













russtedrake PRO
Roboticist at MIT and TRI
Russ Tedrake
December 15, 2023
"Dexterous Manipulation" Team
(founded in 2016)
For the next challenge:
For the next challenge:
We've been exploring, and found something good in...
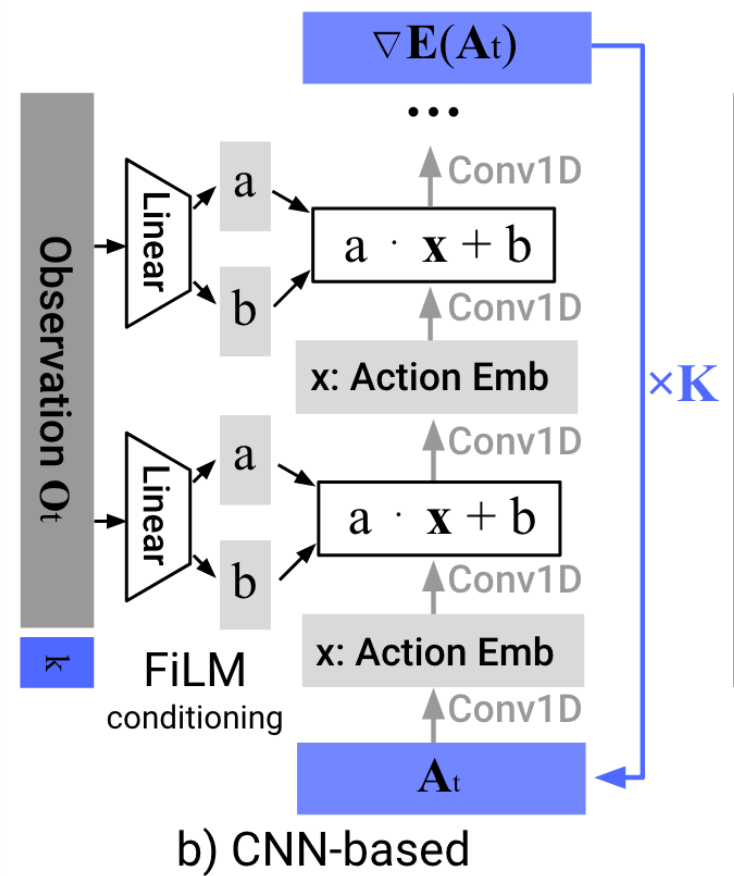
Image backbone: ResNet-18 (pretrained on ImageNet)
Total: 110M-150M Parameters
Training Time: 3-6 GPU Days ($150-$300)
