ARDC Community Data Lab
GLAM Workbench
Workspaces for analysis & exploration
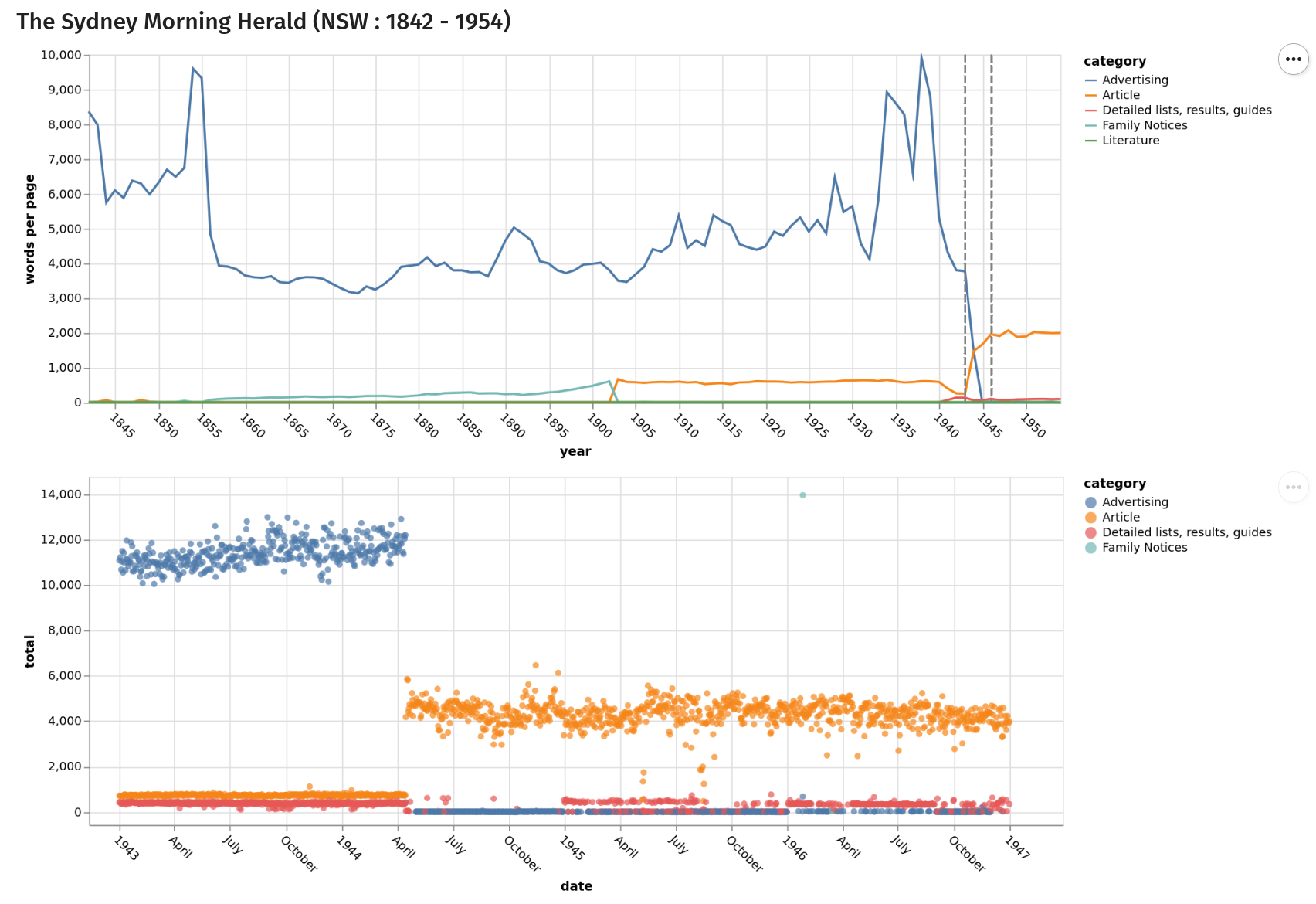
These slides
Community Data Lab
Trove Data Guide
GLAM Workbench
architectures
standards
technologies
principles
GLAM Workbench
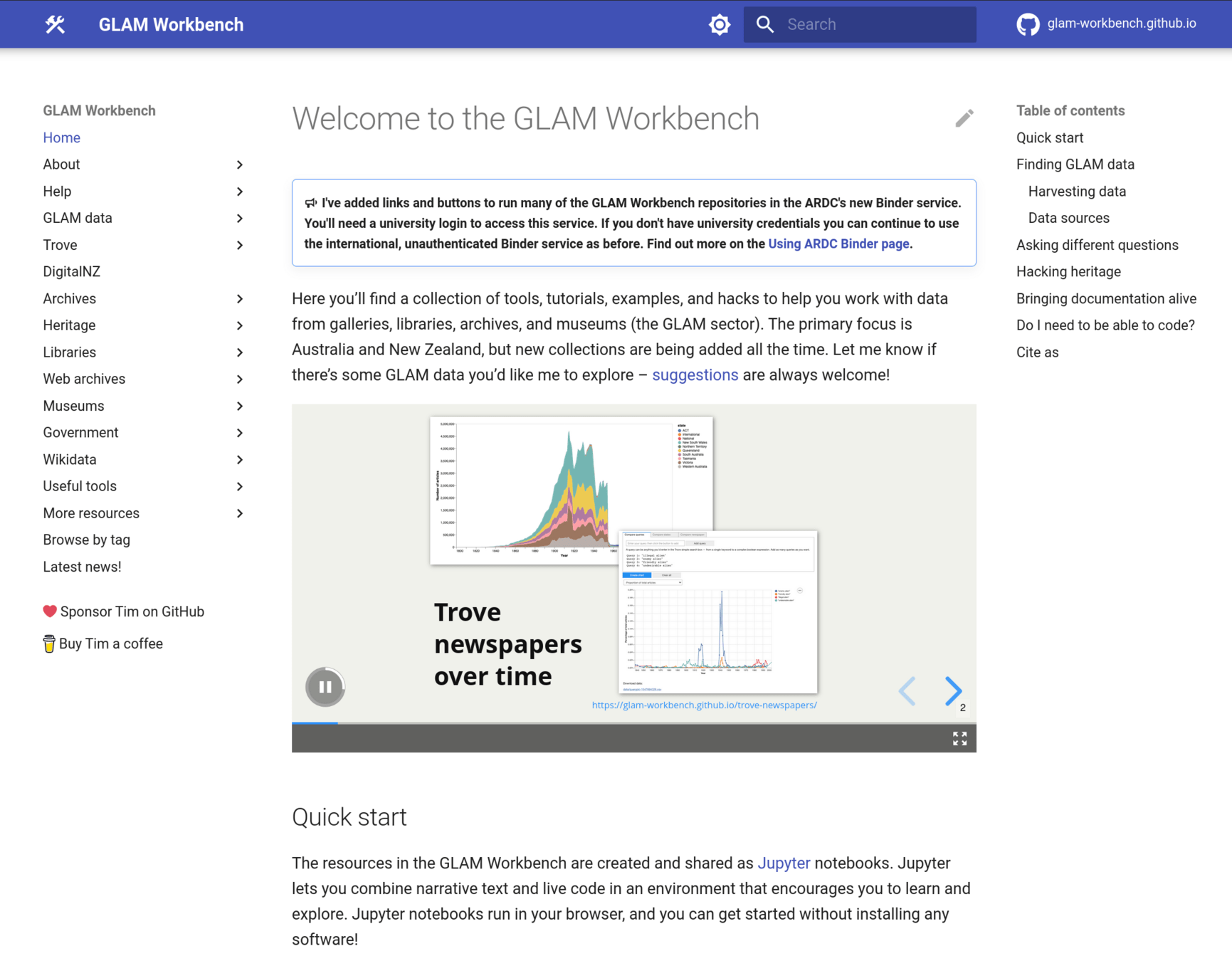
