MCP Server: herramientas para la ia
De ChatGPT a la SAT
-
Cloud Software Engineer
-
X & Linkedin: @aalonzolu
-
Huehuetenango, Guatemala
- Miembro de ASITI
- Anterior Miembro de Arduino Guatemala
- Apasionado por el Software libre
- Curioso y autodidacta
Andrés Alonzo

¿Qué es el Model Context Protocol (MCP)?
-
MCP es un estándar open-source para conectar aplicaciones de IA con sistemas externos.
-
Permite a apps como Claude o ChatGPT conectarse a:
-
Fuentes de datos (archivos locales, bases de datos, APIs internas)
-
Herramientas (buscadores, calculadoras, servicios externos)
-
Workflows (prompts especializados, flujos de trabajo)
-
-
Analogía: MCP es como un puerto USB-C para aplicaciones de IA: una interfaz estándar para enchufar “cualquier cosa”.
¿Por qué importa MCP?
-
Para desarrolladores: reduce tiempo y complejidad al integrar IA con sistemas existentes.
-
Para aplicaciones de IA: acceso a un ecosistema de datos, herramientas y apps ya integradas.
-
Para usuarios finales: asistentes más capaces que:
-
Acceden a tu información
-
Ejecutan acciones en tu nombre (con control y permisos)
-
Arquitectura general de MCP
-
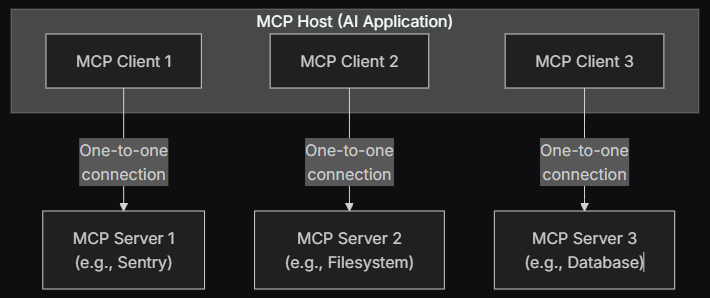
MCP sigue una arquitectura cliente-servidor, pero con 3 actores:
-
MCP Host: la app de IA (p. ej. Claude Desktop, IDE, chatbot corporativo)
-
MCP Client: componente que mantiene la conexión con un MCP Server
-
MCP Server: programa que provee contexto y capacidades al cliente
-
-
El host crea un MCP client por cada MCP server, 1:1.
-
Los MCP servers pueden correr:
-
Localmente (por ejemplo vía STDIO)
-
Remoto (por ejemplo vía HTTP “Streamable”)
-
Arquitectura general de MCP
¿Qué es un MCP Server?
-
Un MCP Server es un programa que expone capacidades específicas a apps de IA mediante las interfaces del protocolo.
-
Su función principal: proveer contexto y acciones a un MCP client.
-
Ejemplos de servidores:
-
Servidor de filesystem (acceso a documentos)
-
Servidor de base de datos (consultas de datos)
-
Servidor de GitHub (repos, issues, PRs)
-
Servidor de Slack (mensajes, canales)
-
Servidor de calendario (eventos, disponibilidad)
-
-
Puede ser local (p. ej. filesystem via STDIO) o remoto (p. ej. Sentry via HTTP).
Primitivas de un MCP Server
-
Un MCP server se construye alrededor de tres primitivas principales:
-
Tools (herramientas):
-
Funciones ejecutables que el modelo puede invocar
-
Pueden escribir en BD, llamar APIs, modificar archivos, etc.
-
-
Resources (recursos):
-
Fuentes de datos read-only para dar contexto
-
Archivos, registros de BD, respuestas de APIs
-
-
Prompts:
-
Plantillas de instrucciones reutilizables
-
Guían cómo usar tools y resources en un flujo concreto
-
-
-
Estas primitivas se descubren y consumen vía métodos como
*/list,*/getytools/call.
Tools: acciones que puede ejecutar el Server
-
Las tools permiten que el modelo ejecute acciones reales.
-
Cada tool define:
-
Nombre, descripción
-
Input schema y output schema usando JSON Schema
-
-
Métodos clave del protocolo:
-
tools/list– descubrir tools disponibles -
tools/call– ejecutar una tool concreta
-
-
Ejemplo típico (viaje):
-
searchFlights(origin, destination, date) -
createCalendarEvent(...) -
sendEmail(...)
-
-
Los clientes pueden exigir consentimiento del usuario antes de ejecutar ciertas tools (diálogos de aprobación, permisos, logs de actividad).
Resources
-
Los resources ofrecen acceso estructurado a datos para contexto.
-
Cada resource:
-
Tiene un URI único (ej.
file:///path/to/doc.md) -
Declara su MIME type
-
-
Dos tipos de discovery:
-
Direct resources: URIs fijos (
calendar://events/2024) -
Resource templates: URIs con parámetros (
travel://activities/{city}/{category})
-
-
Métodos:
resources/list,resources/templates/list,resources/read,resources/subscribe.
Prompts
-
Los prompts son plantillas de interacción que combinan tools y resources en flujos reutilizables (ej. “Planear un viaje” o “Resumir reuniones”).
-
Ayudan a estandarizar cómo el modelo utiliza las capacidades del servidor.
¿Qué esperan los Servers de los Clients?
-
Además de usar tools/resources/prompts, el client también expone primitivas al server:
-
Sampling:
-
El server puede pedirle al client que llame al LLM del host (
sampling/complete), sin acoplarse a un modelo concreto.
-
-
Roots:
-
El client indica directorios/áreas de trabajo donde el server debe operar (p. ej.
file:///Users/agent/travel-planning).
-
-
Elicitation:
-
El server puede solicitar información adicional al usuario en mitad de un flujo.
-
-
-
Esto permite servers más inteligentes sin reimplementar LLMs, UI o seguridad.
Flujo completo: de la app de IA al MCP Server
-
Inicialización y negociación:
-
Host crea un MCP client y se conecta al server.
-
Se negocian capacidades via el protocolo de data layer (lifecycle).
-
-
Descubrimiento:
-
El client llama
tools/list,resources/list,prompts/listpara saber qué ofrece el server.
-
-
Interacción con el usuario:
-
El usuario pide algo (ej. “Planéame un viaje a Barcelona”).
-
El modelo decide qué tools/resources usar.
-
-
Ejecución:
-
El client llama
tools/callyresources/read. -
El server puede usar sampling para pedir al LLM que compare opciones o elicitation para confirmar detalles con el usuario.
-
-
Respuesta y actualizaciones:
-
El server devuelve resultados estructurados.
-
Opcionalmente envía notificaciones cuando cambian tools o resources (ej. nuevas capacidades).
-
Construyendo tu propio MCP Server
-
Componentes del ecosistema MCP:
-
MCP Specification – requisitos formales para clients y servers.
-
MCP SDKs – librerías por lenguaje que implementan el protocolo.
-
Herramientas de desarrollo (p. ej. MCP Inspector).
-
Reference servers – implementaciones de ejemplo.
-
-
Pasos típicos:
-
Elegir el lenguaje y SDK.
-
Decidir el transport (stdio para local, HTTP para remoto).
-
Diseñar las tools, resources y prompts que expondrá tu server.
-
Implementar los métodos del data layer (lifecycle,
*/list,tools/call, etc.). -
Probarlo con un MCP host (Claude Desktop, IDE, etc.) usando las herramientas de inspección.
-
Monos a la obra
Generando Facturas de la SAT desde ChatGPT utilizando
MCP + n8n
