Introduction (101)
*Click*
Repository
Preso
Who am I?
twitter: @pdolega
github: github.com/pdolega

Software Engineer /
Entrepreneur

What is Slick?
Not an ORM

ORM problems
N+1 problem (lazy / eager fetching)
Session context scope
Execution under the cover (cache)
O-R impedance mismatch
False promise
Leaky abstraction
FRM
Embrace database model through a functional paradigm.
If you come from ORM world:
Reactive (™?)
...wait a minute, JDBC is blocking anyway
Everything is async...
db_pool_connections =
(core_count * 2) + effective_spindle_count
source: postgres docs
Brilliant presentation by @StefanZeiger: Reactive Slick for Database Programming
Server handling 10 000 client connections may need not more than 10 connection
It's still viable
Async drivers?
The point being...
Use less threads / let CPU be busy
Threads are expensive
Yet traditionally they are wasted on IO
Don't block general threads / use designated thread pool
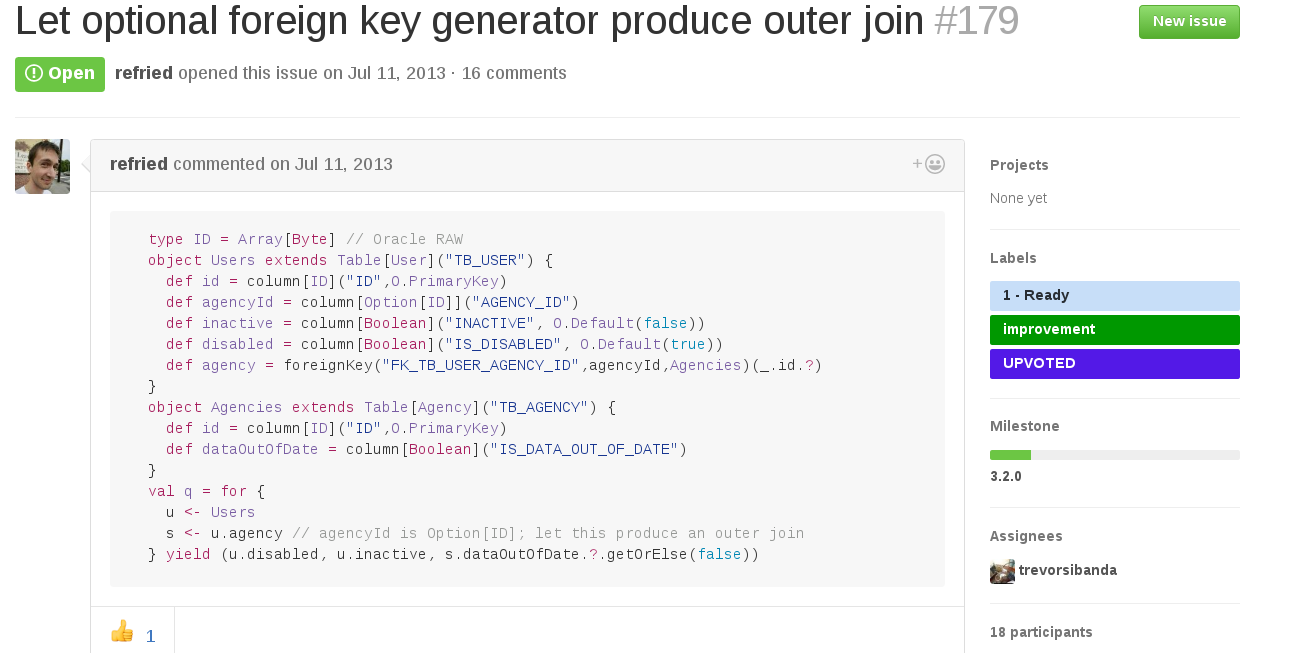
Description
vs
execution
transactions.stream()
.filter(t -> t.getType() == Transaction.GROCERY)
.sorted(comparing(Transaction::getValue).reversed())
.map(Transaction::getId) // up to this line - description
.collect(toList()) // executionJava 8 streams
db.run( // execution
(StudentCourseSegmentTable // description
join CourseTable on (_.courseId === _.id)
join StudentTable on (_._1.studentId === _.id)).result
)Scala / Slick
Last but not least
Type-Safe
db.run( // execution
(StudentCourseSegmentTable // description
join CourseTable on (_.courseId === _.id)
join StudentTable on (_._1.studentId === _.id))
.result
)If you were to remember only one thing
Monadic Trio
DBIO
Query
description of a DB query
description of 1...N DB operations
Future
gimme a break...
