IROS Submission & Next Directions
RLG Short Talk
Mar 13, 2025
Adam Wei
Agenda
- Subset of new experiments
- Next directions for cotraining

Policy:

Performance Objective:
Success rate on a planar pushing task
Diffusion Policy [2]

Sim-and-Real Cotraining
Cotraining: Use both sim and real datasets to train a policy that maximizes some real-world performance objective
Sim-and-Real Cotraining
50 real demos
50 real demos
2000 sim demos
Success rate: 10/20
Success rate: 18/20
2x
2x
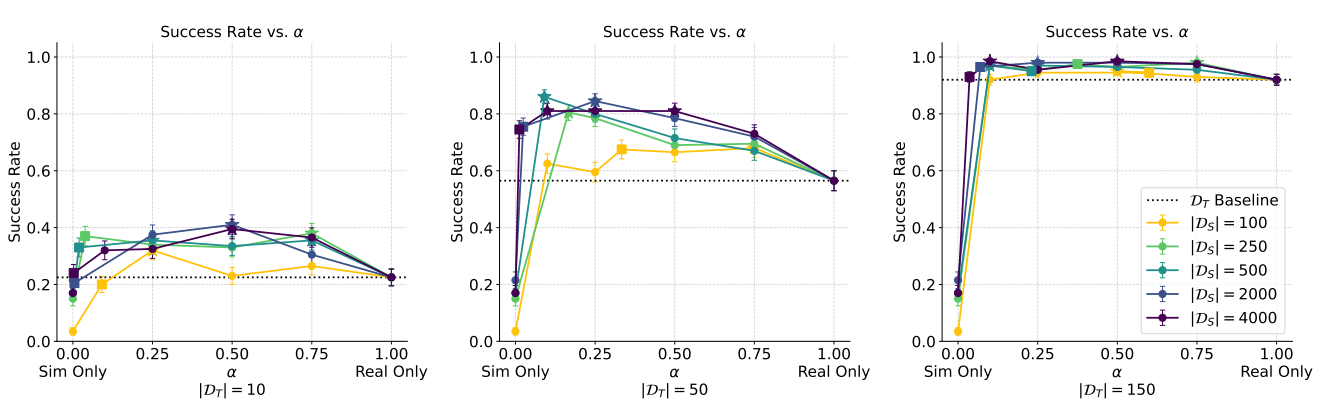
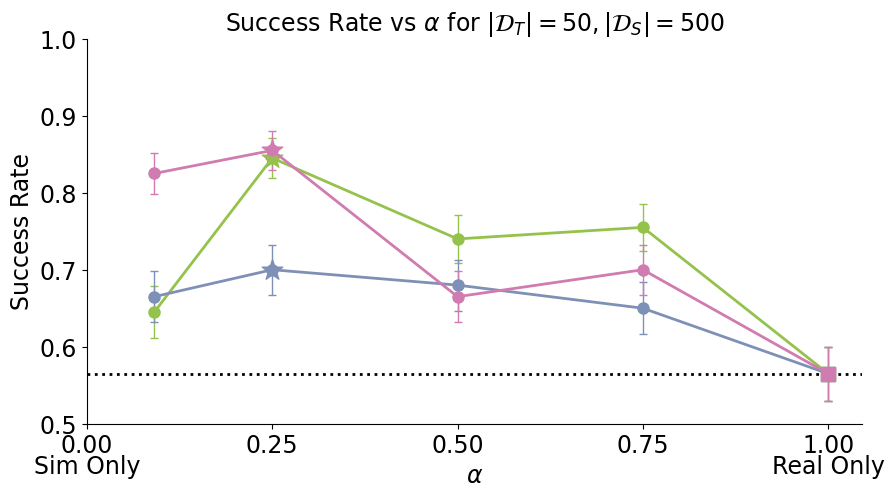
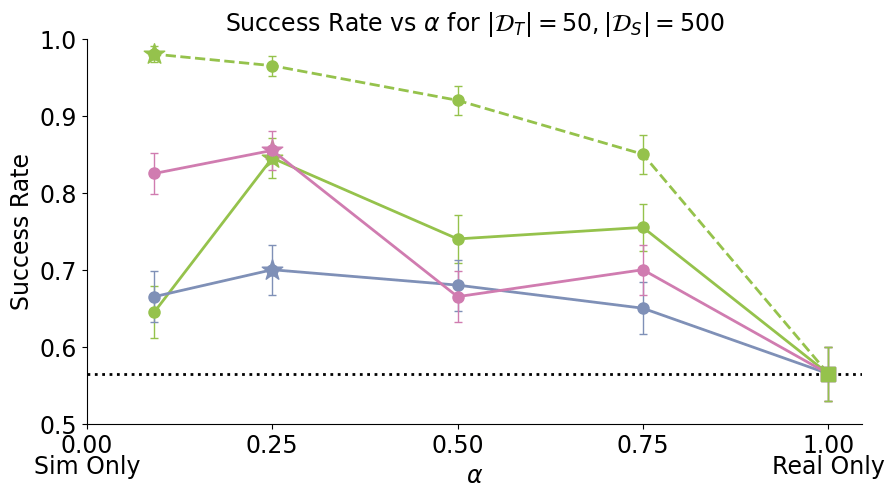
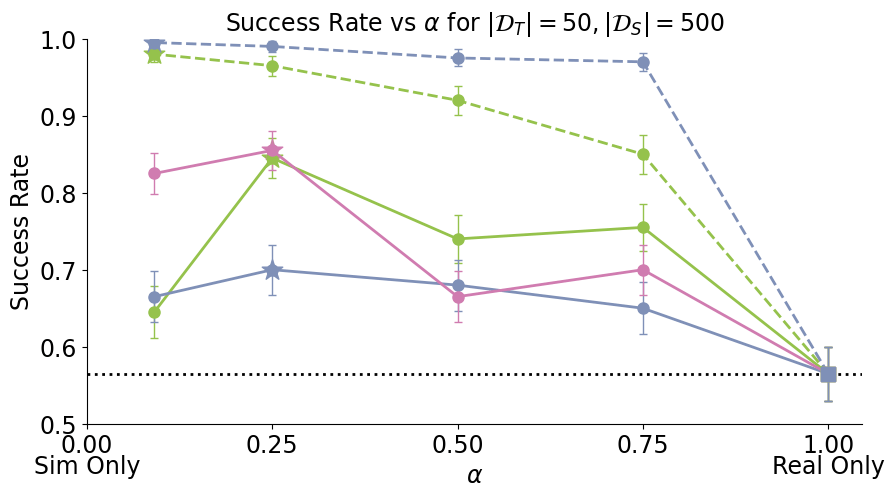
- Cotraining improves policy performance by up to 2-7x
