Topic: RLVR without Label from teacher models or humans to enhance long context capability of LLMs
Method: Given a long document (p1, p2, p3,,,,pn)
First filter some random paragraphs like p4, p9, p15 out as option
Then train model to select those back to reconstruct the original document by order.
Input:
p1, p2, p3, <missing>, p5,,,,,,p8, <missing>,,,,P14, <misssing>,P16,,,,,
A. p9, B.p4, C.p15
ground truth: {B, A, C}
Currently, It has some positive results on RULER, but not significant (still trying more data)
Decomposed Prompt Tuning via Low-Rank Reparameterization
Xiao Yao、Xu Lu、Li JiaXi、Lu Wei and Li XiaoLi
EMNLP 2023
Background
- Update a small amount of parameters
- Achieve comparable (even better) performance than full finetuning
✅ Less storage
✅ Less gpu memory
✅ Less Computational Overhead (Faster training speed)
Parameter Efficient Finetuning
Background
Prompt Tuning
PLM
Bert/T5/GPT
Trainable
Frozen
Soft Prompt e c

Input n c
Observation
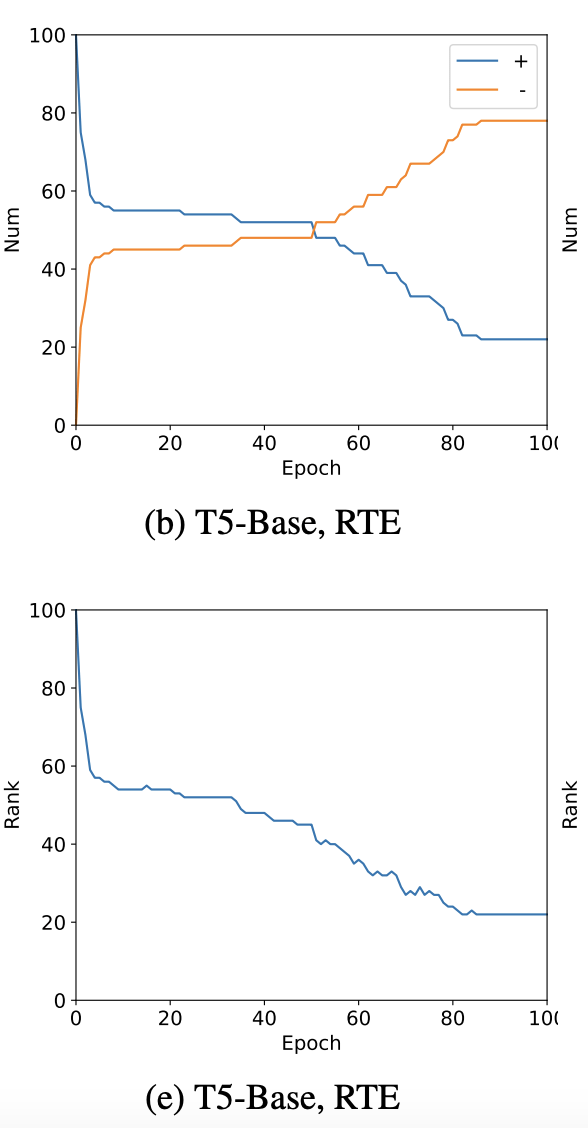
The motivation of this initiation is that soft prompt flexibly adjust its rank.
Observation
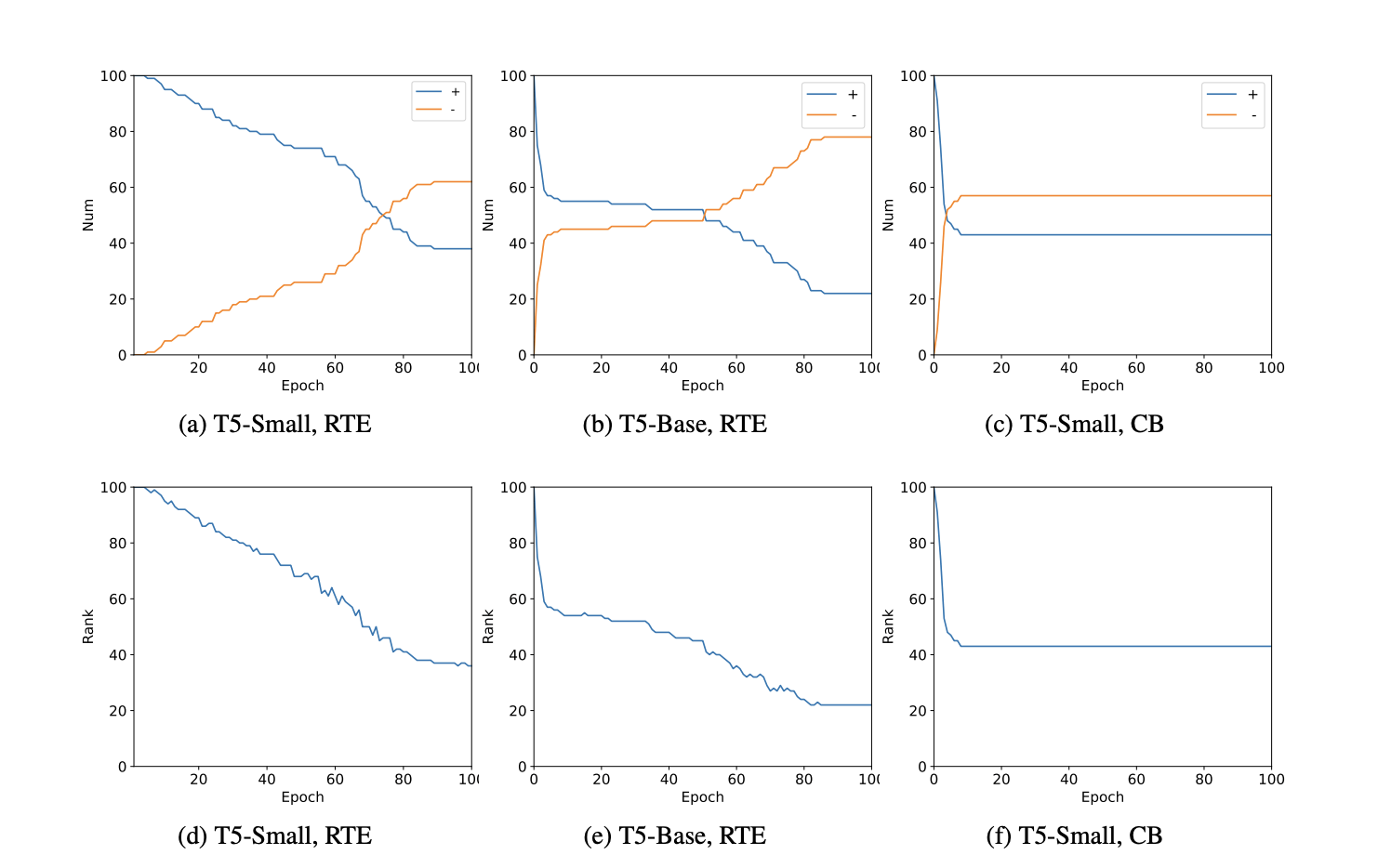
Observation results are consistent.
Method
In practice, c is 100, e is 512, 768, and 1024 for T5-Small, T5-Base, and T5-Large respectively. We set b as 10.
ec >> eb + bc
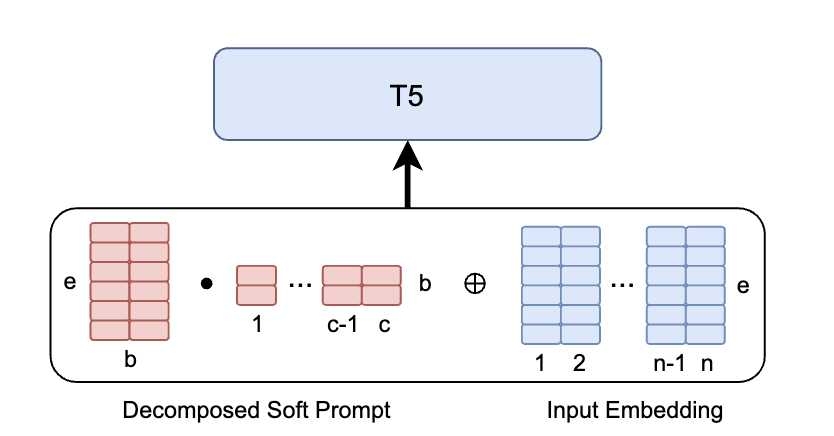
Based on the observation above, we directly decompose the soft prompt into two low-rank trainable matrix.