(when training a single skill)
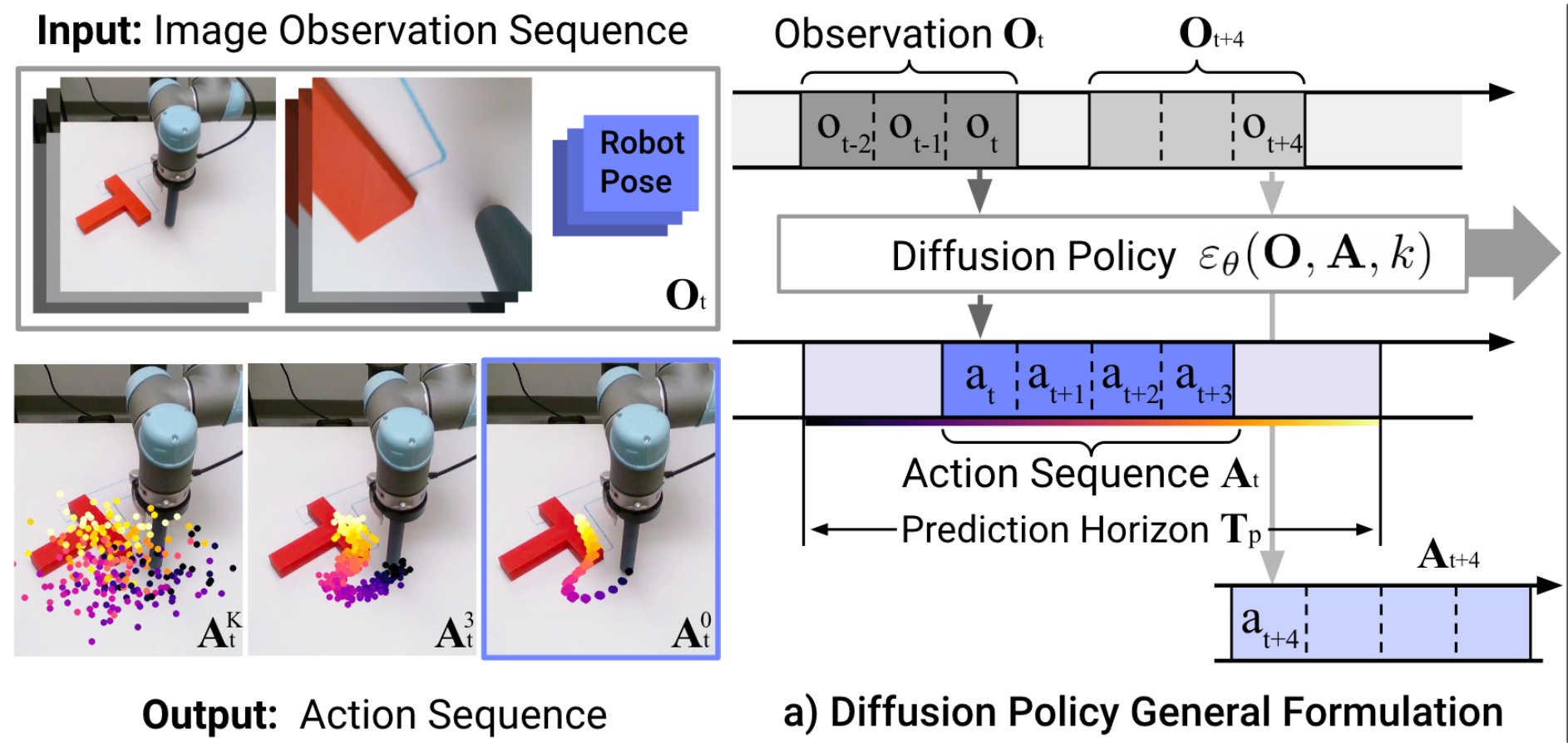
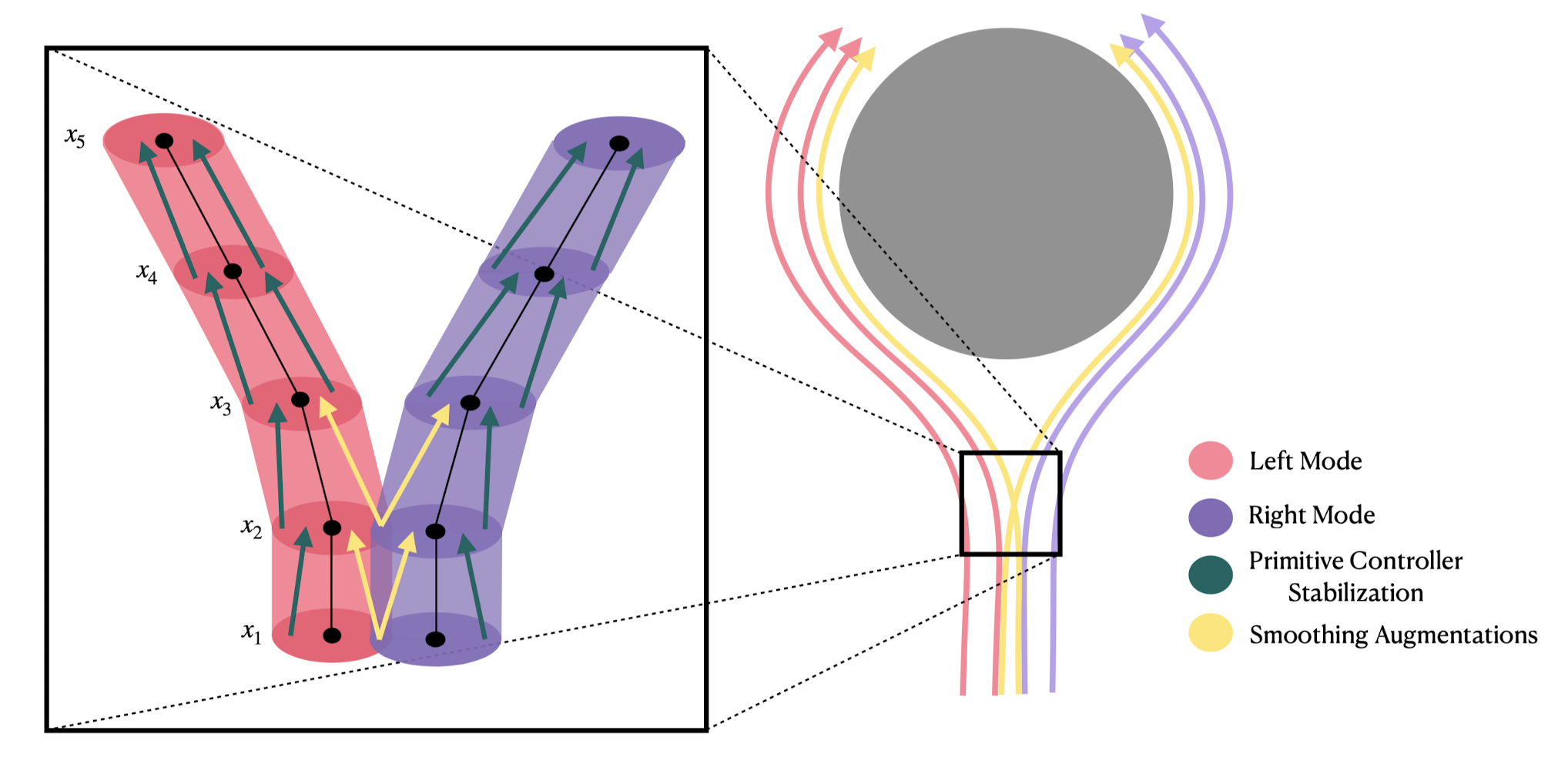
e.g. to deal with "multi-modal demonstrations"
Standard LQR:
Optimal actor:
Training loss:
stationary distribution of optimal policy
Optimal denoiser:
(deterministic) DDIM sampler:
Straight-forward extension to LQG:
Diffusion Policy learns (truncated) unrolled Kalman filter.
