Reweighting
Ablations: Reweighting
1. Ambient benefits from reweighting, but does not need it.
Note: Ambient and reweighting are orthogonal (can be applied simultaneously)
2. Co-training must reweight.
Ablations: Finetuning
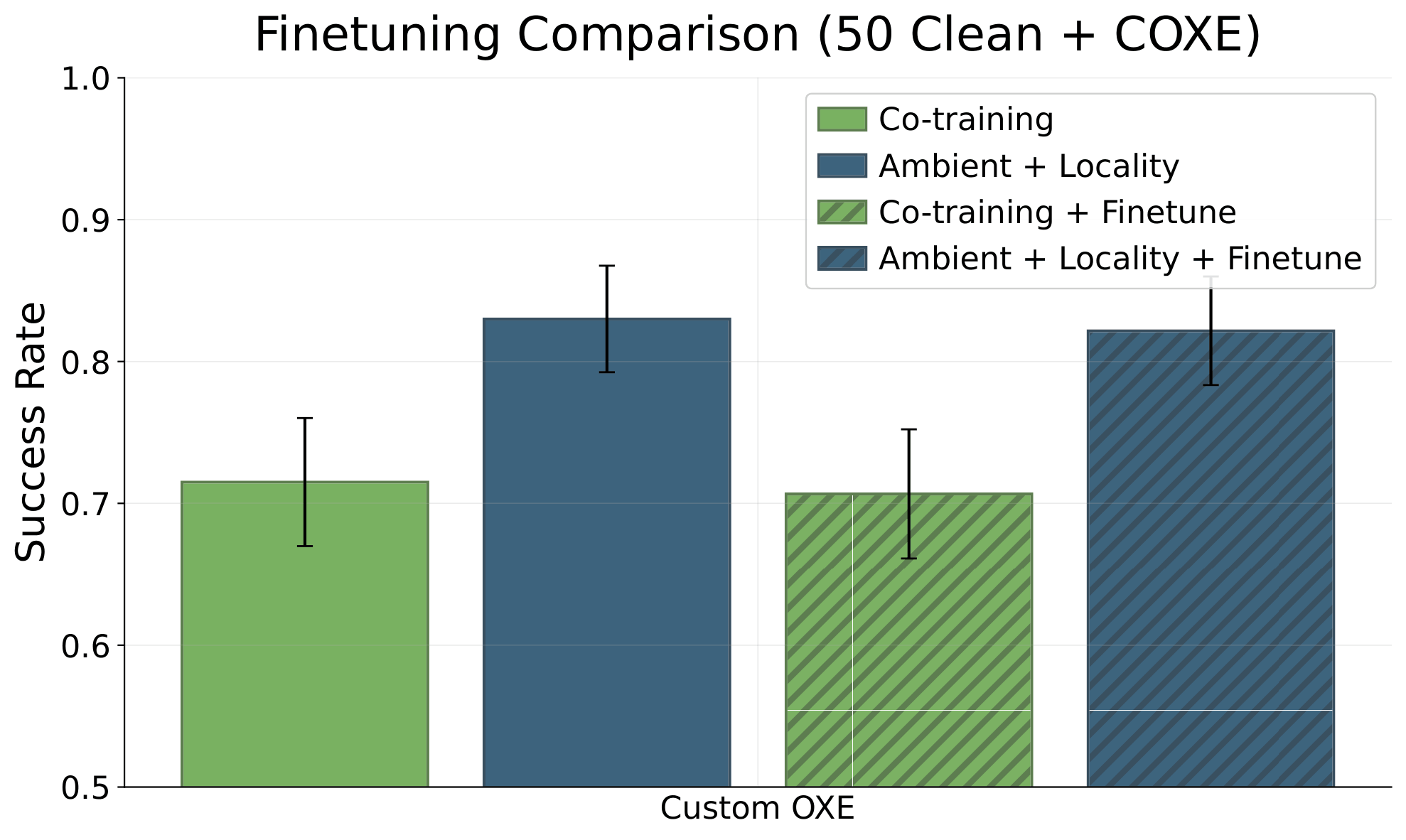
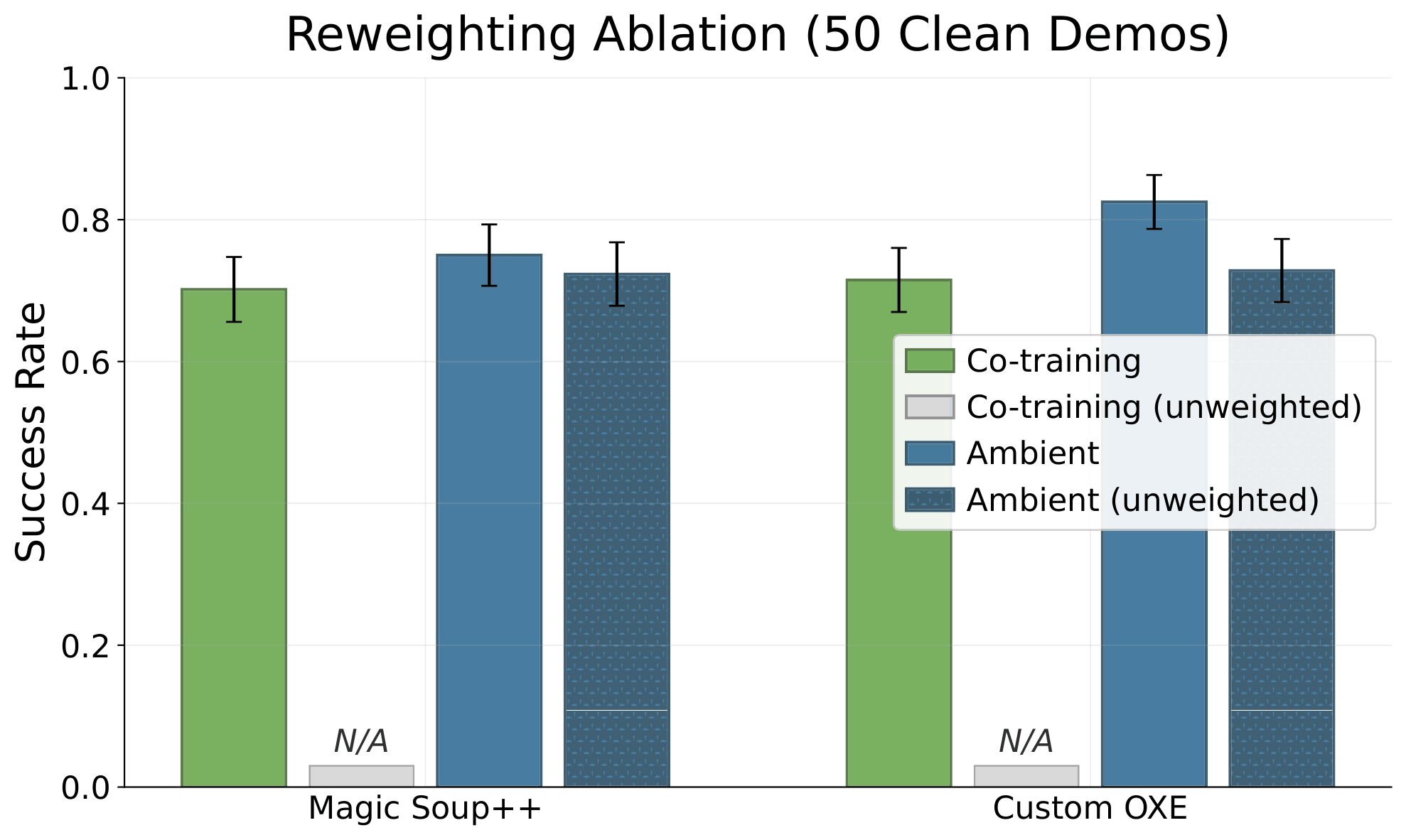
Ablations: Finetuning
Ablations: Finetuning
