Using Apache Flink as a microservice for stateful async processing
@Helpshift
By
Jagadish Bihani
Introduction
- Principal Software Engineer/Architect
- Hardcore backend engineer
- Distributed Systems
- Previously worked as a BigData Engineer
- Helpshift
- Customer Service Platform and in app support software
- High Scale, complex workflows - e.g. Classification of customer tickets, Event based automations on tickets etc.
Use case
- Breaking the title of the talk
- Microservice - Independent service for performing different computation/different workload than the conventional application server
- Event based system
- State update is needed for each event
- Output is not synchronous, it is a function of (future events, time)
- With traditional approaches of using database as state store has challenges
..continued
- Latency in case of higher volume of events
- Ensuring consistency and atomicity in case of failures is challenging due to series of state operations need to be performed
- A lot of bookkeeping needed in case of failure scenarios
- Need of a system, which is stateful and manage state itself in a fault tolerant way and with exactly once semantics
- Minimizes development cycle and adds robustment
- Technology investment justified as other potential use cases as well in other parts of the system
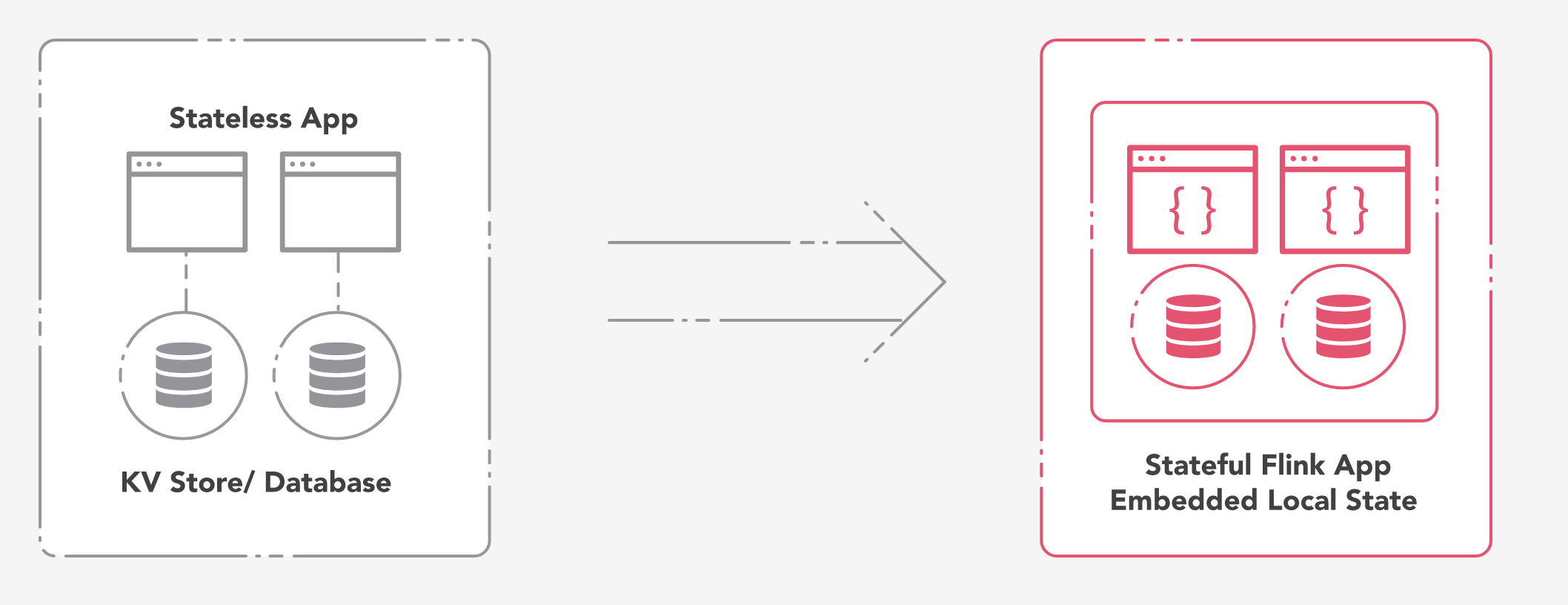
Flink Introduction
- Framework for Distributed Stream Processing System
- Yet another ? - Not Really!
- Strong theoritical foundation
- Exactly Once semantics 'for stateful computations'
- Removes the conventional notion - Low latency vs High Throughput
- Features :
- Event time, Windowing based on time, count, sessions, CEP support, Lightweight fault tolerance
Concepts
- Fault Tolerance - Most important concept which dictates many things
- Checkpointing : Consistent snapshots of the distributed data stream and operator state.
- What does it mean?
- Chandy-Lamport Algorithm
- Barriers
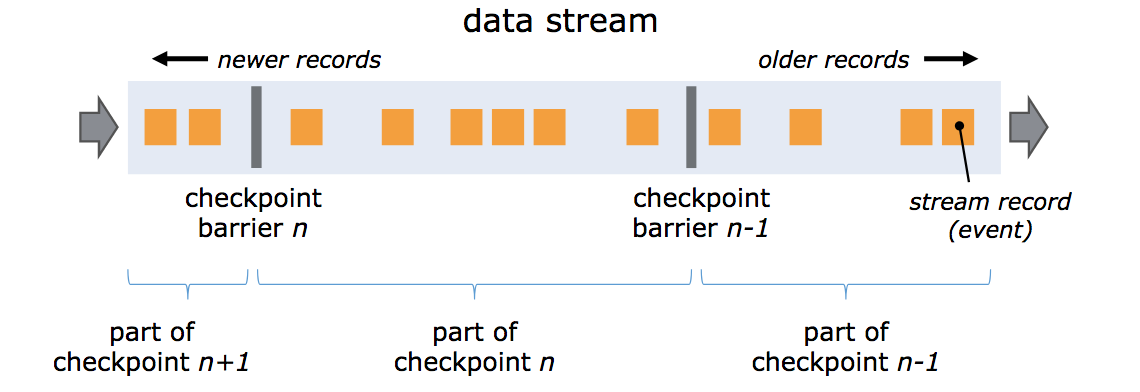
..continued
- State
- User defined/Managed
- Supported State Backends (RocksDB/HDFS)

..continued
- Asynchronous Checkpointing
- Checkpointing by default is synchronous
- For large states this can cause latency issues
- For processing and async checkpointing to coexist -
- Need of copy-on-write structures which are used in RocksDB
- How copy-on-write solves this?
Productionization Problems and Resolutions
Flink Taskmanager failover time tuning
- Default config took 70 seconds for died taskmanager's processing getting transferred to another taksmanager
- Product requirement - ETA of 15 seconds
- How to tune?
- Tune Restart Strategy
- Failure detection mechanism tuning
- Parameter of heartbeat interval, expected pause time and network characteristics
- Operational Recommendations
State Leaks
- State leak leads to monotonically increasing state
- Code example of State leak
- Impact of state leak
- Delays in processing randomly without a fixed pattern to detect
- Random nature of delays caused by the nature of asynchronous checkpointing
- If statepoint is async why does it affect processing?
- Synchronous processing of async checkpointing
- Background garbage collection in RocksDB
Fix State leak without downtime
- Problem: State is leaked but we need to clear the state with zero downtime
- Using domain knowledge
- For state key sending dummy events which enables business logic to clear that without code deployment
- General purpose solution to fix state leak without downtime
Monitoring
- Paramters to monitor
- State size
- Checkpoint time
- Succeeded/failed checkpoints
- Input source rate
- Output sink rate
Summary & Questions