



































russtedrake PRO
Roboticist at MIT and TRI
Part 2
MIT 6.421
Robotic Manipulation
Fall 2023, Lecture 17
Follow live at https://slides.com/d/KAZWmZg/live
(or later at https://slides.com/russtedrake/fall23-lec17)
A sample annotated image from the COCO dataset
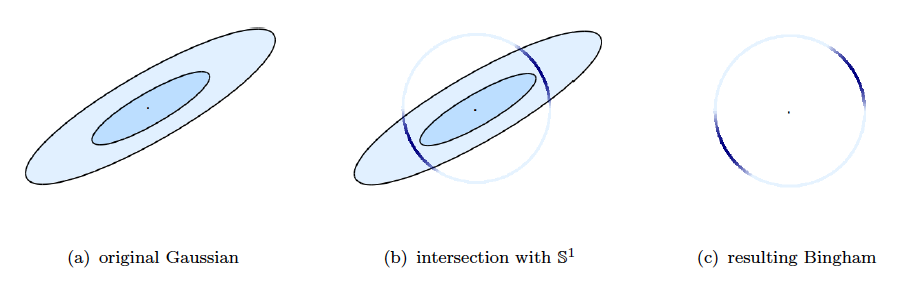
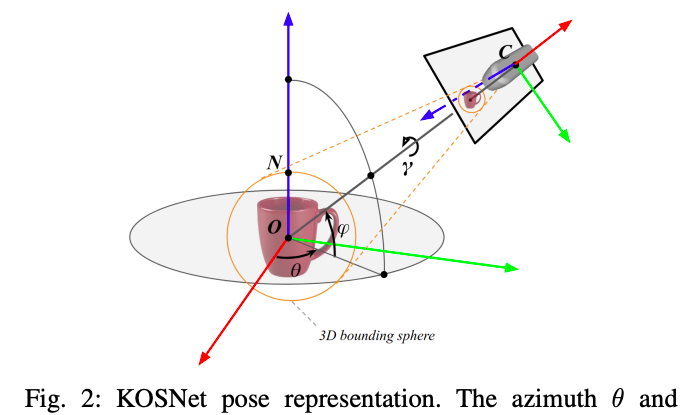
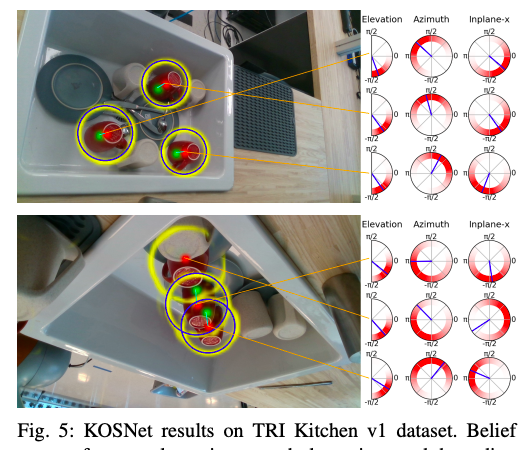
image from Jared Glover's PhD thesis, 2014
in 2D:
from Jared Glover's PhD thesis, 2014
* - partly due to low render quality?
