Eyes on the APIs
How a Gatsby and API-driven architecture can make faster, more secure, and more scalable web projects.
What we'll talk about
- Why APIs?
-
What is GraphQL?
- Building an app with GraphQL + SS CMS
- Building a website with SS CMS + Gatsby
Why APIs?
Clients are like, really into their data.
A content API separates the consumption of content from the delivery of content.
Tooling


THE SWARM
THE HEARD-OF-ITS
THE CV ITEMS
THE IMPACTFUL
The Fanboy Funnel
Laurie Voss
Founder, NPM

- Serves 11 million developers
- 6 billion package downloads per week
- 97% of app code is sourced from NPM
- Creates more data than it provides



JAMES
Trinidad and Tobago

1996: Trinidad gets the internet

Simplicity is a core value of web technology.

Technological gravity
HTML 3.0
HTML 5
Framesets
Shockwave
Applets
Flash
Web 2.0
jQuery UI
React/Vue
2005
1995
2015
Today
"OMG I can do a website using just HTML and CSS"
Gatsby is a static site generator for React.








Server rendered static assets, hydrated to a SPA.
Compiled to static
- Performance
- Security
- Low cost
Then it's dynamic
- User-generated content
- Real time data
- Authenticated / private content
- Declarative behaviours
The best of both worlds...
"What parts of the app need to be dynamic?"

Bring your own data

Guiding principles
1. The App Tuple
HTML
CSS
DATA
+
+
APP
=
(behaviour)
- HTML (Structure)
- CSS (Style)
- Data (Contents)

HTML
DATA
DATA
DATA
CSS
2. The source of your data is just an organisational detail.

3. It's done when you start.
Build
"The right thing is the easy thing."
-
Code splitting
-
Background pre-fetching
-
Image optimisation
-
Lazy loading
Performance
"It's yours to stuff up."
- 100% score on Lighthouse / webpagetest.org
- Service worker
Gatsby OOTB
4. Awesome dev experience
- Just React, GraphQL and your favourite CSS library
- Never worry about builds. Abstracted away.
- Less than 5% of Gatsby projects ever touch the build
5. Invest in the community
Gatsby ❤️ contributors
- Any commit gets free swag.
- Any five commits gets premium swag
- Buy swag at cost. Worldwide shipping free.
- Docs are streamlined to onboard first-time contributors
- Over 1,300 plugins
- Relatively active Discord chat room (no Slack)
What's it like to use Gatsby?
$ gatsby new my-project
cd my-project
gatsby develop<gatsby-starter-default>
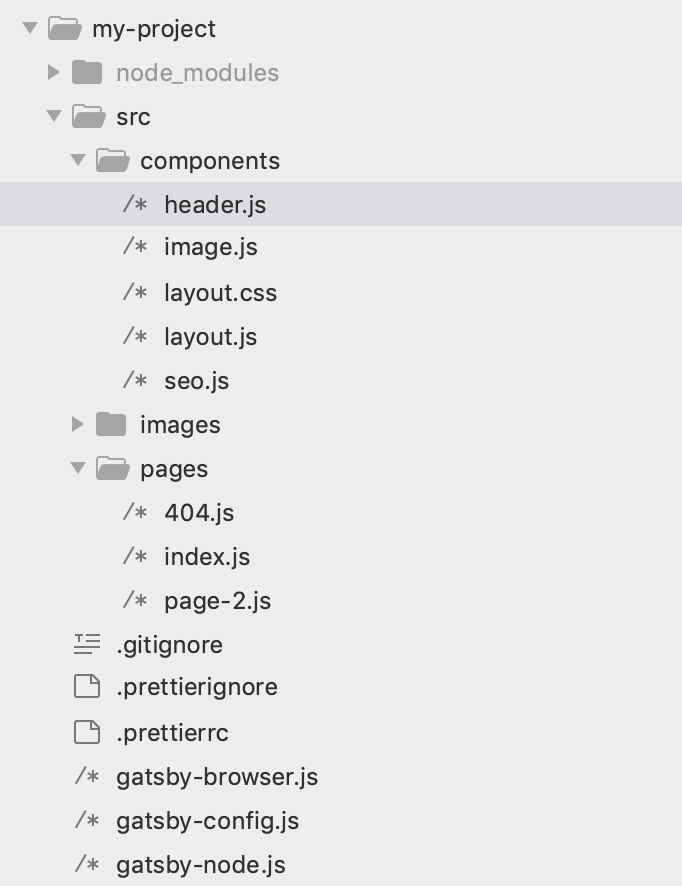

http://localhost:8000

http://localhost:8000/__graphql
Adding data sources
$ yarn add gatsby-source-rss-feed {
resolve: `gatsby-source-rss-feed`,
options: {
url: `https://silverstripe.org/blog/rss`,
name: `SilverStripeBlog`
}
}
$ gatsby develop