Results
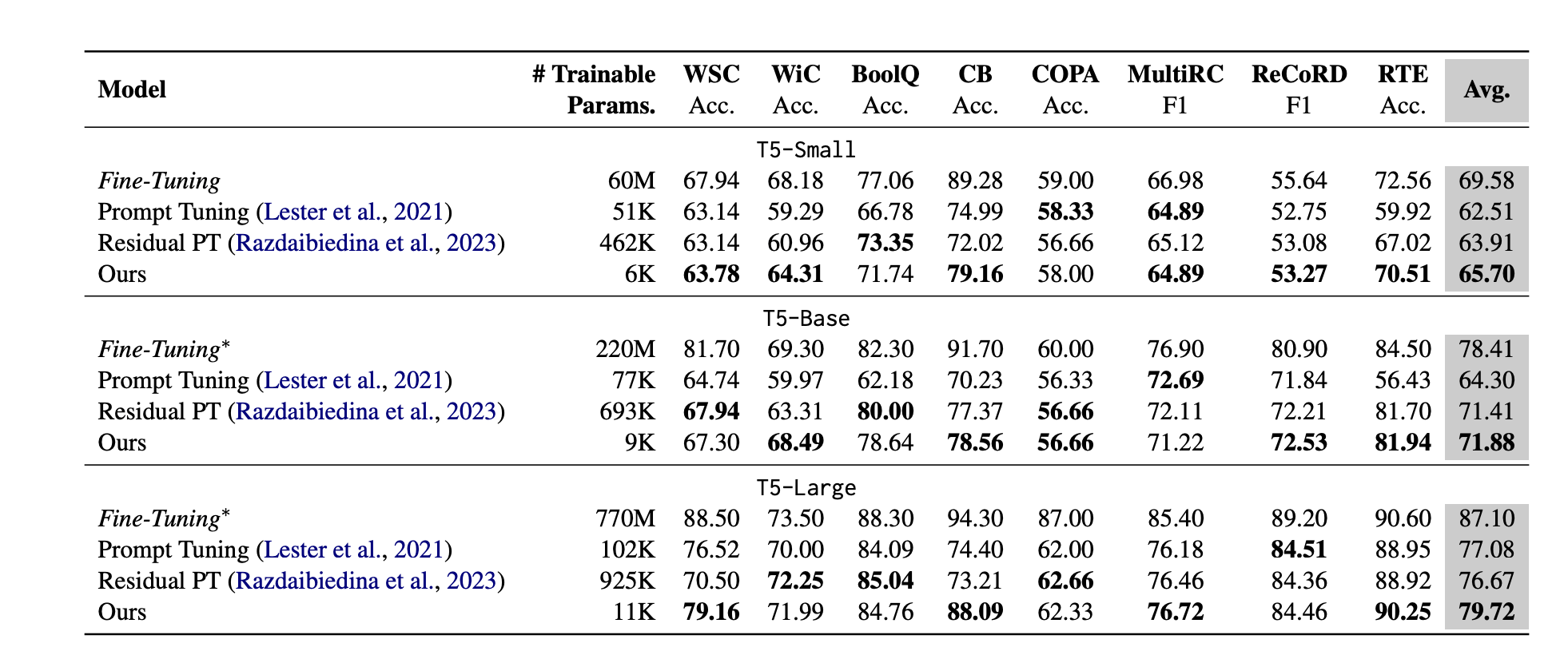
Model: T5-Small, T5-Base, T5-Large
Datasets: SuperGlue
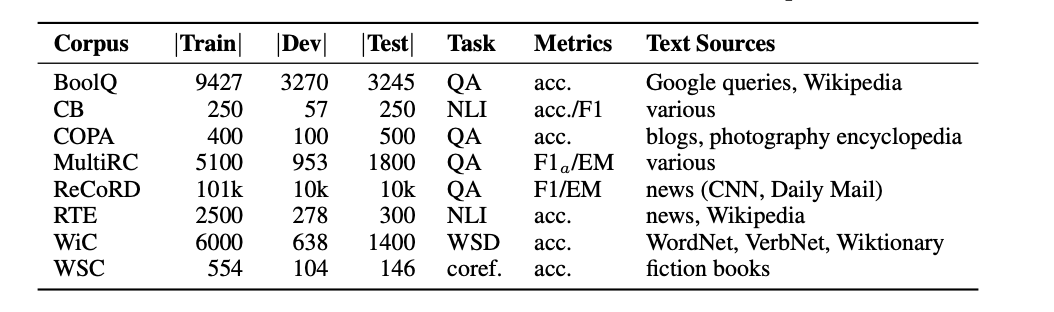
Few-shot Results
8-shot、16-shot and 32-shot
WiC、CB、RTE、and COPA
Ours are consistently better.
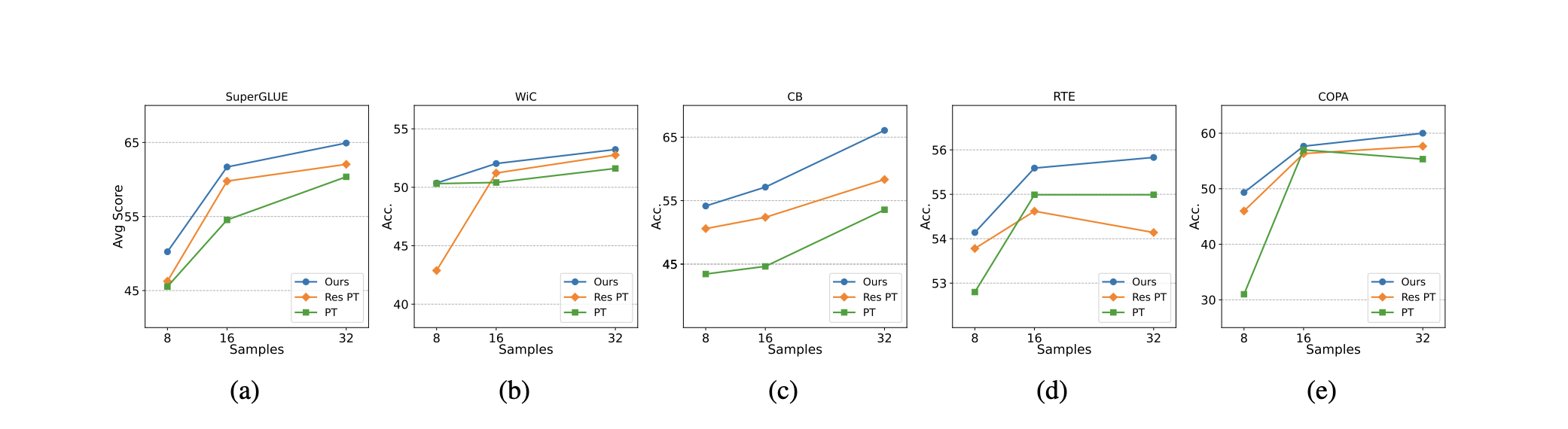
Bottleneck
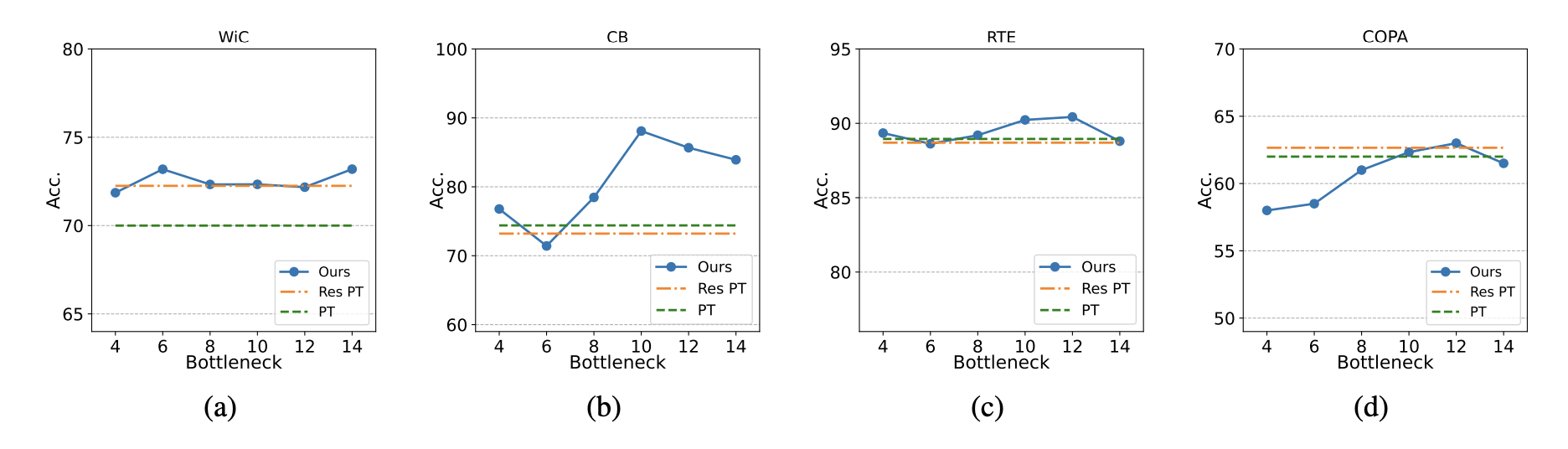
If we increase b to a large number, performance will be unstable.
Prompt Length