lots of cool GLAM data, but...
tools, hacks, & examples
not just the how,
but the why...

Assembling data
Asking questions
Hacking heritage
Live documentation



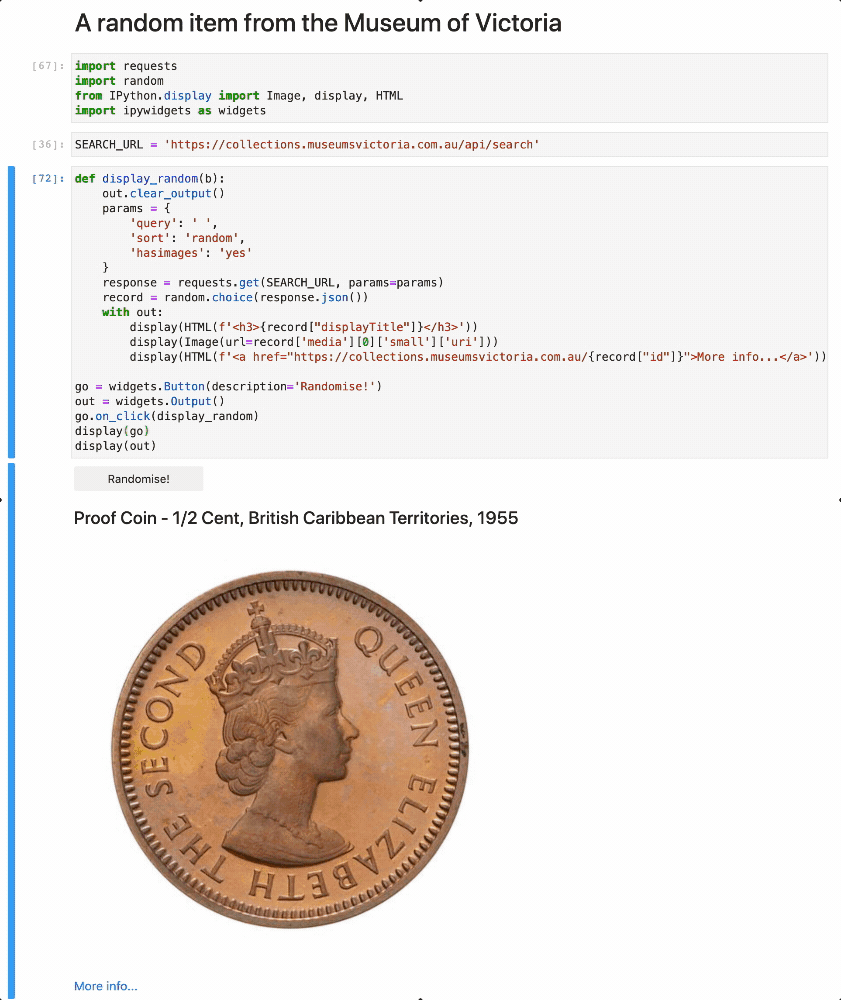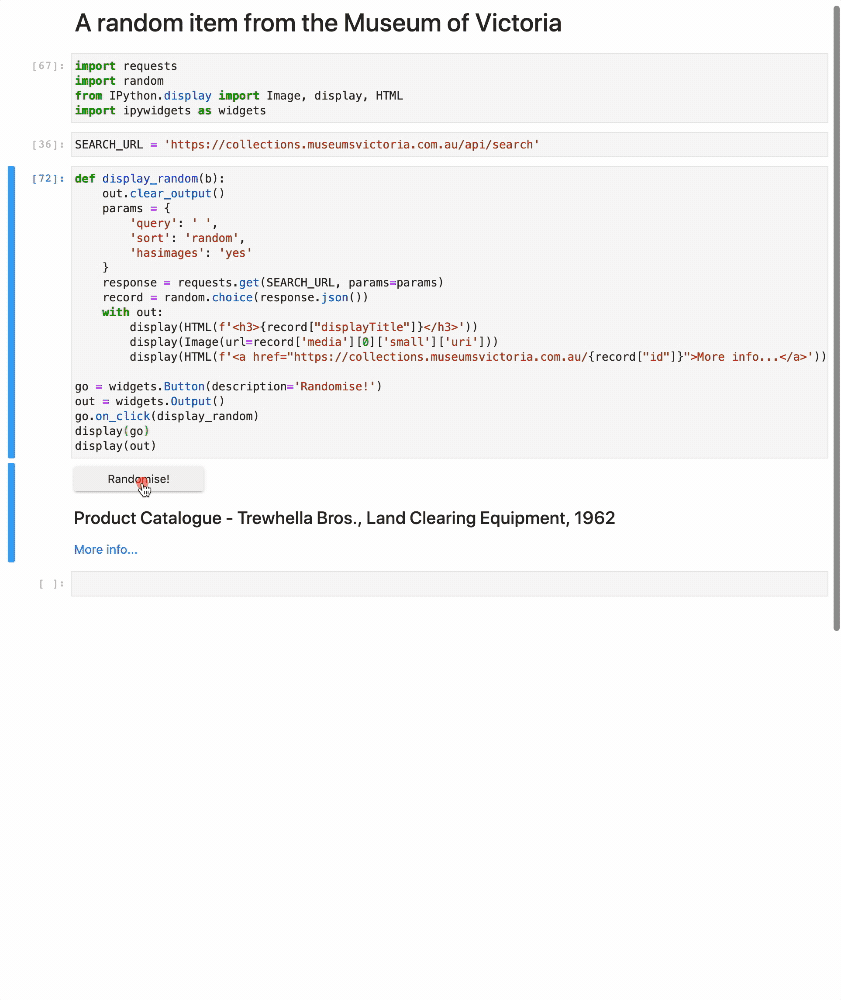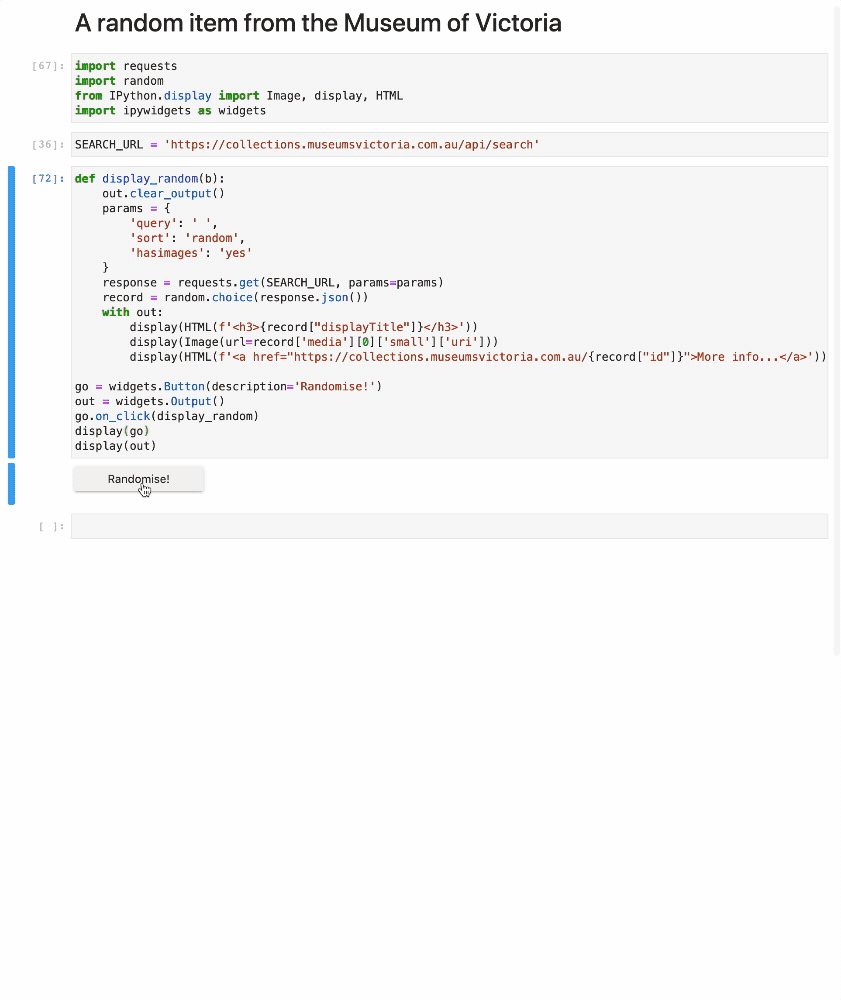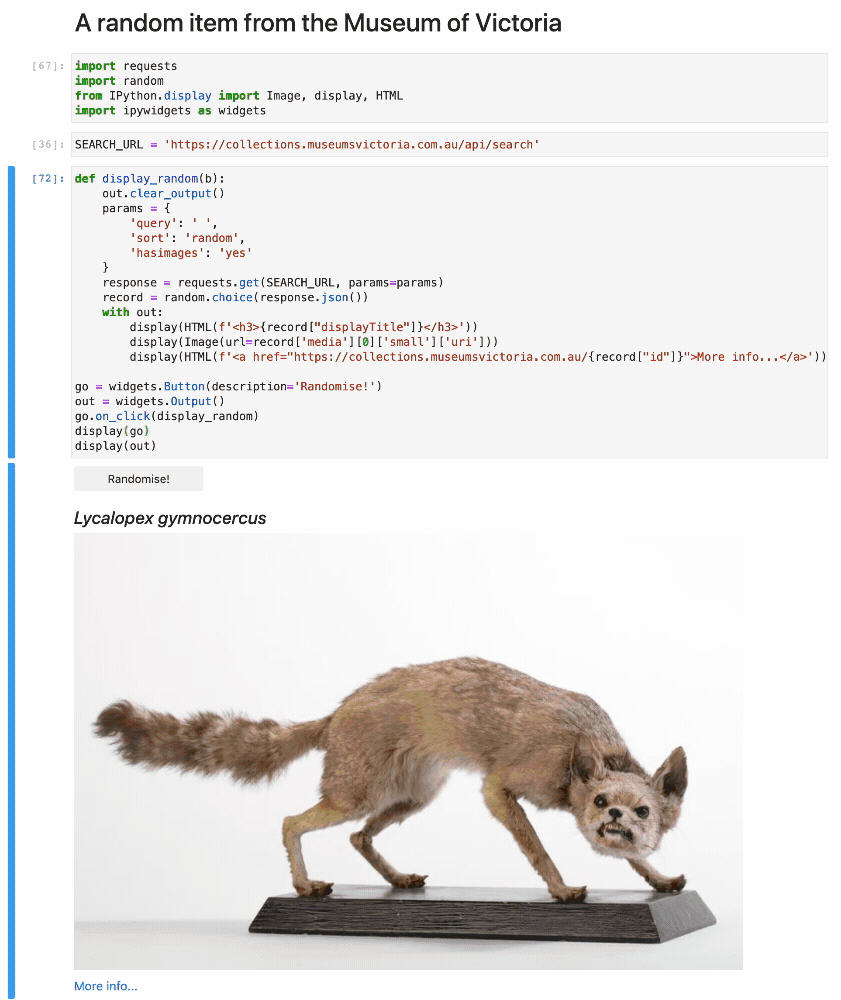