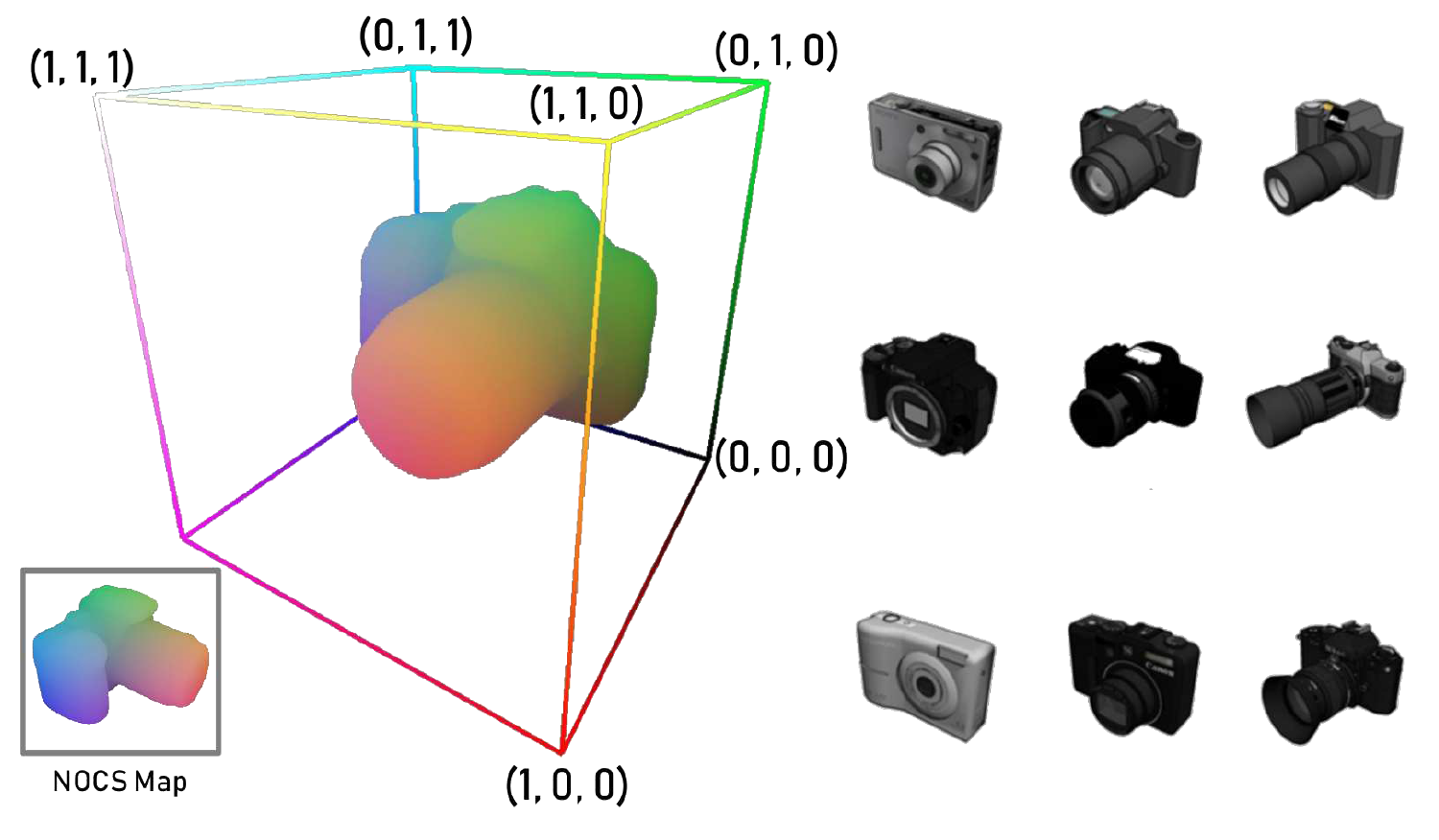
H. Wang, S. Sridhar, J. Huang, J. Valentin, S. Song, and L. J. Guibas, “Normalized Object Coordinate Space for Category-Level 6D Object Pose and Size Estimation,” in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, Jun. 2019, pp. 2637–2646, doi: 10.1109/CVPR.2019.00275.
