Decision Making under Uncertainty for Safe and Efficient Autonomy
Zachary Sunberg
Background







Two Objectives for Autonomy
EFFICIENCY
SAFETY
Minimize resource use
(especially time)
Minimize the risk of harm to oneself and others

Safety often opposes Efficiency

Tweet by Nitin Gupta
29 April 2018
https://twitter.com/nitguptaa/status/990683818825736192
Pareto Optimization
Safety
Better Performance
Model \(M_2\), Algorithm \(A_2\)
Model \(M_1\), Algorithm \(A_1\)
Efficiency
$$\underset{\pi}{\mathop{\text{maximize}}} \, V^\pi = V^\pi_\text{E} + \lambda V^\pi_\text{S}$$
Safety
Weight
Efficiency

Markov Decision Process (MDP)
- \(\mathcal{S}\) - State space
- \(T:\mathcal{S}\times \mathcal{A} \times\mathcal{S} \to \mathbb{R}\) - Transition probability distribution
- \(\mathcal{A}\) - Action space
- \(R:\mathcal{S}\times \mathcal{A} \to \mathbb{R}\) - Reward

Partially Observable Markov Decision Process (POMDP)

- \(\mathcal{S}\) - State space
- \(T:\mathcal{S}\times \mathcal{A} \times\mathcal{S} \to \mathbb{R}\) - Transition probability distribution
- \(\mathcal{A}\) - Action space
- \(R:\mathcal{S}\times \mathcal{A} \to \mathbb{R}\) - Reward
- \(\mathcal{O}\) - Observation space
- \(Z:\mathcal{S} \times \mathcal{A}\times \mathcal{S} \times \mathcal{O} \to \mathbb{R}\) - Observation probability distribution
POMDP Sense-Plan-Act Loop
Environment
Belief Updater
Policy/Planner
\(b\)
\(a\)
\[b_t(s) = P\left(s_t = s \mid a_1, o_1 \ldots a_{t-1}, o_{t-1}\right)\]

True State
\(s = 7\)
Observation \(o = -0.21\)
POMDPs in Aerospace




1) ACAS
2) Orbital Object Tracking
4) Asteroid Navigation
3) Dual Control
ACAS X
Trusted UAV
Collision Avoidance
[Sunberg, 2016]
[Kochenderfer, 2011]
POMDPs in Aerospace
\(\mathcal{S}\): Information space for all objects
\(\mathcal{A}\): Which objects to measure
\(R\): - Entropy
Approximately 20,000 objects >10cm in orbit
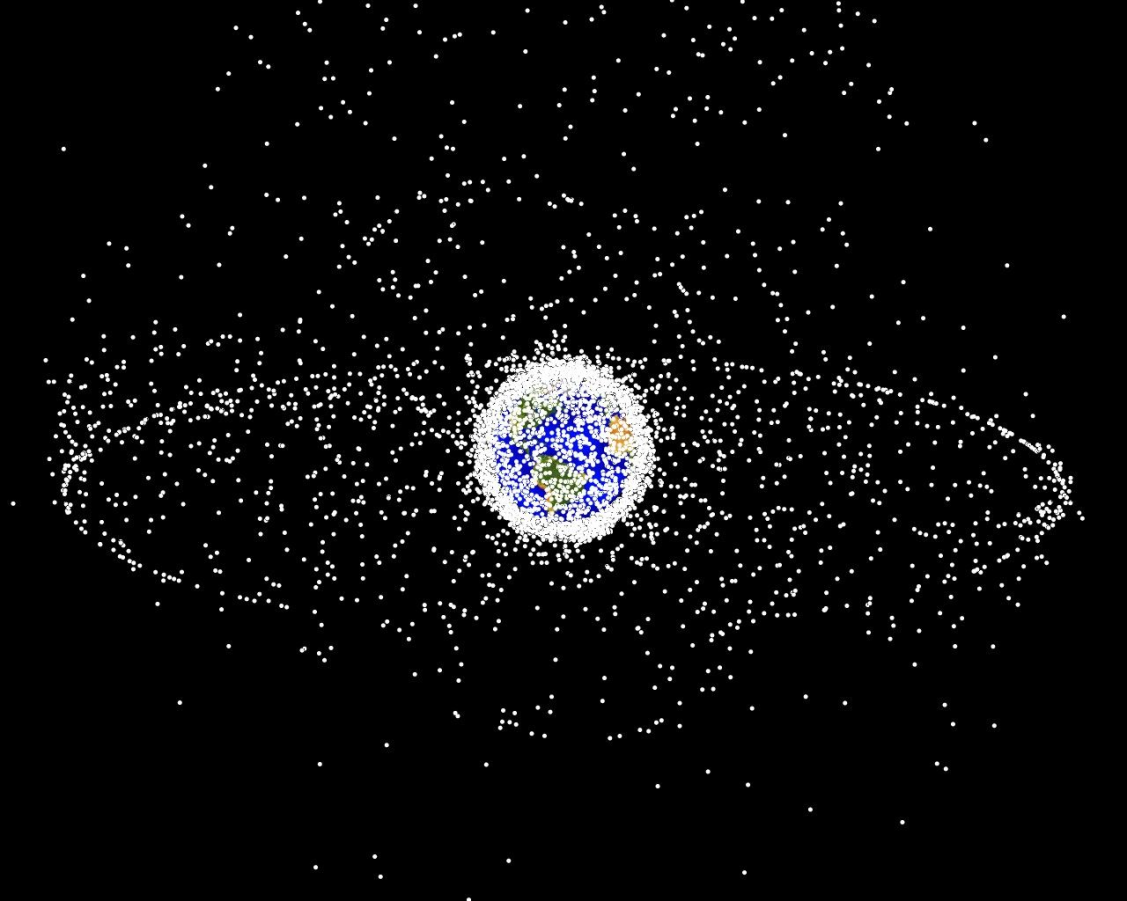
[Sunberg, 2016]
1) ACAS
2) Orbital Object Tracking
4) Asteroid Navigation
3) Dual Control
POMDPs in Aerospace