- Trove
- DigitalNZ
- Commonwealth Hansard
- National Archives of Australia
- National Museum of Australia
- Te Papa
- Open data portals
- Web Archives
- & more!
Collections & data
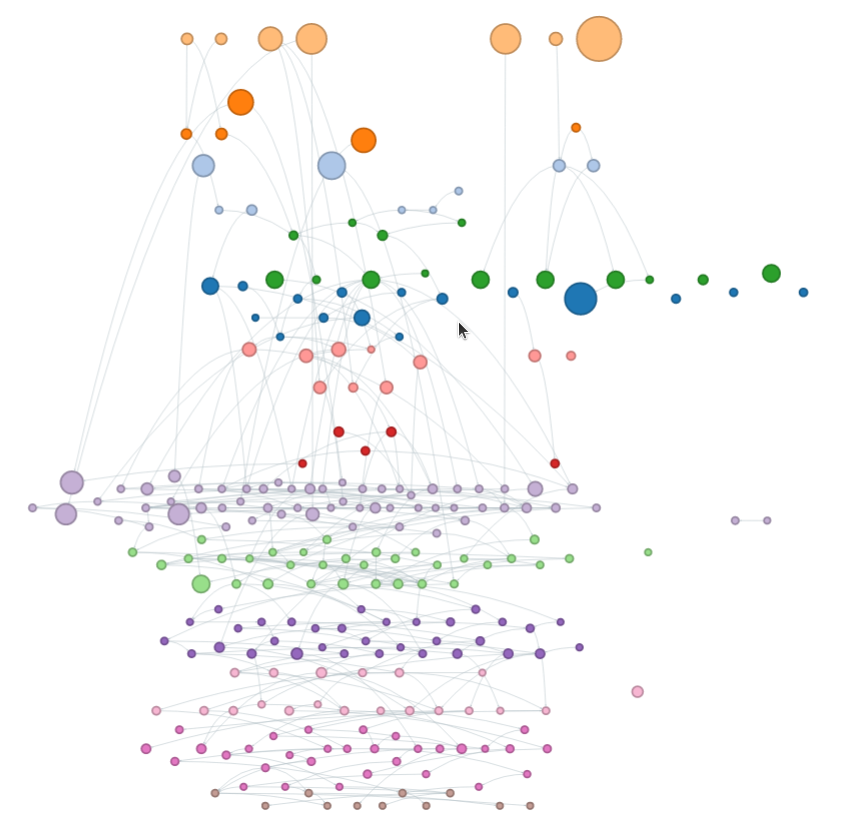
