From Arxiv

Revisit GRPO
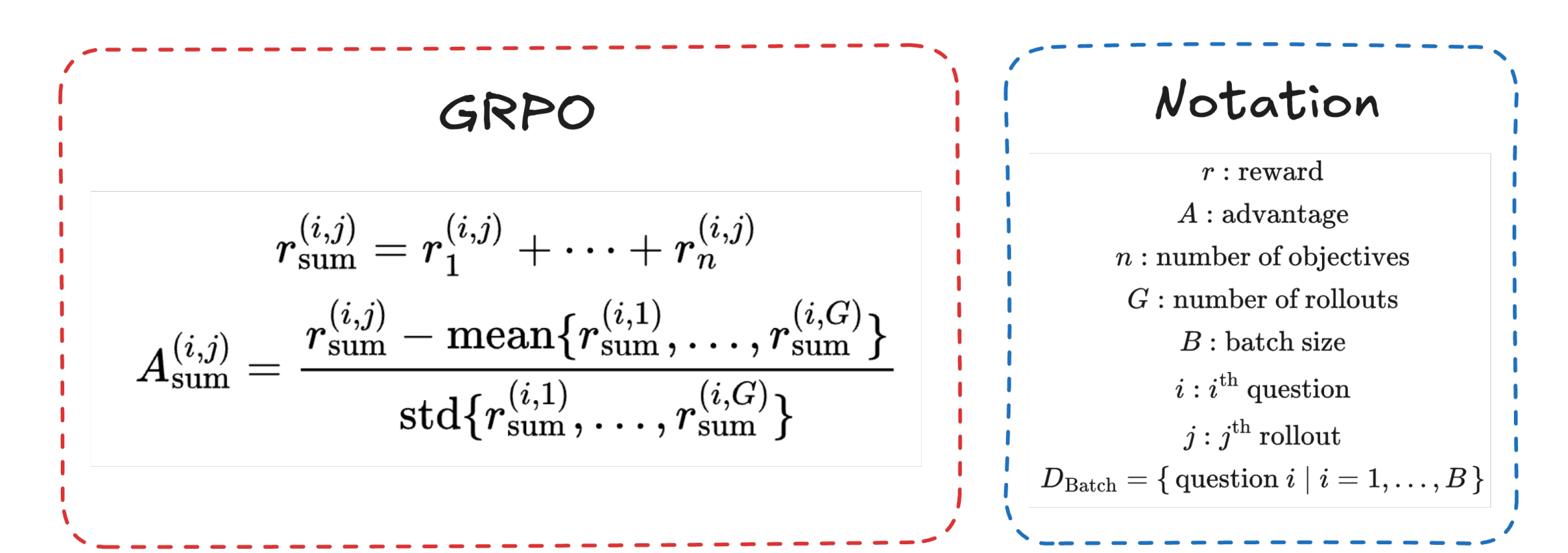
For example, can be sum of answer accuracy and format match.
r_{sum}
Two-binary-reward, Two-rollout example
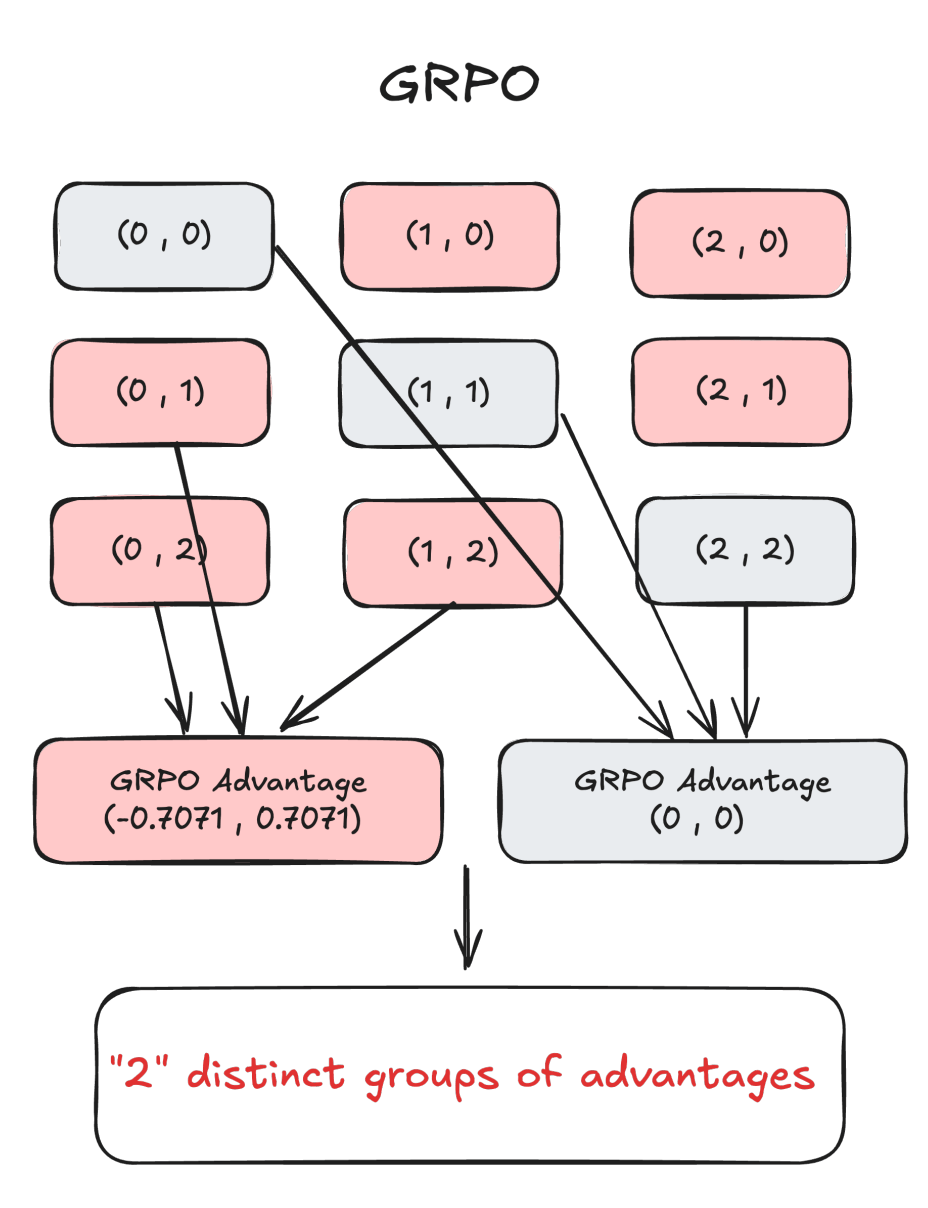