1. Finetuning the Ambient base model is always better
2. When good data is limited, ambient outperforms co-train + finetune
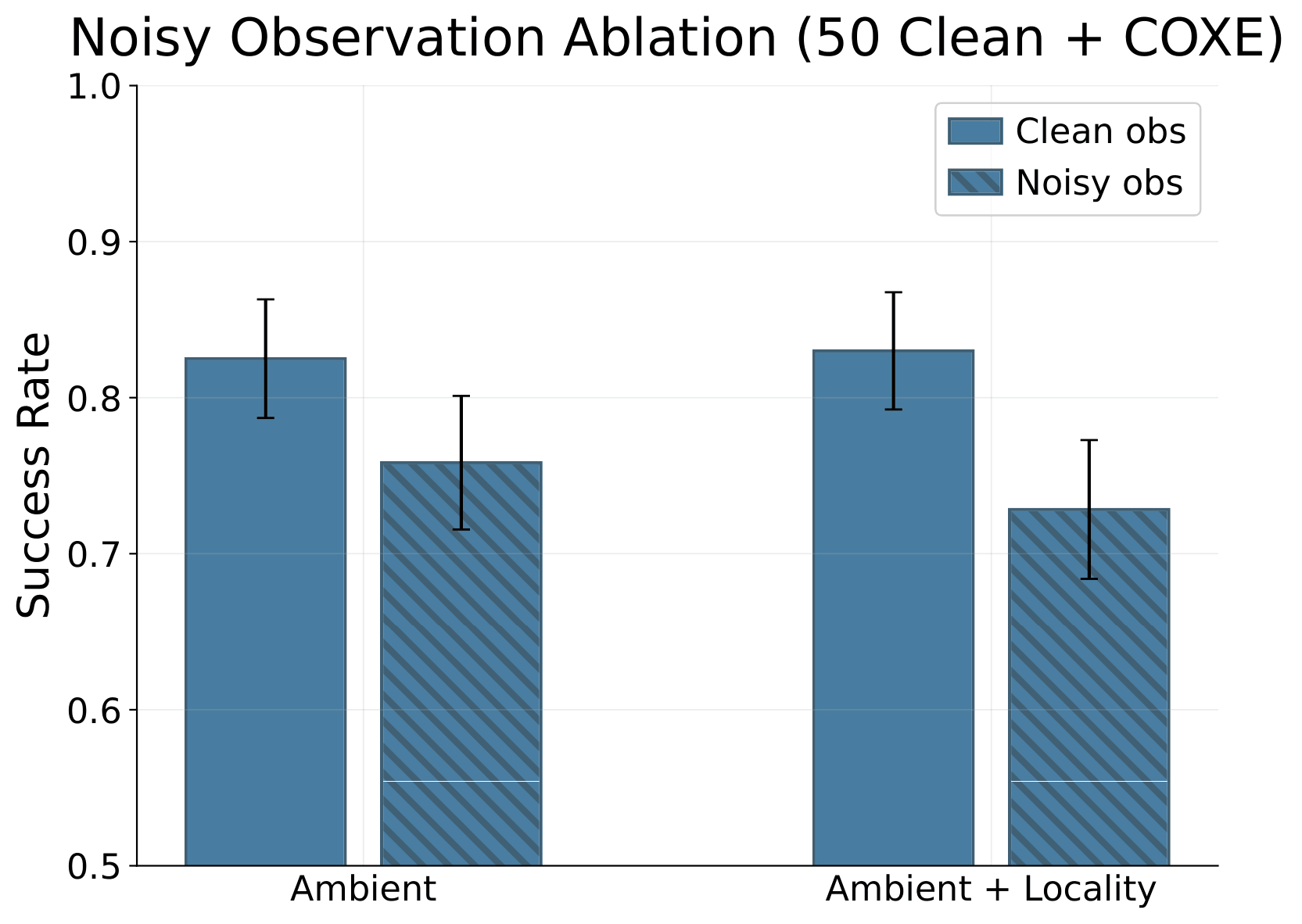
Ablations: Noisy Observations
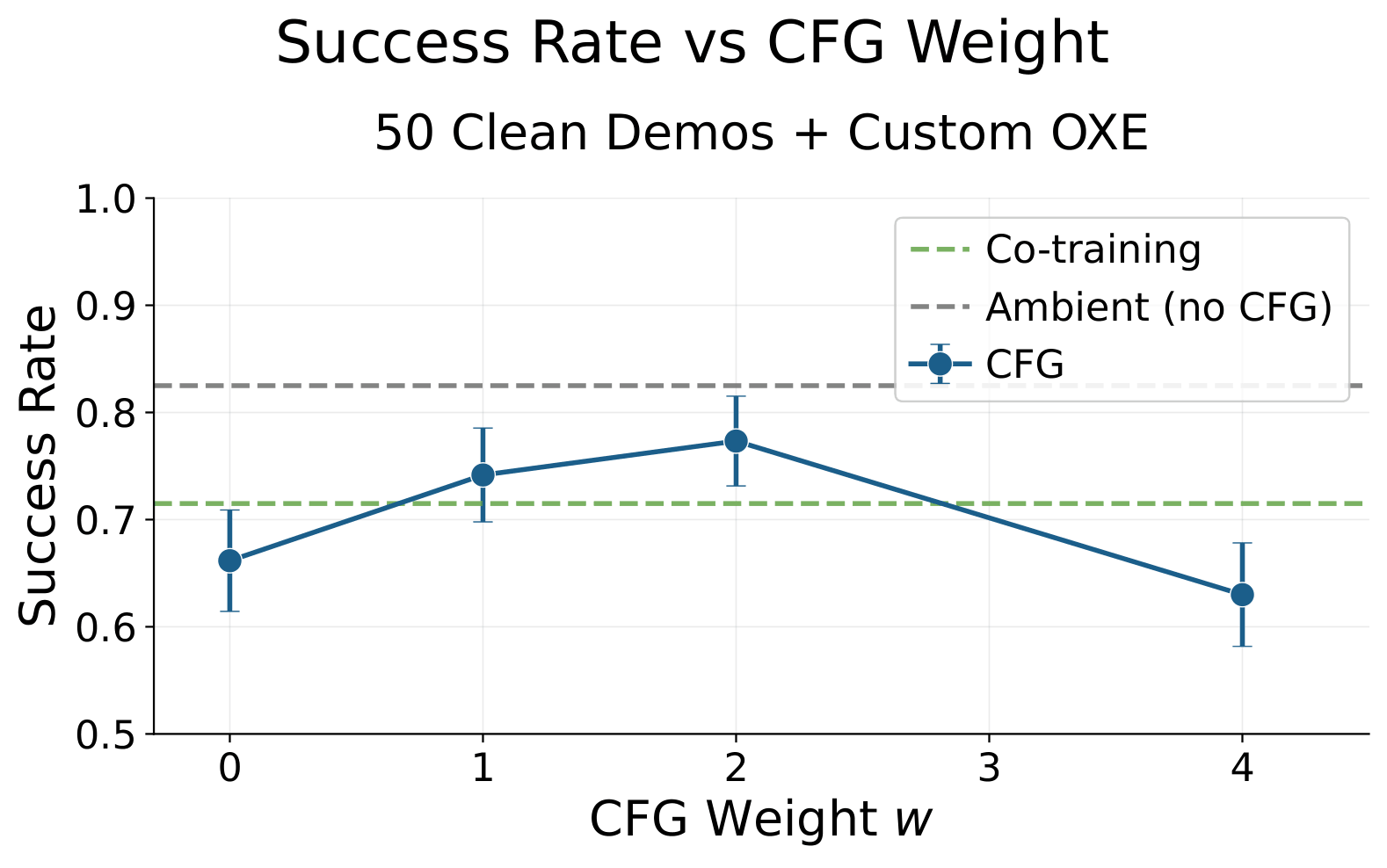
Ablations: CFG
Part 6
Concluding Thoughts
Concluding Thoughts
- Sim2real gaps
- Noisy/low-quality teleop
- Task-level mismatch
- Changes in low-level controller
- Embodiment gap
- Camera models, poses, etc
- Different environment, objects, etc
Ambient can be used to learn from any distribution shift in robotics
In-Distribution Data
Open-X
simulation
Out-of-Distribution Data
Next Directions
Q: What is "in-distribution"?
A [in this paper]: expert teleoperator on your robot, your task, your environment
A [more generally]: data quality?
How you define "in-distribution" changes if Ambient is used as pre-training or finetuning recipe
Next Directions
- Defining "in-distribution"
- Picking \(\sigma_{max}\), \(\sigma_{min}\)
- Rejection sampling idea [Kerem]
- Soft ambient [Pablo/Asu]
- Corruption in observation space
- Extending to Flows
- Ambient for video/latent actions