government departments (via NAA and Wikidata)
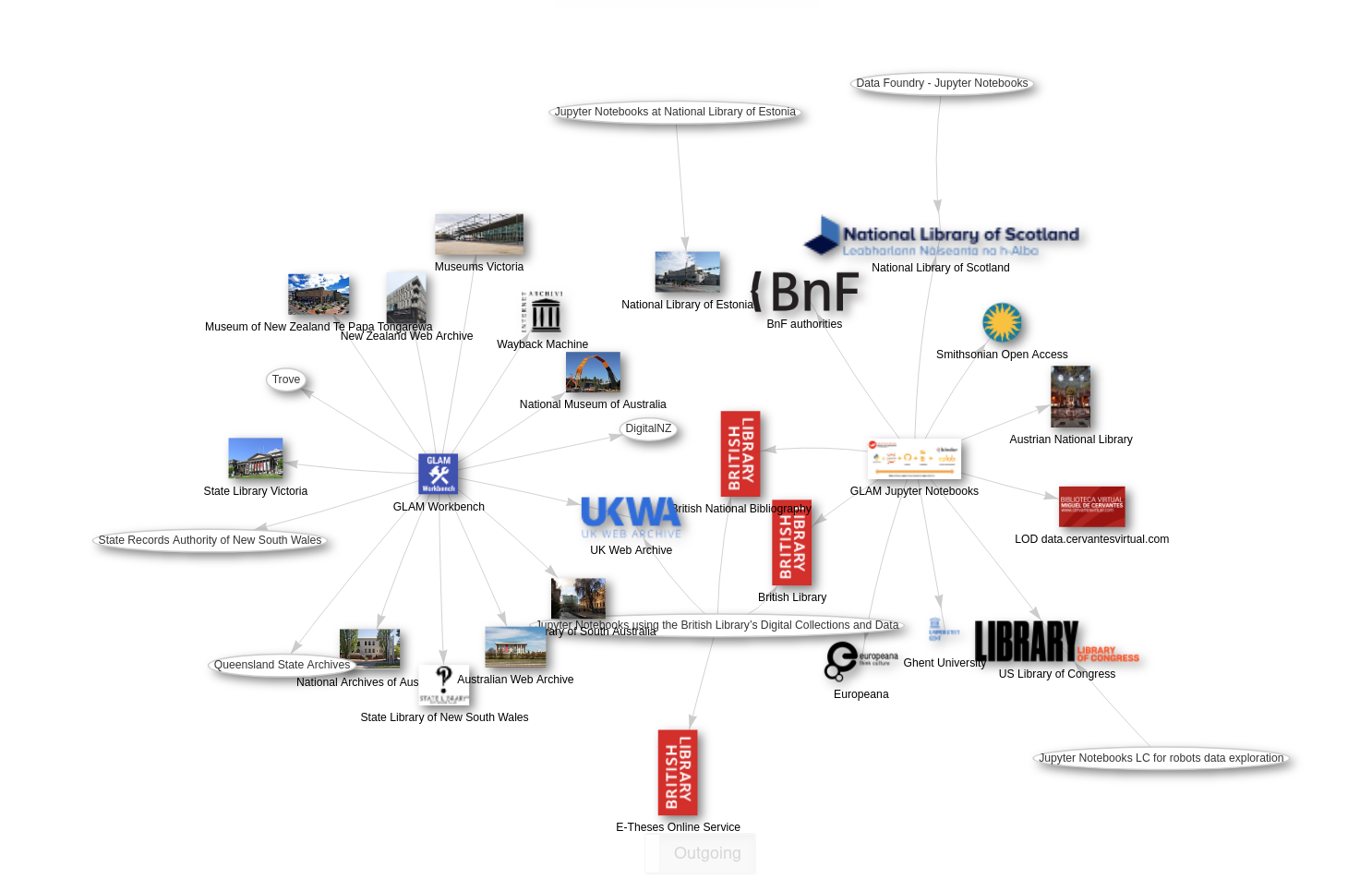

GLAM Labs
- 100+ Jupyter notebooks
- both tool & tutorial
- same code, different views
- all in your browser!
Jump in with Binder

one click to start
Community Data Lab
Trove Data Guide
GLAM Workbench
architectures