- Scaling sim data improves performance and reduces sensitivity to \(\alpha\)
SDE Interpretation
Advantages of Simulation
- Performance gains from scaling sim data plateau; additional real data raises the performance ceiling
New Experiments
Simulation
- Scaling sim data
- Finetuning
- Distribution shifts
Analysis
- Sim-and-real discernability
- Data coverage
- Power laws
- Classifier-free guidance
Simulation Experiments
Key idea: Create two different simulated environments and emulate the sim2real gap.
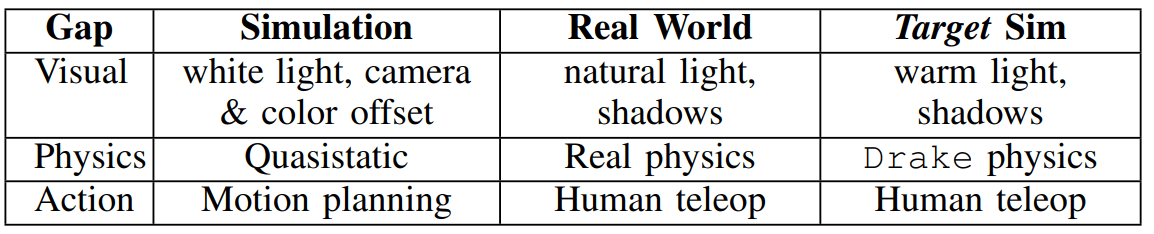
target sim environment emulates the real-world
Sim provides better eval and control over sim2target gap
sim2real gap
sim2target gap
SDE Interpretation
Distribution Shifts