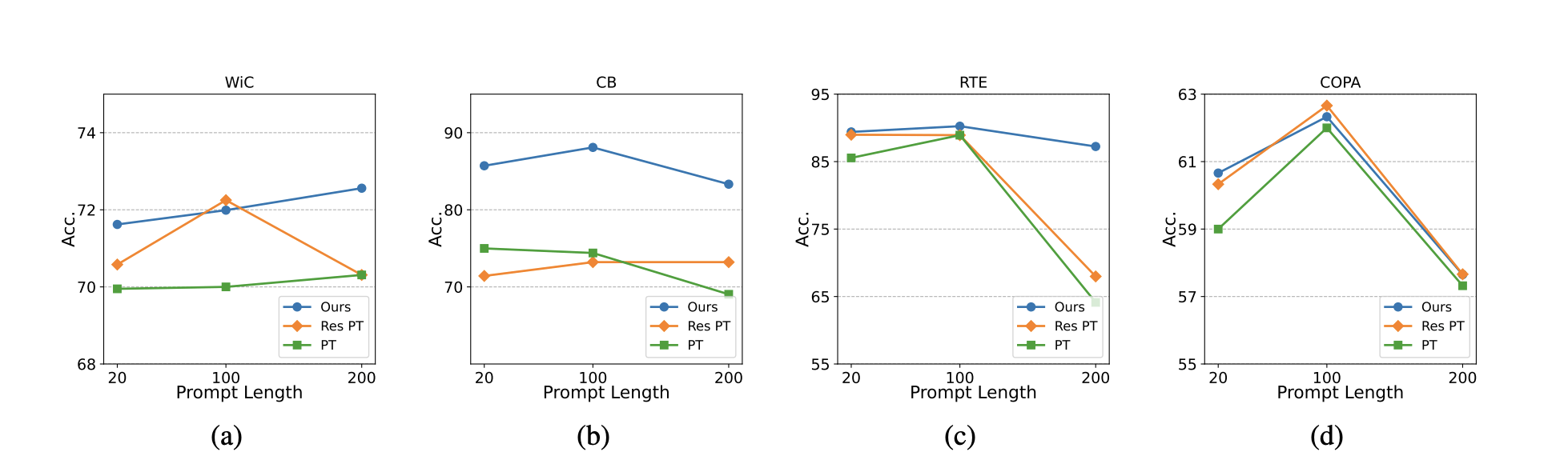
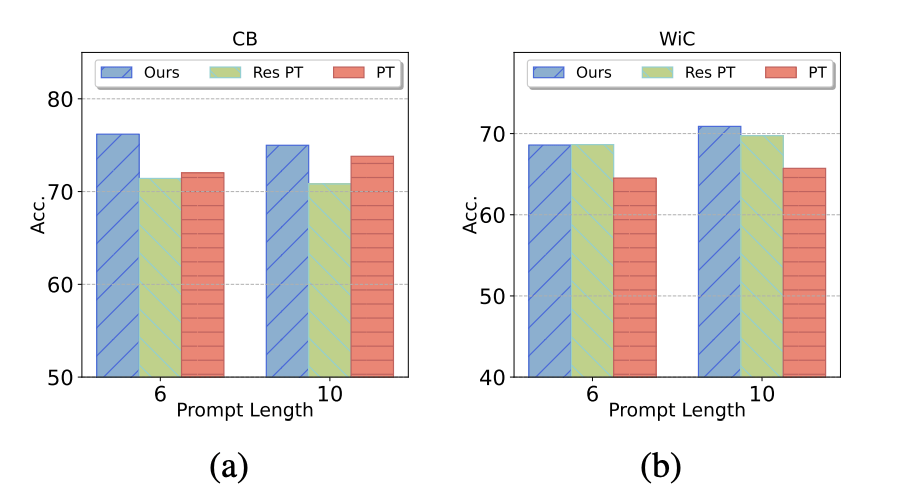
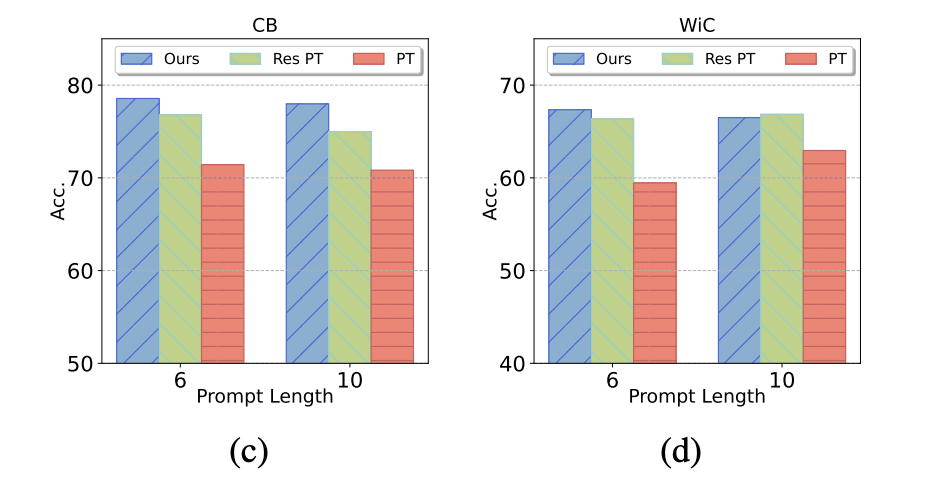
Ours can work even when the length of soft prompt is extremely short.
Same idea
DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning
UCL
ICLR 2024
Self-Adaptive In-Context Chains-of-Thought for Enhanced Mathematical Reasoning
Xiao Yao、Xu Lu、Li JiaXi、Lu Wei and Li XiaoLi
EMNLP 2024 under review
Motivation