standards
technologies
principles
- stay flexible – no single platform or provider
- open licences, open source, open to contributions
- standardise & automate
- explore 'static' approaches
practice / principles

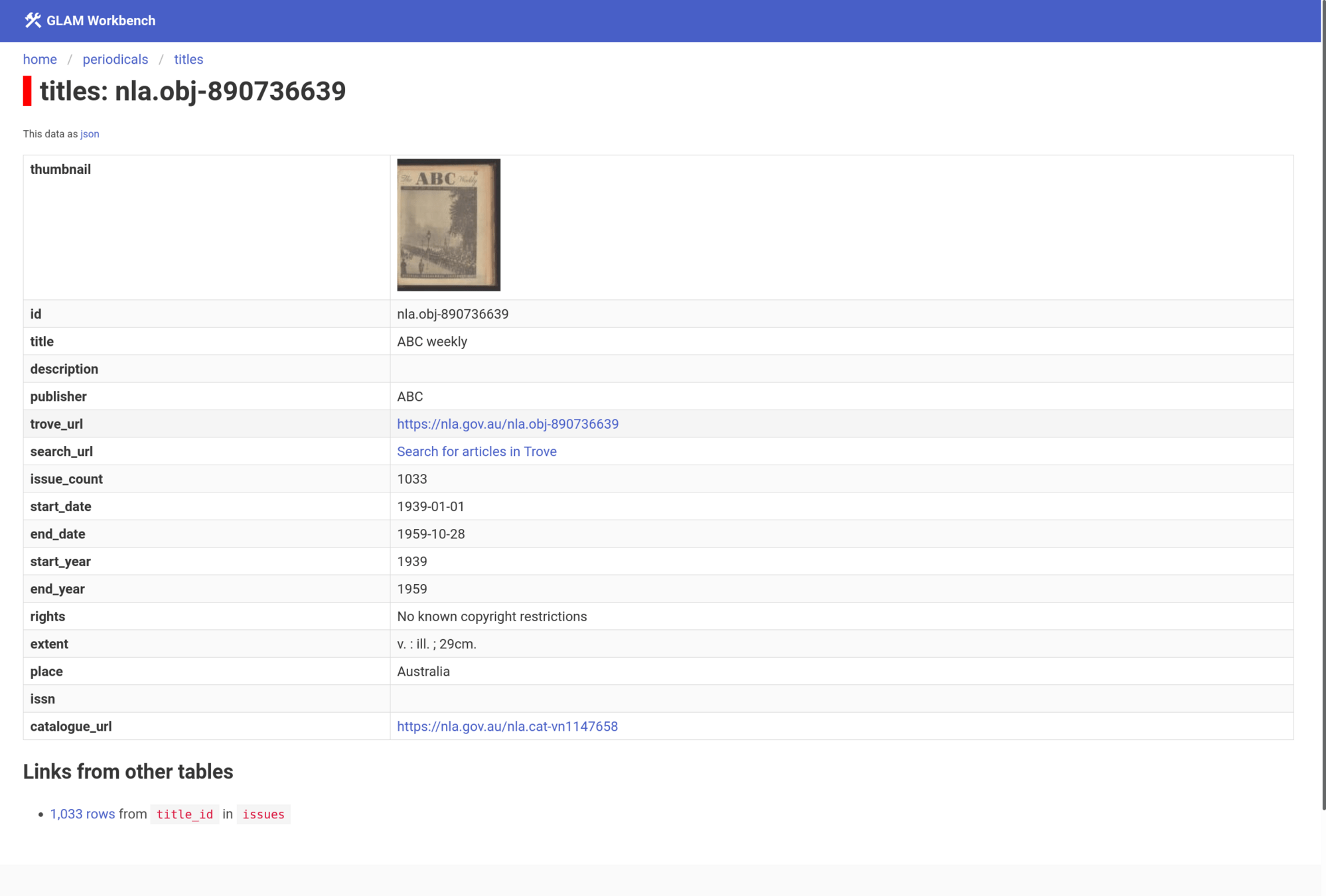
a new GLAM Workbench repository!