State \(x\) Parameters \(\theta\)
\(s = (x, \theta)\) \(o = x + v\)
POMDP solution automatically balances exploration and exploitation
[Slade, Sunberg, et al. 2017]
1) ACAS
2) Orbital Object Tracking
4) Asteroid Navigation
3) Dual Control
POMDPs in Aerospace
Dynamics: Complex gravity field, regolith
State: Vehicle state, local landscape
Sensor: Star tracker?, camera?, accelerometer?
Action: Hopping actuator
[Hockman, 2017]
1) ACAS
2) Orbital Object Tracking
4) Asteroid Navigation
3) Dual Control
Solving MDPs - The Value Function
$$V^*(s) = \underset{a\in\mathcal{A}}{\max} \left\{R(s, a) + \gamma E\Big[V^*\left(s_{t+1}\right) \mid s_t=s, a_t=a\Big]\right\}$$
Involves all future time
Involves only \(t\) and \(t+1\)
$$\underset{\pi:\, \mathcal{S}\to\mathcal{A}}{\mathop{\text{maximize}}} \, V^\pi(s) = E\left[\sum_{t=0}^{\infty} \gamma^t R(s_t, \pi(s_t)) \bigm| s_0 = s \right]$$
$$Q(s,a) = R(s, a) + \gamma E\Big[V^* (s_{t+1}) \mid s_t = s, a_t=a\Big]$$
Value = expected sum of future rewards
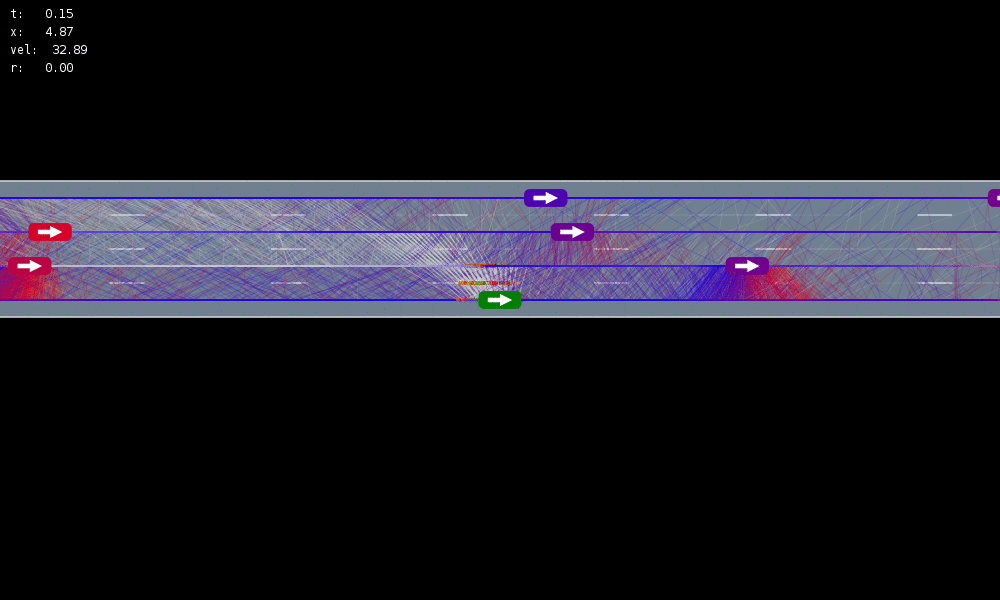
Tree Search Planning