Recently, researcher explored the self-improvement approaches of LLM. These work can be classified into two categories:
- update the parameters of LLM: RFT、DPO
- ICL without parameter update: use external feedback like compiler error or gold label
Can LLM self-improve without parameter update or external feedback?
Method
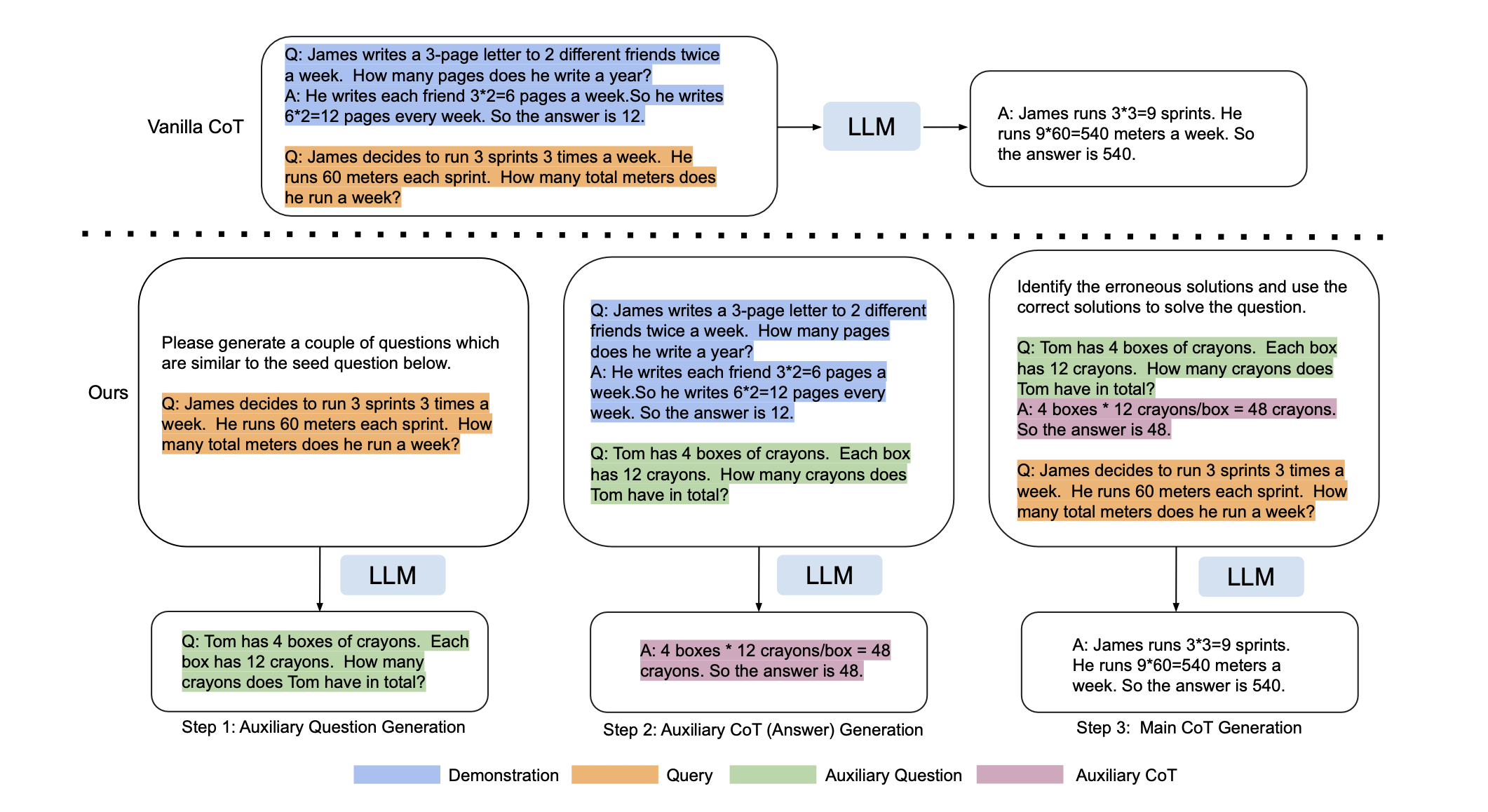
Intuition: Why It Works
Similar questions have similar solutions. Though generated solution may have mistakes, it can reason through the similar solutions to help solve the question.

