




































russtedrake PRO
Roboticist at MIT and TRI
MIT 6.821: Underactuated Robotics
Spring 2024, Lecture 24
Follow live at https://slides.com/d/ssAmqBQ/live
(or later at https://slides.com/russtedrake/spring24-lec24)
Image credit: Boston Dynamics
Levine*, Finn*, Darrel, Abbeel, JMLR 2016
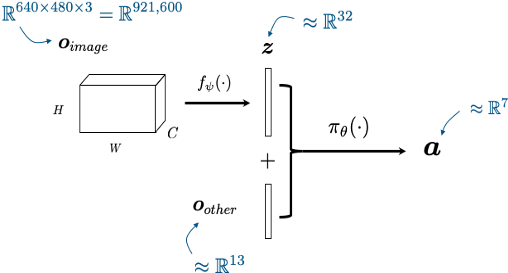
perception network
(often pre-trained)
policy network
other robot sensors
learned state representation
actions
x history
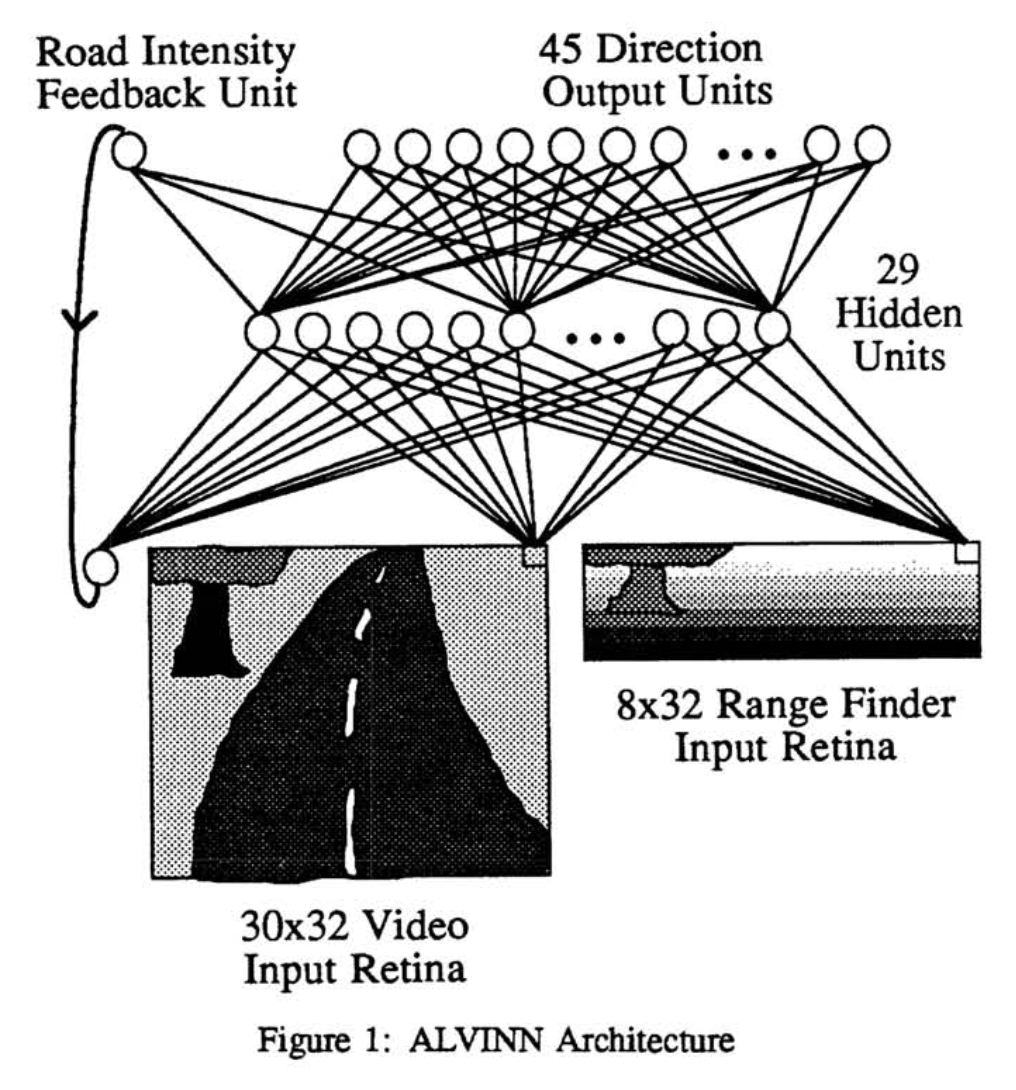
NeurIPS 1988
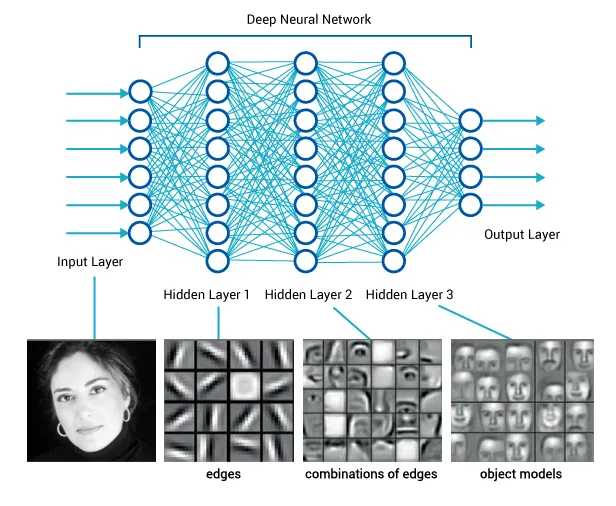
Andy Zeng's MIT CSL Seminar, April 4, 2022
