Design Part 1
What is design?
give a higher level architecture and design an entire system rather than some individual components
System Design Interview
-
No correct answer
-
Very vague problem, e.g. design twitter, design instagram, design a message queue
-
Lots of tradeoff discussions
-
Need to dive into multiple areas
-
Some patterns to follow
-
Need to drive the conversation
System Design Axes
-
Problem Navigation
-
Demonstrates the ability to organize the problem space, the constraints, and potential solution(s).
-
Asks questions to systematically reduce ambiguity, target the most important problems to solve for, understand what's needed for a quantitative analysis, and define a requirement set to design to.
-
Demonstrates awareness of the product from an end-user perspective
-
-
Solution Design
-
Design a working solution
-
Account for scalability
-
Thoughtfully approach layers + organization and design with user experience in mind
-
Keep scale and multiple developer scenarios in mind
-
System Design Axes
-
Technical Excellence
-
Dives deeply into technical details when necessary.
-
Articulates dependencies and trade-offs in the solution.
-
Identifies and grapples with challenging aspects of the problem, including foreseeing and mitigating potential failure points
-
-
Technical Communication
-
Articulate their technical ideas, viewpoints, trade-offs and vision
-
Logically communicate their reasoning
-
Engages with and grasps feedback and concerns from the interviewer
-
Key Characteristics of Distributed Systems
-
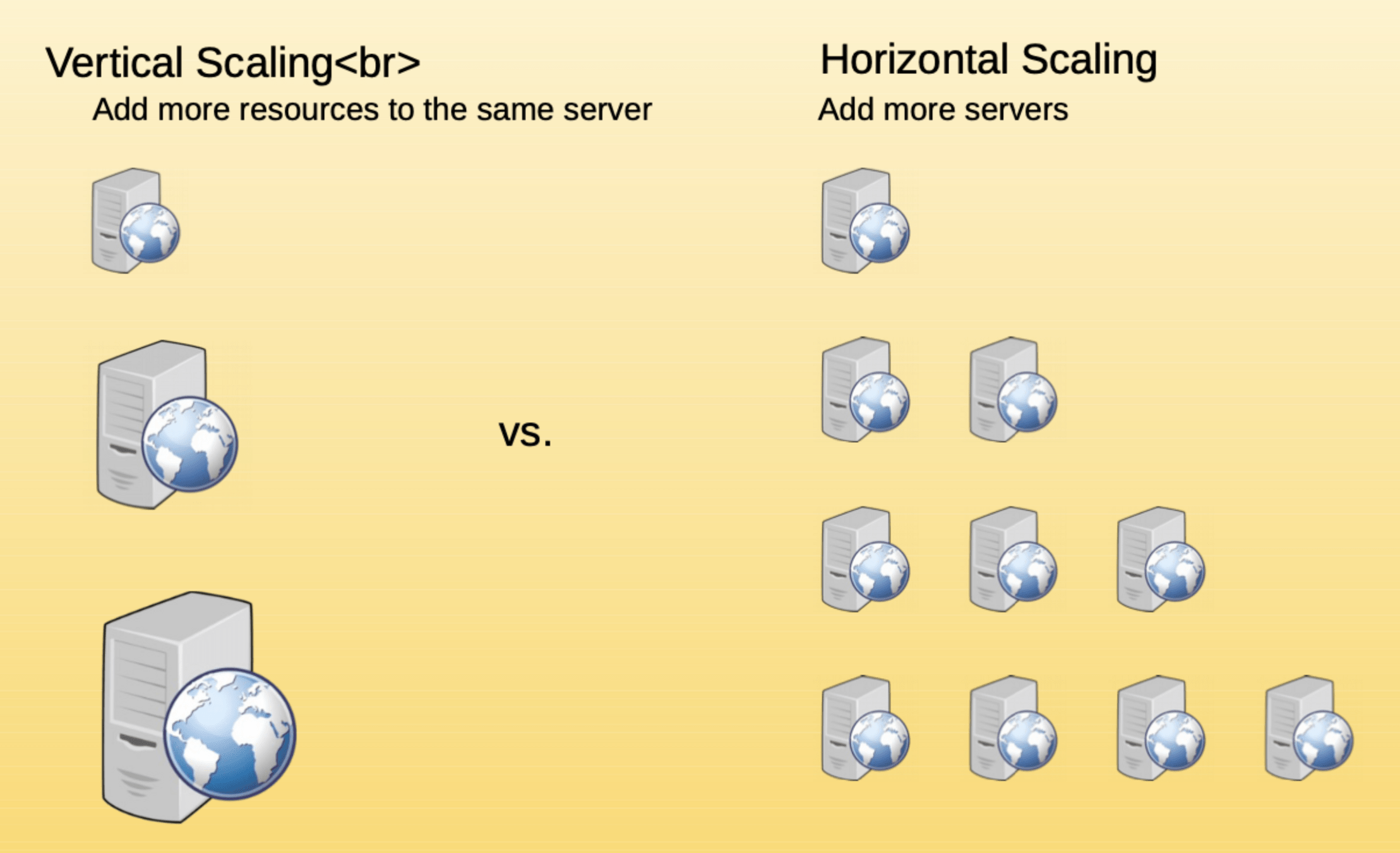
Scalability
