ads recommendation in a collapsed and entangled world
Junwei Pan, Wei Xue, Ximei Wang, Haibin Yu, Xun Liu, Shijie Quan, Xueming Qiu, Dapeng Liu, Lei Xiao, Jie Jiang
tencent ads @kdd '24
yuan meng
november 22, 2024
ml journal club @doordash
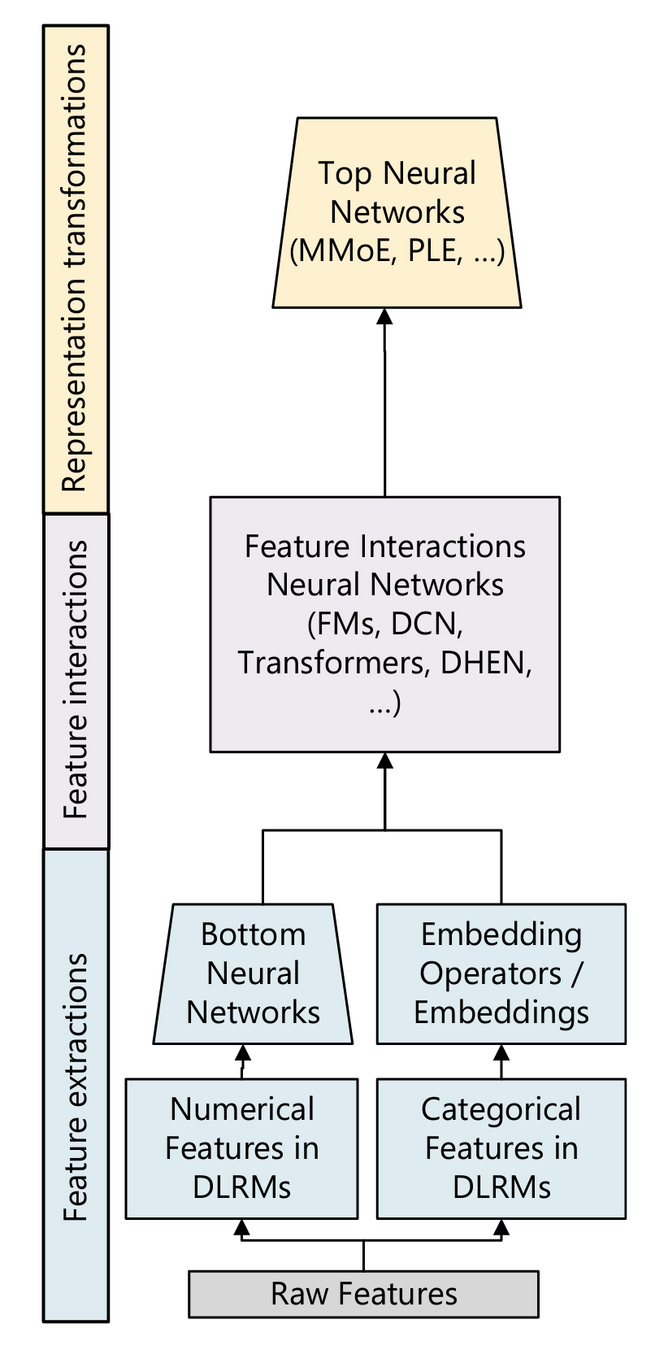
overview: deep learning recommender systems
-
feature extractions/encoding
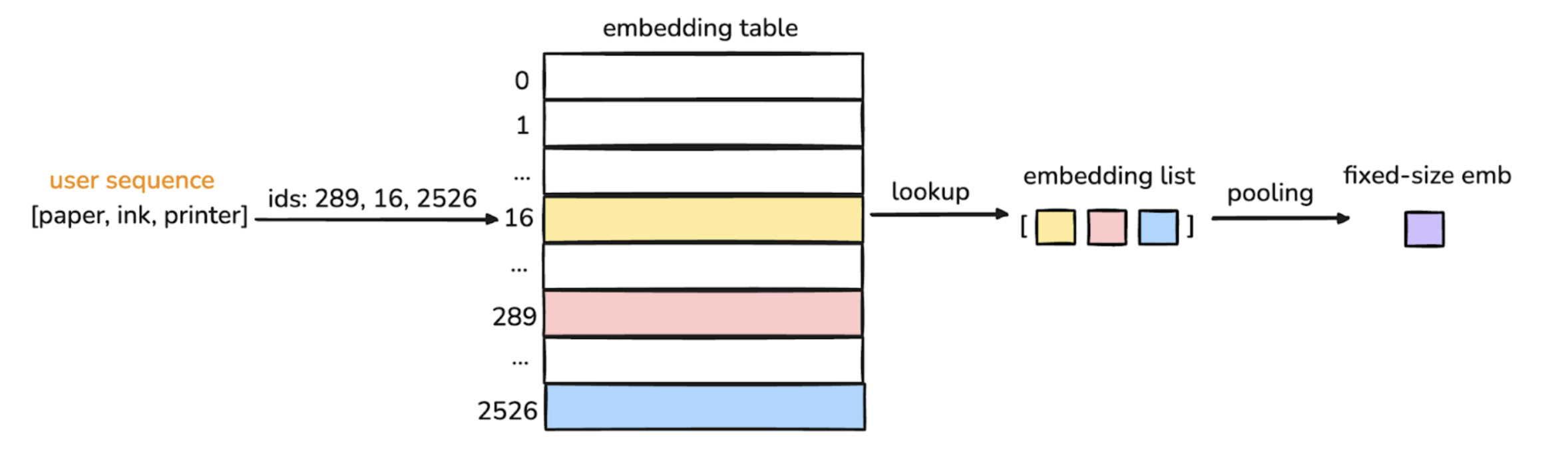
- sequence features: lookup + pooling
- numeric features: scale + normalize