Andy's slides.com presentation
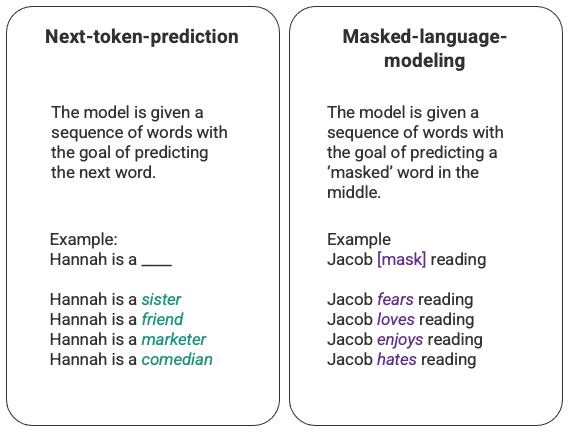
Example: Text completion
No extra "labeling" of the data required!
But it's trained on the entire internet...
And it's a really big network
Humans have also put lots of captioned images on the web
...
"A painting of a professor giving a talk at a robotics competition kickoff"
Input:
Output:
"a painting of a handsome MIT professor giving a talk about robotics and generative AI at a high school in newton, ma"
Input:
Output:
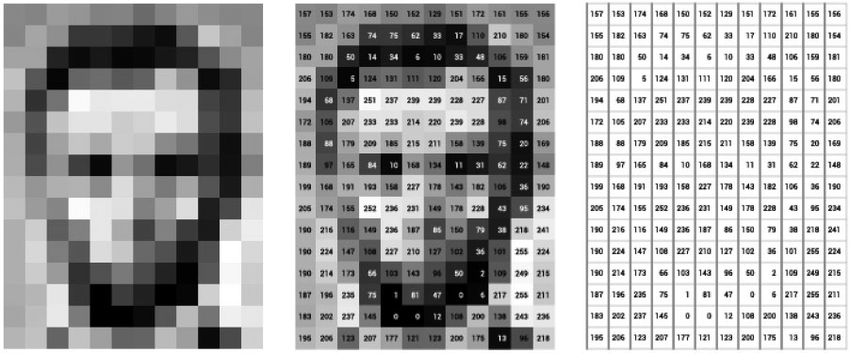
Is Dall-E just next pixel prediction?
