The American World Gazetteer
or too much text, too little time...
Tim Sherratt · @wragge
- OCRd text from 83,135 digitised books (30gb)
- Never mind the metadata – just give me everything!
The dataset
- What's an API anyway?
- Where's the API documentation?
- Used the manifest to get list of files
- Downloading was straightforward – 83,135 text files (30gb) in 5 days
Accessing the dataset
- Encoding of text files
- How many files are there?
- OCR quality (of course!)
- Not enough time!
Biggest obstacle
- Exploring new data!
- The challenges of scale (on a budget)
- I learnt heaps!
What did I enjoy?
- More time!
- Clearer processing pipelines
- Disambiguation and data cleaning?
What would I have done differently?
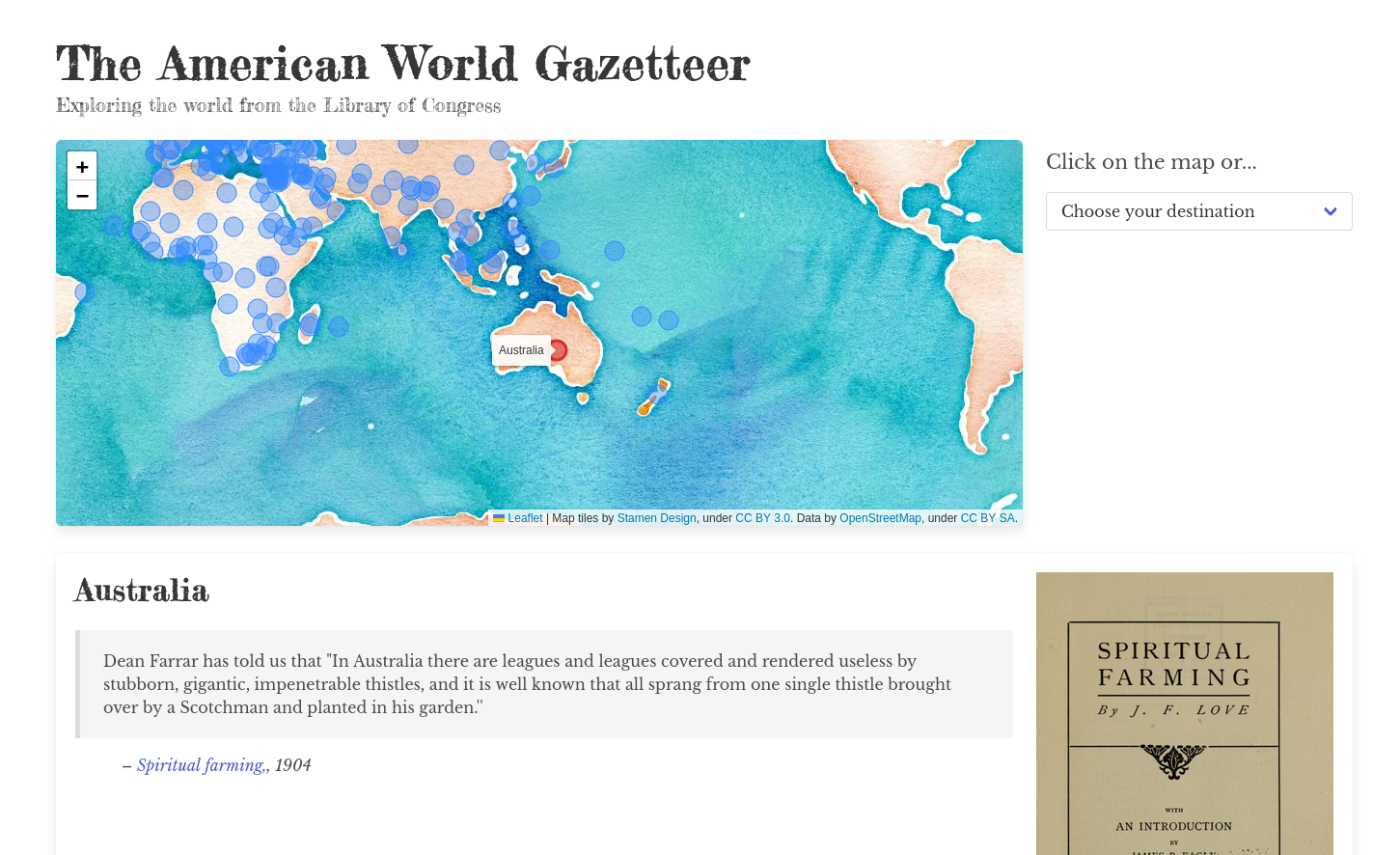
- The world as seen from America?