Results
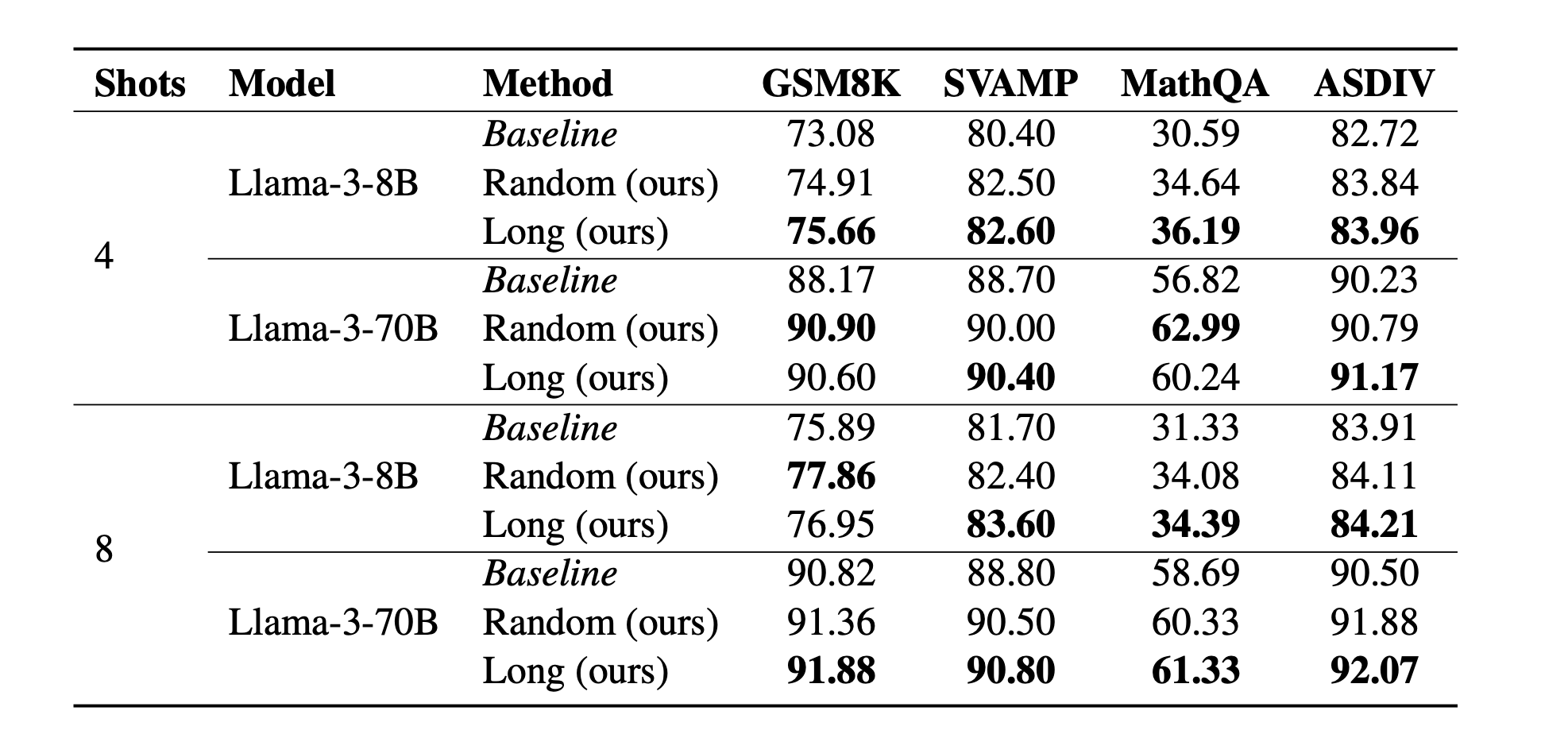
Random: choose n generated samples randomly
Long: choose n longest generated samples
Results
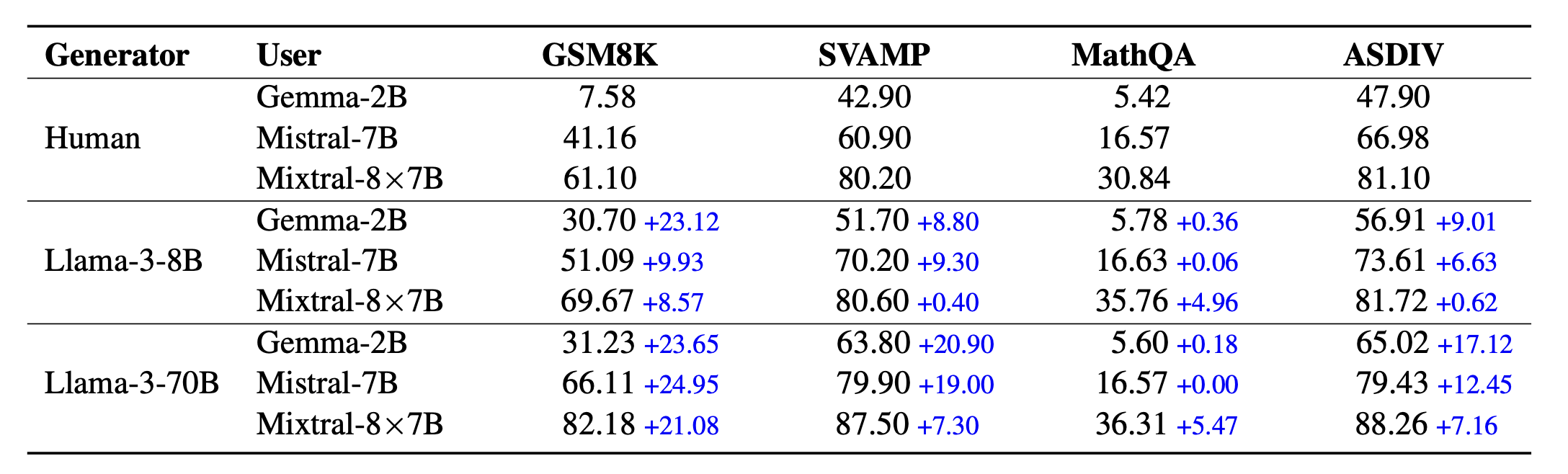
If we feed the generated samples to other models (especially the weak one), we find significant empirical gains.
Effects of Question Generator
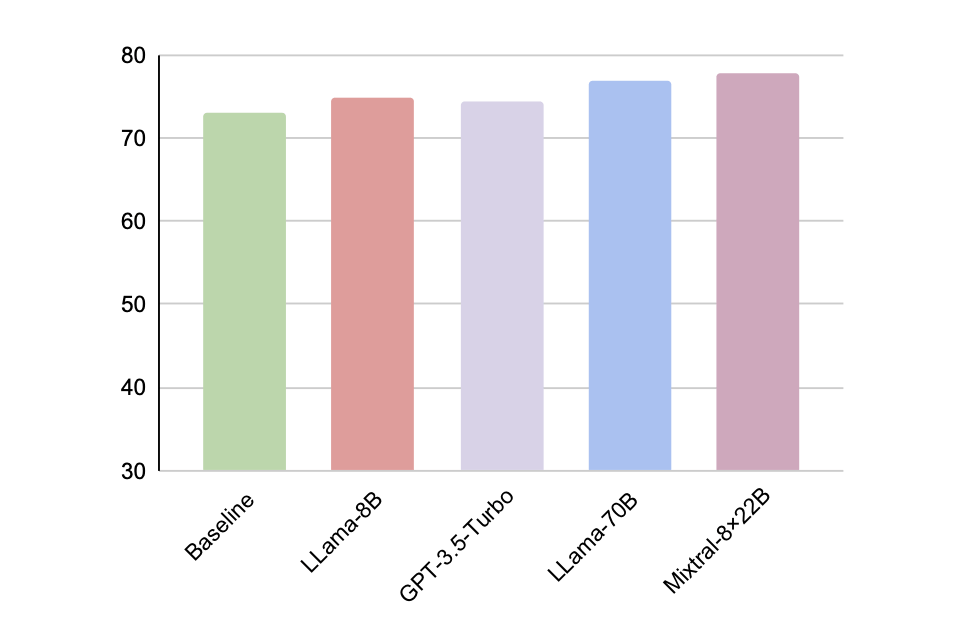
The more powerful the question generator is, the better the performance.