This demonstrates a fundamental limitation of GRPO’s advantage calculation in multi-reward optimization which over-compresses the rich group-wise reward signal.
Intuitively, (0, 2) should produce a stronger learning signal than (0, 1) because a total reward of 2 indicates simultaneous satisfaction of two rewards, whereas a reward of 1 corresponds to achieving only one.
Group reward-Decoupled normalization Policy Optimization
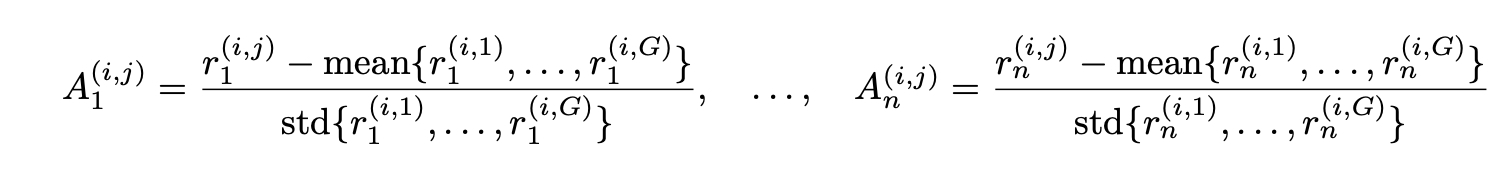
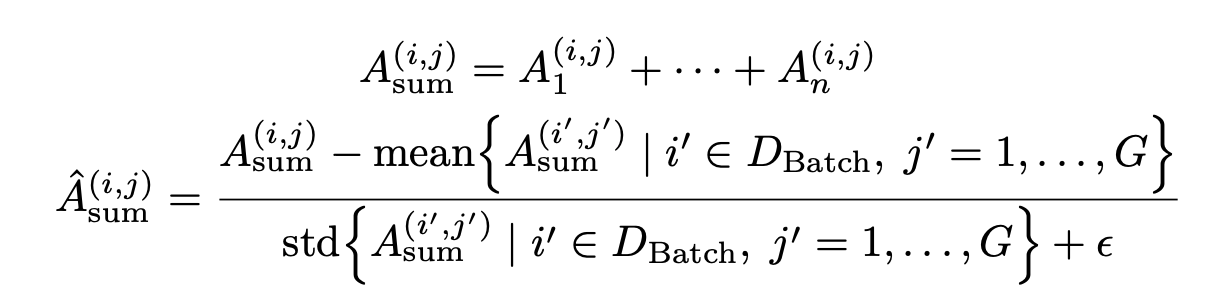