Time
Estimate \(Q(s, a)\) based on children
$$Q(s,a) = R(s, a) + \gamma E\Big[V^* (s_{t+1}) \mid s_t = s, a_t=a\Big]$$
\[V(s) = \max_a Q(s,a)\]
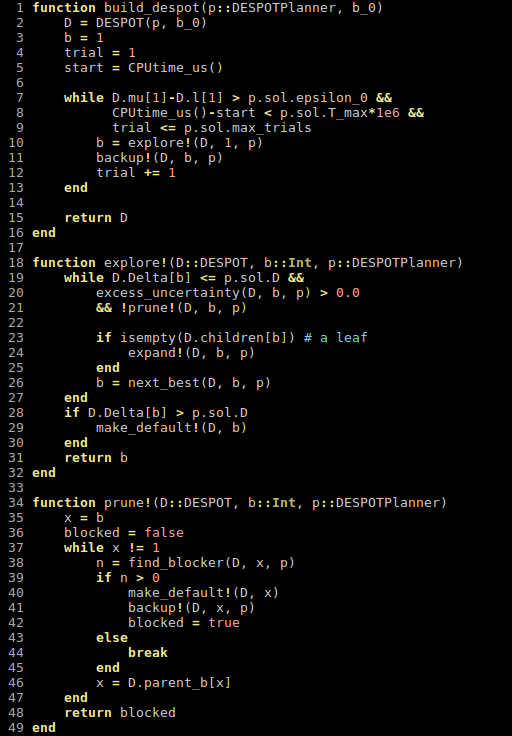
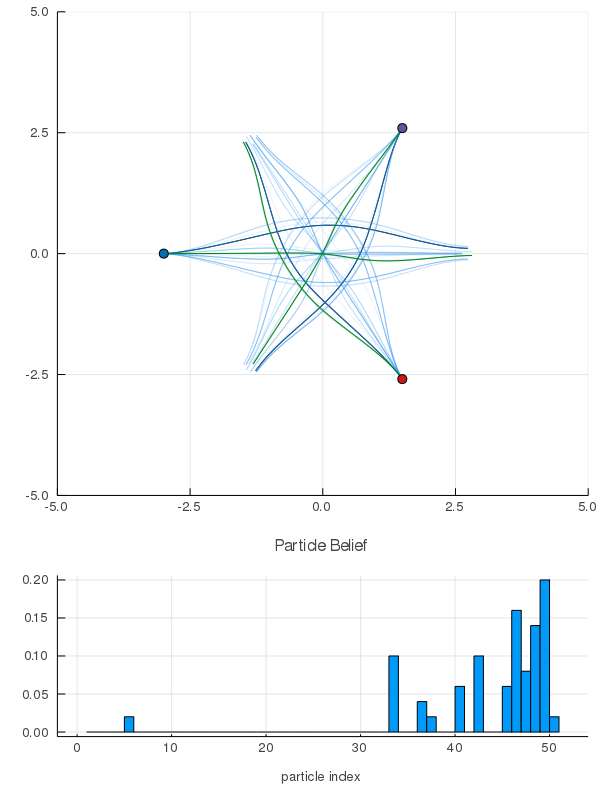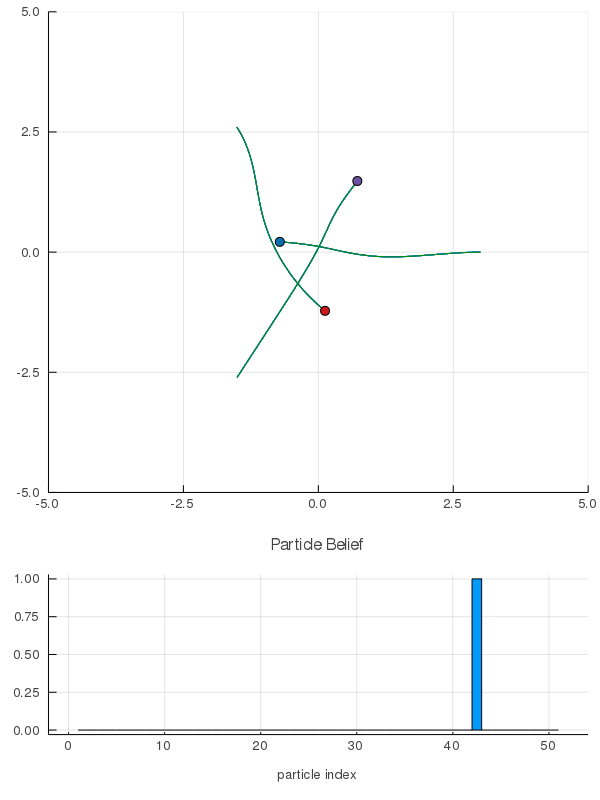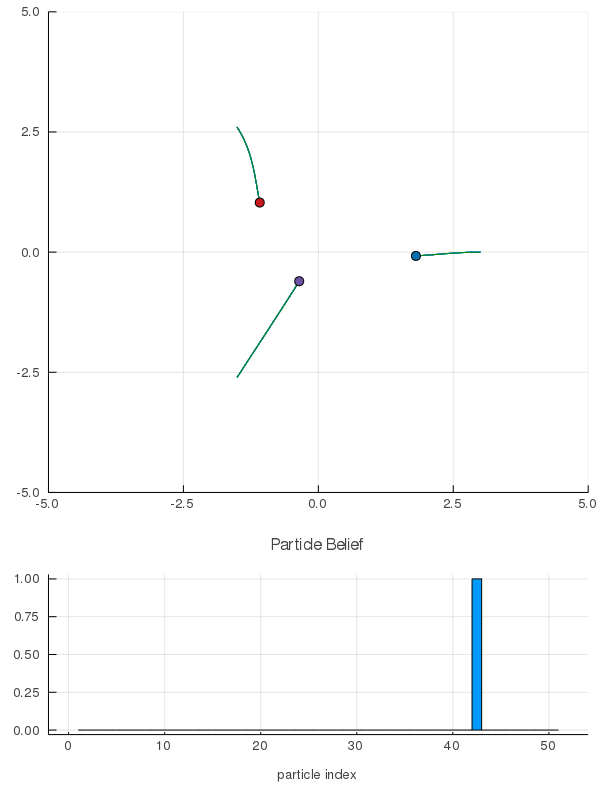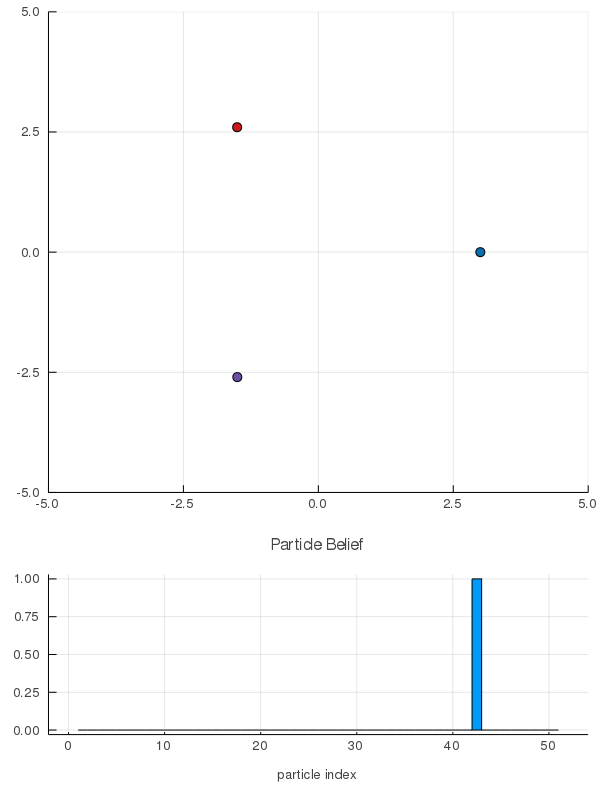
- A POMDP is an MDP on the Belief Space but belief updates are expensive
- POMCP* uses simulations of histories instead of full belief updates
- Each belief is implicitly represented by a collection of unweighted particles