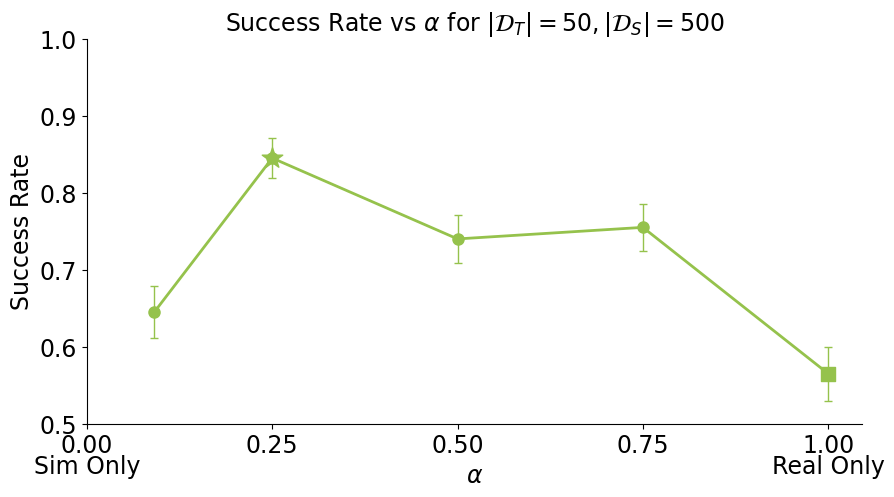
How do visual, physics, and task shift on performance?
Paradoxically, some visual shift is required for good performance!
Physics and task shift are most impactful for downstream performance.
SDE Interpretation
Sim-and-Real Discernability
Real-World Demo
Policy Rollout
(Cotrained)
Simulated Demo
- Fix orientation, then translation
- Sticking & sliding contacts
- Similar to real-world demos
- Fix orientation and translation simultaneously
- Sticking contacts only
2x
2x
2x
SDE Interpretation
Sim-and-Real Discernability
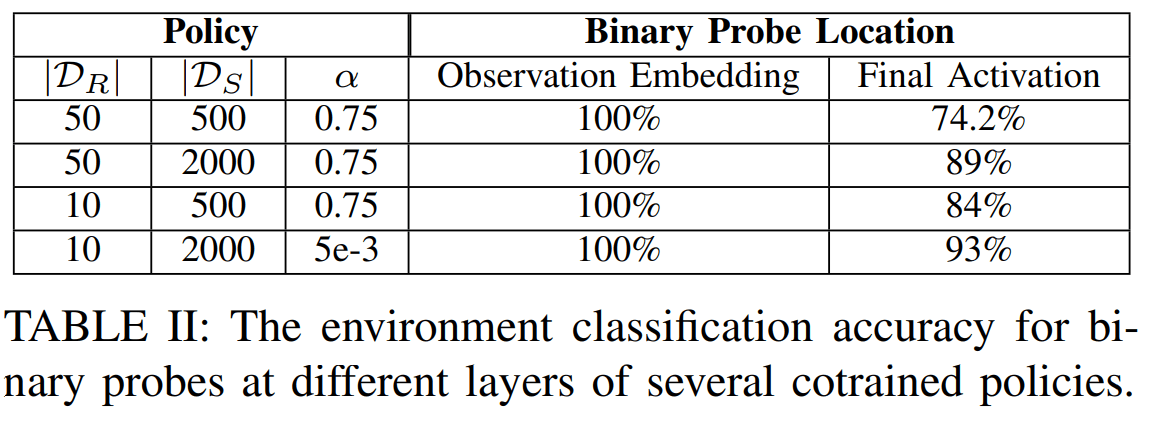
SDE Interpretation
Sim-and-Real Discernability
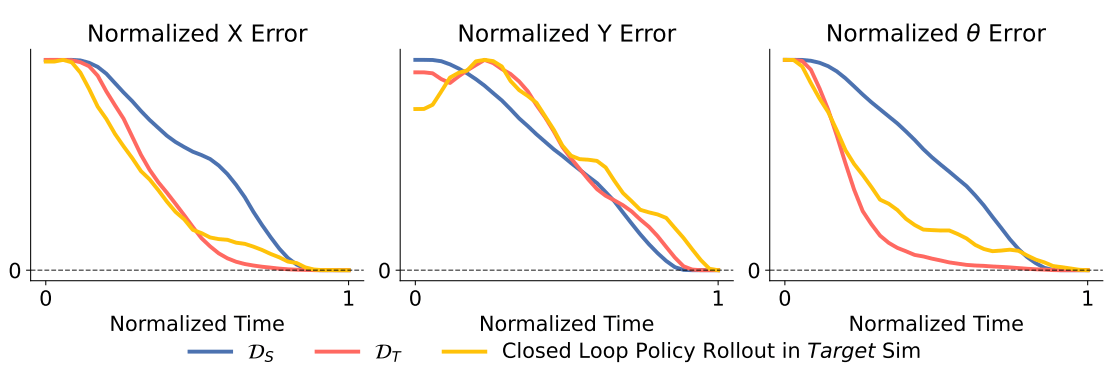
High-performing policies must learn to identify sim vs real
since the physics of each environment requires different actions