converges to LQR solution
with TRI's Soft Bubble Gripper
Open source:
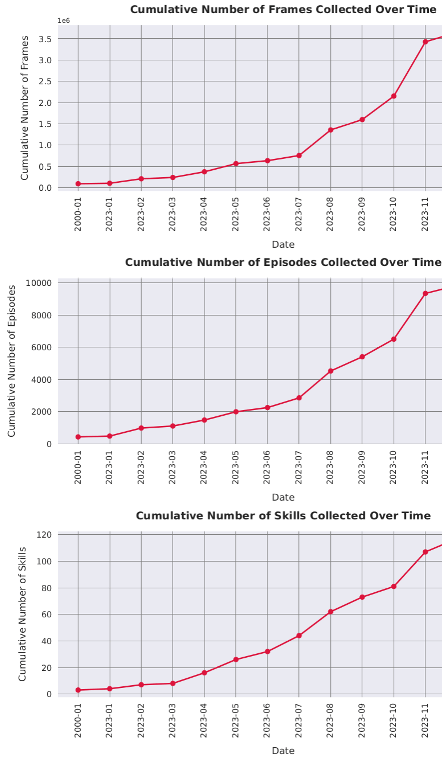
Cumulative Number of Skills Collected Over Time
I do think there is something deep happening here...
Graphs of Convex Sets
for trajectory optimization and RL
http://manipulation.mit.edu
http://underactuated.mit.edu
https://www.tri.global/careers
By russtedrake


