







russtedrake PRO
Roboticist at MIT and TRI
Part 1
MIT 6.421
Robotic Manipulation
Fall 2023, Lecture 16
Follow live at https://slides.com/d/dy2gx20/live
(or later at https://slides.com/russtedrake/fall23-lec16)
Released in 2009
A sample annotated image from the COCO dataset
Something we couldn't have expected...
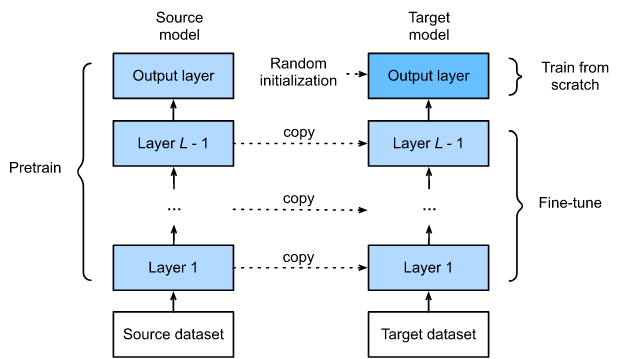
(Pre-)Training on ImageNet/COCO makes it easier to "learn" to recognize other objects
source: https://d2l.ai/chapter_computer-vision/fine-tuning.html
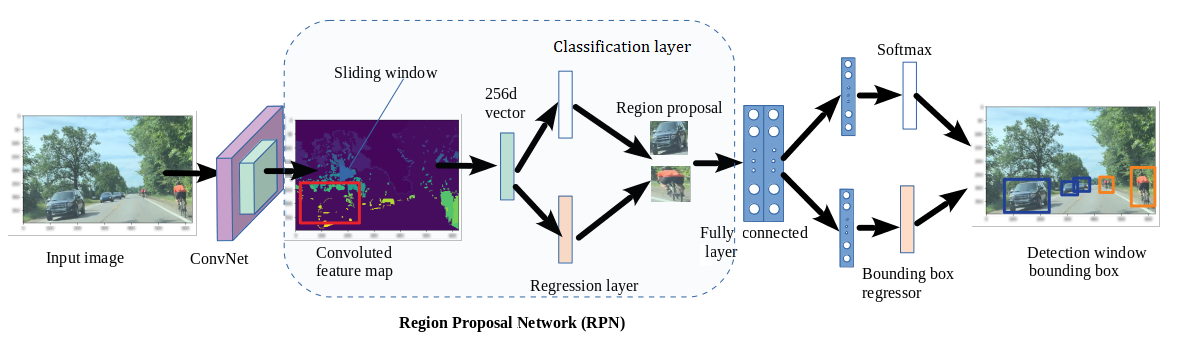
image from https://arxiv.org/abs/2012.02055
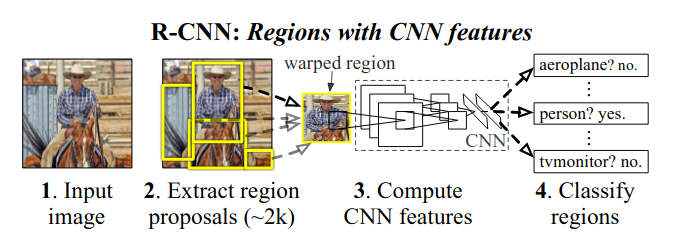
source: https://towardsdatascience.com/understanding-regions-with-cnn-features-r-cnn-ec69c15f8ea7
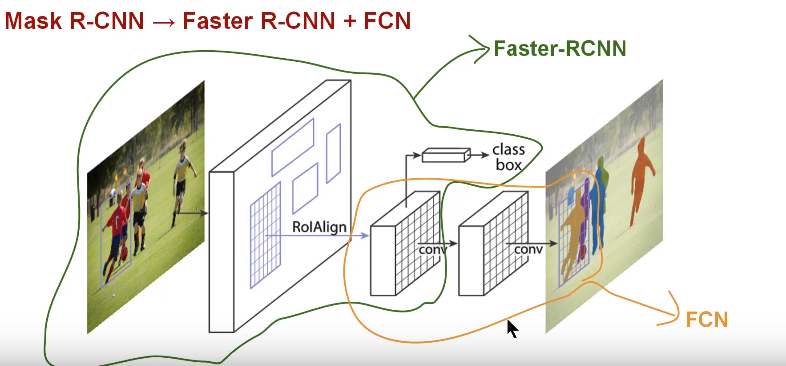
source: https://www.analyticsvidhya.com/blog/2018/07/building-mask-r-cnn-model-detecting-damage-cars-python/
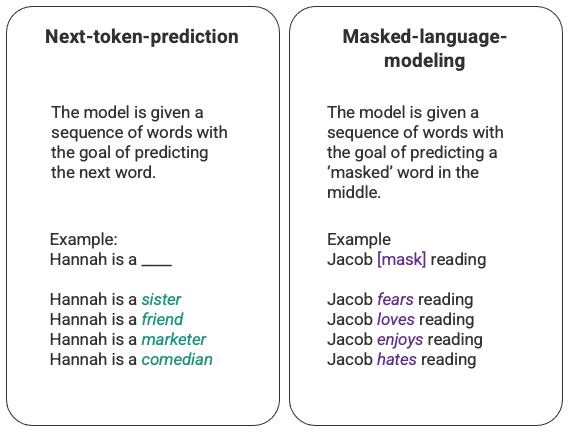