- embedding features: lookup
- feature interactions: FM, DCN-v2, attention... 👉 ensemble: DHEN
- representation transformation: experts control which features to use in what ways in which tasks
meta mrs @icml '24
improve a DLRM: better feature interactions, better ways to transform features, longer user sequences...
bag of tricks
- feature extractions/encoding: sequence + ordinal features
- feature interactions: embedding dimensional collapse
- feature transformations: interest entanglement
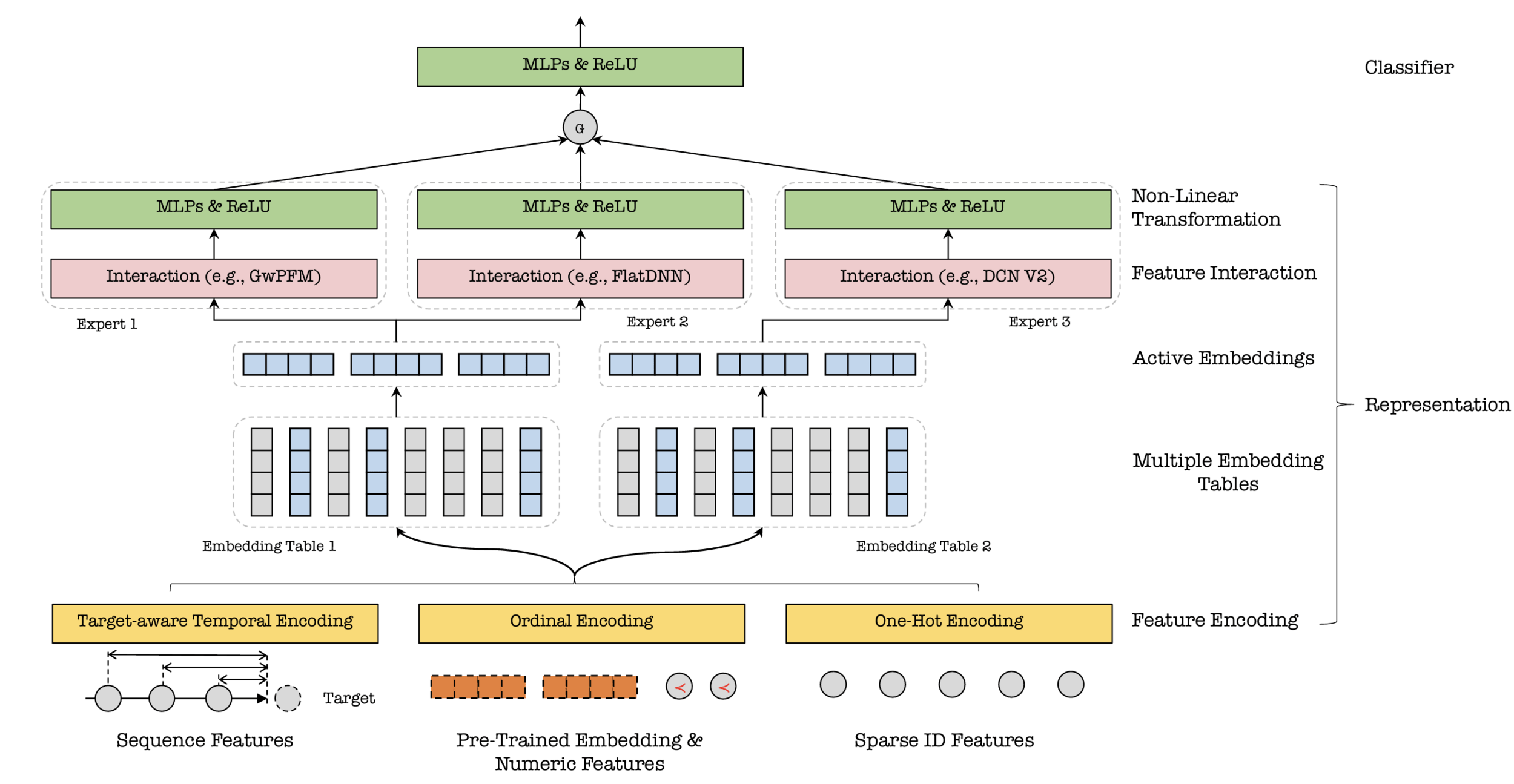
feature encoding
sequence features (read more)
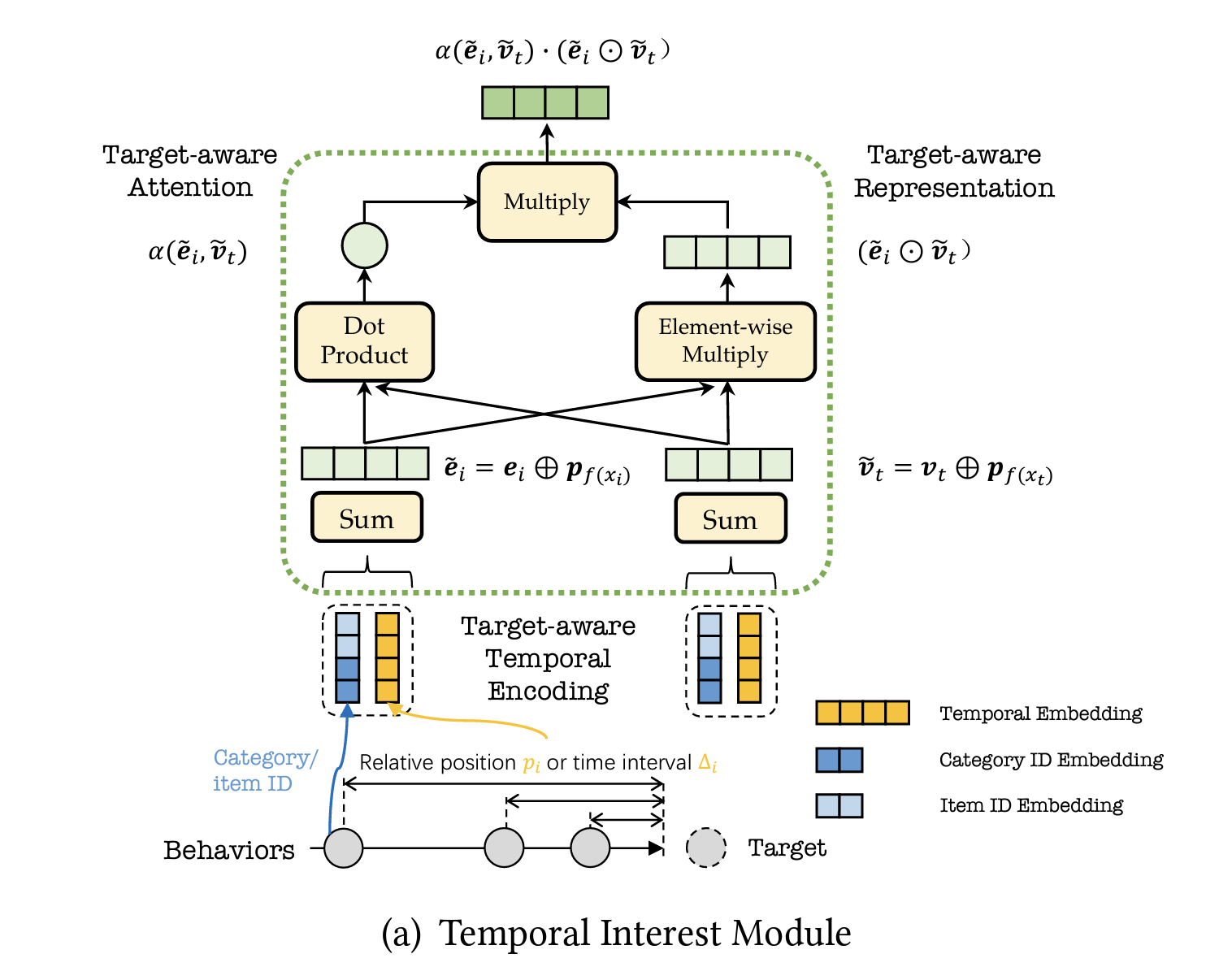
temporal interest module (tim)
- motivation: items interacted more recently & semantically closer to target should be weighted more
- formula: target attention (e.g., din, dien), but w/ temporal + semantic info
temporally encoded embedding
temporal encoding: time delta since action