-
A system may have to scale because of many reasons like increased data volume or increased amount of work
-
Vertical scaling vs horizontal scaling
-
-
Reliability
-
reliability is the probability a system will fail in a given period.
-
-
Availability
-
availability is the time a system remains operational to perform its required function in a specific period. It is a simple measure of the percentage of time that a system, service, or a machine remains operational under normal conditions
-
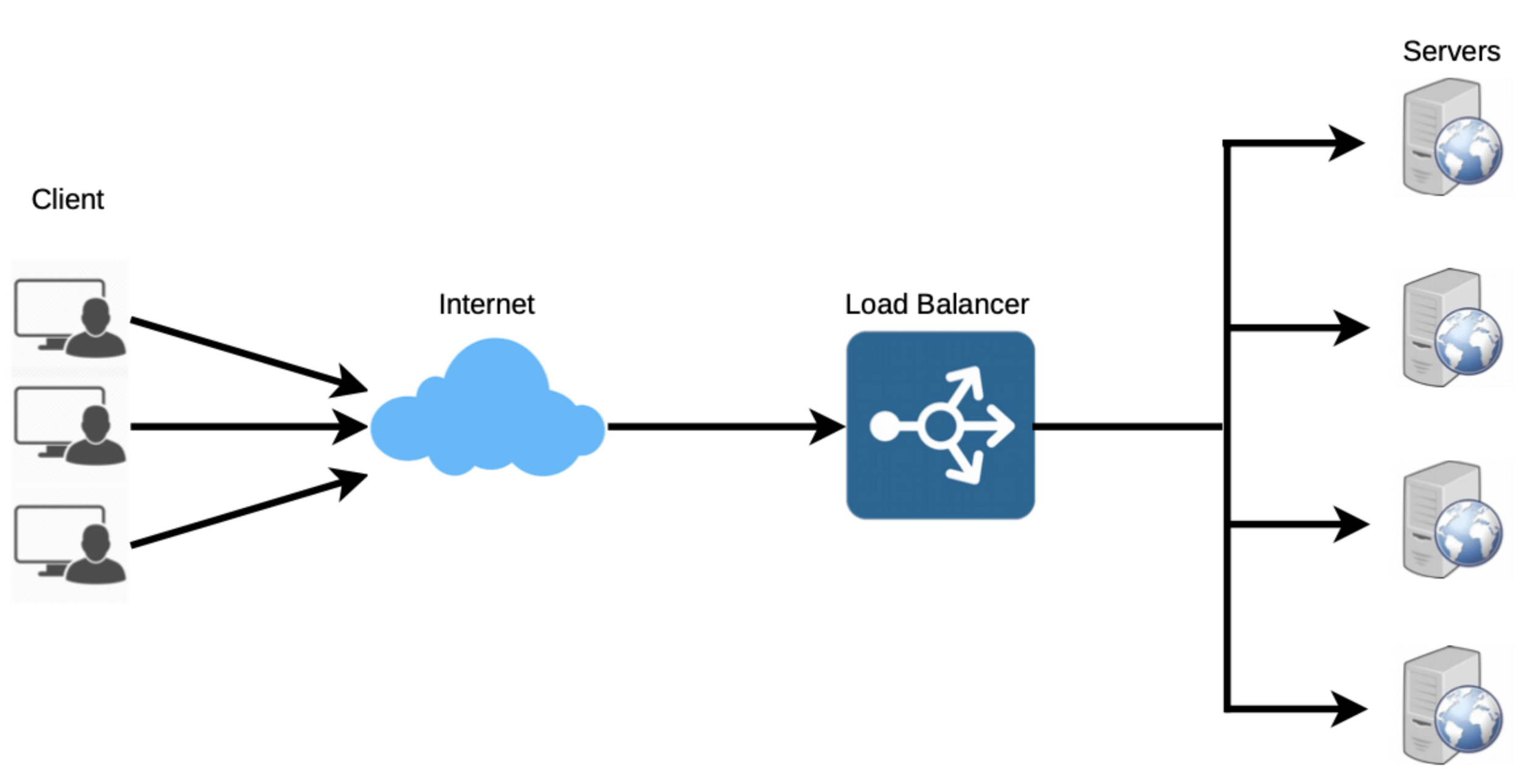
Load balancing
-
It helps to spread the traffic across a cluster of servers to improve responsiveness and availability of applications, websites or databases
-
LB also keeps track of the status of all the resources while distributing requests.
-
load balancer reduces individual server load and prevents any one application server from becoming a single point of failure, thus improving overall application availability and responsiveness.
Load balancing
-
To utilize full scalability and redundancy, we can try to balance the load at each layer of the system. We can add LBs at three places:
-
Between the user and the web server
-
Between web servers and an internal platform layer, like application servers or cache servers
-
Between internal platform layer and database.
-

Load Balancing Algorithms
-
Health Checks - Load balancers should only forward traffic to “healthy” backend servers. To monitor the health of a backend server, “health checks” regularly attempt to connect to backend servers to ensure that servers are listening.
-
Load balancing algorithms