Docker container
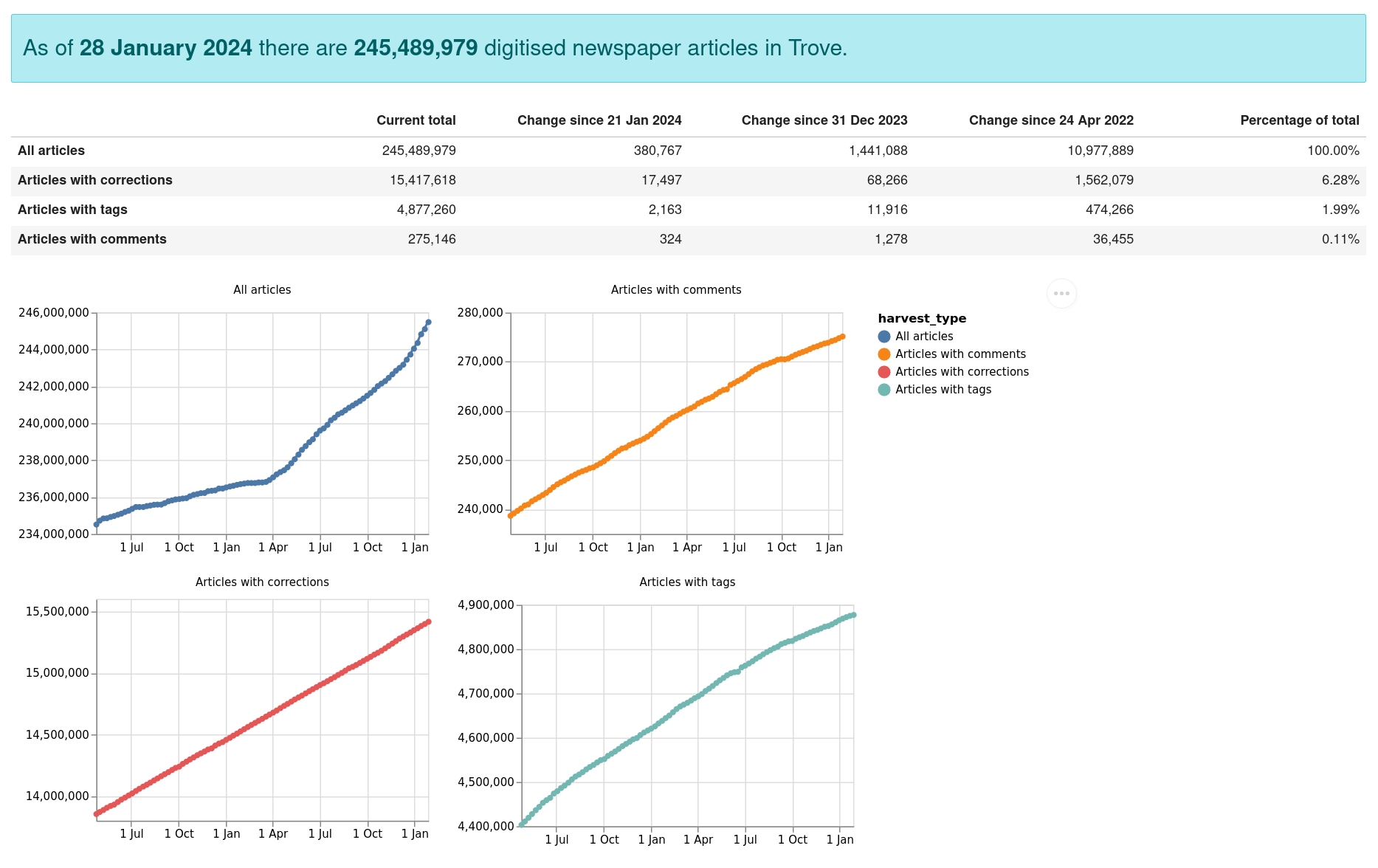
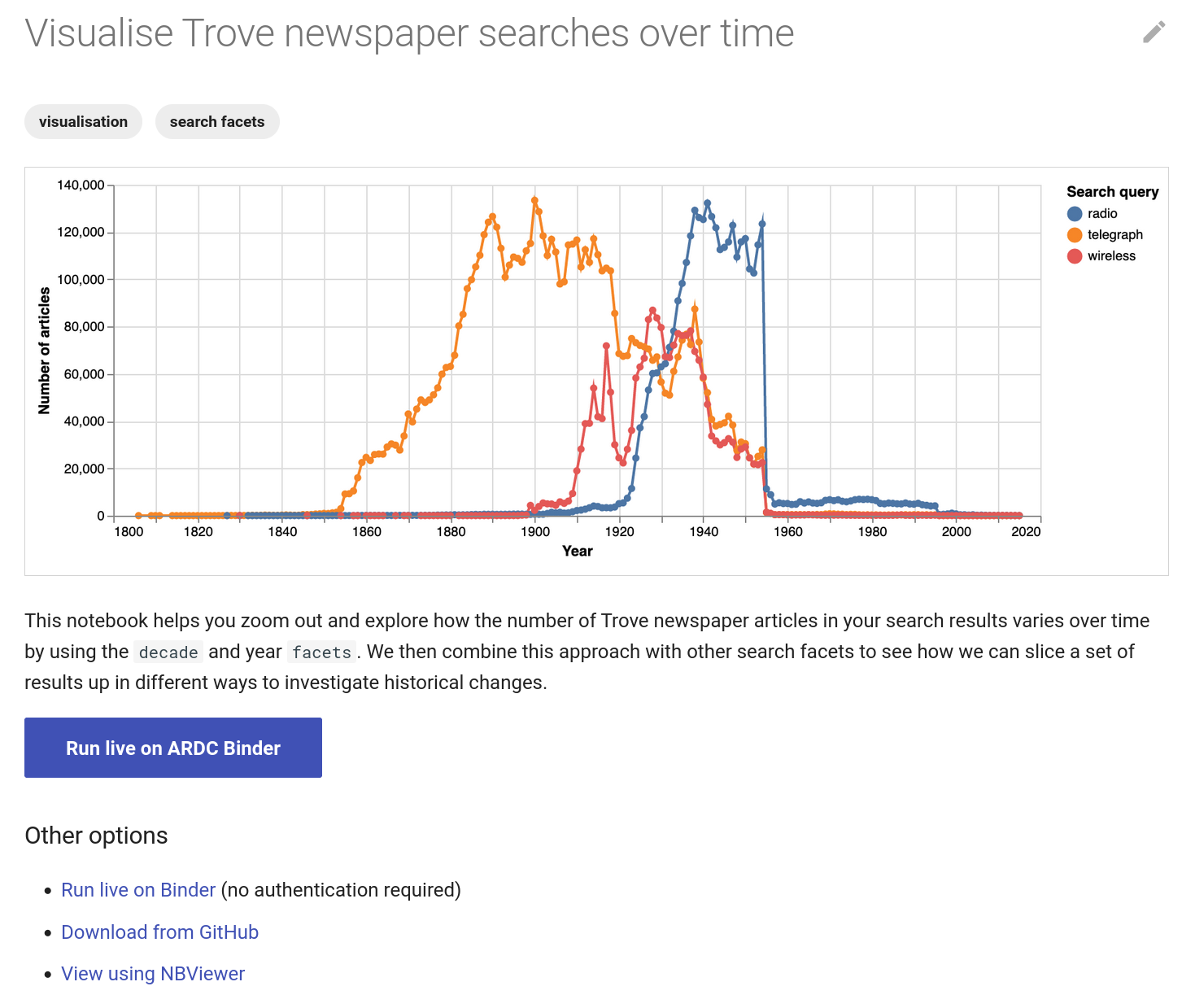
Trove newspapers data dashboard
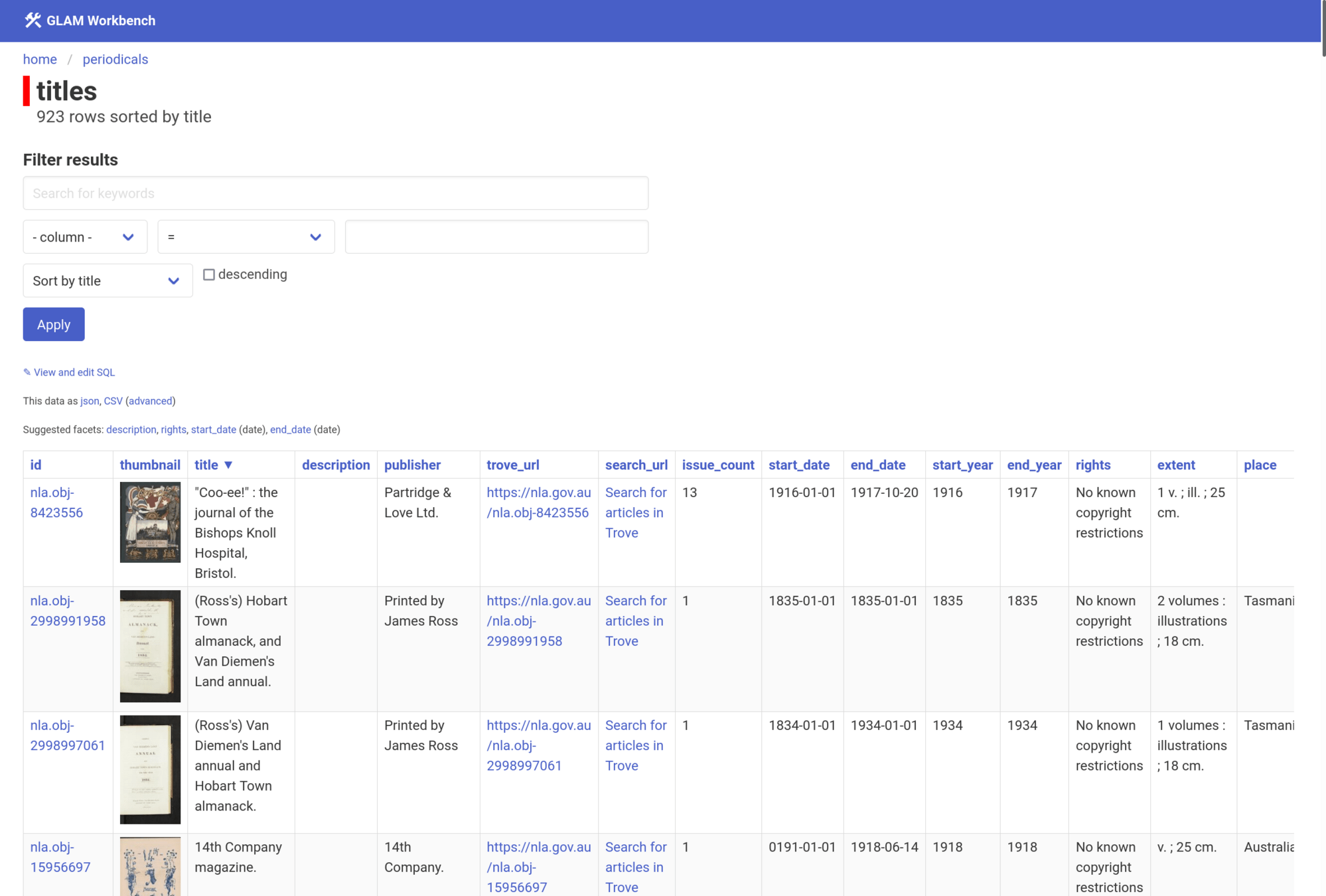
Datasette-Lite
- machine-readable metadata (RO-Crate) for tools & datasets
- thinking about quality
connecting things up

Best practices for GLAM Jupyter
Trove Newspaper Harvester
{
"@context": "https://w3id.org/ro/crate/1.1/context",
"@graph": [
{
"@id": "ro-crate-metadata.json",
"@type": "CreativeWork",
"about": {
"@id": "./"
},
"conformsTo": {
"@id": "https://w3id.org/ro/crate/1.1"
},
"license": {
"@id": "https://creativecommons.org/publicdomain/zero/1.0/"
}
},
{
"@id": "./",
"@type": "Dataset",
"datePublished": "2023-10-23T05:02:01+00:00",
"description": "This dataset of digitised newspaper articles from Trove was created using the Trove Newspaper Harvester. Details of the search query used to generate this dataset can be found in the harvester_config.json file.",
"hasPart": [
{
"@id": "harvester_config.json"
},
{
"@id": "text"
},
{
"@id": "results.csv"
}
],
"mainEntity": {
"@id": "#harvester_run"
},
"name": "Dataset of digitised newspaper articles harvested from Trove on 23 October 2023"
},
{
"@id": "harvester_config.json",
"@type": "File",
"encodingFormat": "application/json",
"name": "Trove Newspaper Harvester configuration file"
