
















Elisa Beshero-Bondar PRO
Professor of Digital Humanities and Chair of the Digital Media, Arts, and Technology Program at Penn State Erie, The Behrend College.
A Panel for the TEI 2019 Conference in Graz, Austria
Presenters: Hugh Cayless (@hcayless), Elisa Beshero-Bondar (@epyllia), Raffaele Viglianti (@raffazizzi)
Respondent: James Cummings (@jamescummings)
Link to these slides: http://bit.ly/crit-app-panel
Hugh Cayless (@hcayless)
Latin: apparatus criticus, pl. apparatūs critici
A critical apparatus is the set of notes explaining an editor’s (re)construction of a text. These notes may contain the readings of witnesses, conjectures not promoted to the text, explanatory notes, alternative spellings or punctuation, parallels from other works, and in general any information that might help a reader understand the background of the presented text.
A critical apparatus is the set of notes explaining an editor’s (re)construction of a text.
A TEI app. crit. represents a forking and rejoining of the text stream, a run of text for which there are multiple possibilities.
A: “The quick brown fox ju...”
B: “The quick brown mouse jumps over the lazy cat.”
C: “The quick brown cat jumps over the lazy dog.”
A: “The quick brown fox ju...”
B: “The quick brown mouse jumps over the lazy cat.”
C: “The quick brown cat jumps over the lazy dog.”
We think A and B derive from the archetype via different routes, and C derives from A.
<p>The quick brown <app> <lem wit="#A">fox</lem> <rdg wit="#B">mouse</rdg> <rdg wit="#C">cat</rdg></app> jumps over the lazy <app> <lem wit="#C">dog</lem> <rdg wit="#B">cat</rdg></app>.</p>
We might decide that, since the transmission of B and C was independent, you can’t have two cats.
”The quick, brown cat jumps over the lazy cat.”
<p>The quick brown <app>
<lem wit="#A">fox</lem>
<rdg wit="#B">mouse</rdg>
<rdg xml:id="C1" wit="#C" exclude="#C2">cat</rdg></app> jumps over the lazy <app>
<lem wit="#C">dog</lem>
<rdg xml:id="C2" wit="#B" exclude="#C1">cat</rdg></app>.</p>
These aren’t simple, independent variations. There can be interdependencies. Imagine a German family of the tradition with two versions:
“Der schnelle braune Fuchs springt über den faulen Hund.”
“Die schnelle braune Katze springt über die faule Katze.”
If you have “Fuchs” the first word must be “Der”, if “Katze” then “Die”. “Die schnelle braune Fuchs...” would be another impossible text.
A TEI app. crit. represents a forking and rejoining of the text stream, a run of text for which there are multiple possibilities. These possibilities may be constrained by their context.
A TEI app. crit. entry is a type of annotation on the text, asserting that a particular source or authority has a different opinion about the text content.
or...
<p>The quick brown <app>
<lem wit="#A">fox</lem>
<rdg wit="#B">mouse</rdg>
<rdg xml:id="C1" wit="#C" exclude="#C2">cat</rdg></app> jumps over the lazy <app>
<lem wit="#C">dog</lem>
<rdg xml:id="C2" wit="#B" exclude="#C1">cat</rdg></app>.</p>
“A says, and the editor agrees, that the fourth word is ‘fox’. B says that it is ‘mouse’, and C says that it is ‘cat‘.”
Note that the apparatus doesn’t have to be inline. It could be standoff and say the same thing.
<p>The quick brown fox jumps over the lazy dog.</p>
...
<listApp>
<app from="#match(//p[1],'fox')">
<lem wit="#A">fox</lem>
<rdg wit="#B">mouse</rdg>
<rdg xml:id="C1" wit="#C" exclude="#C2">cat</rdg>
</app>
<app from="#match(//p[1],'dog')">
<lem wit="#C">dog</lem>
<rdg xml:id="C2" wit="#B" exclude="#C1">cat</rdg>
</app>
</listApp>
All that said, it’s a data structure, and can be repurposed. Collatex uses it as a collation export format, for example.
If we accept that a TEI critical apparatus can be viewed as a sort of (optionally standoff) assertive annotation, then we might imagine using it to describe things other than textual variation. What about variant markup?
Most annotation formats, including TEI <note> and things like Web Annotation, only allow you to associate the content of the annotation with the thing annotated, not to say something positive about it, like “I think this is a place name”.