great tutorial: https://chenyang.co/diffusion.html
great tutorial: https://chenyang.co/diffusion.html
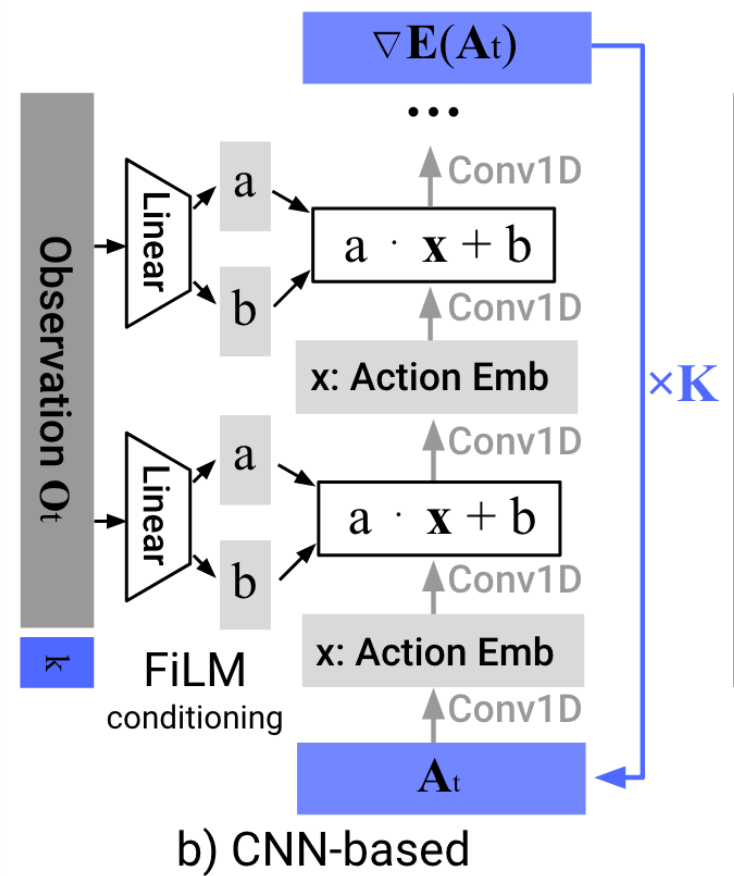
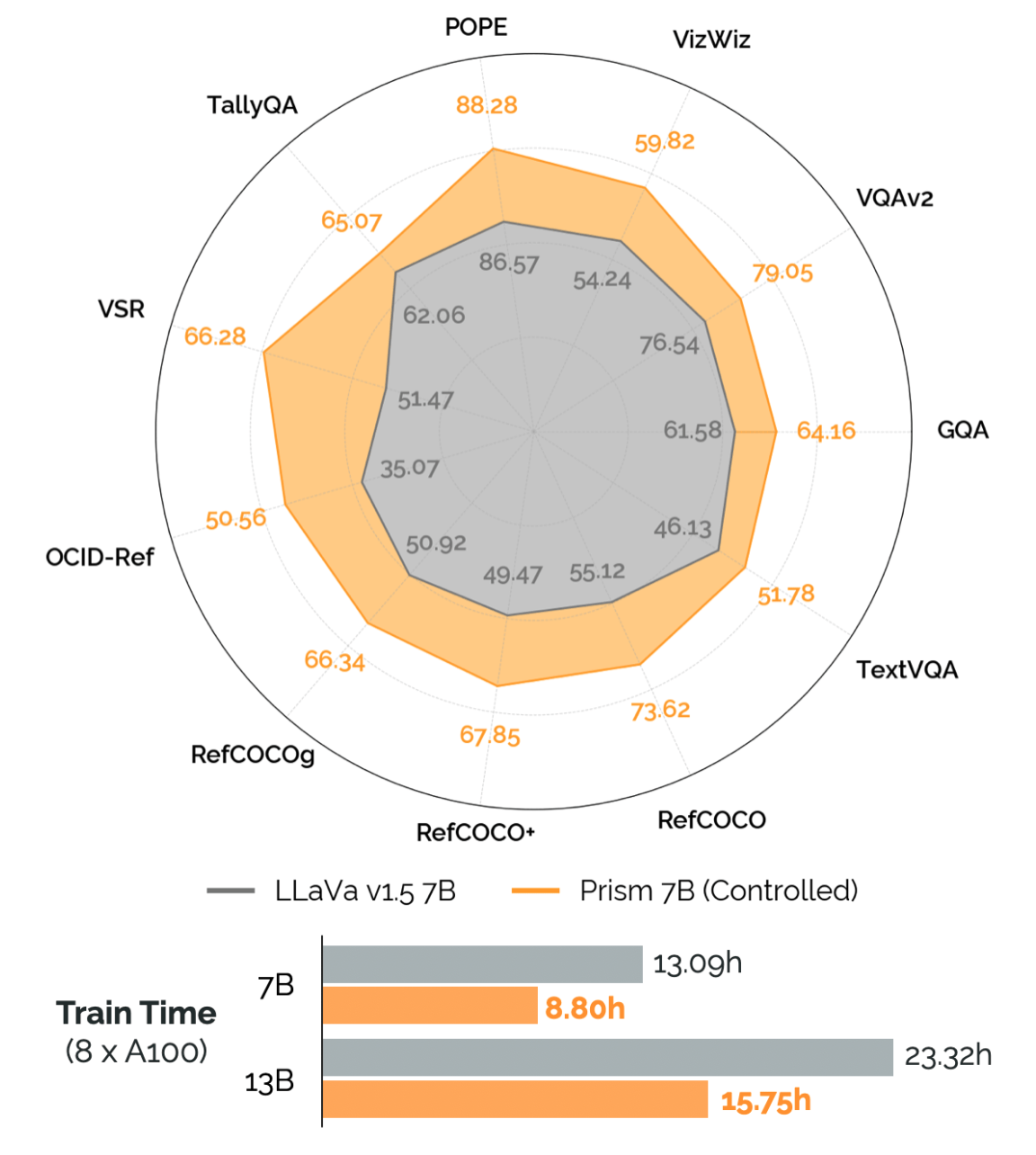
Image backbone: ResNet-18 (pretrained on ImageNet)
Total: 110M-150M Parameters