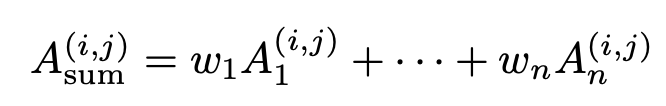
Weighted
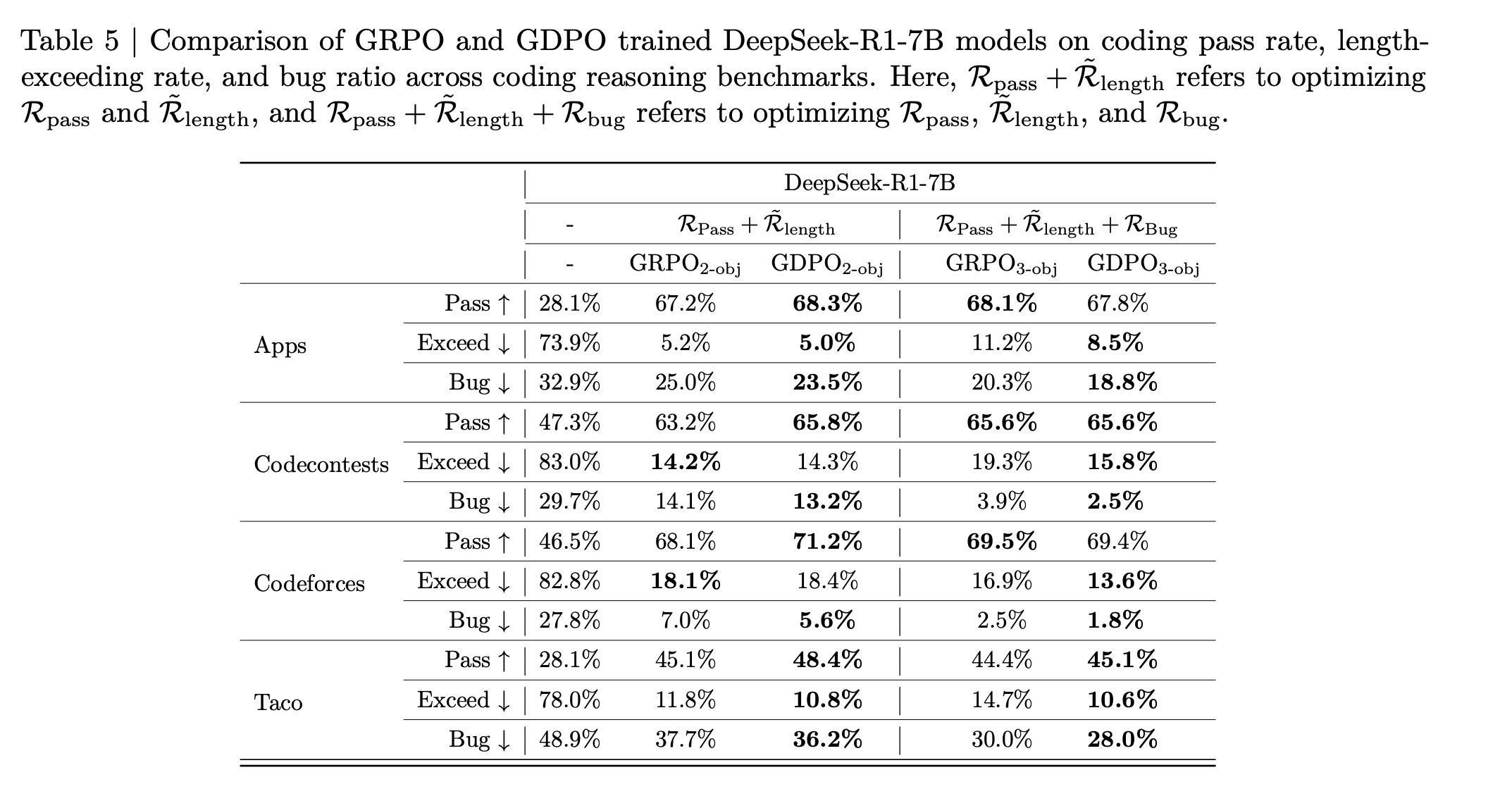
Experiment 1: Tool Calling
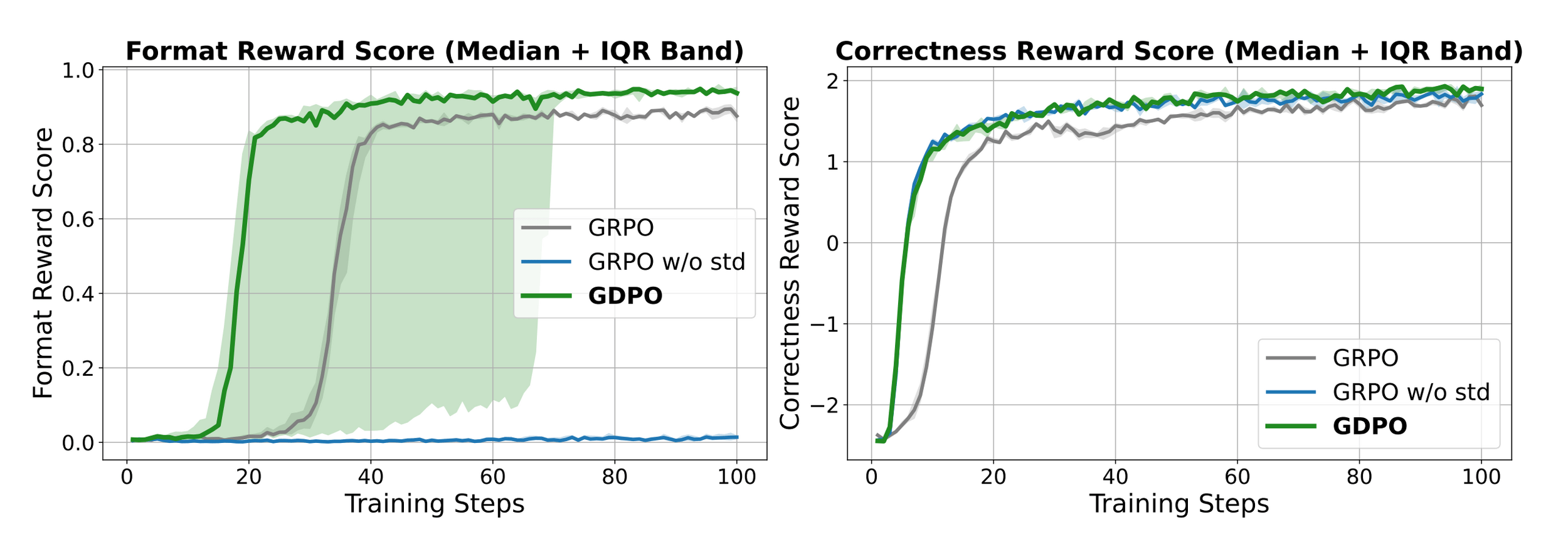

Experiment 1: Tool Calling
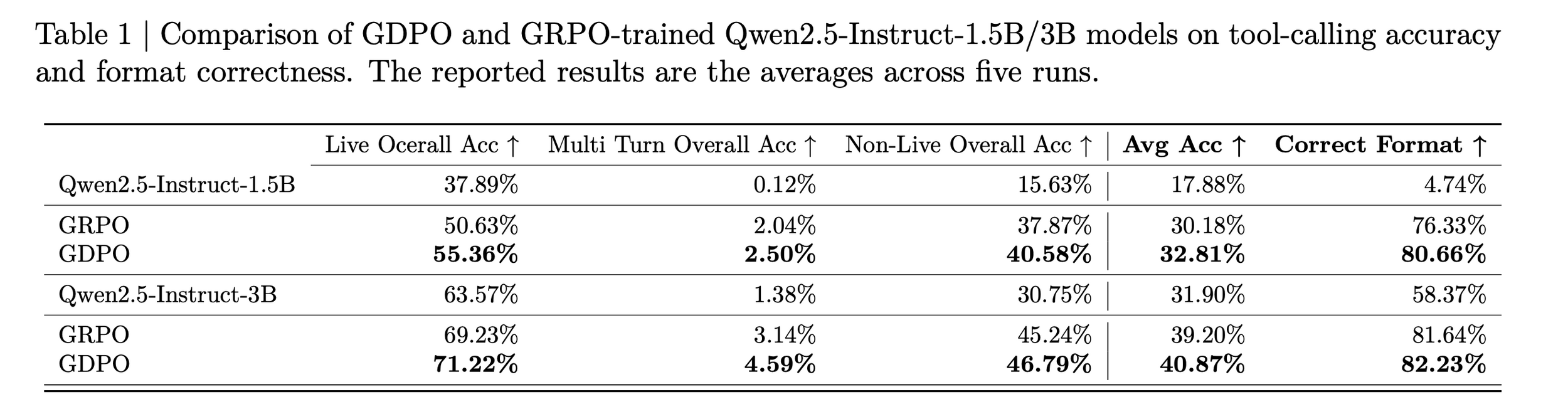
BFCL-v3 evaluation