The other thing worth to remember
It's (mostly) all about DBIO composition
And...
The best approach to write queries using Slick’s type-safe API is thinking in terms of Scala collections.
*Click*
Overview
- Tables
- Actions
- Queries
- Composition / Transactions
Code samples:
SmokeSpec
"correctly open db" in {
val db = Database.forConfig("memoryDb")
val results = db.run(sql"SELECT 2 + 3".as[(Int)])
// option 1 - bad
blockingWait(results).head shouldBe 5
// option 2 - better
results.map { r =>
r.head shouldBe (5)
}.futureValue // this is only for unit tests to work
}
memoryDb = {
connectionPool = disabled
url = "jdbc:h2:mem:slick-101"
driver = "org.h2.Driver"
user = ""
password = ""
keepAliveConnection = true
}Config
Tables
Code samples 2:
TableSpec
// in-application respresentation of table's tuple
case class University(name: String,
id: Long = -1L)
// definition of table
class UniversityTable(tag: Tag) extends Table[University](
tag, "university") {
def name = column[String]("name")
def id = column[Long]("id", O.PrimaryKey, O.AutoInc)
// default projection
def * = (name, id) <> (University.tupled,
University.unapply)
}
// 'table' object used for interacting with in app
lazy val UniversityTable = TableQuery[UniversityTable] "be insertable and retrievable - poor version" in {
// read everything from a table
blockingWait(db.run(UniversityTable.result)) should
have size 0
// insert into table
blockingWait(db.run(
UniversityTable ++= Seq(
University("Hogwart"),
University("Scala University")
)
))
// read again
val results = blockingWait(
db.run(UniversityTable.result)
)
results.map(_.name) should contain theSameElementsAs
Seq("Hogwart", "Scala University")
}Poor version
Actions
Monadic Trio
memDb.run(
UniversityTable
.filter(_.name === "Hogwarth") // Query
.result // DBIOAction (DBIO)
) // Future db.run( // first all within this block is constructed
// and the resulting DBIO is passed to db.run
// to be executed
for {
emptyResults <- UniversityTable.result
_ <- insertUnis
nonEmptyResults <- UniversityTable.result
} yield {
emptyResults should have size 0
nonEmptyResults.map(_.name) should
contain theSameElementsAs
Seq("Hogwart", "Scala University")
}
)
...
def insertUnis = UniversityTable ++= Seq(
University("Hogwart"),
University("Scala University")
) Better version
DBIOAction / DBIO
DBIOAction[R, S, E]
R - type of result
S - streaming / not streaming
E - what kind of effect
DBIO[R] =
DBIOAction[R, NoStream, Effect.All]
R - type of result
def executeReadOnly[R, S <: dbio.NoStream](
readOnlyOper: DBIOAction[R, S, Effect.Read] // param decl
): Future[Unit] = { // result type
db.run(readOnlyOper).map { results =>
log.info(s"Results are: $results")
}
}// this works
executeReadOnly(UniversityTable.result)// this won't even compile
executeReadOnly(UniversityTable += University("Nice try!"))// DBIOAction[Seq[University], Stream, Effect.Read]
db.run(
UniversityTable.result
)
...
// DBIOAction[Option[Int], NoStream, Effect.Write]
db.run(
UniversityTable += University("Nice try!")
)
...
// DBIOAction[Option[Int], NoStream,
// Effect.Write with Effect.Transactional]
db.run(
(UniversityTable += University("Nice try!"))
.transactionally
)
...
// DBIOAction[Unit, NoStream, Effect.Schema]
db.run(
UniversityTable.schema.create
)Queries
Query
Query[M, U, C]
M - mixed type
U - unpacked type
C - collection type
UniversityTable
.filter(_.name === "Hogwarth")What are unpacked (U), mixed (M) and collection (C) types?