target-aware attention
target-aware representation (feature interaction)
not all actions are equal
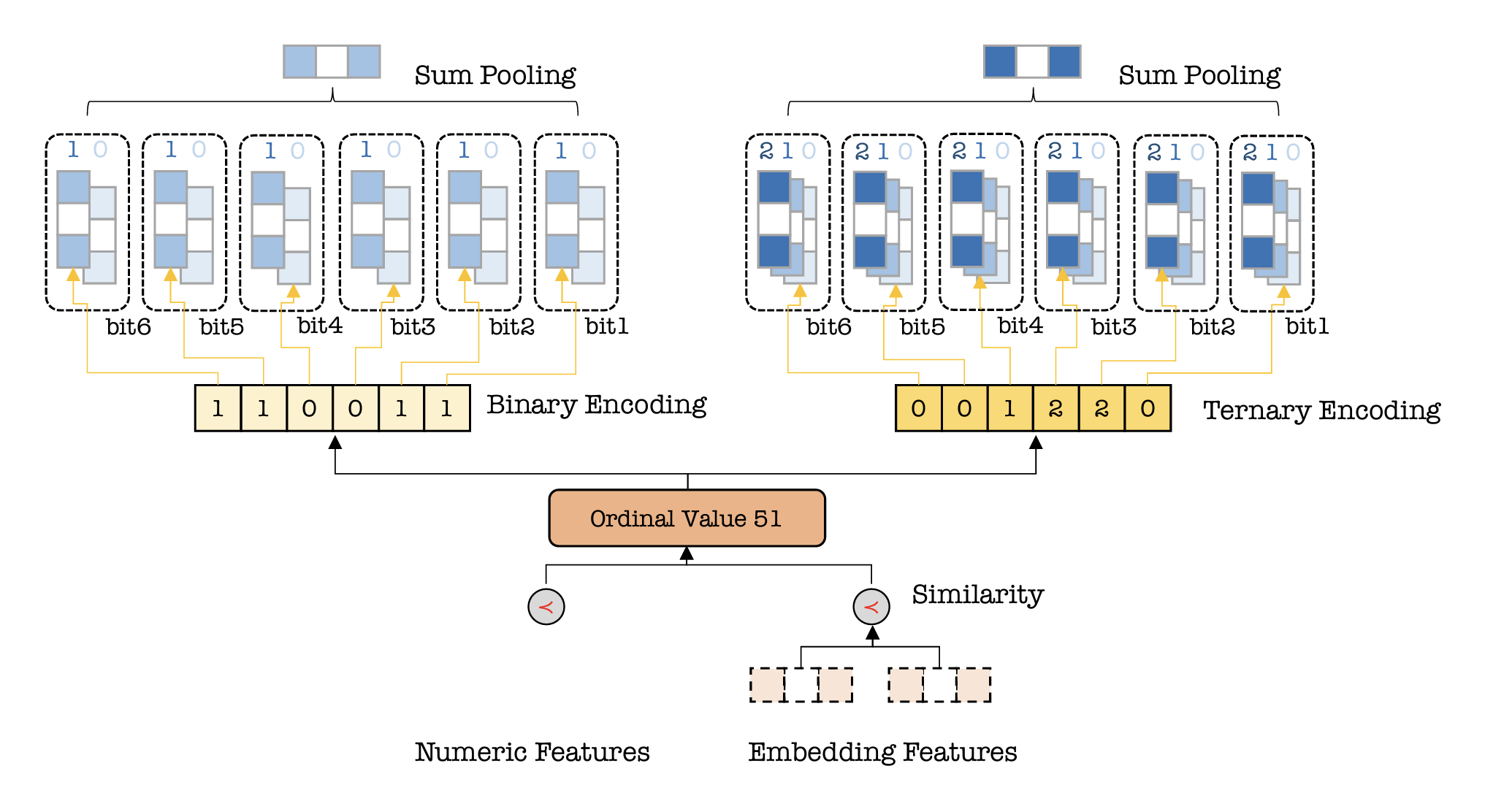
multiple numeral systems encoding (mnse)
- motivation: preserve ordinality 👉 age 51 is closer to 50 than to 60
-
encoding: e.g., "51" mapped into multiple numeral systems
-
binary: 6_1, 5_1, 4_0, 3_0, 2_1, 1_1
- ternary: 6_0, 5_0, 4_1, 3_2, 2_2, 1_0
-
-