},
{
"@id": "text",
"@type": [
"File",
"Dataset"
],
"dateCreated": "2023-10-23T16:02:30.929438+11:00",
"description": "There is one text file per article. The file titles include basic article metadata \u2013 the date of the article, the id number of the newspaper, and the id number of the article.",
"license": {
"@id": "http://rightsstatements.org/vocab/CNE/1.0/"
},
"name": "Text files harvested from articles",
"size": 272
},
{
"@id": "results.csv",
"@type": [
"File",
"Dataset"
],
"contentSize": 80336,
"dateCreated": "2023-10-23T16:02:30.944094+11:00",
"encodingFormat": "text/csv",
"license": {
"@id": "http://rightsstatements.org/vocab/NKC/1.0/"
},
"name": "Metadata of harvested articles in CSV format",
"size": 272
},
{
"@id": "#harvester_run",
"@type": "CreateAction",
"actionStatus": {
"@id": "http://schema.org/CompletedActionStatus"
},
"endDate": "2023-10-23T16:02:30.929438+11:00",
"instrument": "https://github.com/wragge/trove-newspaper-harvester",
"name": "Run of harvester",
"object": "harvester_config.json",
"result": [
{
"@id": "text"
},
{
"@id": "results.csv"
}
],
"startDate": "2023-10-23T16:02:01.306088+11:00"
},
{
"@id": "https://github.com/wragge/trove-newspaper-harvester",
"@type": "SoftwareApplication",