"NOCS"
SE(3) pose is difficult to generalize across a category
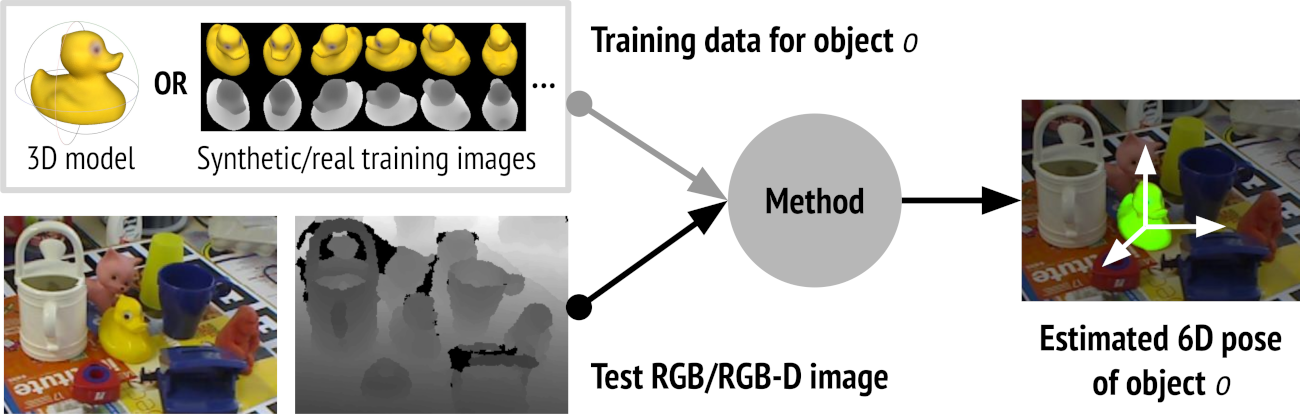
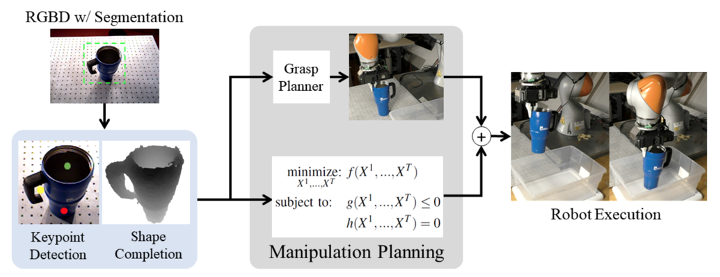
So how do we even specify the task?
What's the cost function?
(Images of mugs on the rack?)
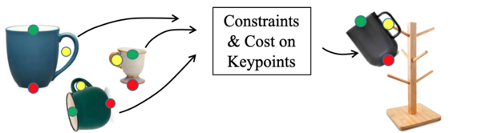
3D Keypoints provide rich, class-general semantics
Constraints & Cost on Keypoints
... and robust performance in practice
Lucas Manuelli*, Wei Gao*, Peter R. Florence and Russ Tedrake. kPAM: KeyPoint Affordances for Category Level Manipulation. ISRR 2019
Keypoint "semantics" + dense 3D geometry
https://keypointnet.github.io/
https://nanonets.com/blog/human-pose-estimation-2d-guide/
Typically don't predict keypoints directly; predict a "heatmap" instead
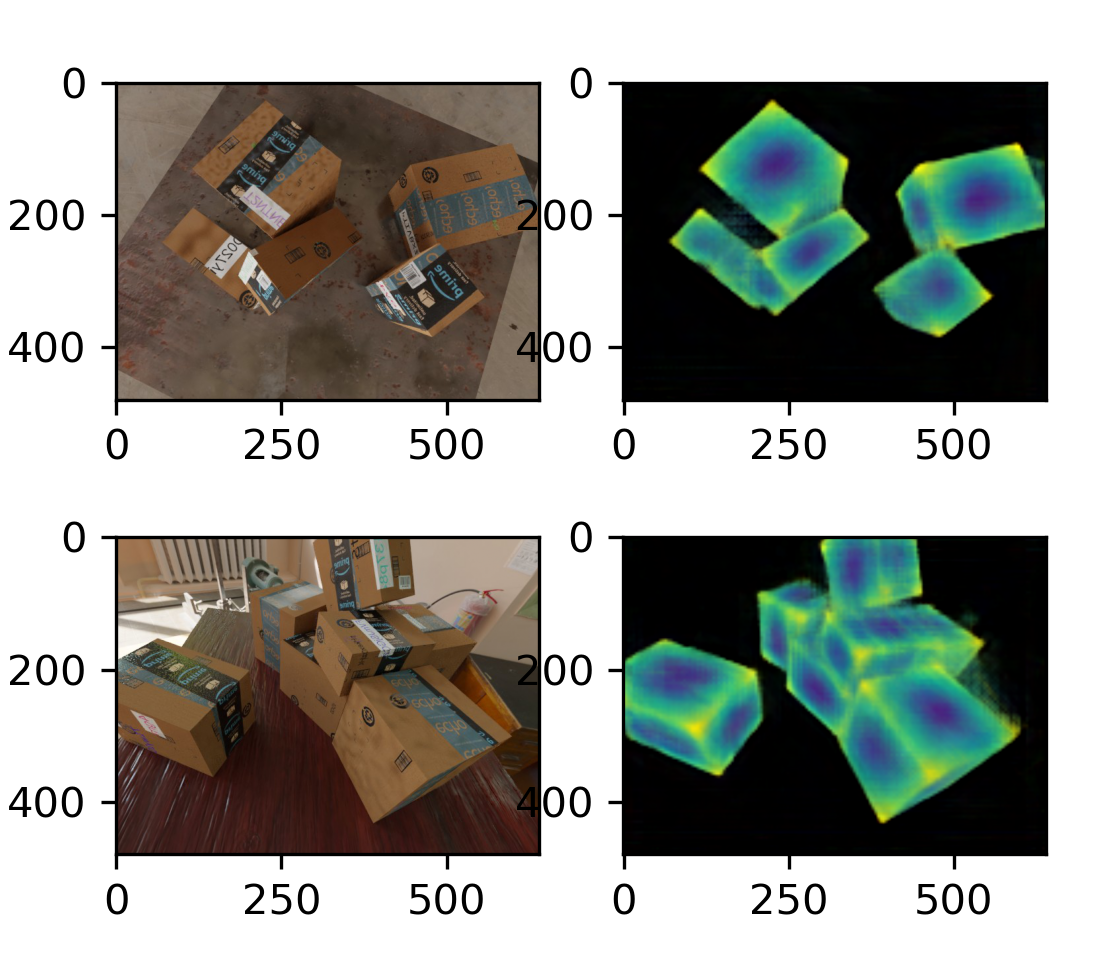
box example figures from Greg Izatt
Sample of results
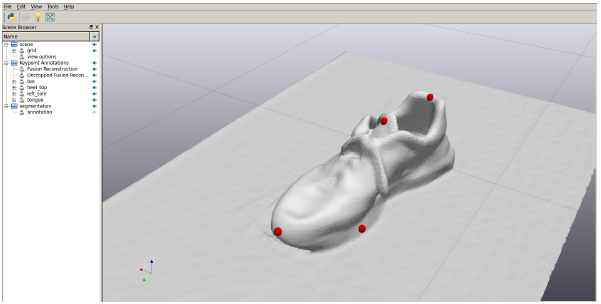
(shoes on rack)
| # train objects | 10 |
| # test objects | 20 |
| # trials | 100 |
| placed on shelf | 98% |
| heel error (cm) | 1.09 ± (1.29) |
| toe error (cm) | 4.34 ± (3.05) |
to include collision-avoidance constraints