embedding: project each bit into a learnable embedding 👉 in each system, sum pool bit embs 👉 for each number, concat pooled emb from each system for ranking
- "learning": e.g., 1_1 and 1_0 are closer than, say, 5_0 and 5_1
feature encoding
numeric features (ordinal)
concat before passing to ranking
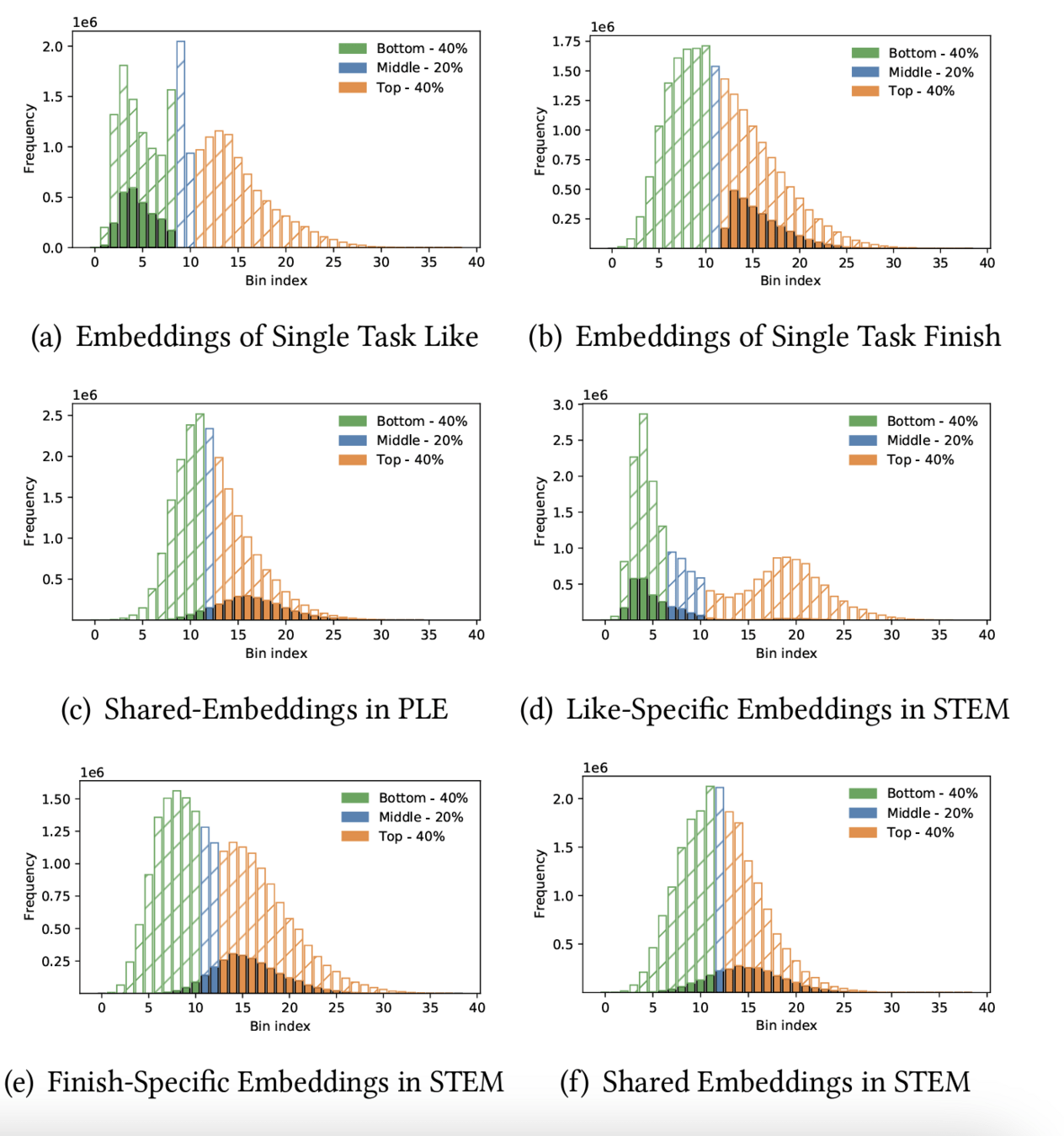
dimensional collapose
phenomenon & root cause (read more)
- discovery: increasing emb size (64 👉 192) doesn't always improve model performance (and can hurt sometimes...)