Experiment 2: Mathematical reasoning

Model: DeepSeek-R1-1.5B
Dataset: DeepScaler
Experiment 2: Mathematical reasoning
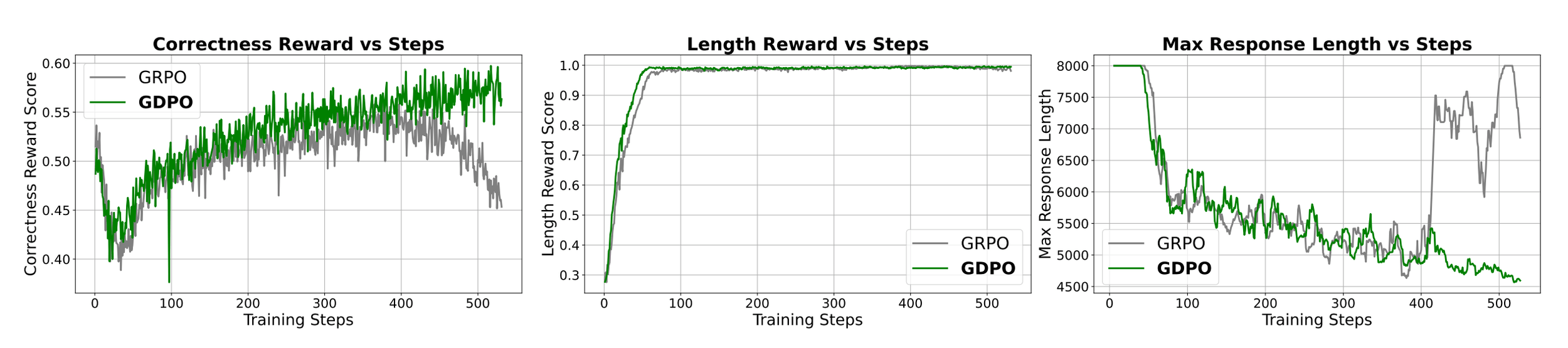
We see that GRPO training starts to destabilize after 400 steps with the correctness rewards score gradually