Jumping over data land mines with blaze
about me
- MA Psychology
- Computational Neuroscience
- Core pandas dev
- Blaze et al @ContinuumIO
Motivation
- NumPy and Pandas are limited to memory
- And they have great APIs
- Let's bring those APIs to more complex technologies
Approach
- Blaze is an interface
- It doesn't implement any computation on its own
- It doesn't replace databases or pandas
- It sits on top of them
- Like a compiler for read only analytics queries
- It makes complex technologies more accessible
WHERE does BLAZe fit in to pydata?

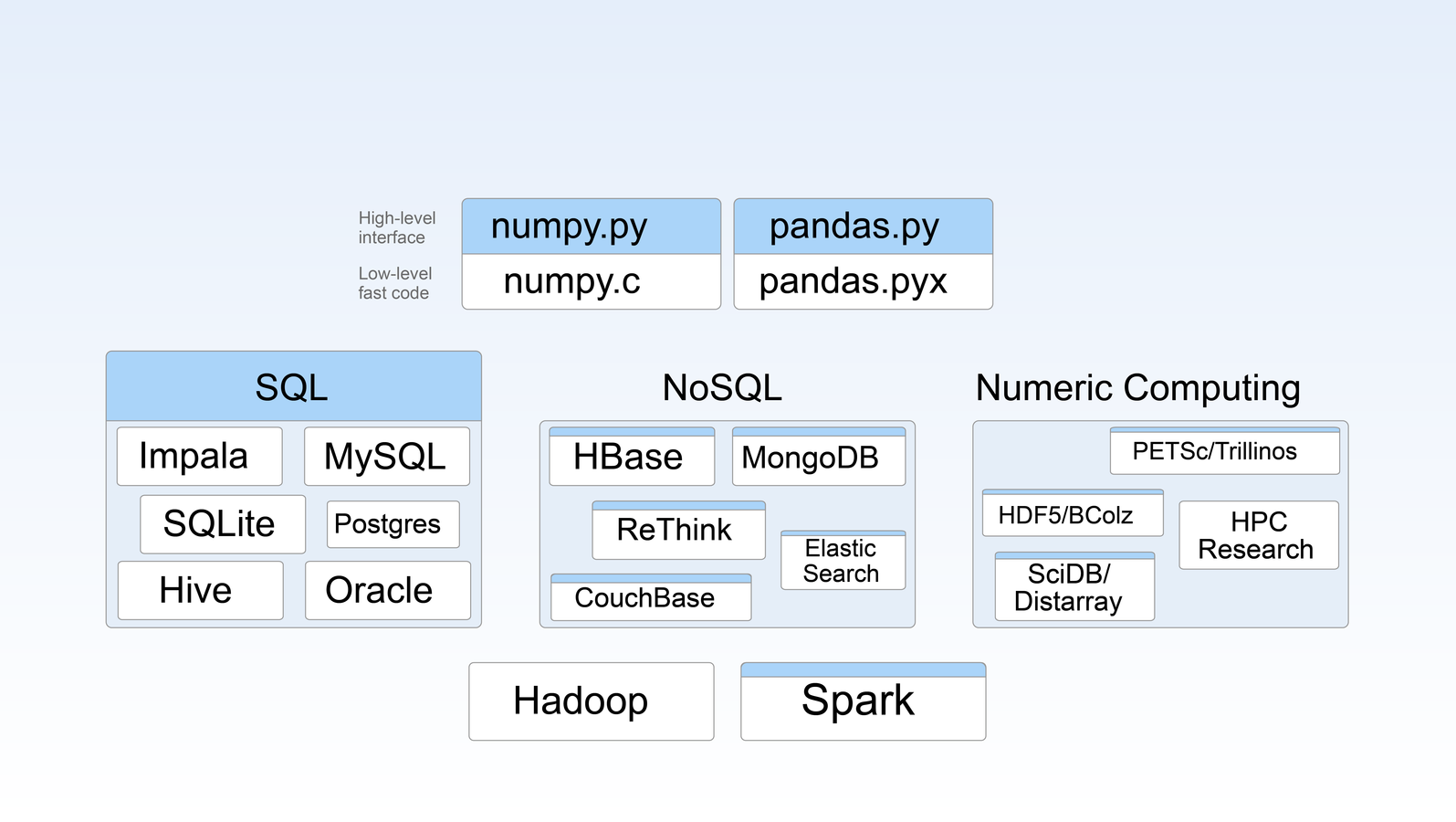
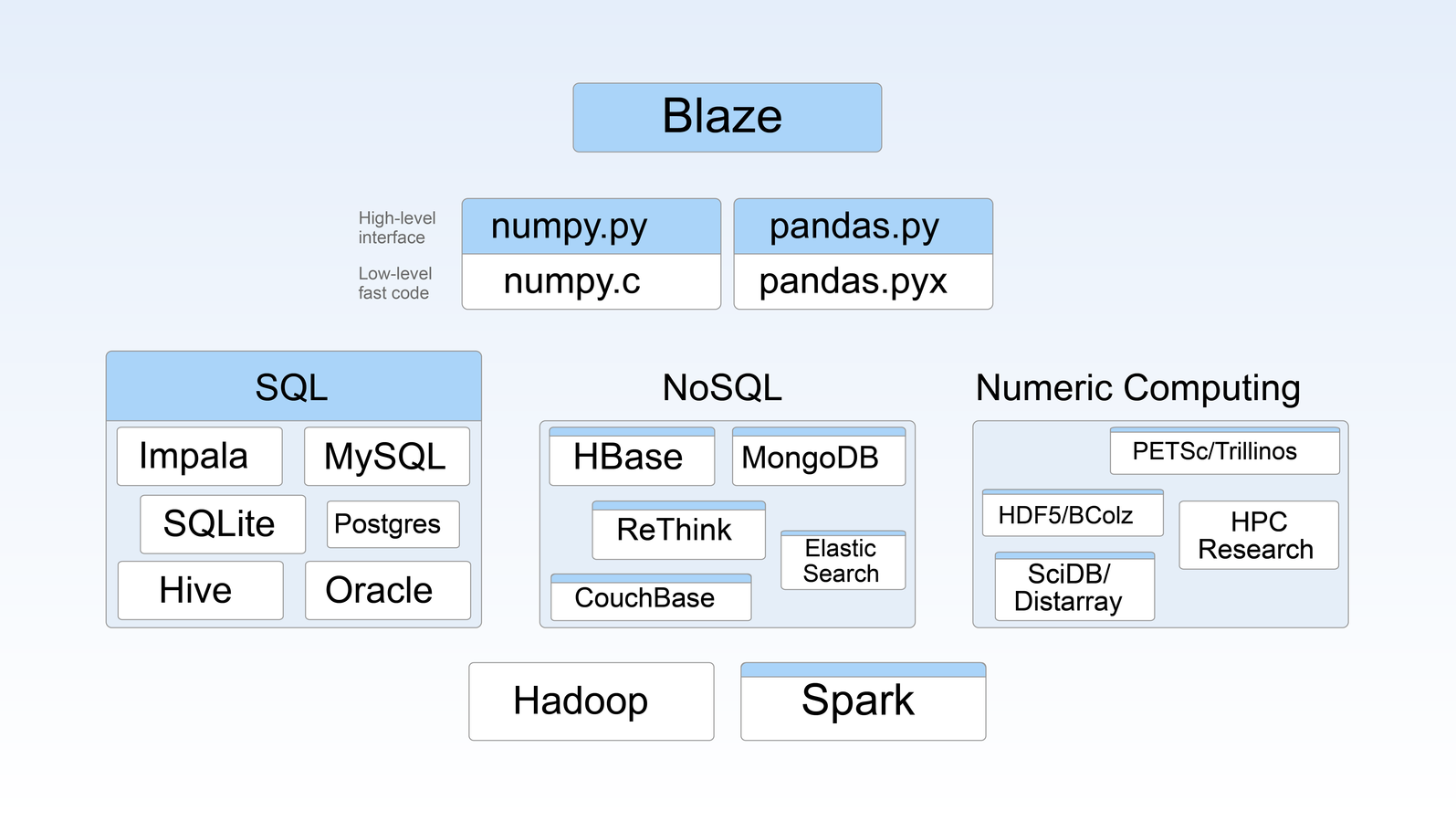
pieces of blaze
Expressions + TYPES
>>> from blaze import symbol, discover, compute
>>> import pandas as pd
>>> df = pd.DataFrame({'name': ['Alice', 'Bob', 'Forrest', 'Bubba'],
... 'amount': [10, 20, 30, 40]})
...