-
phenomenon: embs only span a small subspace of available dimension!!
- super wasteful: 99.9% tencent ads model params are dedicated to emb features
-
root cause: explicit feature interaction
- feature 1: gender 👉 low cardinality
- feature 2: item taxonomy 👉 high cardinality
- after interaction: only spans min(dim_feature1, dim_feature2)
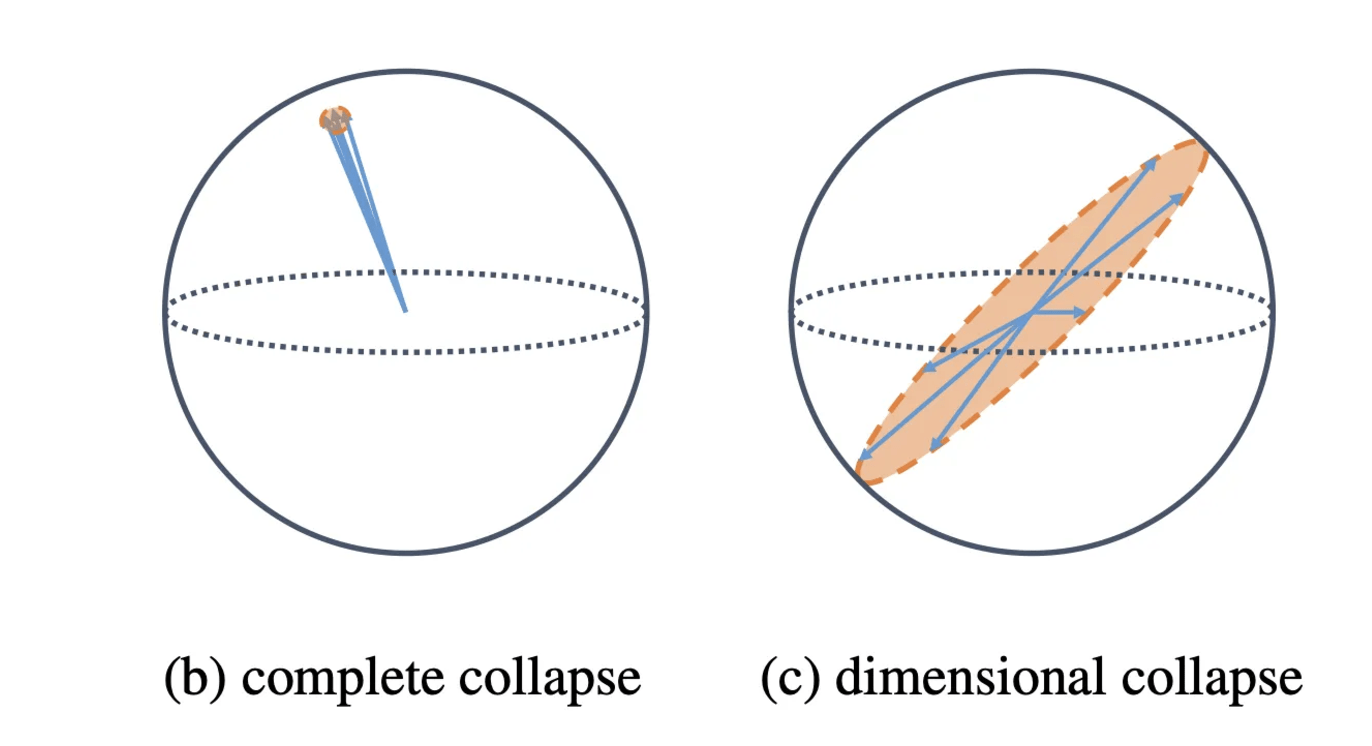
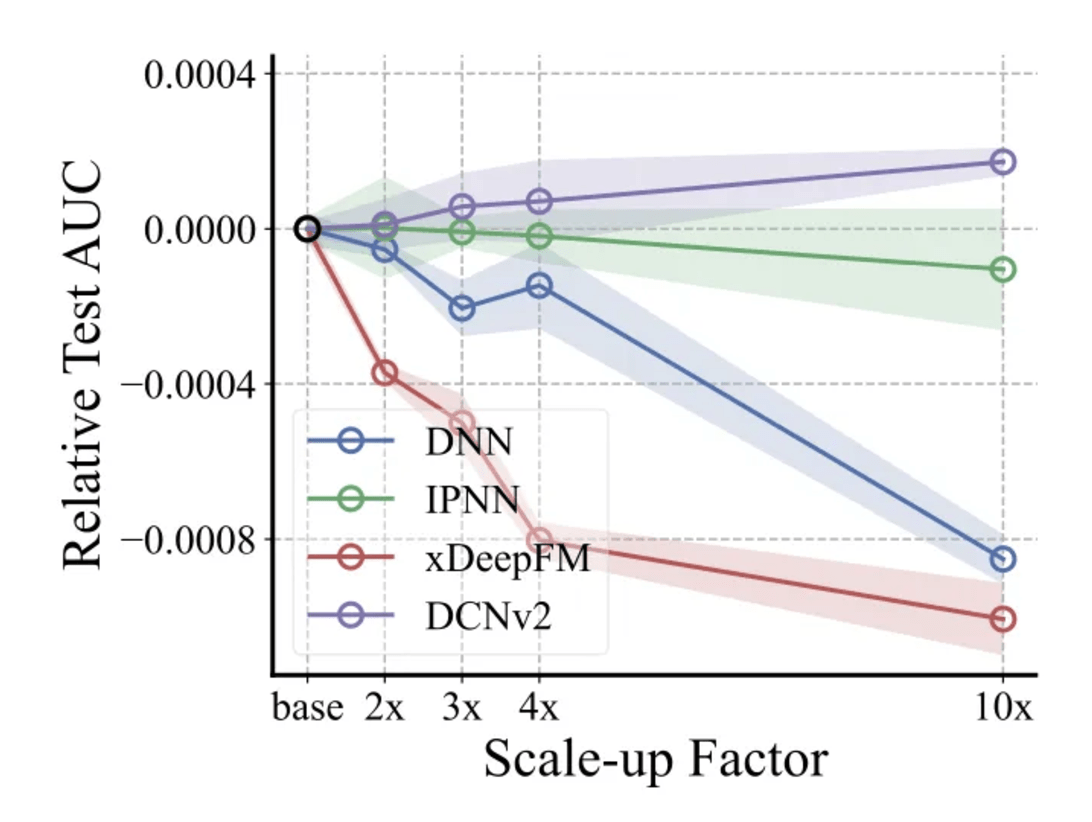