- 7,762,992 places from 34,570 books
- Limited to 737 'countries' & linked to Wikidata
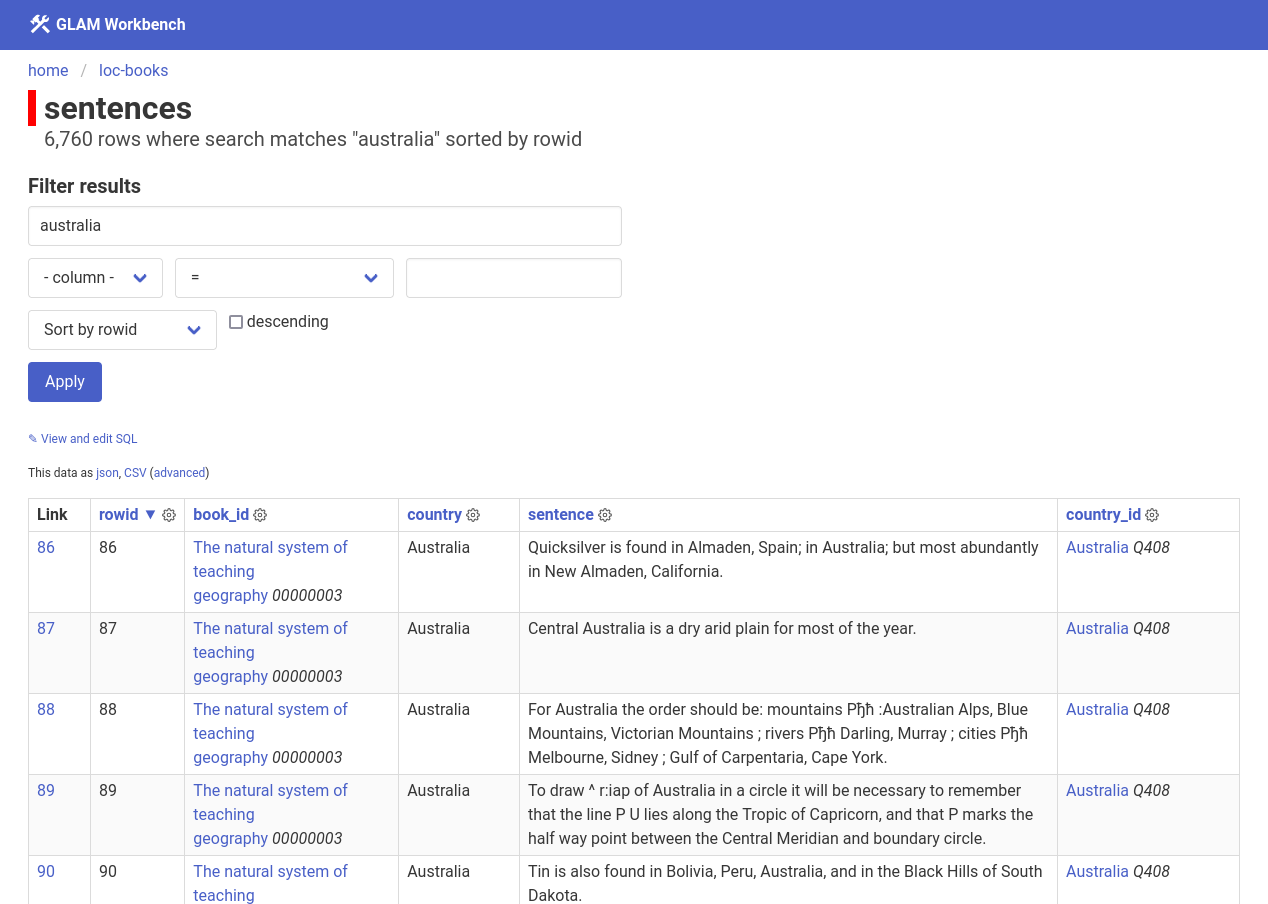
- 1,393,125 sentences extracted from 10,155 books
- Book metadata, countries, & sentences saved to SQLite, searchable through Datasette
-
American World Gazetteer app – random sentences from Datasette
How did you choose to represent the dataset?
- What does 'access' and how does it change?
- What's possible? Does large-scale analysis need large-scale resources?
Did you have a specific research question?
- More LoC examples in the GLAM Workbench
- Mashing up LoC books with OCRd text from 26,762 Trove books
- Disambiguation & data cleaning...
- More links (to Wikidata and beyond)
If you had endless amounts of time and money...
- Jupyter notebooks for data download and processing
- Code repository for app
- Datasette instance
- App (on GitHub pages)