"description": "The Trove Newspaper (& Gazette) Harvester makes it easy to download large quantities of digitised articles from Trove\u2019s newspapers and gazettes.",
"documentation": "https://wragge.github.io/trove-newspaper-harvester/",
"name": "Trove Newspaper and Gazette Harvester",
"softwareVersion": "0.7.2",
"url": "https://github.com/wragge/trove-newspaper-harvester"
},
{
"@id": "http://rightsstatements.org/vocab/NKC/1.0/",
"@type": "CreativeWork",
"description": "The organization that has made the Item available reasonably believes that the Item is not restricted by copyright or related rights, but a conclusive determination could not be made.",
"name": "No Known Copyright",
"url": "http://rightsstatements.org/vocab/NKC/1.0/"
},
{
"@id": "http://rightsstatements.org/vocab/CNE/1.0/",
"@type": "CreativeWork",
"description": "The copyright and related rights status of this Item has not been evaluated.",
"name": "Copyright Not Evaluated",
"url": "http://rightsstatements.org/vocab/CNE/1.0/"
},
{
"@id": "https://creativecommons.org/publicdomain/zero/1.0/",
"@type": "CreativeWork",
"name": "CC0 Public Domain Dedication",
"url": "https://creativecommons.org/publicdomain/zero/1.0/"
}
]
}- every harvest generates an RO-Crate file
- new config file with tool and query parameters
- links tool, configuration, query, and dataset
- captures the context of a harvest
- easy to re-run a harvest