-
Least Connection Method - the fewest active connections.
-
Least Response Time Method - the fewest active connections and the lowest average response time
-
Least Bandwidth Method - the least amount of traffic measured in megabits per second (Mbps)
-
Round Robin Method - cycle around
-
Weighted Round Robin Method - Each server is assigned a weight
-
IP Hash - a hash of the IP address
-
SQL vs NoSQL
-
SQL
-
Relational databases store data in rows and columns. Each row contains all the information about one entity and each column contains all the separate data points. Some of the most popular relational databases are MySQL, Oracle, MS SQL Server, SQLite, Postgres, and MariaDB.
-
-
NoSQL
-
Key-Value Stores: Data is stored in an array of key-value pairs. E.g. redis
-
Document Databases: Data is stored in documents and these documents are grouped together in collections. E.g. MongoDB, json format
-
Wide-Column Databases: in columnar databases we have column families, which are containers for rows. we don’t need to know all the columns up front and each row doesn’t have to have the same number of columns. e.g. Cassandra, dynamoDB and HBase.
-
Graph Databases: Data is saved in graph structures with nodes (entities), properties (information about the entities), and lines (connections between the entities). E.g. Neo4J and InfiniteGraph
-
SQL vs NoSQL
-
Storage
-
SQL: table where each row represents an entity and each column represents a data point about that entity
-
NoSQL: different data storage models. The main ones are key-value, document, graph, and columnar.