Creating pages


What does this mean for Silverstripe?
docs.silverstripe.org
silverstripe/silverstripe-gatsby
Gatsby source plugin that sources from a site with silverstripe-gatsby installed
gatsby-source-silverstripe
Silverstripe CMS module that exposes all your DataObjects to Gatsby
silverstripe-gatsby-helpers
Lightweight npm package that provides utility functions for working with the Silverstripe CMS source, such as `buildSiteTree()`, `useMenu(1)`



Things to consider
- How do we handle draft content?
- Long build times
- Content blocks
- Form submissions
- CMS Netlify module for user instantiated builds
Also...
Doesn't
silverstripe-graphql SUCK?
YUP.
It really sucks.
How we're fixing GraphQL


The A&D Team
Gets paid to hack on shit.
Yup, sounds like hacking.
yawn.. more bullshit. We get it, you're a hack.
But we're fixing GraphQL!
How we got here
-
GraphQL was the chosen API layer for asset-admin in CMS v4
-
Early adopters, but proven right
-
silverstripe-graphql module tagged stable in CMS 4.0 release
-
Major version releases required
It's slow AF.
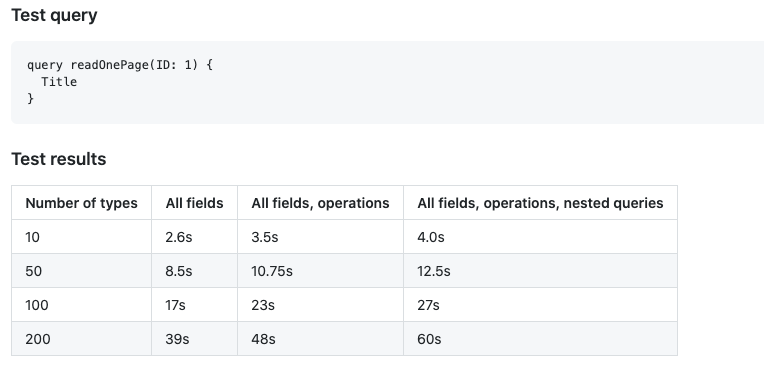
GraphQHell
A problem we Graph-Knew-Well
-
Discussions about making the schema cacheable date back nearly two years.
-
Complex problem to solve: Lots of dynamic code
-
Needs of our bespoke teams and partner agencies drive our product roadmap
How we fixed it
Attempt #1: serialize() into submission

It finally serialize()'ed!
unserialize() => 200ms


The problem
The solution
Attempt #2: Code generation
-
Concession: For GraphQL to scale, a build step is inevitable
-
Rewrote scaffolding APIs to generate PHP code
-
~1.2 million layers of abstraction
-
And... it worked!
-
But were performance gains worth the DX penalty?
The problem
The solution


March 2020: Major news breaks.
graphql-php v14.0 released
graphql-php 14.0
-
Small print mentions new lazy type loading API
-
More small print mentions type language support (and caching!)
-
Type language = DX win
-
Type lazy loading = Performance win.
Right?