UniversityTable
.filter(_.name === "Hogwarth")
// _ above is UniverityTable (M)
// unpacked type
case class University(name: String,
id: Long = -1L)
// mixed type
class UniversityTable(tag: Tag) extends Table[University](
tag, "university") {
def name = column[String]("name")
def id = column[Long]("id", O.PrimaryKey, O.AutoInc)
// default projection
def * = (name, id) <> (University.tupled,
University.unapply)
}
db.run( // Future[Seq[University]]
UniversityTable.filter(uni => // Query[UniversityTable,
// University, Seq]
uni.name === "Hogwarth"
)
.result // DBIO[Seq[University]]
)
Code samples:
QueriesSpec
// here we get Future[Seq[Student]]
db.run(CourseModel.StudentTable.result)
// here I map over Future
// within map we have results: Seq[Student]
.map { results =>
// we map it to (String, String)
results.map(student => (student.name,
student.surname))
}
// we end up with Future[Seq[(String, String)]]select "NAME", "MIDDLE_NAME", "SURNAME", "NATIONALITY", "ID"
from "STUDENT"Actual query
db.run(
CourseModel.StudentTable.map { student =>
// here I map over query!
(student.name, student.surname)
}
.result
)
// we end up with Future[Seq[(String, String)]]select "NAME" "SURNAME"
from "STUDENT"Actual query
Do you speak it?!
Queries
select "NAME",
"MIDDLE_NAME",
"SURNAME",
"NATIONALITY",
"ID"
from "STUDENT"
StudentTable
// or
for {student <- StudentTable }
yield student
execQuery(
StudentTable
)
def execQuery[E, U, C[_]](q: Query[E, U, C]): Future[C[U]] =
db.run( // convert into Future
q.result // convert into DBIO
)
StudentTable
.map(_.name)
select "NAME"
from "STUDENT"
StudentTable
.map(s =>
(s.name, s.middleName.ifNull("*no-middlename*"))
)
.sortBy(_.name) select "NAME",
ifnull("MIDDLE_NAME",'*no-middlename*')
from "STUDENT"
order by "NAME"Wrong!
StudentTable
.map(s =>
(s.name, s.middleName.ifNull("*no-middlename*"))
)
.sortBy(_._1) select "NAME",
ifnull("MIDDLE_NAME",'*no-middlename*')
from "STUDENT"
order by "NAME"OK!
StudentTable
.sortBy(_.name)
.map(s =>
(s.name, s.middleName.ifNull("*no-middlename*"))
) select "NAME",
ifnull("MIDDLE_NAME",'*no-middlename*')
from "STUDENT"
order by "NAME"
StudentTable
.map(nat => nat.nationality ++ " ")
.map(_.toUpperCase)
.map(_.trim)
.map((_, currentTime, pi))
.map(row =>
row._1 ++ " " ++
row._2.asColumnOf[String] ++ " " ++
row._3.asColumnOf[String]
) select (((ltrim(rtrim(ucase("NATIONALITY"||' ')))||' ')
|| cast(curtime() as VARCHAR))||' ')
|| cast(pi() as VARCHAR)
from "STUDENT"
StudentTable
.filter(_.name === "Tom")
// or
for {
student <- StudentTable if student.name === "Tom"
} yield student
select "NAME", "MIDDLE_NAME", "SURNAME", ...
from "STUDENT"
where "NAME" = 'Tom' StudentTable
.filterNot(student =>
student.name === "Tom" &&
student.surname.startsWith("Smi")
)
// or
for {
student <- StudentTable if !(
student.name === "Tom" &&
student.surname.startsWith("Smi"))
} yield student
select "NAME",
"MIDDLE_NAME",
"SURNAME",
"NATIONALITY",
"ID"
from "STUDENT"
where not (("NAME" = 'Tom') and
("SURNAME" like 'Smi%' escape '^'))
StudentTable
.filter(student => student.middleName.nonEmpty)
.sortBy(s => (s.name.desc, s.middleName.asc))
.distinct
select distinct "NAME", ...
from "STUDENT"
where "MIDDLE_NAME" is not null
order by "NAME" desc, "MIDDLE_NAME"
StudentTable
.map(s => (s.name, s.surname))
.drop(2)
.take(3)
select ...