Training Time: 3-6 GPU Days ($150-$300)
input
output
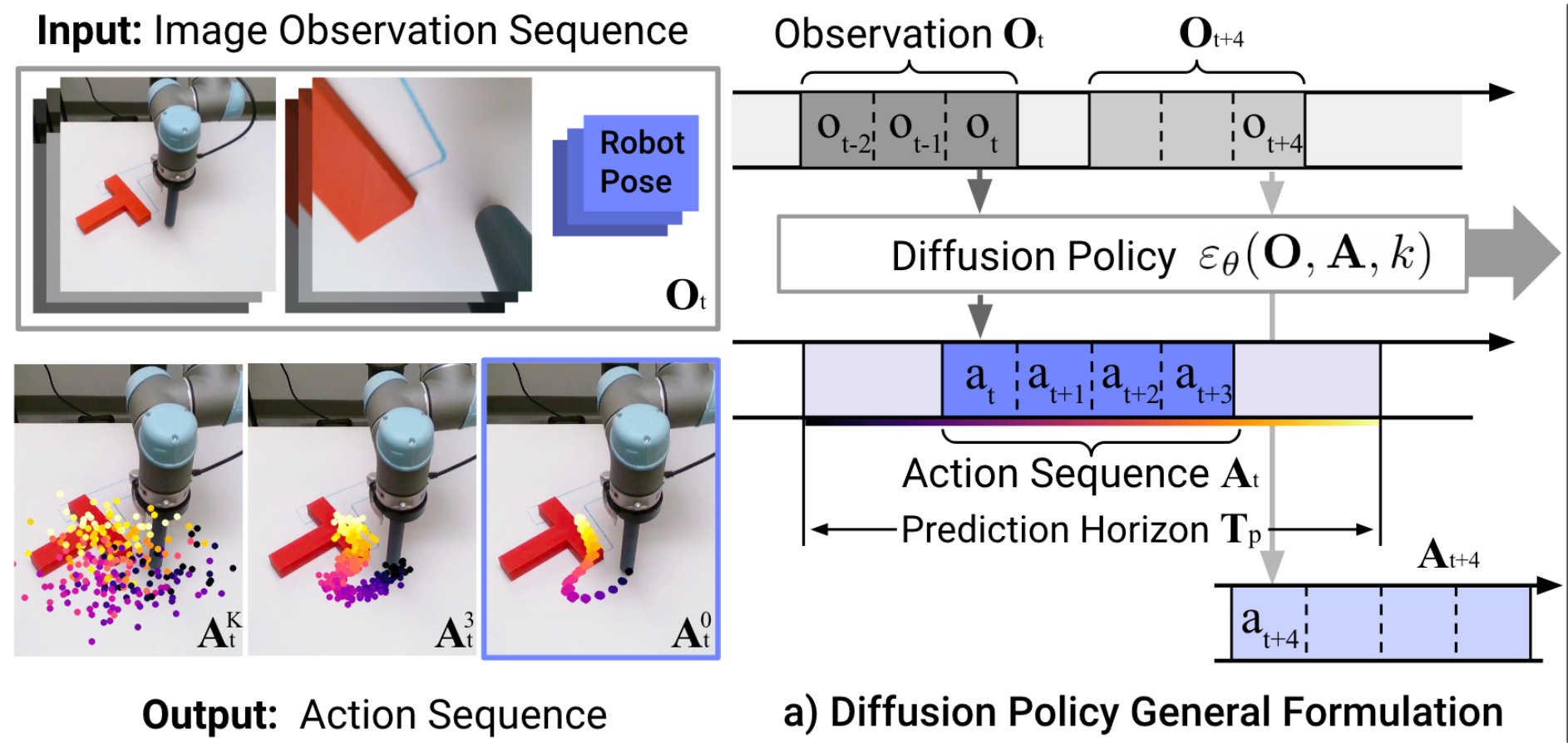
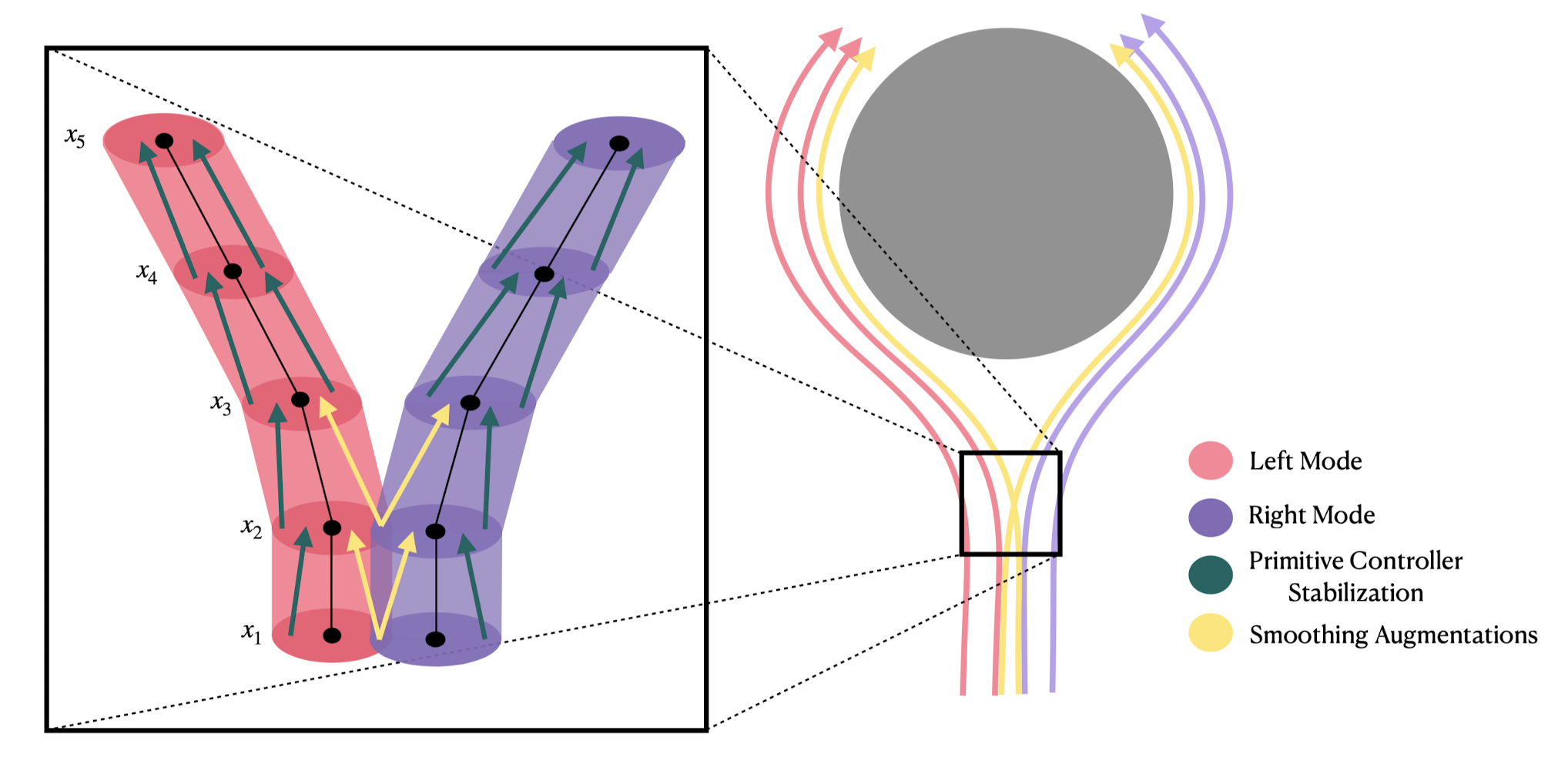
Control Policy
(as a dynamical system)
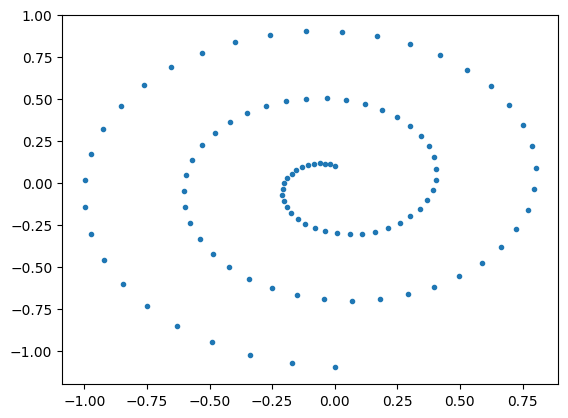
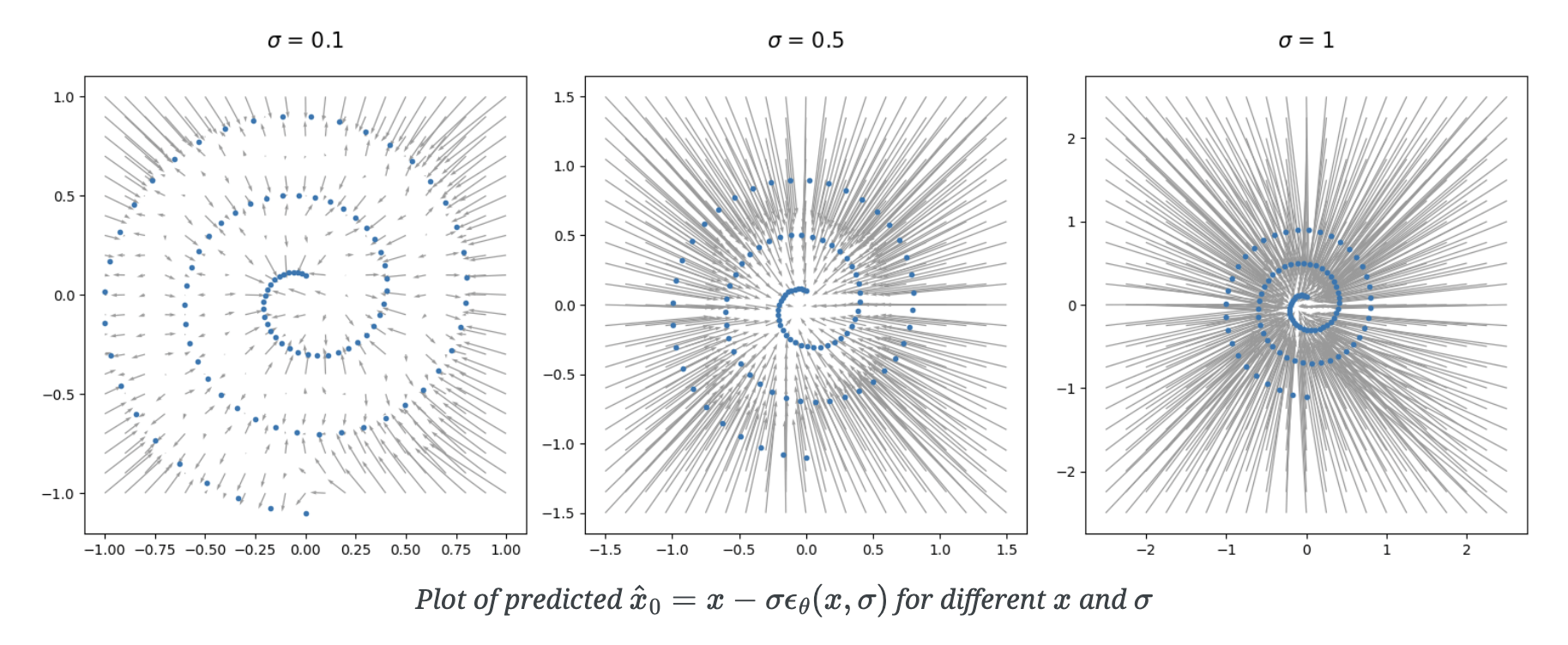