<div type="textpart" subtype="chapter" n="1" xml:id="c1"> <p type="textpart" subtype="section" n="1" xml:id="c1s1"> <seg n="1" xml:id="c1s1p1">Gallia est omnis divisa in partes tres, quarum unam incolunt Belgae, Aliam Aquitani, tertiam qui ipsorum lingua Celtae, nostra Galli appellantur.</seg>...</p></div>... <standoff> <listApp> <app from="#match(//seg[@xml:id='c1s1p1'],'Gallia')"> <rdg><placeName ref="https://pleiades.stoa.org/places/993" source="#Damon">Gallia</placeName></rdg> </app> </listApp> </standoff>
“Damon says that ‘Gallia’ in chapter 1, paragraph 1, segment 1 is a place name referencing Pleiades #993.”
Elisa Beshero-Bondar (@epyllia)
“Spine 2” by Buzz Spector:
polaroid of 33 books aligned at the spines, one per human vertebra
Inspiration for Frankenstein Variorum: Darwin Online (ed. Barbara Bordalejo), except...
algorithm for computer-aided collation, developed in 2009 workshop of collateX and Juxta developers.
Tokenization :
Break down the smallest unit of comparison: (words--with punctuation, or character-by-character): FV tokenizes words and includes punctuation
Normalization
('&' = 'and')
Alignment
Identify comparable divergence: what makes text sequences comparable units?
“Chunking” text into comparable passages (chapters/paragraphs that line up with identifiable start and end points). Collation proceeds chunk by chunk.
Analysis
(study output, correct, and re-align after machine process, AND refine automated processing)
Visualization
critical edition apparatus, graph displays
required XSLT resequencing of margin zones (follow @corresp values to @xml:ids)
required Python normalizing algorithm to suppress <line> from collation
<app xml:id="C10_app44">
<rdgGrp xml:id="C10_app44_rg1"
n="['<del>handsome<del>
<del>handsome<
del>beautiful.<del>handsome<del>beautiful;', 'great']"
<rdg wit="fMS"><lb n="c56-0045__main__23"/>
<del rend="strikethrough" sID="c56-0045__main__d2e9837"/>
handsome<del eID="c56-0045__main__d2e9837"/>
<mdel>.
</mdel><lb n="c56-0045__left_margin__1"/>
<del rend="strikethrough" sID="c56-0045__left_margin__d2e9853"/>handsome<
del eID="c56-0045__left_margin__d2e9853"/>beautiful.
<del rend="strikethrough" sID="c56-0045__main__d2e9865"/>
Handsome<del eID="c56-0045__main__d2e9865"/>
Beautiful; Great </rdg>
</rdgGrp>
<rdgGrp xml:id="C10_app44_rg2" n="['beautiful.', 'beautiful!—great']">
<rdg wit="f1818">beautiful. Beautiful!—Great </rdg>
<rdg wit="f1823">beautiful. Beautiful!—Great </rdg>
<rdg wit="fThomas">beautiful. Beautiful!—Great </rdg>
<rdg wit="f1831">beautiful. Beautiful!—Great </rdg>
</rdgGrp>
</app>an ugly but powerful Frankenstein creature of collation!
TEI advantage: Interchange (cf. Syd Bauman, “Interchange vs. Interoperability”):
”Human A” reading code written and documented by ”Human B” can understand how to adapt that code without consulting Human B.
Determine how to follow the “running stream” of semantically readable text to be compared with other editions.
Doing the work of interchange:
<milestone unit="tei:p"/>::
<p>. . . . . . </p>
Legend
MS
1818
Thm
1823
1831
Alignments, gaps, and comparative lengths of each collation unit
chapter heading or other structural boundary
For more on our document data modeling, see
Beshero-Bondar, Elisa E., and Raffaele Viglianti. “Stand-off Bridges in the Frankenstein Variorum Project: Interchange and Interoperability within TEI Markup Ecosystems.” Balisage Series on Markup Technologies, vol. 21 (2018). https://doi.org/10.4242/BalisageVol21.Beshero-Bondar01.
”Preparing diversely encoded documents for collation challenges us to consider inconsistent and overlapping hierarchies as a tractable matter for computational alignment—where alignment becomes an organizing principle that fractures hierarchies, chunking if not atomizing them at the level of the smallest meaningfully sharable semantic features.”