So far, keypoints are geometric and semantic
(mug handle, front toe of shoe), but required human labels
If we forgo semantics, can we self-supervise?
Z. Qin, K. Fang, Y. Zhu, L. Fei-Fei, and S. Savarese, “KETO: Learning Keypoint Representations for Tool Manipulation,” in 2020 IEEE International Conference on Robotics and Automation (ICRA), May 2020, pp. 7278–7285
Core technology: dense correspondences
(built on Schmidt, Newcombe, Fox, RA-L 2017)
Peter R. Florence*, Lucas Manuelli*, and Russ Tedrake. Dense Object Nets: Learning Dense Visual Object Descriptors By and For Robotic Manipulation. CoRL, 2018.
dense 3D reconstruction
+ pixelwise contrastive loss
Good training/loss functions sharpen correspondences
Descriptors as dense self-supervised keypoints
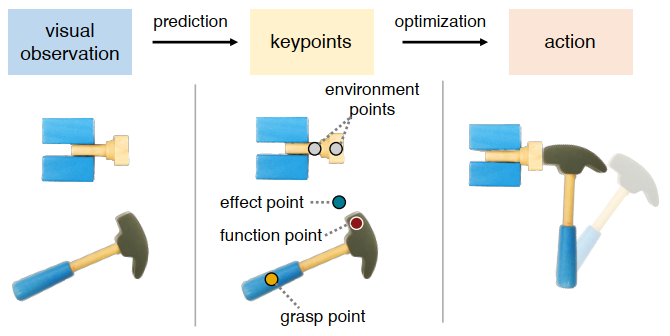
Correspondences alone are sufficient to specify some tasks
Andy Zeng et al. Transporter Networks: Rearranging the Visual World for Robotic Manipulation, CoRL, 2020
By russtedrake
MIT Robotic Manipulation Fall 2023 http://manipulation.csail.mit.edu