Effects of Generated Solutions' Accuracy
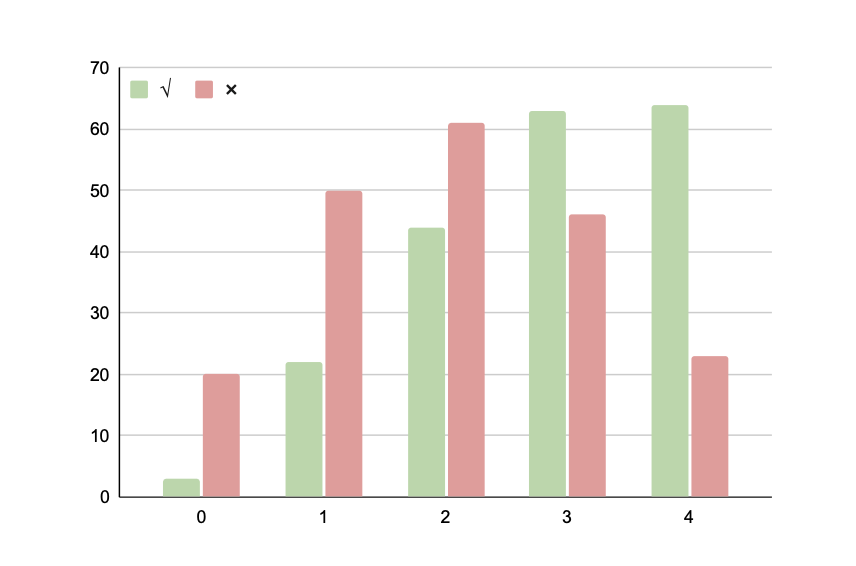
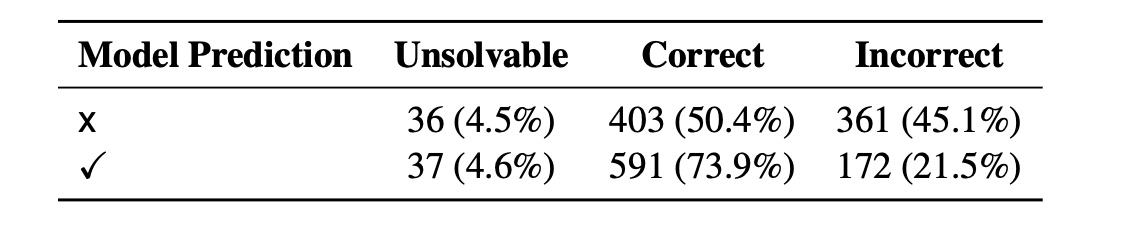

The more accurate the generated solution is, the better the performance.
Robustness
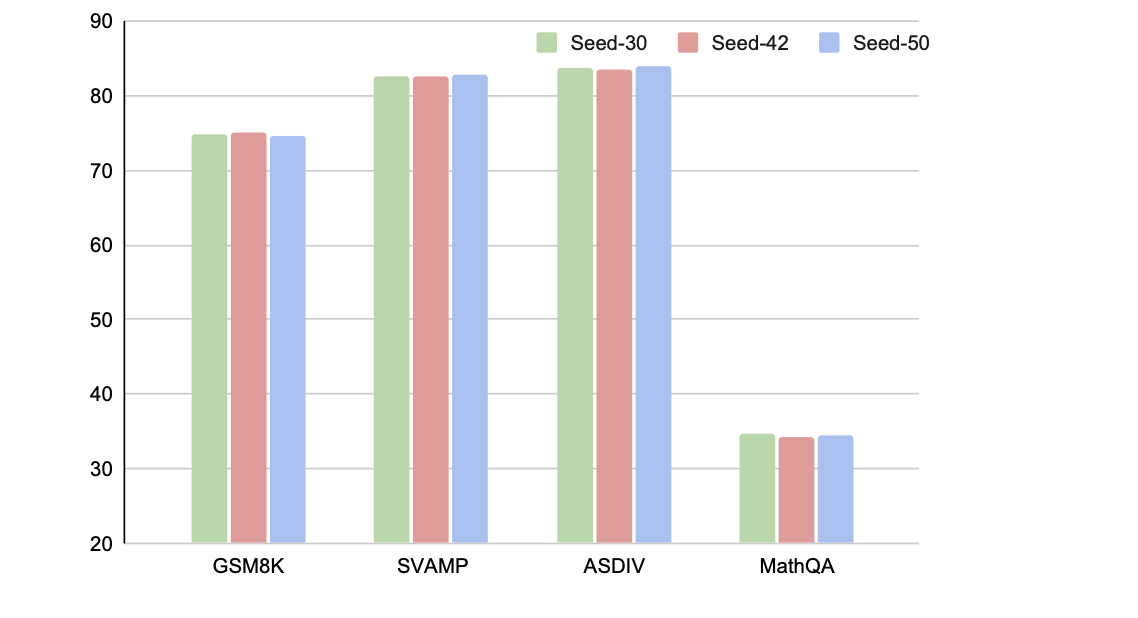
The performance is relatively stable.