JEPA: Joint Embedding Predictive Architecture
Apr 3, 2026
Adam Wei
Agenda
1. Methods for representation learning
2. JEPAs
3. I-JEPAs
4. V-JEPA 2 and Robotics
Today's Goal!
Representation Learning
Every figure in this talk is taken from either the JEPA or the V-JEPA 2 paper
"Invariance Methods"
"Generative Methods"
Invariance Methods
ex. CLIP, contrastive loss, BYOL, MoCo, etc
Limitation: encoding for \(x\) and \(y\) are invariant under some transform
... but what transform?
\(f_{\theta}(x) \approx f_{\theta}(T(x))\)
Generative Methods
ex. VAE, BERT, MAE
Limitation: embeddings are less semantic
- must encode pixel-level details
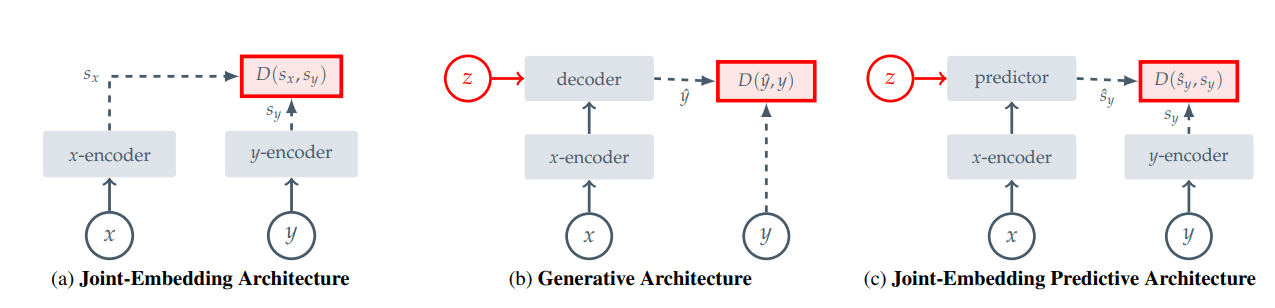
JEPA
not pixel-level!
\(\implies\) semantic
I-JEPA

Sampling \(s_y\) ("Targets")
\(B_1\)
\(\xrightarrow{f_{\bar \theta}} s_y(1)\)
\(B_2\)
\(\xrightarrow{f_{\bar \theta}} s_y(2)\)
\(B_3\)
\(\xrightarrow{f_{\bar \theta}} s_y(3)\)
\(B_4\)
\(\xrightarrow{f_{\bar \theta}} s_y(4)\)
\(s_y(i)\) are the targets for prediction!
Sampling \(s_x\) ("Context")
\(s_x\)
\(B_x = \) crop \(\setminus \{{s_y(i)\}_{i\in [M]}}\)
\(B_x\xrightarrow{f_{\theta}} s_x\)
\(s_x\)
Prediction: \(\hat s_y = g_\phi(s_x, z)\)
For all \(M\) targets, \(s_y(i)\)
\(\hat s_y(i) = g_\phi(s_x, z_i)\)
\(z_i\) is a learnable mask corresponding to \(B_i\)
\(s_x\)
Objective Function
Minimize:
\(\frac{1}{M} \sum_{i=1}^M D(\hat s_y(i), s_y(i)\))
\(D(\cdot, \cdot)\) is essentially \(\ell_2\)*
*\(\ell_1\) for V-JEPA
Full Picture
\(\xrightarrow{f_{\theta}} s_x\)
\(\xrightarrow{f_{\bar \theta}} s_y(i)\)
\(\xrightarrow{g_\phi(s_x, z_i)} \hat s_y(i)\)
\(D(\hat s_y(i), s_y(i))\)
"Target"
"Context"
Training
\(g_\phi\)
\(f_\theta\)
\(f_{\bar \theta}\)
Learn \(\theta\) and \(\phi\) with gradient descent
\(\bar \theta = \mathrm{EMA}(\theta)\)
Use \(f_{\bar \theta}\) for downstream tasks
V-JEPA 2-AC
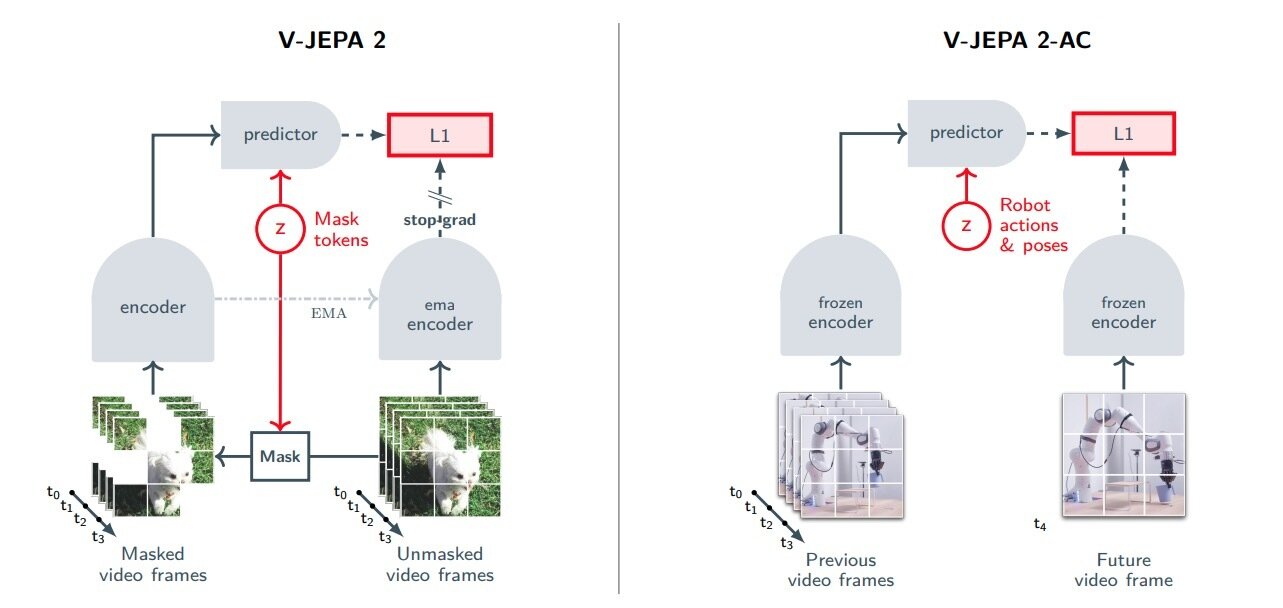
V-JEPA 2
"world model"
V-JEPA 2-AC
Predictor
Inputs:
- prev frames embeddings
- robot actions
Output:
- next frame embedding
Predictor is our world model!
Planning with World Model
Planning:
- Cross Entropy Method
- Execute actions in MPC-like fashion
Results:
- reach goal, pick & place
- it's ok I guess... (see paper)
[Current] Limitations
- Slow (16s per action)
- Unstable long-horizon rollouts
- Limited to "greedy" tasks
- Requires goal image
- Compares against weak baselines
- Sensitive to long horizon planning
Some of these limitations seem surmountable?
Thanks!