[Ross, 2008] [Silver, 2010]
*(Partially Observable Monte Carlo Planning)



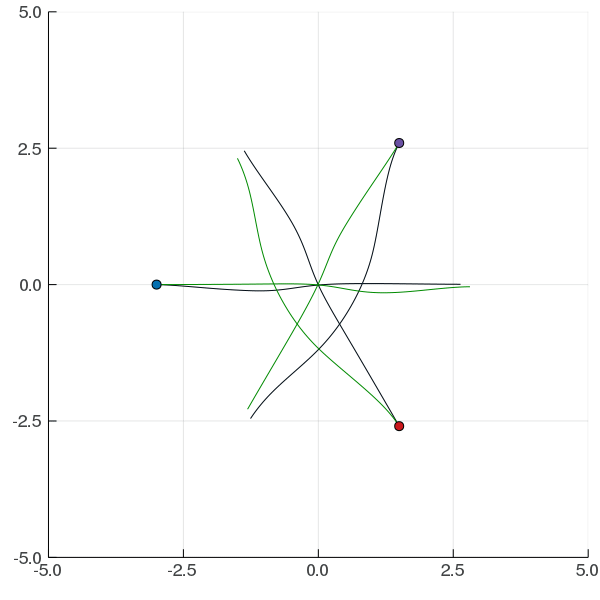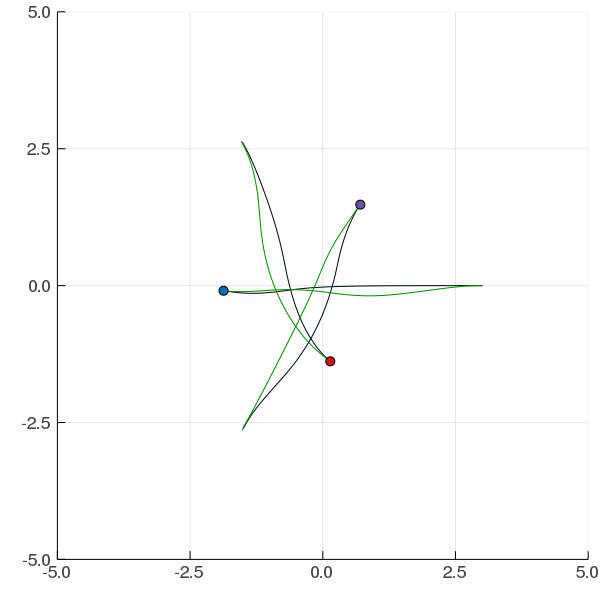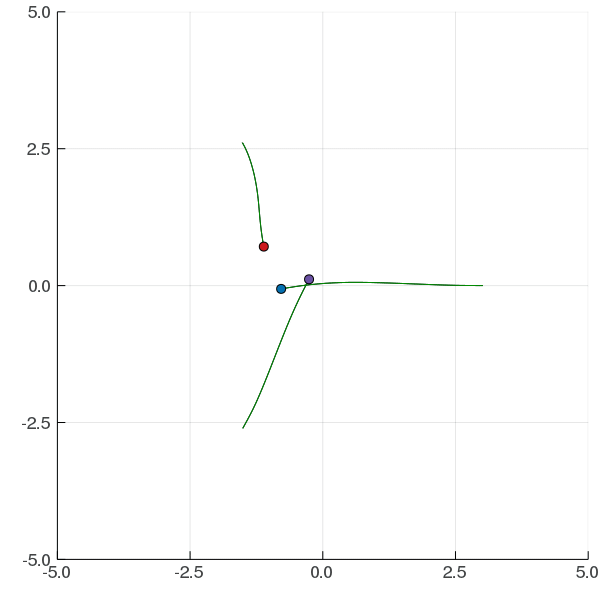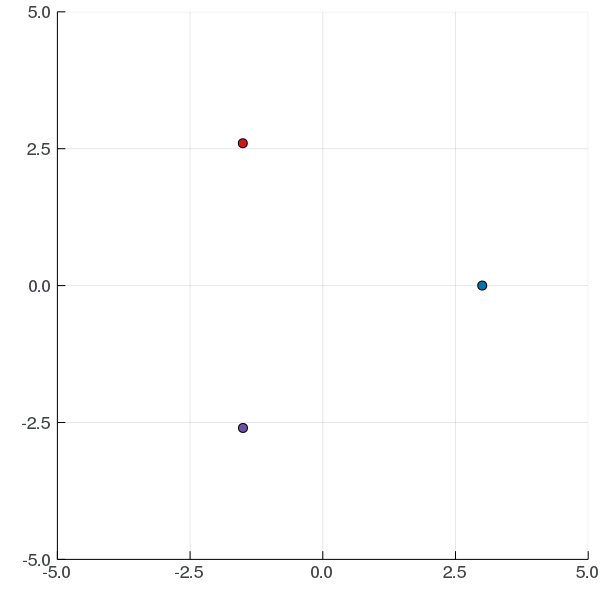
POMCP
POMCP-DPW
POMCPOW
(Silver, 2010)
(Sunberg, 2017)
(Sunberg, 2018)
[Sunberg and Kochenderfer, ICAPS 2018]