Example: Text completion
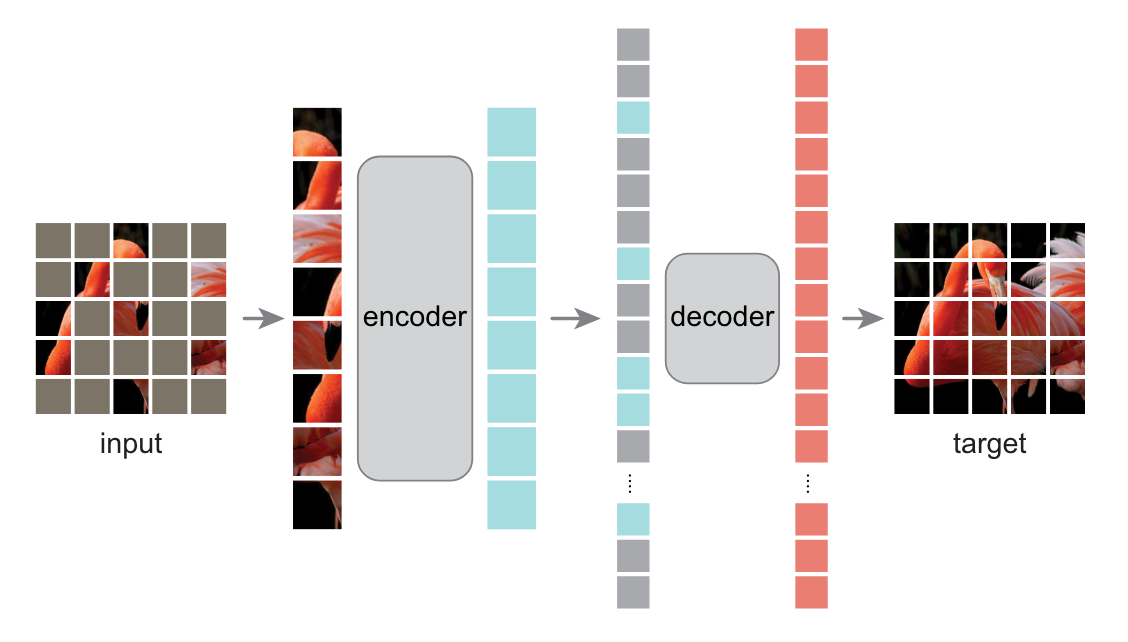
No extra "labeling" of the data required!
https://ai.googleblog.com/2020/04/advancing-self-supervised-and-semi.html
https://ai.googleblog.com/2020/04/advancing-self-supervised-and-semi.html
"Contrastive visual representation learning"
from TRI Medium Blog Post
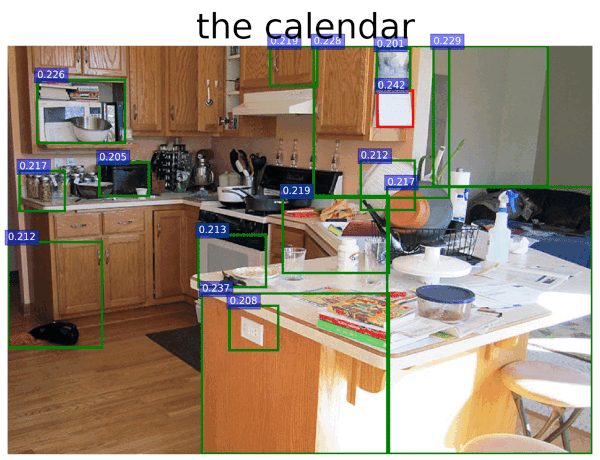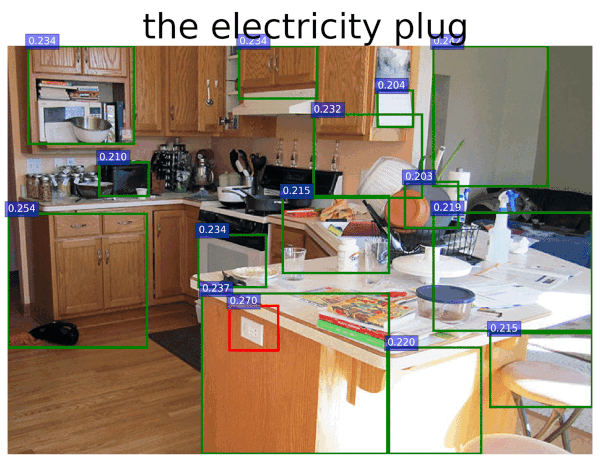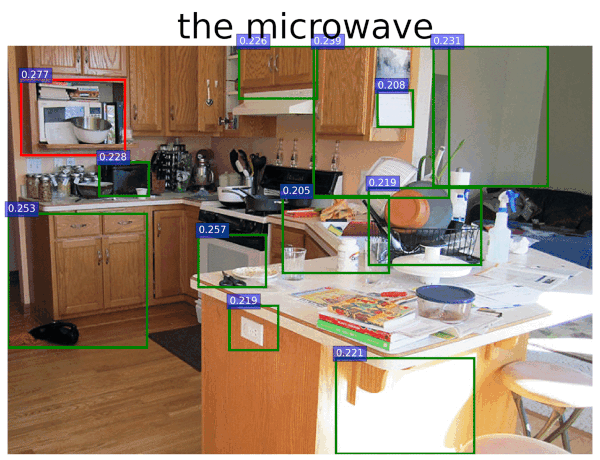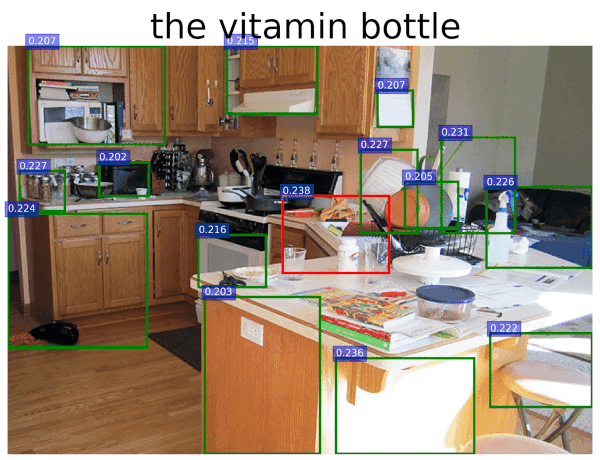