>>> t = symbol('t', discover(df))
>>> t.amount.sum()
sum(t.amount)>>> compute(t.amount.sum(), df)
100
>>> compute(t.amount.sum(), odo(df, list))
100
>>> compute(t.amount.sum(), odo(df, np.ndarray))
100compute recipes
demo time!
Blaze also lets you Do it yourself
Who's heard of the q language?
q)x:"racecar"
q)n:count x
q)all{[x;n;i]x[i]=x[n-i+1]}[x;n]each til _:[n%2]+1
1bCheck if a string is a palindrome
q)-1 x
racecar
-1
q)1 x
racecar1Print to stdout, with and without a newline
Um, integers are callable?

How about:
1 divided by cat

q)1 % "cat"
0.01010101 0.01030928 0.00862069
However, KDB is fast
so....
Ditch Q,
Keep KDB+
kdbpy: Q without the WAT, via blaze
- KDB+ is a database sold by Kx Systems.
- Free 32-bit version available for download on their website.
- Column store*.
- Makes big things feel small and huge things feel doable.
- Heavily used in the financial world.
Why KDB+/Q?
*It's a little more nuanced than that
-
It's a backend for blaze
-
It generates q code from python code
-
That code is run by a q interpreter
What is kdbpy?
To the notebook!
How does Q compare to other blaze backends?
NYC Taxi Trip Data
≈16 GB (trip dataset only)
partitioned in KDB+ on date (year.month.day)
vs
blaze (bcolz + pandas + multiprocessing)
The computation
-
group by on
-
passenger count
-
medallion
-
hack license
-
-
sum on
-
trip time