”We have negotiated interchangeability by cutting across individual text hierarchies to emphasize lateral connections and commonalities—making a new TEI whose hierarchy serves as a stand-off ”spine” or ”switchboard” permitting comparison and sharing of common data. Our goal of pointing to aligned data required us to locate the interchangeable structural markers in our source documents.”
Raff Viglianti (@raffazizzi)
songscapes.org
Stand-off apparatus and
the representation of primary sources
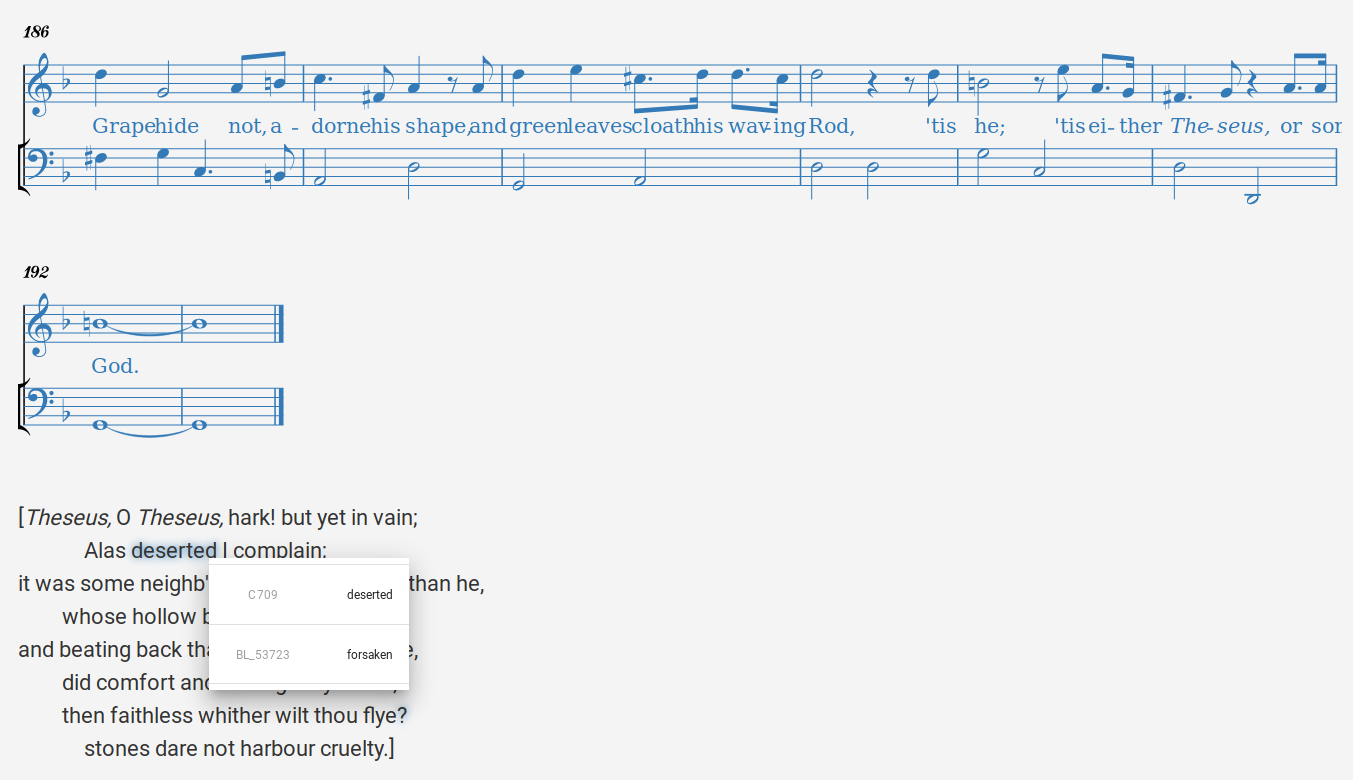
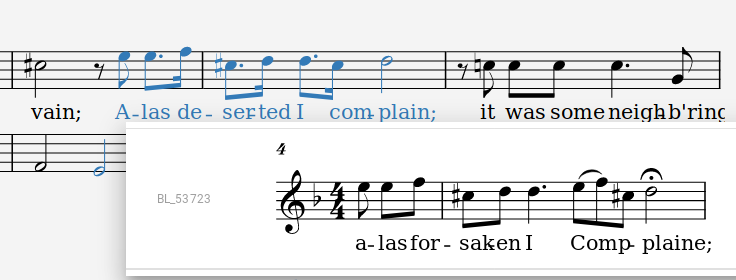
<l>alas forsaken I Complaine;</l><l>Alas deserted I Complain,</l><l>Alas deserted I complain;</l>BL Add. MS 53723
C 709
Folger L638
Variant
Songscapes stand-off collation
TEI (no XPointer in this case)
<TEI>
<div>
<head>Text Collation</head>
<app>
<rdgGrp>
<rdg wit="#BL_53723">
<ptr target="tei/Ariadne-BL_53723.xml#v1"/>
</rdg>
<rdg wit="#L638">
<ptr target="tei/Ariadne-L638.xml#v1"/>
</rdg>
</rdgGrp>
<rdg wit="#C709">
<ptr target="tei/Ariadne-C709.xml#v1"/>
</rdg>
</app>
</div>
</TEI>
+
BL Add. MS 53723
+
Folger L638
C 709
Adapted from: https://github.com/EarlyModernSongscapes/songscapes/blob/master/data/collations/Theseus%2C_O_Theseus%2C_hark!.xml
Songscapes stand-off collation
<TEI>
<div>
<head>Music Collation</head>
<notatedMusic>
<mei:mei> <!-- header -->
<mei:music><mei:body><mei:mdiv><mei:score>
<mei:app>
<mei:rdg source="#M-BL_53723"
target="mei/Ariadne-BL_53723.xml#m-101
mei/Ariadne-BL_53723.xml#m-106"/>
<mei:rdg source="#M-L638"
target="mei/Ariadne-L638.xml#m-101
mei/Ariadne-L638.xml#m-106"/>
</mei:app>
</mei:score></mei:mdiv></mei:body></mei:music>
</mei:mei>
</div>
</TEI>
+
BL Add. MS 53723
+
Folger L638
MEI
Adapted from: https://github.com/EarlyModernSongscapes/songscapes/blob/master/data/collations/Theseus%2C_O_Theseus%2C_hark!.xml