diagnose: svd 👉 watch out for vanishing singular values
dimensional collapose
solution: multi-embedding paradigm
- multi-embedding: each feature has multiple embedding tables
- heterogeneous mixture-of-experts: use different embeddings in different interaction modules (i.e., GwPFM, FlatDNN, DCN V2)
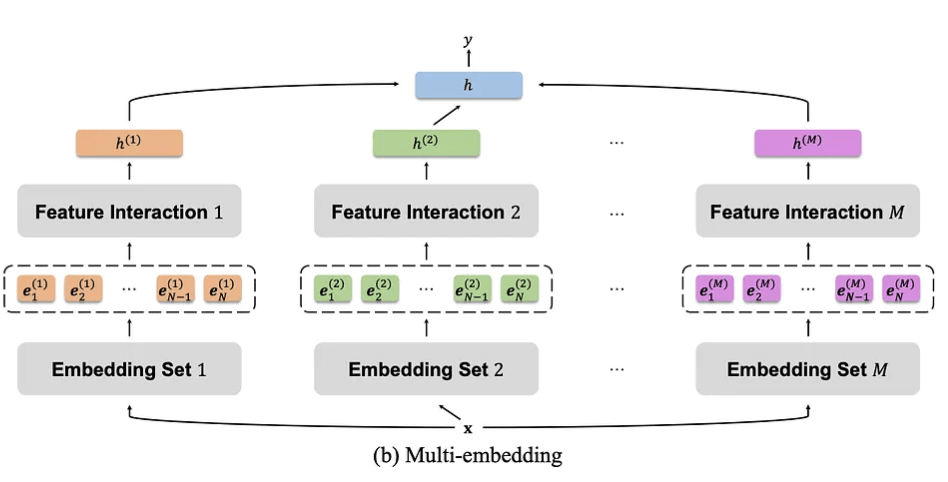
different emb tables collapse differently, preserving more information than a single table...
