Actor-Critic
Reinforcement Learning
Text
Aadesh Neupane

-
Evaluation of action candidates
-
Action Selection
-
Learning
Decision Making
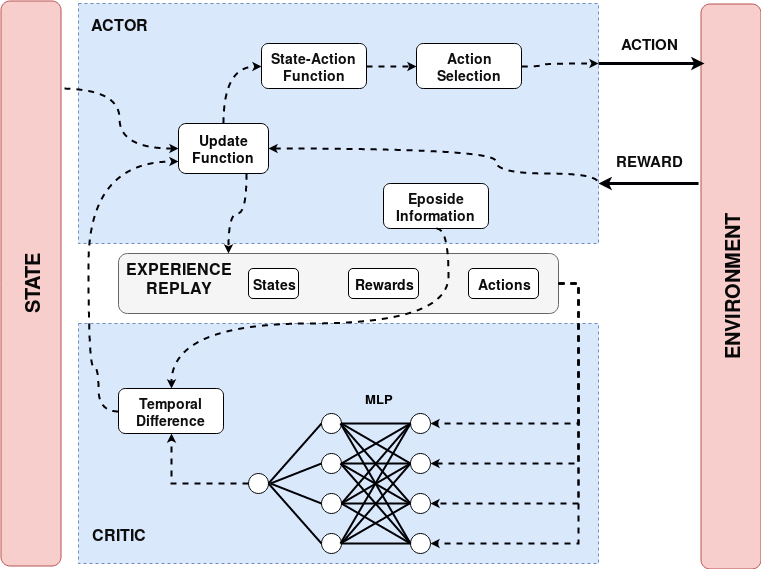
Actor/Critic RL
-
Temporal Difference
-
Q-learning
-
SARSA
-
REINFORCE
-
Policy gradient
-
Evolutionary Algorithms
Critic
Actor
Disadvantages
Actor/Critic RL
-
Computational intensive
-
don't optimize directly over policy space
-
large variance
-
estimation independently of past estimates
Critic
Actor
Actor-Critic RL

Image credit : Massimiliano Patacchiola
Model
Results
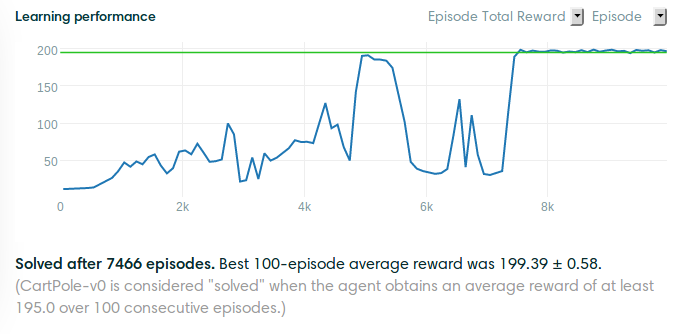
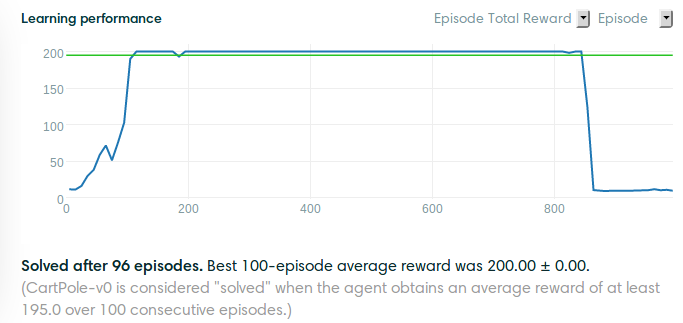
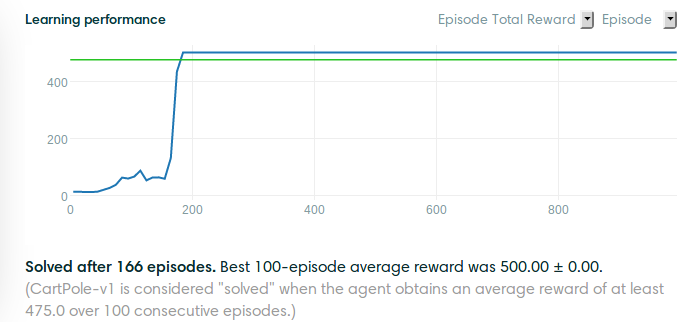
Cartpole-v0
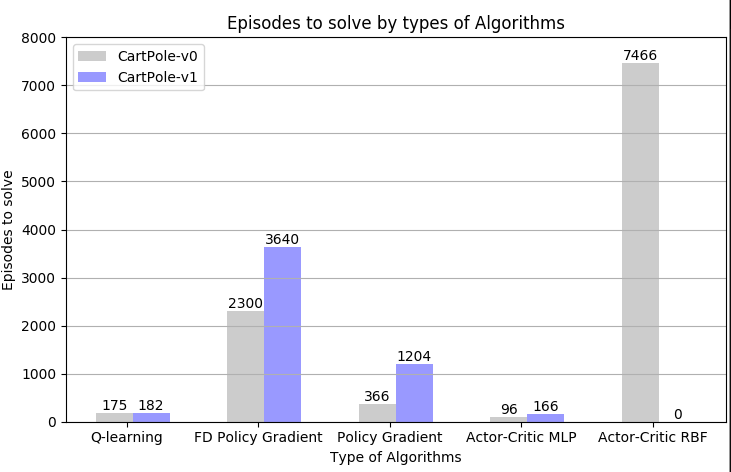
Cartpole-v1
Results
Questions