-
-
Schema
-
SQL: fixed schema
-
NoSQL: dynamic schema
-
-
Querying
-
SQL: use SQL
-
NoSQL: queries are focused on a collection of documents
-
SQL vs NoSQL
-
Scalability
-
SQL: vertically scalable. It is possible to scale a relational database across multiple servers, but this is a challenging and time- consuming process
-
NoSQL: horizontally scalable, more cost-effective than vertical scaling
-
-
Reliability or ACID Compliancy
-
SQL: ACID compliant. data reliability and safe guarantee of performing transactions
-
NoSQL: sacrifice ACID compliance for performance and scalability.
-
SQL VS. NoSQL - Which one to use?
-
SQL
-
ensure ACID compliance, sacrifice scalability and processing speed
-
Your data is structured and unchanging.
-
Use join
-
-
NoSQL
-
Storing large volumes of data that often have little to no structure. no limits on the types of data
-
Rapid development. Flexible data structures
-
Caching scenarios
-
High throughput / performance
-
CAP Theorem
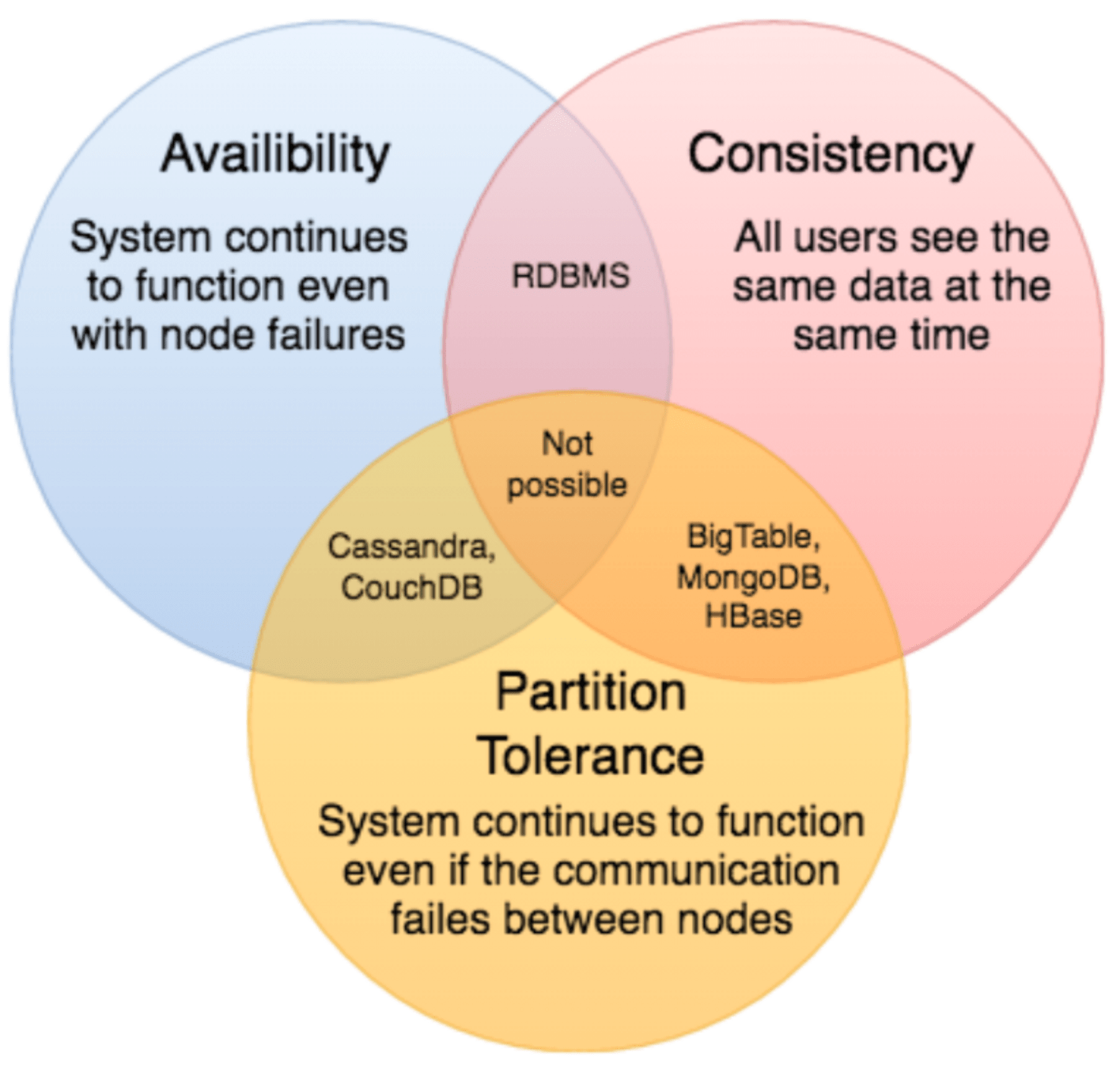
- CAP theorem states that it is impossible for a distributed software system to simultaneously provide more than two out of three of the following guarantees (CAP): Consistency, Availability, and Partition tolerance.