Publishing this kind of model
(including Frankenstein Variorum!)
<ptr target="MSC56.xml#string-range(//line[13],0,21)" />?
Isomorphic representations (TEI)
CETEIcean 🐳 (/sɪˈti:ʃn/) https://github.com/TEIC/CETEIcean
HTML5 Custom Elements
<tei-lg type="stanza">
<tei-l>Theseous! ô theseus! heark! but yet in vaine,</tei-l>
<tei-l>alas <tei-seg xml:id="v4">forsaken</tei-seg> I Complaine;</tei-l>
<tei-l>it was some Neighb'ringe Rock / more softe then he, /</tei-l>
<tei-l rend="indent1">whose hollow Bowels pittyed me,</tei-l>
<!-- ... -->
</tei-lg><lg type="stanza">
<l>Theseous! ô theseus! heark! but yet in vaine,</l>
<l>alas <seg xml:id="v4">forsaken</seg> I Complaine;</l>
<l>it was some Neighb'ringe Rock / more softe then he, /</l>
<l rend="indent1">whose hollow Bowels pittyed me,</l>
<!-- ... -->
</lg>Isomorphic representations (MEI)
Songscapes viewer
music
text
From: ems.digitalscholarship.utsc.utoronto.ca/islandora/object/ems%3A102
Addressability beyond a single project
James Cummings (@jamescummings)
A TEI app. crit. represents a forking and rejoining of the text stream, a run of text for which there are multiple possibilities. These possibilities may be constrained by their context.
A TEI app. crit. entry is a type of annotation on the text, asserting that a particular source or authority has a different opinion about the text content.
or...
<p>The quick brown fox jumps over the lazy dog.</p>
...
<listApp>
<app from="#match(//p[1],'fox')">
<lem wit="#A">fox</lem>
<rdg wit="#B">mouse</rdg>
<rdg xml:id="C1" wit="#C" exclude="#C2">cat</rdg>
</app>
<app from="#match(//p[1],'dog')">
<lem wit="#C">dog</lem>
<rdg xml:id="C2" wit="#B" exclude="#C1">cat</rdg>
</app>
</listApp>
All that said, it’s a data structure, and can be repurposed. Collatex uses it as a collation export format, for example.