decreasing while GDPO continue to improve the correctness score.
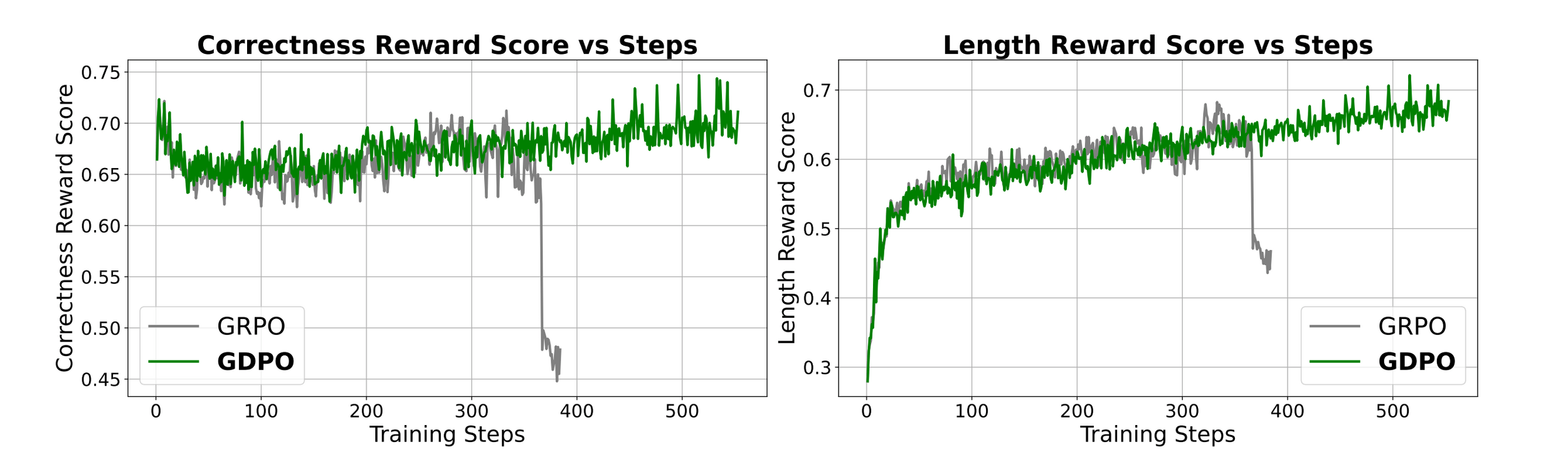
Experiment 2: Mathematical reasoning
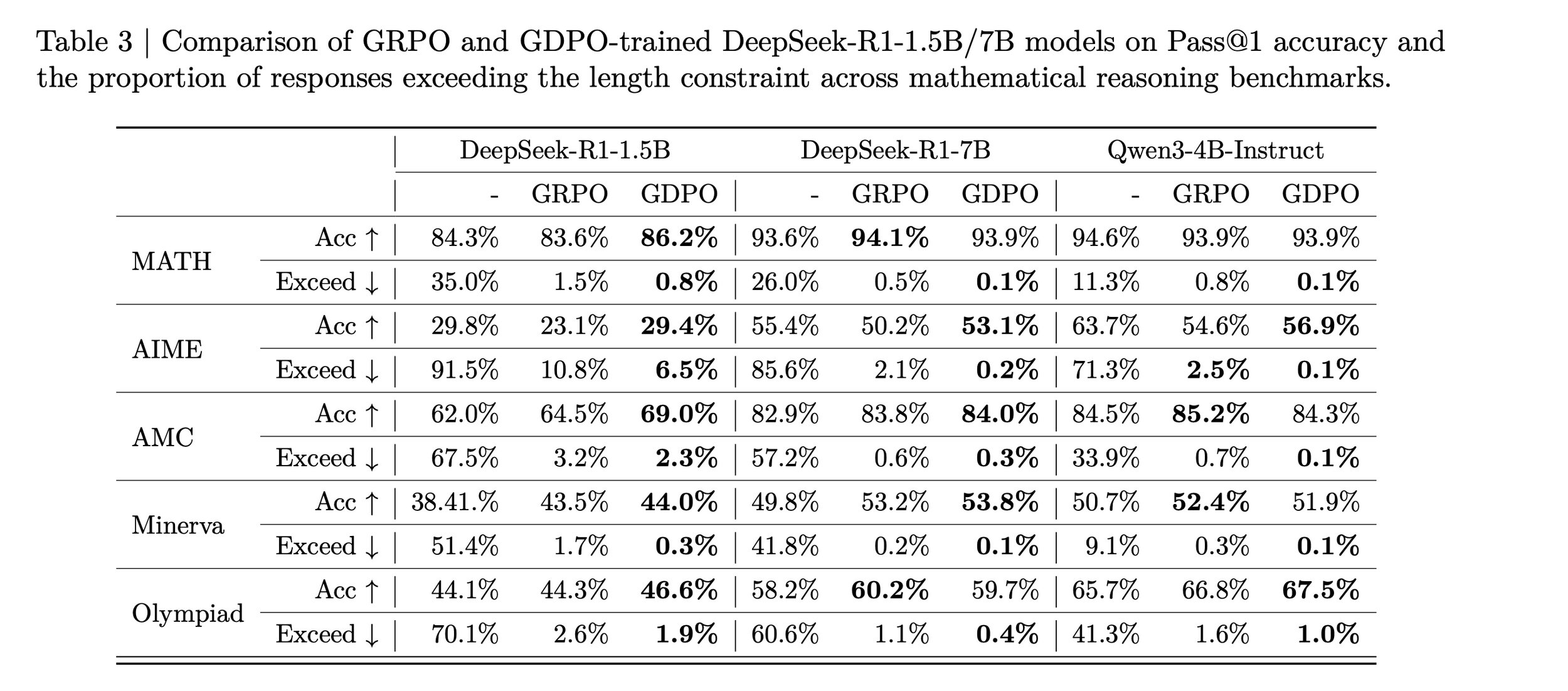
Experiment 3: Coding Reasoning

Experiment 3: Coding Reasoning