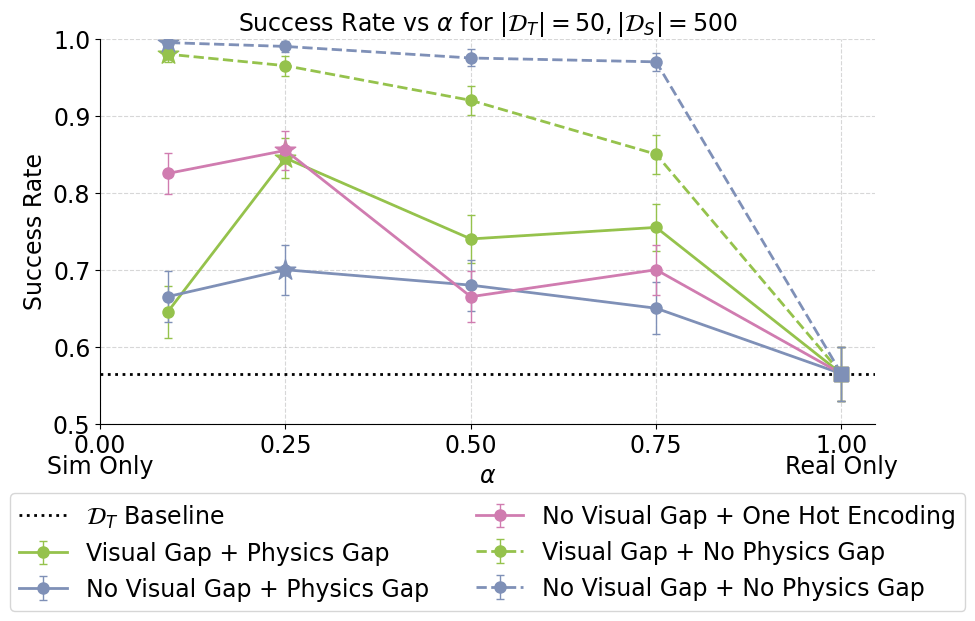
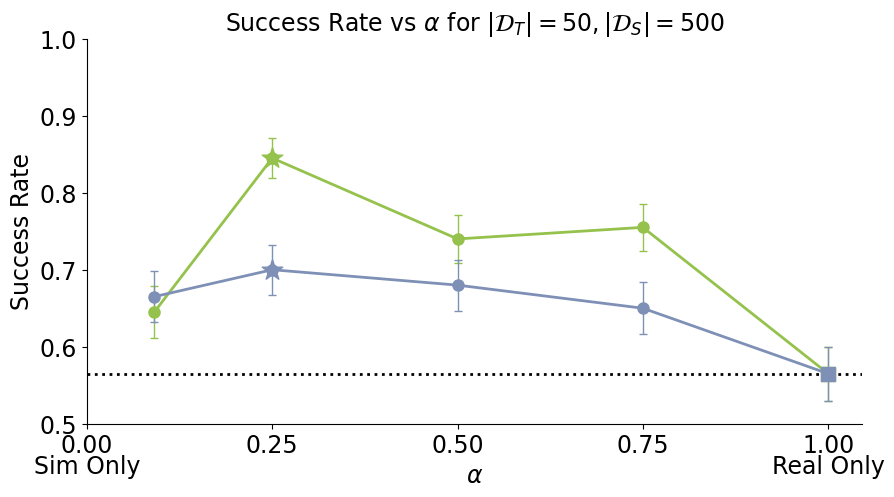
SDE Interpretation
Positive Transfer & Power Laws
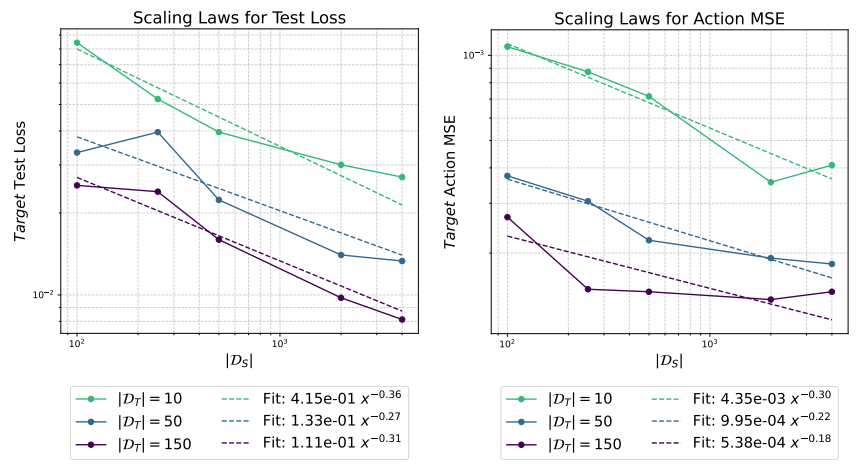
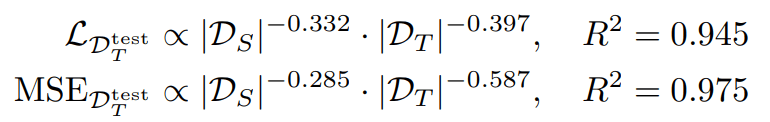
\(\implies\)
Sim demo worth 0.83 real demos
Sim demo worth 0.49 real demos
SDE Interpretation
Next Directions
- Reducing sim2real gap at the representation level
- Cotraining from corrupt (sim) data
Reducing sim2real
Conclusions
- Reducing sim2real gap improves performance
- Preserving sim-and-real discernability is important
Is there a training formulation that simultaneously:
- Learns domain invariant representations
- Preserves sim-and-real discernability?
Cotraining Formulation
Intuitively, this objective:
- Minimizes the sim2real gap in the learned representation