"Diffusion Policy" is an auto-regressive (ARX) model with forecasting
\(H\) is the length of the history,
\(P\) is the length of the prediction
Conditional denoiser produces the forecast, conditional on the history
(when training a single skill)
e.g. to deal with "multi-modal demonstrations"
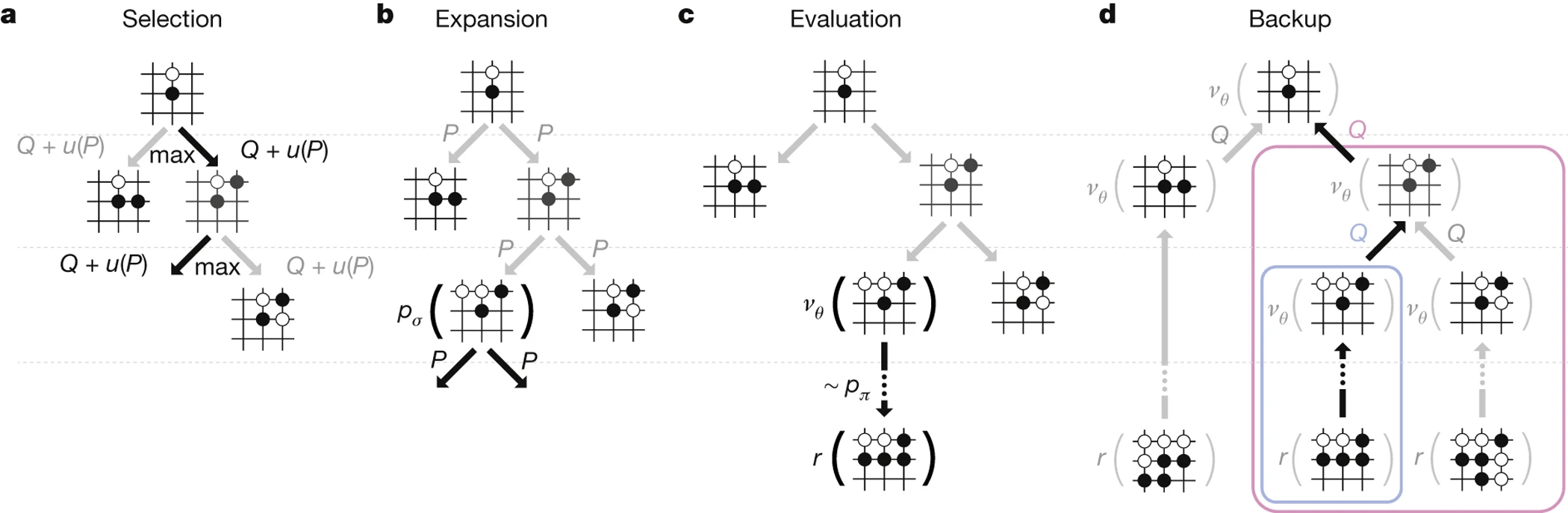
Learning categorial distributions already worked well (e.g. AlphaGo)
Diffusion helped extend this to high-dimensional continuous trajectories
with TRI's Soft Bubble Gripper
Open source:
large language models
visually-conditioned language models
large behavior models
\(\sim\) VLA (vision-language-action)
\(\sim\) EFM (embodied foundation model)
Why actions (for dexterous manipulation) could be different:
should we expect similar generalization / scaling-laws?