<div type="textpart" subtype="chapter" n="1" xml:id="c1"> <p type="textpart" subtype="section" n="1" xml:id="c1s1"> <seg n="1" xml:id="c1s1p1">Gallia est omnis divisa in partes tres, quarum unam incolunt Belgae, Aliam Aquitani, tertiam qui ipsorum lingua Celtae, nostra Galli appellantur.</seg>...</p></div>... <standoff> <listApp> <app from="#match(//seg[@xml:id='c1s1p1'],'Gallia')"> <rdg><placeName ref="https://pleiades.stoa.org/places/993" source="#Damon">Gallia</placeName></rdg> </app> </listApp> </standoff>
“Damon says that ‘Gallia’ in chapter 1, paragraph 1, segment 1 is a place name referencing Pleiades #993.”
<div type="textpart" subtype="chapter" n="1" xml:id="c1"> <p type="textpart" subtype="section" n="1" xml:id="c1s1"> <seg n="1" xml:id="c1s1p1">Gallia est omnis divisa in partes tres, quarum unam incolunt Belgae.</seg>...</p></div>... <standoff> <listApp> <app from="#match(//seg[@xml:id='c1s1p1'],'Gallia')"> <rdg> <div> <head>Does standoff have to result in valid TEI? Should this only be used for assertive annotation?</head> <!-- Lots of random stuff here --> </div> </rdg> </app> </listApp> </standoff>
Reminder: <div> and <floatingText> now allowed inside <rdg>... for better or worse
algorithm for computer-aided collation, developed in 2009 workshop of collateX and Juxta developers.
Tokenization :
Break down the smallest unit of comparison: (words--with punctuation, or character-by-character): FV tokenizes words and includes punctuation
Normalization
('&' = 'and')
Alignment
Identify comparable divergence: what makes text sequences comparable units?
“Chunking” text into comparable passages (chapters/paragraphs that line up with identifiable start and end points). Collation proceeds chunk by chunk.
Analysis
(study output, correct, and re-align after machine process, AND refine automated processing)
Visualization
critical edition apparatus, graph displays
<app xml:id="C10_app44">
<rdgGrp xml:id="C10_app44_rg1"
n="['<del>handsome<del>
<del>handsome<
del>beautiful.<del>handsome<del>beautiful;', 'great']"
<rdg wit="fMS"><lb n="c56-0045__main__23"/>
<del rend="strikethrough" sID="c56-0045__main__d2e9837"/>
handsome<del eID="c56-0045__main__d2e9837"/>
<mdel>.
</mdel><lb n="c56-0045__left_margin__1"/>
<del rend="strikethrough" sID="c56-0045__left_margin__d2e9853"/>handsome<
del eID="c56-0045__left_margin__d2e9853"/>beautiful.
<del rend="strikethrough" sID="c56-0045__main__d2e9865"/>
Handsome<del eID="c56-0045__main__d2e9865"/>
Beautiful; Great </rdg>
</rdgGrp>
<rdgGrp xml:id="C10_app44_rg2" n="['beautiful.', 'beautiful!—great']">
<rdg wit="f1818">beautiful. Beautiful!—Great </rdg>
<rdg wit="f1823">beautiful. Beautiful!—Great </rdg>
<rdg wit="fThomas">beautiful. Beautiful!—Great </rdg>
<rdg wit="f1831">beautiful. Beautiful!—Great </rdg>
</rdgGrp>
</app>Songscapes TEI stand-off collation
TEI (no XPointer)
<TEI>
<div>
<head>Text Collation</head>
<app>
<rdgGrp>
<rdg wit="#BL_53723">
<ptr target="tei/Ariadne-BL_53723.xml#v1"/>
</rdg>
<rdg wit="#L638">
<ptr target="tei/Ariadne-L638.xml#v1"/>
</rdg>
</rdgGrp>
<rdg wit="#C709">
<ptr target="tei/Ariadne-C709.xml#v1"/>
</rdg>
</app>
</div>
</TEI>
+
BL Add. MS 53723
+
Folger L638
C 709
Adapted from: https://github.com/EarlyModernSongscapes/songscapes/blob/master/data/collations/Theseus%2C_O_Theseus%2C_hark!.xml
Publishing this kind of model
A Panel for the TEI 2019 Conference in Graz, Austria
Presenters: Hugh Cayless (@hcayless), Elisa Beshero-Bondar (@epyllia), Raffaele Viglianti (@raffazizzi)
Respondent: James Cummings (@jamescummings)
By Elisa Beshero-Bondar
A panel presentation for the 2019 TEI Conference in Graz Austria