- Preserves domain-specific features that are relevant for control (i.e. minimizing \(\mathcal L_{\mathcal D^\alpha}\))
denoiser loss
sim2real loss
Adversarial Formulation
Adversarial formulation:
Adversarial Formulation
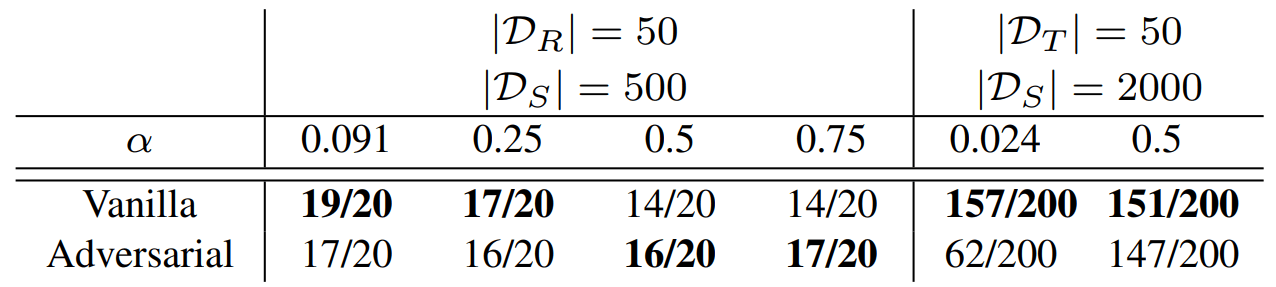
Challenges: Great in theory, but GANs are hard to train...
... this is not the path to happiness in robotics
MMD Formulation
MMD Formulation:
MMD is differentiable* and does not require a max operation!
Learning From Corrupt Data
Corrupt Data
High Quality Data
Computer Vision
Language


Social media, etc


There exist theoretically sound algorithms for cotraining on both corrupt and high-quality data

Learning From Corrupt Data
Corrupt Data
High Quality Data
Protein Folding
Robotics?

Sim Data
Real Data

+ 5 years
=