Success in (single-task) behavior cloning suggests that these are not blockers
Big data
Big transfer
Small data
No transfer
robot teleop
(the "transfer learning bet")
Open-X
simulation rollouts
novel devices
In both ACT and Diffusion Policy, predicting sequences of actions seems very important
Thought experiment:
To predict future actions, must learn
dynamics model
task-relevant
demonstrator policy
dynamics
Cumulative Number of Skills Collected Over Time
w/ Chelsea Finn and Sergey Levine
Big data
Big transfer
Small data
No transfer
robot teleop
(the "transfer learning bet")
Open-X
simulation rollouts
novel devices
w/ Shuran Song
Big data
Big transfer
Small data
No transfer
robot teleop
(the "transfer learning bet")
Open-X
simulation rollouts
novel devices
w/ Dorsa Sadigh
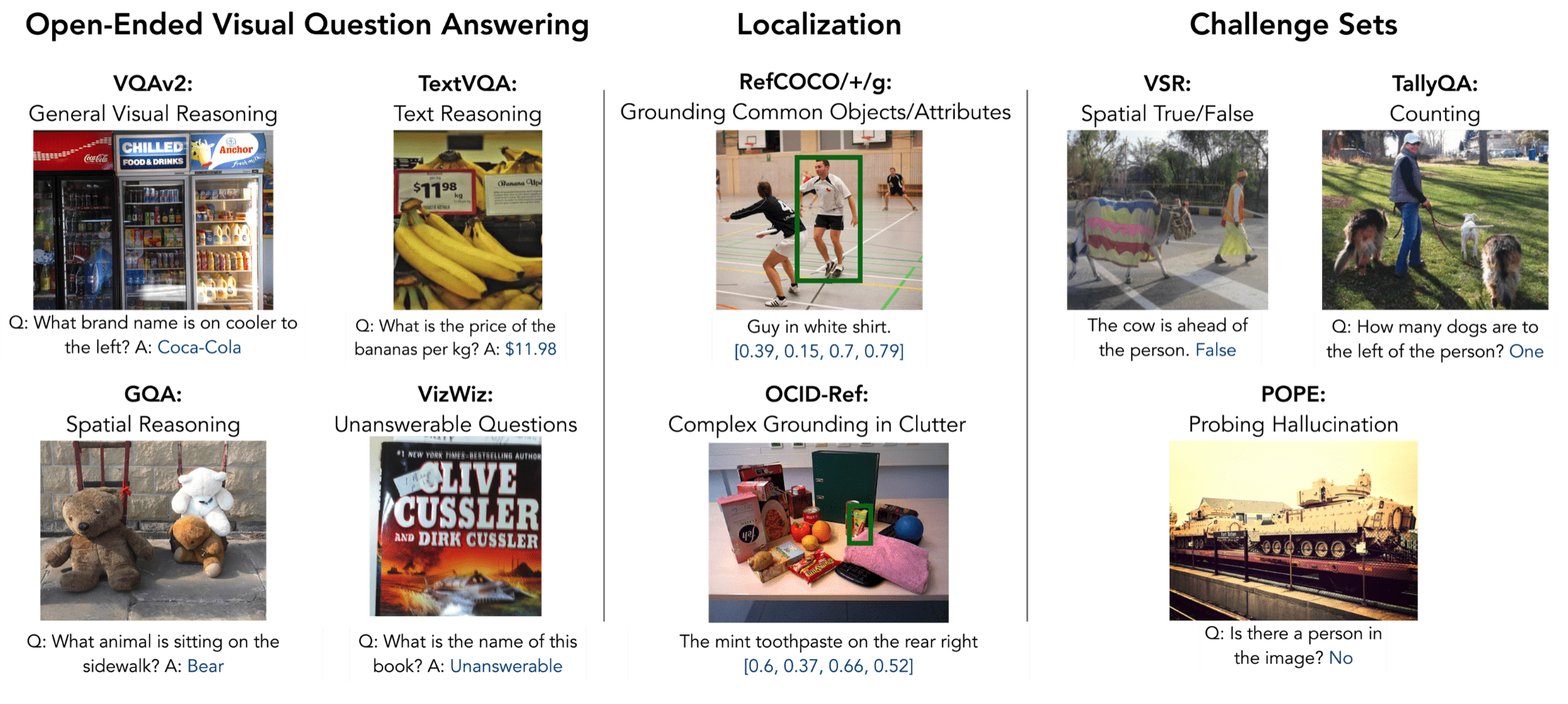
Fine-grained evaluation suite across a number of different visual reasoning tasks
Prismatic VLMS \(\Rightarrow\) Open-VLA
w/ Carl Vondrick
Enough to make robots useful (~ GPT-2?)
\(\Rightarrow\) get more robots out in the world
\(\Rightarrow\) establish the data flywheel
Then we get into large-scale distributed (fleet) learning...
"Graphs of Convex Sets" (GCS)
Example: we asked the robot to make a salad...
Rigorous hardware eval (Blind, randomized testing, etc)
But in hardware, you can never run the same experiment twice...
A foundation model for manipulation, because...
Some (not all!) of these basic research questions require scale
There is so much we don't yet understand... many open algorithmic challenges
By russtedrake