quick experiments using CLIP "out of the box" by Kevin Zakka
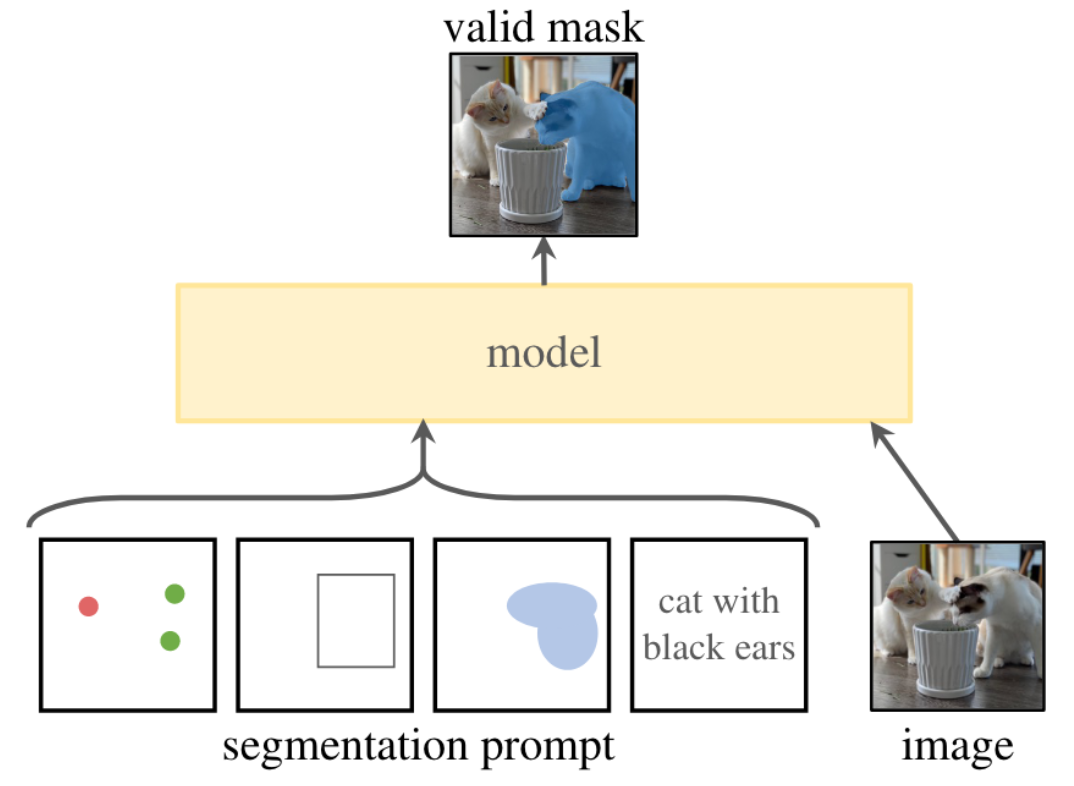
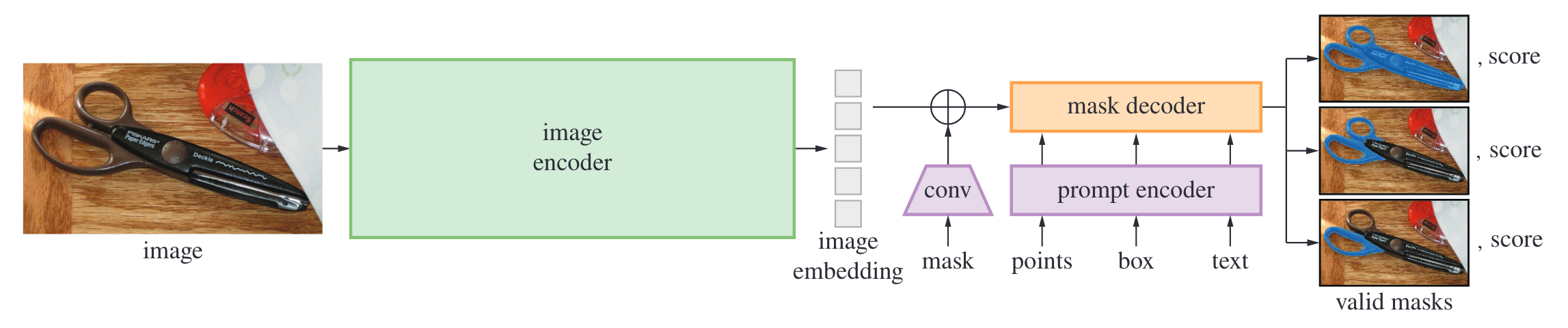
Open-source release doesn't accept text. You need a wrapper... e.g. Grounded Segment Anything
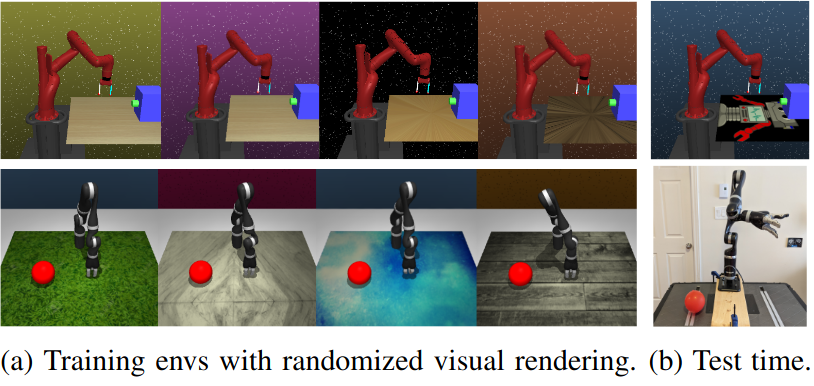
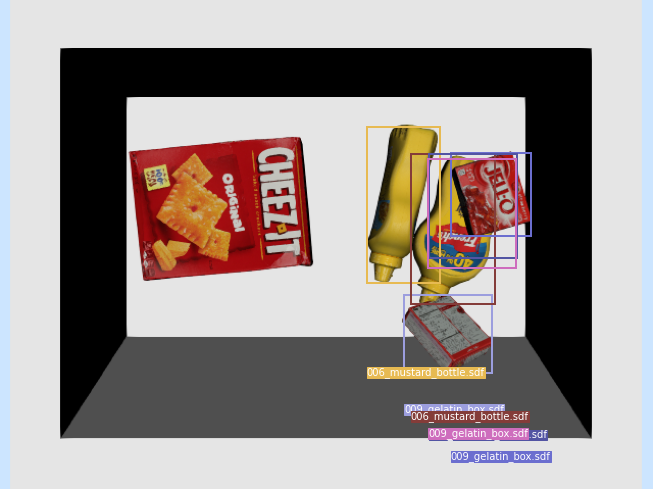
* - partly due to low render quality?
By russtedrake
MIT Robotic Manipulation Fall 2023 http://manipulation.csail.mit.edu