from "STUDENT"
limit 3 offset 2
StudentTable
.map(s => (s.name, s.surname))
.take(3)
.drop(2)
select ...
from "STUDENT"
limit 1 offset 3
StudentTable
.filter(_.surname =!= "Test")
.groupBy(_.surname)
.map { case (surname, group) =>
(surname, group.map(_.name).countDistinct)
}
.filter(row => row._2 > 5)
select "SURNAME", count(distinct "NAME")
from "STUDENT"
where not ("SURNAME" = 'Test')
group by "SURNAME"
having count(distinct "NAME") > 5Joins
Monadic
vs
applicative
// student course segment
case class StudentCourseSegment(studentId: Id[Student],
courseId: Id[Course],
semesterId: Id[Semester],
id: Id[StudentCourseSegment] = Id.none)
class StudentCourseSegmentTable(tag: Tag) extends
Table[StudentCourseSegment](tag, "STUDENT_COURSE_SEGMENT") {
def studentId = column[Id[Student]]("STUDENT_ID")
def courseId = column[Id[Course]]("COURSE_ID")
def semesterId = column[Id[Semester]]("SEMESTER_ID")
def id = column[Id[StudentCourseSegment]]("ID", O.PrimaryKey, O.AutoInc)
def * = (studentId, courseId, semesterId, id) <> (StudentCourseSegment.tupled,
StudentCourseSegment.unapply)
// foreign keys
def student = foreignKey("fk_segment_student", studentId, StudentTable)(_.id)
def course = foreignKey("fk_segment_course", courseId, CourseTable)(_.id)
def semester = foreignKey("fk_segment_semester", semesterId, SemesterTable)(_.id)
}
lazy val StudentCourseSegmentTable = TableQuery[StudentCourseSegmentTable]
def student =
foreignKey("fk_segment_student",
studentId, StudentTable)(_.id)
def course =
foreignKey("fk_segment_course",
courseId, CourseTable)(_.id)
def semester =
foreignKey("fk_segment_semester",
semesterId, SemesterTable)(_.id)
...
// in my table mapping
def id = column[Id[StudentCourseSegment]]("ID",
O.PrimaryKey, O.AutoInc)
...
// in my case class
case class StudentCourseSegment(studentId: Id[Student],
courseId: Id[Course],
semesterId: Id[Semester],
id: Id[StudentCourseSegment] = Id.none)
...db.run((
for {
segment <- StudentCourseSegmentTable
course <- segment.course // foreign key
student <- segment.student // foreign key
} yield (course, student)
)db.run(
StudentCourseSegmentTable
join CourseTable on (_.courseId === _.id)
join StudentTable on (_._1.studentId === _.id)
).map {
case ((segment, course), student) =>
(course, student)
}
)Monadic
Applicative
StudentCourseSegmentTable
join CourseTable on (_.studentId === _.id) // WTF
join StudentTable on (_._1.courseId === _.id)Type-safety again
Wrong!
More complicated join
Applicative vs monadic
StudentCourseSegmentTable
.join(StudentTable)
.on { case (segment, student) =>
student.id === segment.studentId }
.join(CourseTable)
.on { case ((segment, _), course) =>
course.id === segment.courseId }
.join(SemesterTable)
.on { case (((segment, _), _), semester) =>
semester.id === segment.semesterId }
.filter { case (((_, student), _), _) =>
student.name === "Tim"
} select x2."NAME",
...
from "STUDENT_COURSE_SEGMENT" x2,
"STUDENT" x3,
"COURSE" x4,
"SEMESTER" x5
where (x3."NAME" = 'Tim') and
(((x3."ID" = x2."STUDENT_ID") and
(x4."ID" = x2."COURSE_ID")) and
(x5."ID" = x2."SEMESTER_ID")) for {
segment <- StudentCourseSegmentTable
student <- segment.student if student.name === "Tim"
course <- segment.course
semester <- segment.semester
} yield (segment, student, course, semester) select x2."NAME",
...