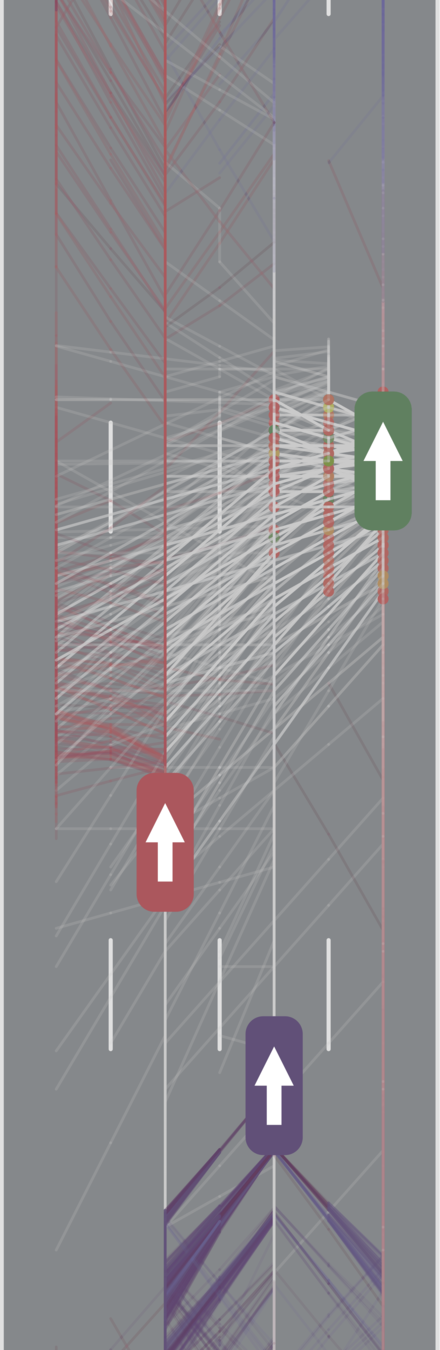
MDP trained on normal drivers



MDP trained on all drivers
Omniscient
POMCPOW (Ours)
Simulation results
