Messaging with Kafka
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
Taras Voinarovskiy
voyn1991@gmail.com
Follow slides realtime at:
App
Hadoop
App
App
Other service
Real time analytics
Monitoring
Data Wharehouse
Literally in a Web
App
Hadoop
App
App
Other service
Real time analytics
Monitoring
Data Wharehouse
Broker
Yea in Java. What about Python?
Simple benchmark with 0 configuration local machine
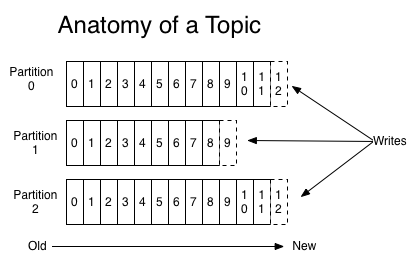
Kafka is similar to Logs...
Publish-subscribe messaging rethought as a distributed commit log
Broker 1
P1
P2
Broker 2
P2
P3
Broker 3
P1
P3
Producer
replication factor: 2; partitions: 3
Broker cluster
P1
P2
P3
Consumer group 1
group 2
B1
A1
A2
A3
A3
We just released aiokafka driver for asyncio:
Code hosted on GitHub
https://github.com/aio-libs/aiokafka
Read the docs:
What can we say after writing it
producer = AIOKafkaProducer(
loop=loop, bootstrap_servers='localhost:9092')
# Get cluster layout and topic/partition allocation
await producer.start()
# Produce messages.
await producer.send_and_wait(
"my_topic", b"Super message")
# Don't forget to close.
# This will flush all pending messages!
await producer.close()Behind the scenes
consumer = AIOKafkaConsumer(
"my_topic", loop=loop, group_id="worker_group",
bootstrap_servers='localhost:9092')
# Get cluster layout and topic/partition allocation
await consumer.start()
async for msg in consumer:
# Process message
print(msg.value)
# Optionally commit
consumer.commit()
# Don't forget to close.
# This will commit last offset in AutoCommit mode.
await consumer.stop()Behind the scenes
Taras Voinarovskiy
voyn1991@gmail.com
slides available:
yea, I know, Zookeeper... I only had 40 minutes =)