from "STUDENT_COURSE_SEGMENT" x2,
"STUDENT" x3,
"COURSE" x4,
"SEMESTER" x5
where (x3."NAME" = 'Tim') and
(((x3."ID" = x2."STUDENT_ID") and
(x4."ID" = x2."COURSE_ID")) and
(x5."ID" = x2."SEMESTER_ID"))Sometimes one form is more elegant than the other
Outer joins
// document
case class Document(studentId: Option[Id[Student]],
name: String,
uuid: String,
id: Id[Document] = Id.none)
class DocumentTable(tag: Tag) extends Table[Document]
(tag, "DOCUMENT") {
def studentId = column[Option[Id[Student]]]("STUDENT_ID")
def name = column[String]("NAME")
def uuid = column[String]("UUID")
def id = column[Id[Document]]("ID",
O.PrimaryKey, O.AutoInc)
def * = (studentId, name, uuid, id) <>
(Document.tupled, Document.unapply)
def student = foreignKey("fk_document_student",
studentId, StudentTable)(_.id.?)
}
lazy val DocumentTable = TableQuery[DocumentTable]
case class Document(studentId: Option[Id[Student]],
name: String,
uuid: String,
id: Id[Document] = Id.none)
//...
//...
class DocumentTable(tag: Tag) extends Table[Document]
(tag, "DOCUMENT") {
def studentId = column[Option[Id[Student]]]("STUDENT_ID")
//...
//...
def student = foreignKey("fk_document_student",
studentId, StudentTable)(_.id.?)
}
DocumentTable
.joinLeft(StudentTable).on(_.studentId === _.id) select x2."STUDENT_ID", ..., x3."ID", ...
from "DOCUMENT" x2
left outer join "STUDENT" x3
on x2."STUDENT_ID" = x3."ID"
DocumentTable
.joinLeft(StudentTable).on(_.studentId === _.id)
.filter { case(doc, student) =>
student.map(_.name) === "Tom"
} select x2."STUDENT_ID", ..., x3."ID", ...
from "DOCUMENT" x2
left outer join "STUDENT" x3
on x2."STUDENT_ID" = x3."ID"
where x3."NAME" = 'Tom'Slick 3.2 ?
No nice monadic form for outer joins
Composition / Transactions
DBIO.transactionally
*Click*
db.run(
(UniversityTable ++= Seq(
University("Hogwart"),
University("Scala University")
)).transactionally
)Transactions - example
OK, but how do we combine DB operations?
DBIO is a monad

db.run(
(for {
dbio1 <- insertUnis
dbio2 <- ...
dbio3 <- ...
...
dbioN <- ...
} yield {
...
}).transactionally
)def insertUnis: DBIO[Option[Int]] =
UniversityTable ++= Seq(
University("Hogwart"),
University("Scala University")
)map / flatMap
seq
val combined: DBIO[Unit] = DBIO.seq(
produceDbOper1, // DBIO[T]
produceDbOper2, // DBIO[R]
produceDbOper3 // DBIO[M]
)sequence
val combined: DBIO[Seq[T]] = DBIO.sequence(
Seq(
produceDbOper1, // DBIO[T]
produceDbOper2, // DBIO[T]
produceDbOper3 // DBIO[T]
)
) db.run( // Future[Seq[Seq[Course]]]
for {
students <- StudentTable.result
courses <- DBIO.sequence(students.map(fetchMoreData))
} yield {
courses
}
)
...
private def fetchMoreData(student: Student):
DBIO[Seq[Course]] = {
(for {
segment <- StudentCourseSegmentTable
if segment.studentId === student.id
course <- segment.course
} yield {
course
}).result
}unit
db.run(
(for {
student <- StudentTable
.filter(_.name === "Tim").result // DBIO
smthNotDb <- calculateSomethingNotDb(student) // duh?!
_ <- updateBasedOnCalculation(smthNotDb) // DBIO
} yield (...)).transcationally
)Wrong!
DBIO.successful
db.run(
(for {
student <- StudentTable
.filter(_.name === "Tim").result // DBIO
smthNotDb <- DBIO.successful(
calculateSomething(student)
) // Yeah!