[Sunberg & Kochenderfer, T-ITS Under Review]
Current Projects
Continuous Action Spaces
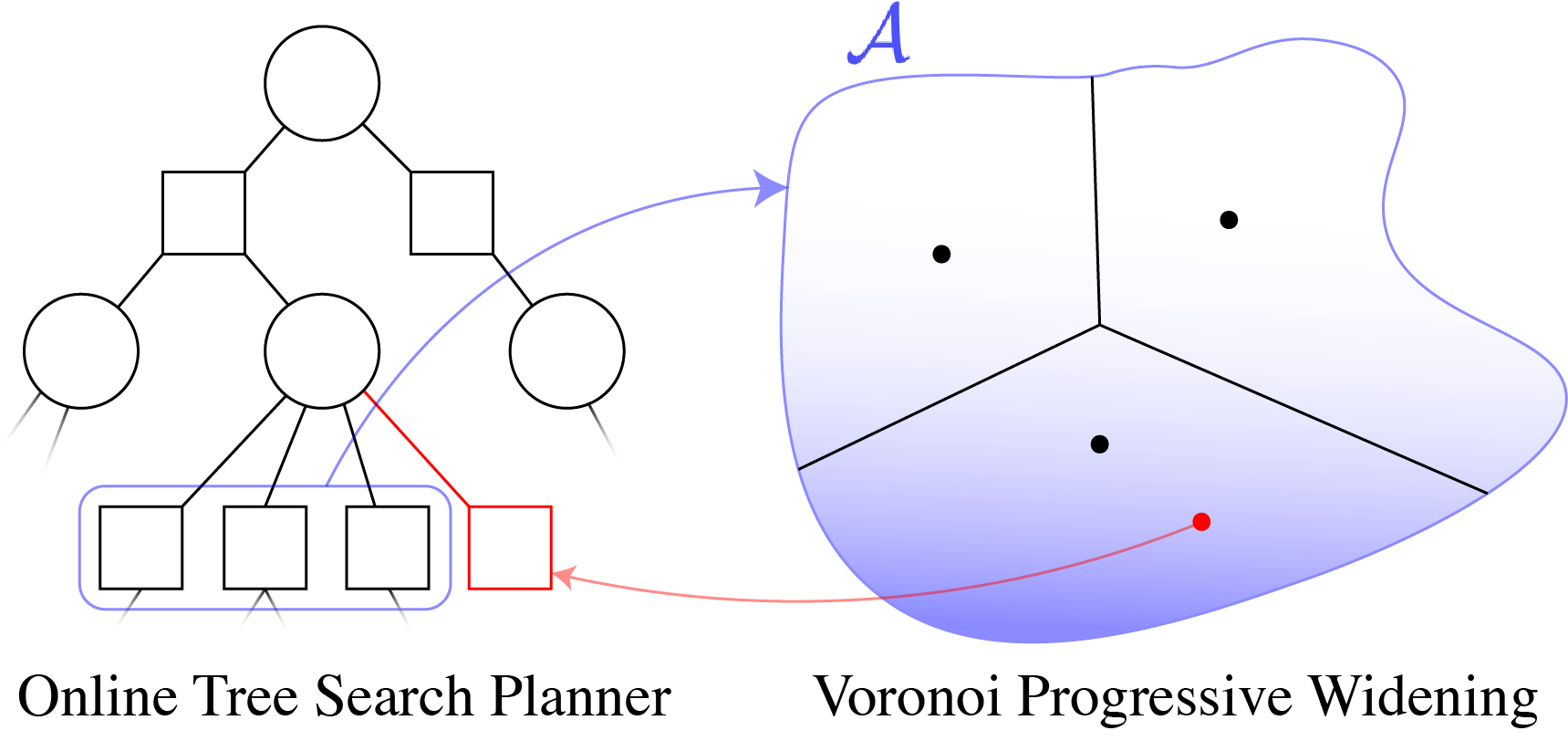
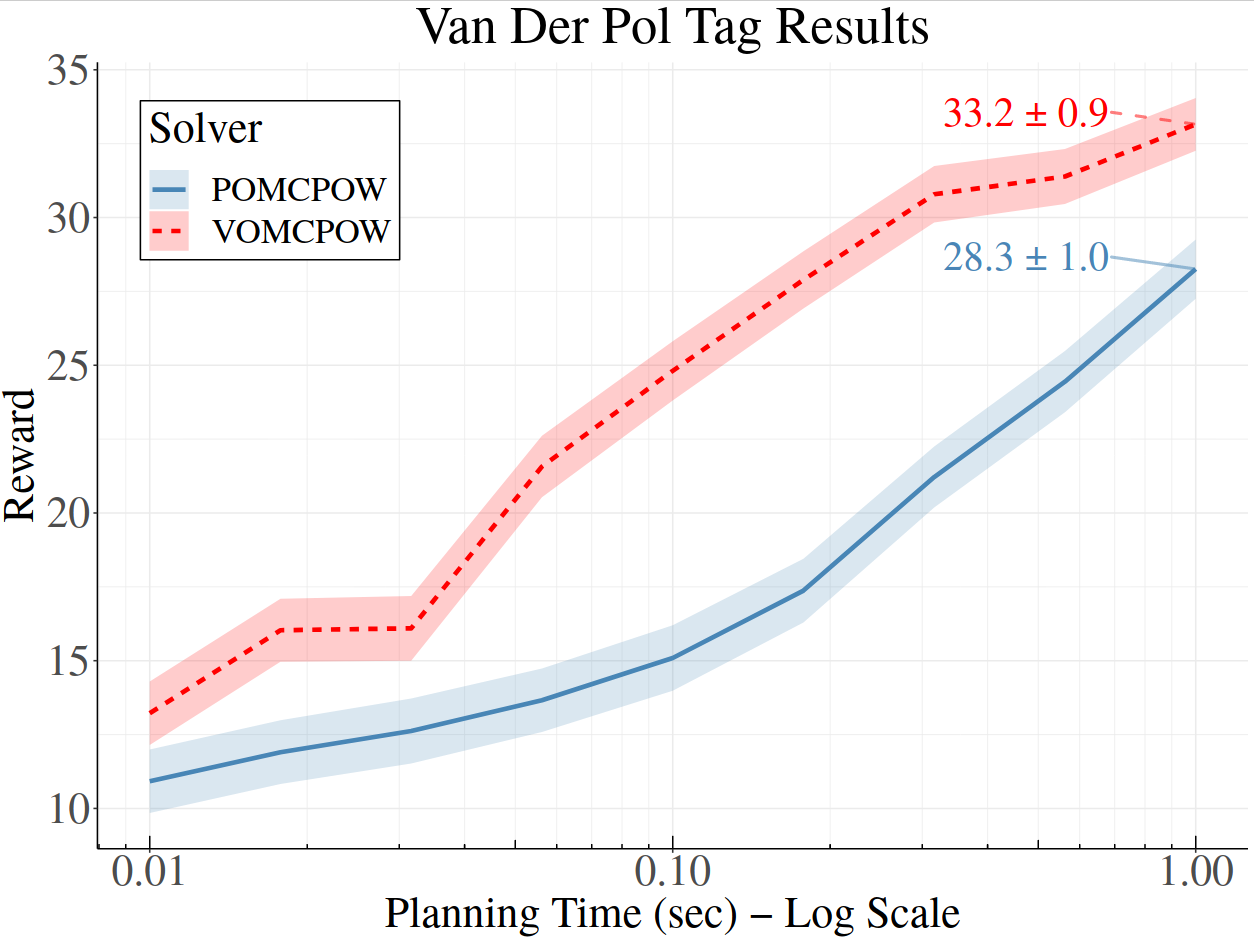

