










russtedrake PRO
Roboticist at MIT and TRI
Towards Foundations Models for Control(?)
Russ Tedrake
Workshop on Control and Machine Learning
October 11, 2023
"What's still hard for AI" by Kai-Fu Lee:
Manual dexterity
Social intelligence (empathy/compassion)
"Dexterous Manipulation" Team
(founded in 2016)
For the next challenge:
For the next challenge:
Levine*, Finn*, Darrel, Abbeel, JMLR 2016
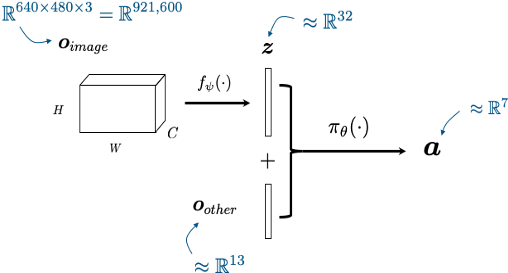
perception network
(often pre-trained)
policy network
other robot sensors
learned state representation
actions
x history
We've been exploring, and seem to have found something...
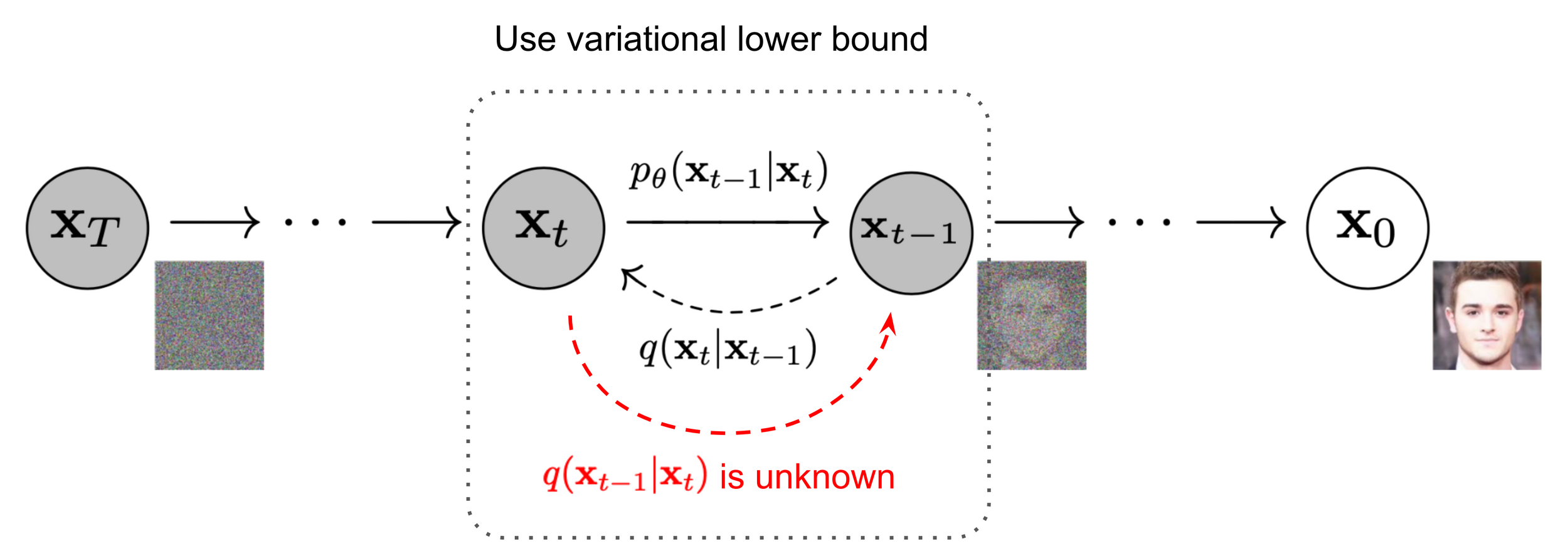
Image source: Ho et al. 2020
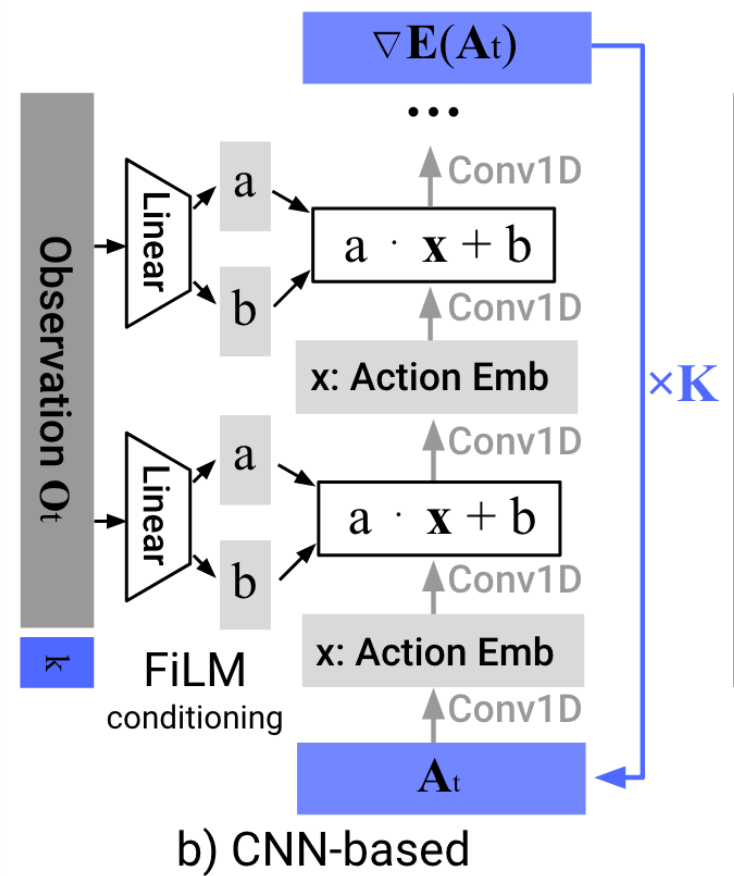
Denoiser can be conditioned on additional inputs, \(u\): \(p_\theta(x_{t-1} | x_t, u) \)
Denoising approximates the projection onto the data manifold;
approximating the gradient of the distance to the manifold
input
output
Control Policy
(as a dynamical system)
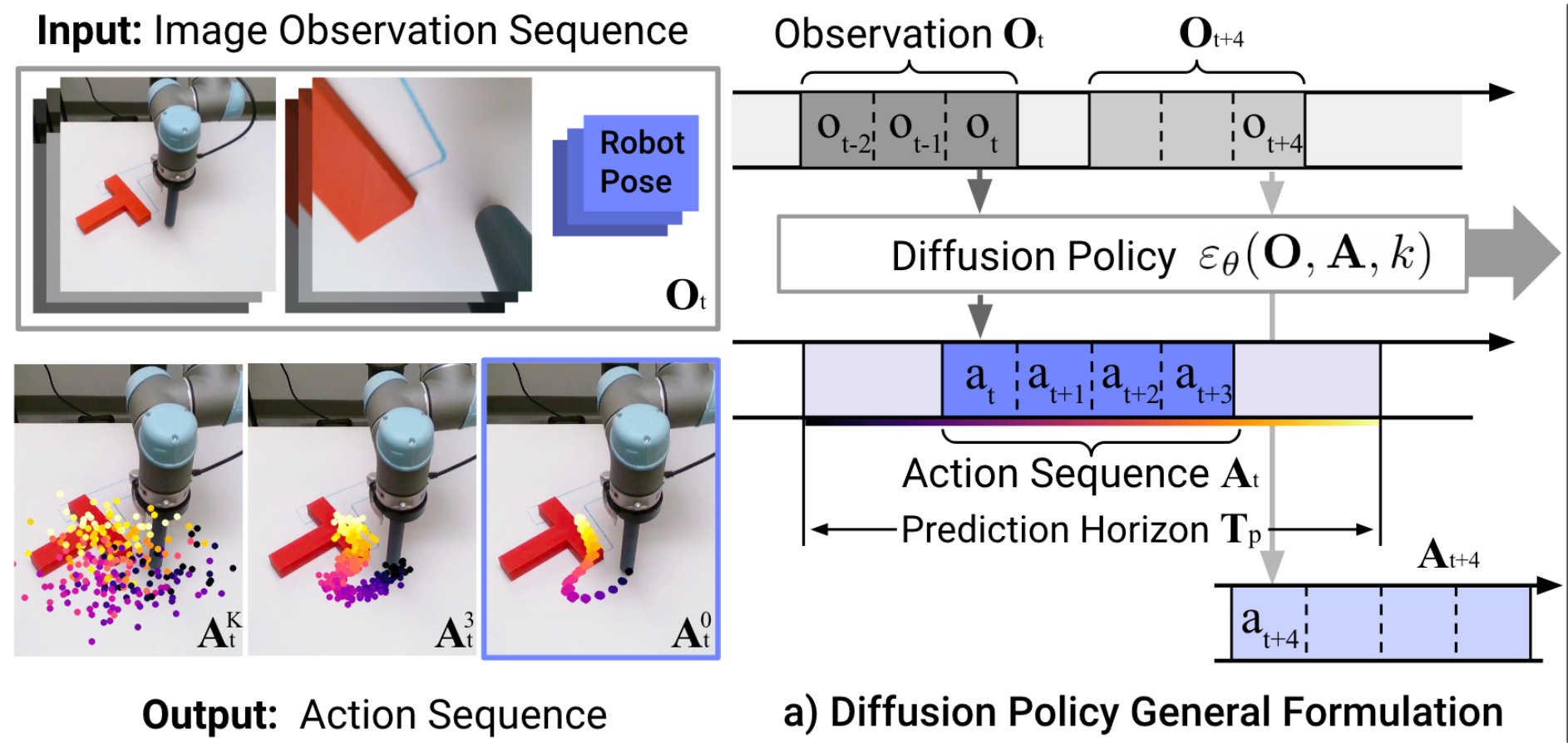
"Diffusion Policy" is an auto-regressive (ARX) model with forecasting
\(H\) is the length of the history,
\(P\) is the length of the prediction