-
trip distance
-
The queries
# trip time
avg_trip_time = trip.trip_time_in_secs.mean()
by(trip.medallion, avg_trip_time=avg_trip_time)
by(trip.passenger_count, avg_trip_time=avg_trip_time)
by(trip.hack_license, avg_trip_time=avg_trip_time)The hardware
- two machines
- 32 cores, 250GB RAM, ubuntu
- 8 cores, 16GB RAM, osx
Beef vs. Mac 'n Cheese vs. Pandas
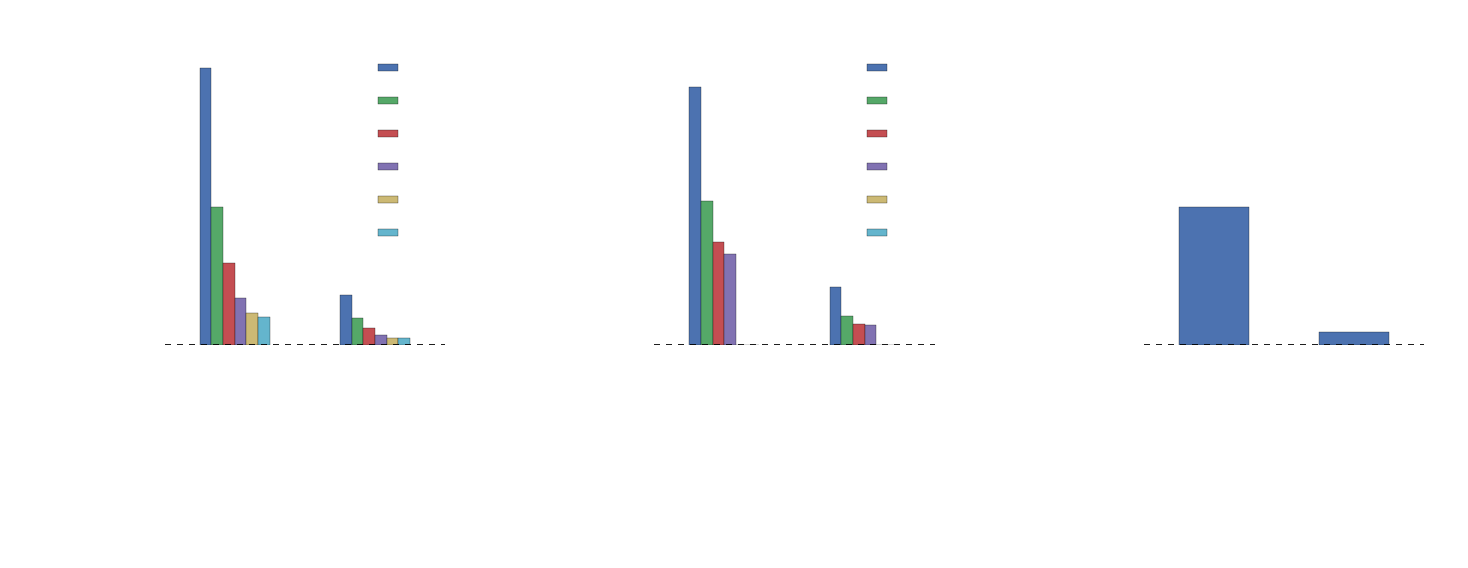
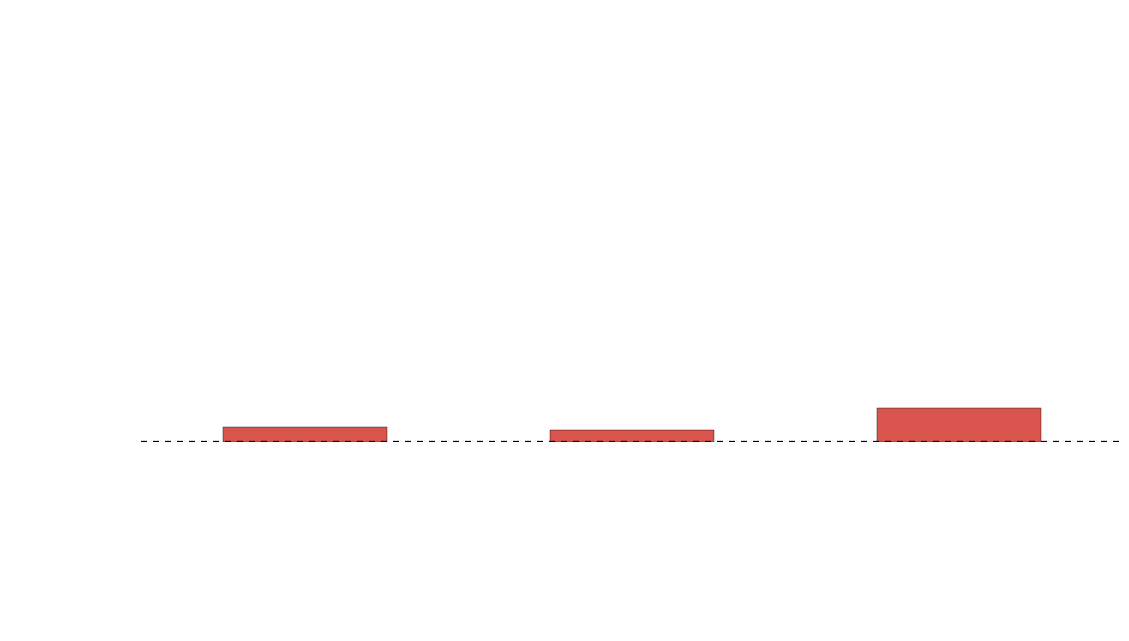
How pe-q-ular...
Questions
-
Is this a fair comparison?
- bcolz splits each column into chunks that fit in cache
- kdb writes a directory of columns per value in the partition column
-
kdb is using symbols instead of strings
-
requires an index column for partitions
- can take a long time to sort
- strings are not very efficient
-
requires an index column for partitions
How does the blaze version work?
bcolz +
pandas +
multiprocessing
bcolz
- Column store
- directory per column
- Column chunked to fit in cache
- numexpr in certain places
- reductions
- arithmetic
- transparent reading from disk
pandas
- fast, in-memory analytics
Multiprocessing
- compute each chunk in separate process
Storage
Compute
Parallelization
pray to the demo gods
graphlab integration
Thanks!
- docs: http://blaze.pydata.org
PyData Dallas 2015
By Phillip Cloud
PyData Dallas 2015
Blazing through data land mines with Python