[Lim, Tomlin, & Sunberg CDC 2021 (Submitted)]
Responding to UAV Emergencies
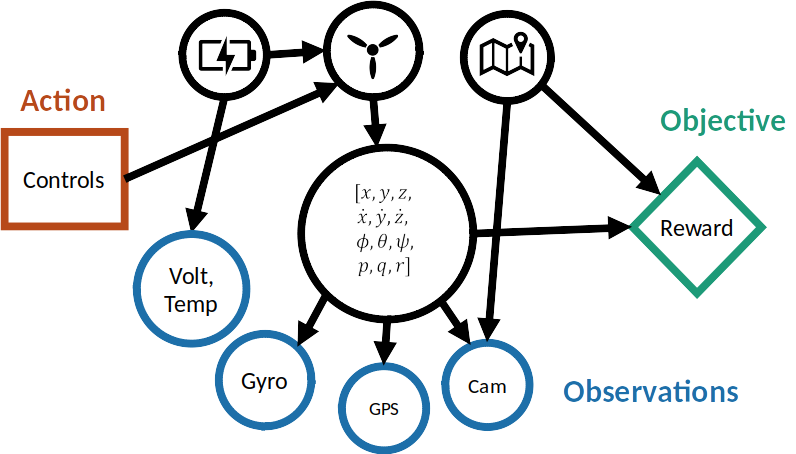
POMDPs with High-Dimensional Observations