_ <- updateBasedOnCalculation(smthNotDb) // DBIO
} yield (...)).transcationally
)
def execTransact[T](dbio: DBIO[T]): Future[T] =
db.run(dbio.transactionally)Combine operations & fire within transtion
Summary
Future / DBIO / Query
Slick is not ORM
DBIO composition
Think in terms of Collection API
Last but not least
Slick 3.1.1 and 3.2 are much better in terms of SQL generation
Questions?

Resources
Slick docs: http://slick.lightbend.com/docs/
Online workshop by Dave Gurnell: https://vimeo.com/148074461
Excelent book: http://underscore.io/books/essential-slick/
Bonus
for {
segment <- StudentCourseSegmentTable
student <- segment.student if student.name === "Tim"
course <- segment.course
semester <- segment.semester
} yield (segment, student, course, semester)
DEBUG s.c.QueryCompilerBenchmark - ------------------- Phase: Time ---------
DEBUG s.c.QueryCompilerBenchmark - assignUniqueSymbols: 0.446286 ms
DEBUG s.c.QueryCompilerBenchmark - inferTypes: 0.239283 ms
DEBUG s.c.QueryCompilerBenchmark - expandTables: 0.984031 ms
DEBUG s.c.QueryCompilerBenchmark - forceOuterBinds: 1.048910 ms
DEBUG s.c.QueryCompilerBenchmark - removeMappedTypes: 0.536035 ms
DEBUG s.c.QueryCompilerBenchmark - expandSums: 0.016068 ms
DEBUG s.c.QueryCompilerBenchmark - emulateOuterJoins: 0.108066 ms
DEBUG s.c.QueryCompilerBenchmark - expandRecords: 0.421471 ms
DEBUG s.c.QueryCompilerBenchmark - flattenProjections: 2.212847 ms
DEBUG s.c.QueryCompilerBenchmark - rewriteJoins: 2.219579 ms
DEBUG s.c.QueryCompilerBenchmark - verifySymbols: 0.204175 ms
DEBUG s.c.QueryCompilerBenchmark - relabelUnions: 0.086386 ms
DEBUG s.c.QueryCompilerBenchmark - createAggregates: 0.013349 ms
DEBUG s.c.QueryCompilerBenchmark - resolveZipJoins: 0.126179 ms
DEBUG s.c.QueryCompilerBenchmark - pruneProjections: 0.567347 ms
DEBUG s.c.QueryCompilerBenchmark - rewriteDistinct: 0.018858 ms
DEBUG s.c.QueryCompilerBenchmark - createResultSetMapping: 0.274411 ms
DEBUG s.c.QueryCompilerBenchmark - hoistClientOps: 0.649790 ms
DEBUG s.c.QueryCompilerBenchmark - reorderOperations: 0.643005 ms
DEBUG s.c.QueryCompilerBenchmark - mergeToComprehensions: 4.482695 ms
DEBUG s.c.QueryCompilerBenchmark - optimizeScalar: 0.179255 ms
DEBUG s.c.QueryCompilerBenchmark - removeFieldNames: 1.145481 ms
DEBUG s.c.QueryCompilerBenchmark - codeGen: 3.783455 ms
DEBUG s.c.QueryCompilerBenchmark - TOTAL: 20.406962 ms
val query = Compiled { name: Rep[String] =>
for {
segment <- StudentCourseSegmentTable
student <- segment.student if student.name === name
course <- segment.course
semester <- segment.semester
} yield (segment, student, course, semester)
}
...
...
db.run(query("Tim").result)Precompilation
Property age = Property.forName("age");
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.disjunction()
.add( age.isNull() )
.add( age.eq( new Integer(0) ) )
.add( age.eq( new Integer(1) ) )
.add( age.eq( new Integer(2) ) )
) )
.add( Property.forName("name").in(
new String[] { "Fritz", "Izi", "Pk" } )
)
.list();Criteria API?
StudentTable.filter(row: StudentTable => ...)Criteria API?
StudentTable.filter(myExtractedFilter)
def myExtractedFilter(row: StudentTable): Rep[Boolean] = {
row.name === "Tom" && row.nationality === "American"
}
StudentTable
.map(s => (s.name, s.surname))
.distinctOn(_._1)
select "NAME", min("SURNAME")
from "STUDENT"
group by "NAME"Slick 101
By Pawel Dolega