Conditional denoiser produces the forecast, conditional on the history
Image backbone: ResNet-18 (pretrained on ImageNet)
Total: 110M-150M Parameters
Training Time: 3-6 GPU Days ($150-$300)
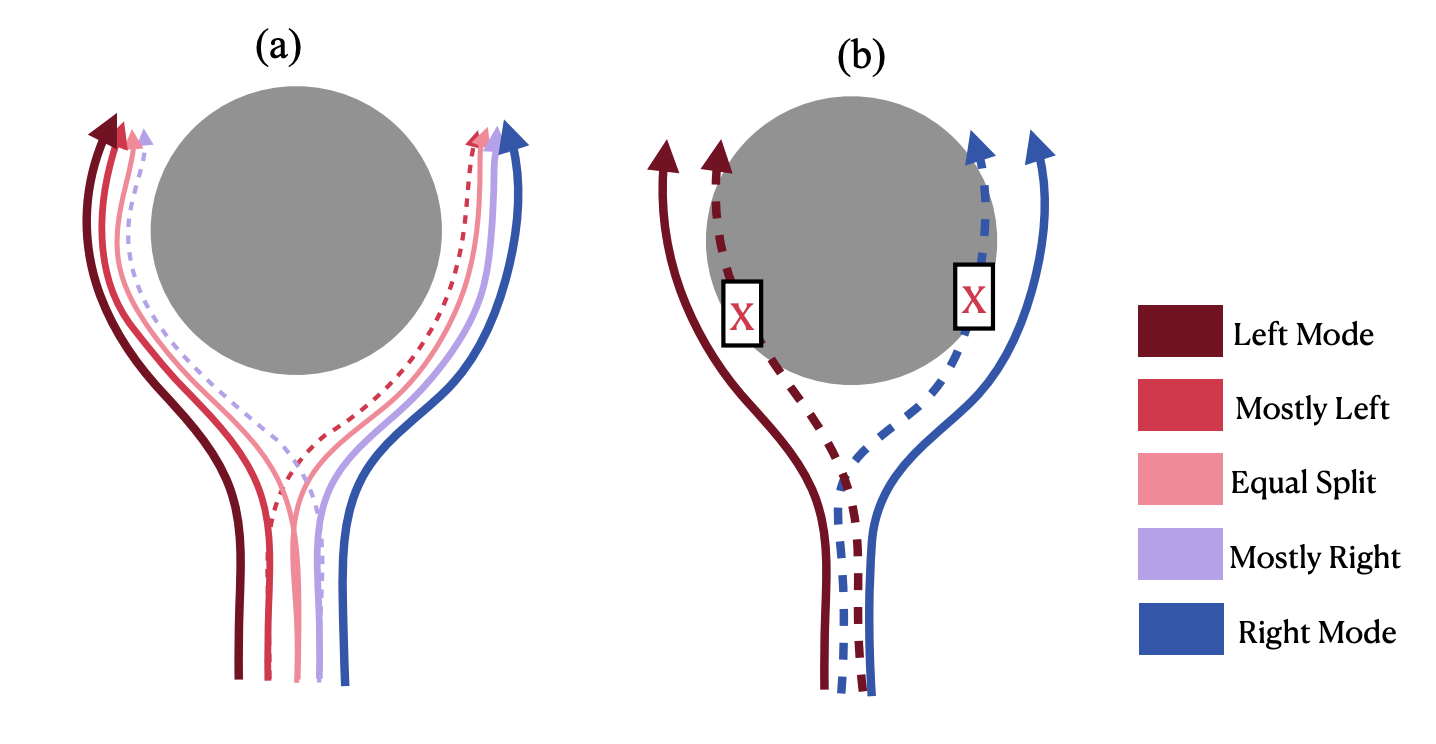
e.g. to deal with "multi-modal demonstrations"
with TRI's Soft Bubble Gripper
Open source:
I do think there is something deep happening here...
If we really understand this, can we do the same via principles from a model? Or will control go the way of computer vision and language?
pip install drake
sudo apt install drakeBy russtedrake
Workshop on Control and Machine Learning: Challenges and Progress