Active Information Gathering for Safety
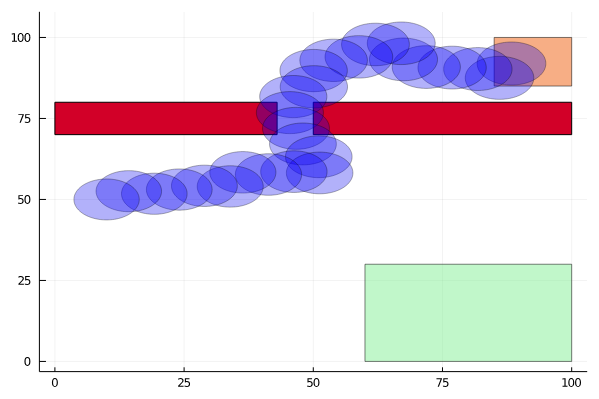
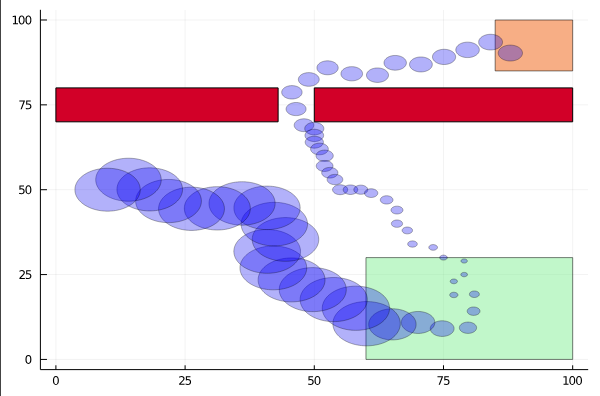
Open Source Software
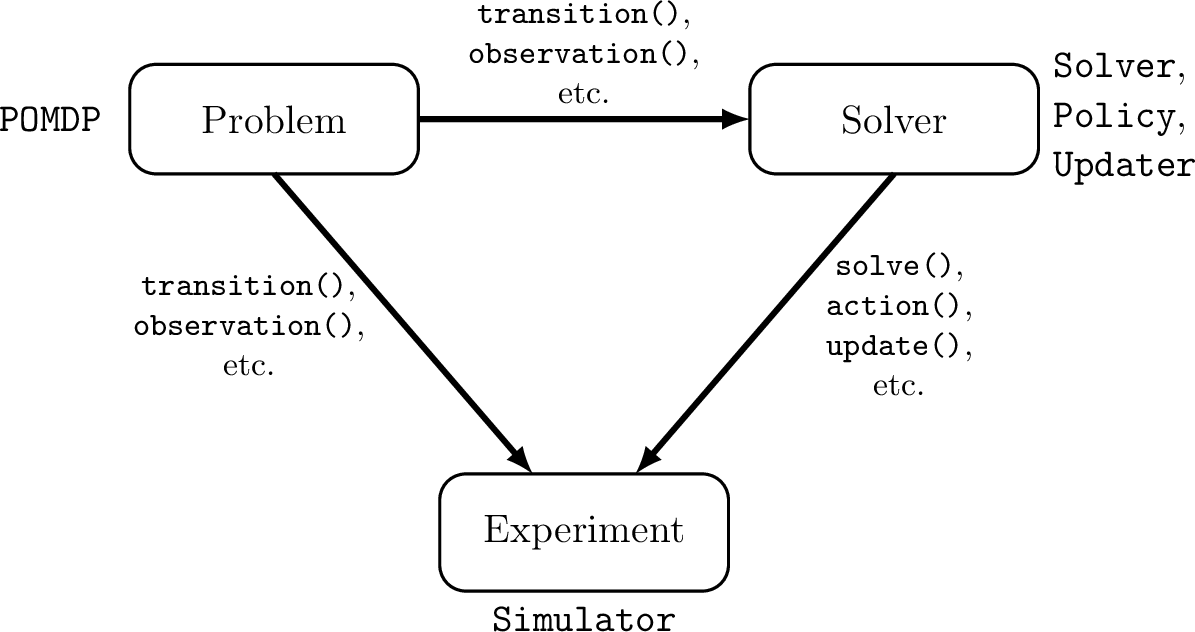
POMDPs.jl - An interface for defining and solving MDPs and POMDPs in Julia
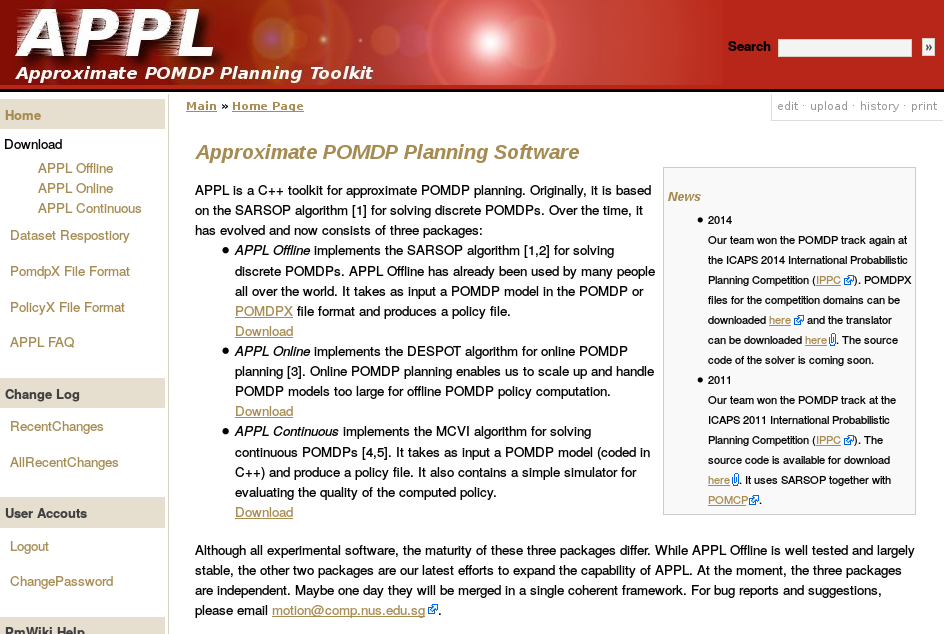
Previous C++ framework: APPL
"At the moment, the three packages are independent. Maybe one day they will be merged in a single coherent framework."

Julia - Speed

Celeste Project
1.54 Petaflops



Group






Thank You!

Types of Uncertainty
Alleatory
Static Epistemic
Dynamic Epistemic



MDP
Uncertain MDP (RL)
POMDP
Games

[Peters, Sunberg, et al. AAMAS 2020]