- Consistency: All nodes see the same data at the same time. Consistency is achieved by updating several nodes before allowing further reads.
- Availability: Every request gets a response on success/failure. Availability is achieved by replicating the data across different servers.
- Partition tolerance: The system continues to work despite message loss or partial failure. A system that is partition-tolerant can sustain any amount of network failure that doesn’t result in a failure of the entire network. Data is sufficiently replicated across combinations of nodes and networks to keep the system up through intermittent outages.
Caching
- Caches take advantage of the locality of reference principle: recently requested data is likely to be requested again.
- A cache is like short- term memory: it has a limited amount of space, but is typically faster than the original data source and contains the most recently accessed items.
- Caches can exist at all levels in architecture, but are often found at the level nearest to the front end where they are implemented to return data quickly without taxing downstream levels.
Redis vs Memcached
-
Redis and Memcached are popular, open-source, in-memory data stores. Memcached is a cache-focused key/value store. Redis is also a key/value store often used for caching, but is also often utilized as a primary database or a message broker and offers a clear growth path to an enterprise-hardened solution.
-
Redis supports data persistence, memcached does not
-
Redis supports more data structures, memcached does not
-
Redis is slower than memcached
-
If it’s only used for key-value storage, use memcached
CDN
- CDNs are a kind of cache that comes into play for sites serving large amounts of static media. In a typical CDN setup, a request will first ask the CDN for a piece of static media; the CDN will serve that content if it has it locally available. If it isn’t available, the CDN will query the back-end servers for the file, cache it locally, and serve it to the requesting user.
- If the system we are building isn’t yet large enough to have its own CDN, we can ease a future transition by serving the static media off a separate
- subdomain (e.g. static.yourservice.com) using a lightweight HTTP server like Nginx, and cut-over the DNS from your servers to a CDN later.
Cache Invalidation
Cache requires some maintenance for keeping cache coherent with the source of truth (e.g., database).
-
Write-through cache: data is written into the cache and the corresponding database at the same time. Con: higher latency for write operations.
-
Write-around cache: This technique is similar to write through cache, but data is written directly to permanent storage, bypassing the cache. Con: A read request for recently written data will create a “cache miss”
-
Write-back cache: Under this scheme, data is written to cache alone and completion is immediately confirmed to the client. Con: data loss in database.
Sharding or data partitioning
Data partitioning (also known as sharding) is a technique to break up a big database (DB) into many smaller parts. It is the process of splitting up a DB/table across multiple machines to improve the manageability, performance, availability, and load balancing of an application. The justification for data sharding is that, after a certain scale point, it is cheaper and more feasible to scale horizontally by adding more machines than to grow it vertically by adding beefier servers.
Sharding methods
-
Horizontal partitioning: In this scheme, we put different rows into different tables.
-
Need extra data to maintain the range
-
join is much more difficult
-
Referential integrity cannot be maintained
-
-
Vertical Partitioning: In this scheme, we divide our data to store tables related to a specific feature in their own server. The main problem with this approach is that if our application experiences additional growth, then it may be necessary to further partition a feature specific DB across various servers
-
Scaling could be a big problem
-