biggest gmv gain for tencent: 3.9% rel lift
interest entanglement
beyond mmoe and ple
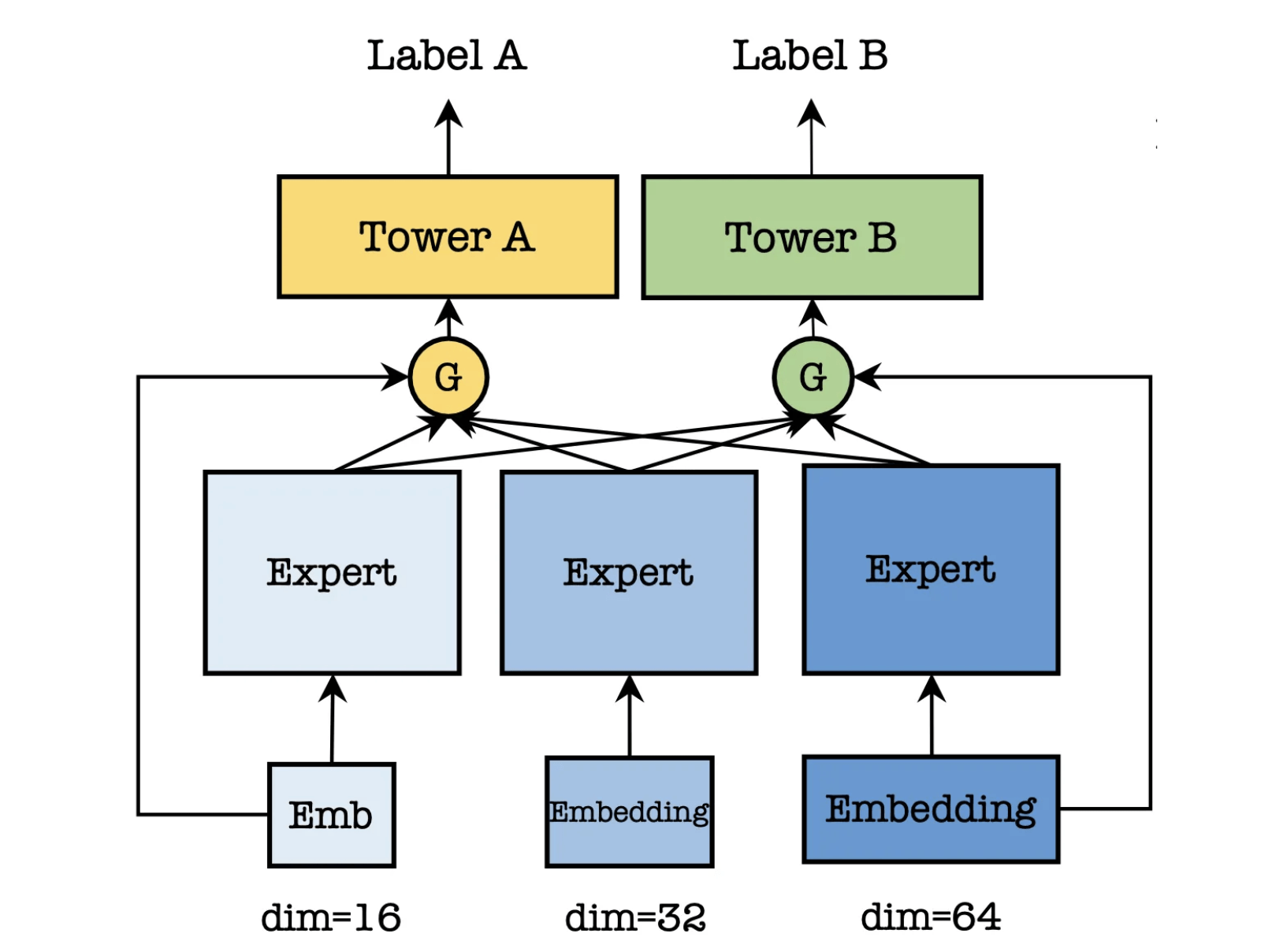
-
observation: users have different interests in different scenarios and tasks
- ads surfaces: moments (social feed), official accounts (subscription), tencent video (long video), channels (short video), tencent news...
- tasks: even just for "conversion" that sounds like one task, each conversion type is a task
- problem: same user-item pair may be close in one scenario/task and far part in another... 👉 may result in negative transfer
-
solution: asymmetric multi-embedding (ame)
- each task group (e.g., different conversion types) has a fixed number of embs tables of diff sizes
- small tasks are routed to smaller embs via gating
read more
- sam flender @meta
- coding monkey @linkedin
- yuan's blogpost on sequential user modeling
- new from tencent ads: scaling laws for online advertisement retrieval