But we got there.
GraphQL v4 in summary
-
Uses code generation to persist an executable schema to the filesystem
-
Requires a build step
-
Almost everything can be done in YAML
-
Type/Query creators and scaffolders just glorified arrays
-
Scaffolders are now “models” that populate those arrays
-
GraphQL v4 in summary
-
All you’re doing is composing value objects that render themselves in PHP code.
-
Manager is now Schema, and query handling has been isolated out.
-
Plugins distribute single-concern, reusable code
-
Confirmed: We don’t have a schema problem, we have a resolver problem.
The resolver problem
-
Resolvers must be static. (99% of resolvers already are)
-
To reduce boilerplate, a resolver discovery pattern will find resolvers implicitly
-
Resolvers can take context (e.g. for generic DataObject resolvers)
-
($context) => ($obj, $args) => $result
-
-
Classes will define many resolver methods, organised as needed
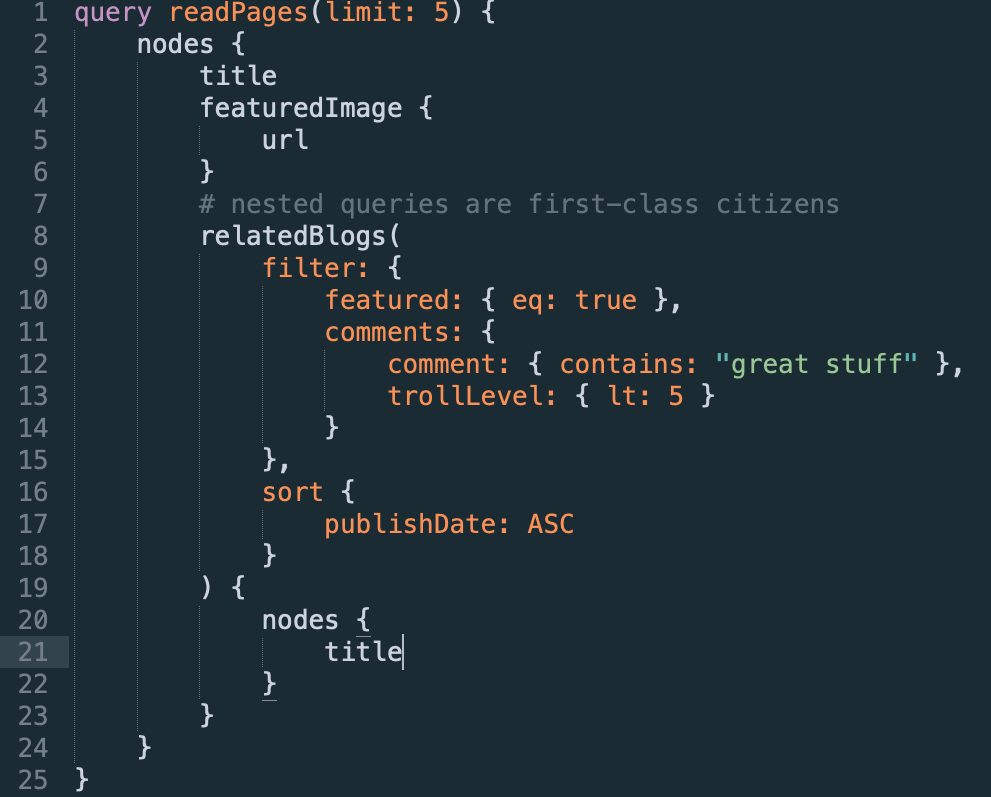
The Plugin API
-
Just about everything in the Schema accepts plugins:
-
Updates can be a one-type schema-wide update or a very surgical update to one field
-
Example plugins: Versioned, Sort, Filter, Paginate, PermissionCheck

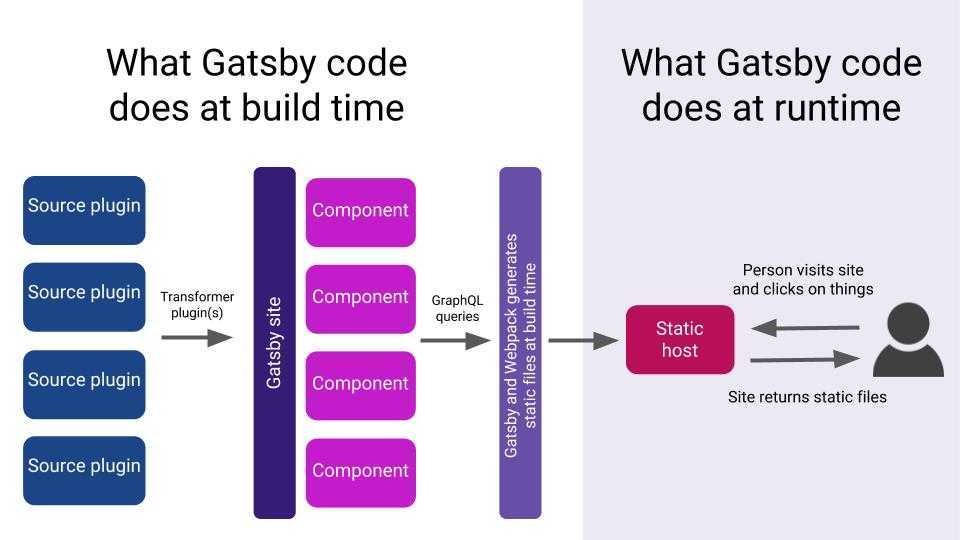
But is it faster?!

Average response time: ~70ms
Our graph-grew-well.
Live code demo.
What the hell. It's not like 2020 can get much worse.
What's next?
-
Backward compat with core modules:
-
Asset-admin
-
Versioned
-
Elemental
-
Versioned-admin / Snapshots
-
-
Refine the DX and devops around the new schema build:
-
Build performance
-
Autobuilding?
-
-
N+1 optimisation, query caching
-
Real world usage
You can help
-
Why aren’t you building more API-driven sites?
-
What can Silverstripe Ltd do to help derisk this?
-
Try it on a small project, or a side project, and give us feeback