Cloud basics
High Availability
Based on AWS, Azure and IBM ressources
Abderrahmane Smimite
"Everything fails, all the time."
Werner Vogels, CTO, amazon.com
My basic
ten
steps
1 - Business drives HA requirements
Availability is usually a part of the SLA (Service Level Agreement)
the 9s: level of availability
| Nines | percent of uptime | Max downtime/ year | eq. Max downtime/day |
|---|---|---|---|
| 1 | 90% | 36,5 days | 2,4 hrs |
| 2 | 99% | 3,65 days | 14 min |
| 3 | 99,9% | 8,76 hrs | 86 sec |
| 4 | 99,99% | 52,6 min | 8,6 sec |
| 5 | 99,999% | 5,25 min | 0,86 sec |
simple calculator: https://uptime.is
2- Define your Objectives and ressources
Recovery Time Objective (RTO)
Recovery Point Objective (RPO)
How much money/time can you invest to meet these objectives
How quickly must the system recover?
How much data can you afford to lose?
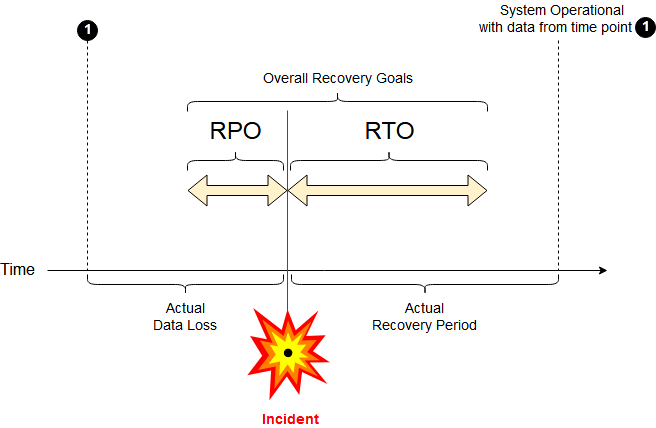
Source: wikipedia
3 - Keep-it-simple strategy
Complex systems:
- make it harder for people to understand, manage and troubleshoot
- increase the risk of failures
- could make the fault recovery more difficult and in some cases more risky
- ==> Less is more
4 - Understand your application and environment
Consider deployment constraints during the first design stages (DevOps)
Fault tolerance
Built-in Redundancy (self-healing) of an application component

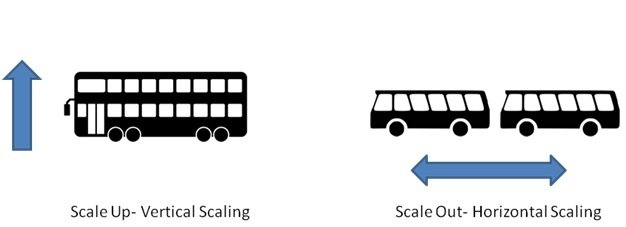
Scalability
Capability to accommodate to growth without changing application design
Recoverability
Process, policies and procedures related to restoring service after catastrophic event
"Assume everything fails, and design backwards"
Implement redundancy when possible in order to prevent single failure from bringing down the entire system
Golden rule:
5 - Design your system while checking the state of the art
Understand design patterns, clustering, Replication, containerization/ virtualization, etc.
Understand provider's services and features

Note: maybe you need multi-cloud, maybe you don't
6 - Know when to use managed services
7 - The system will fail and you will miss someting

(there's a letter missing btw)
Build resilience instead of strength
Golden rule:
8 - Keep up with team training and technical updates
AWS Well-Architected Framework
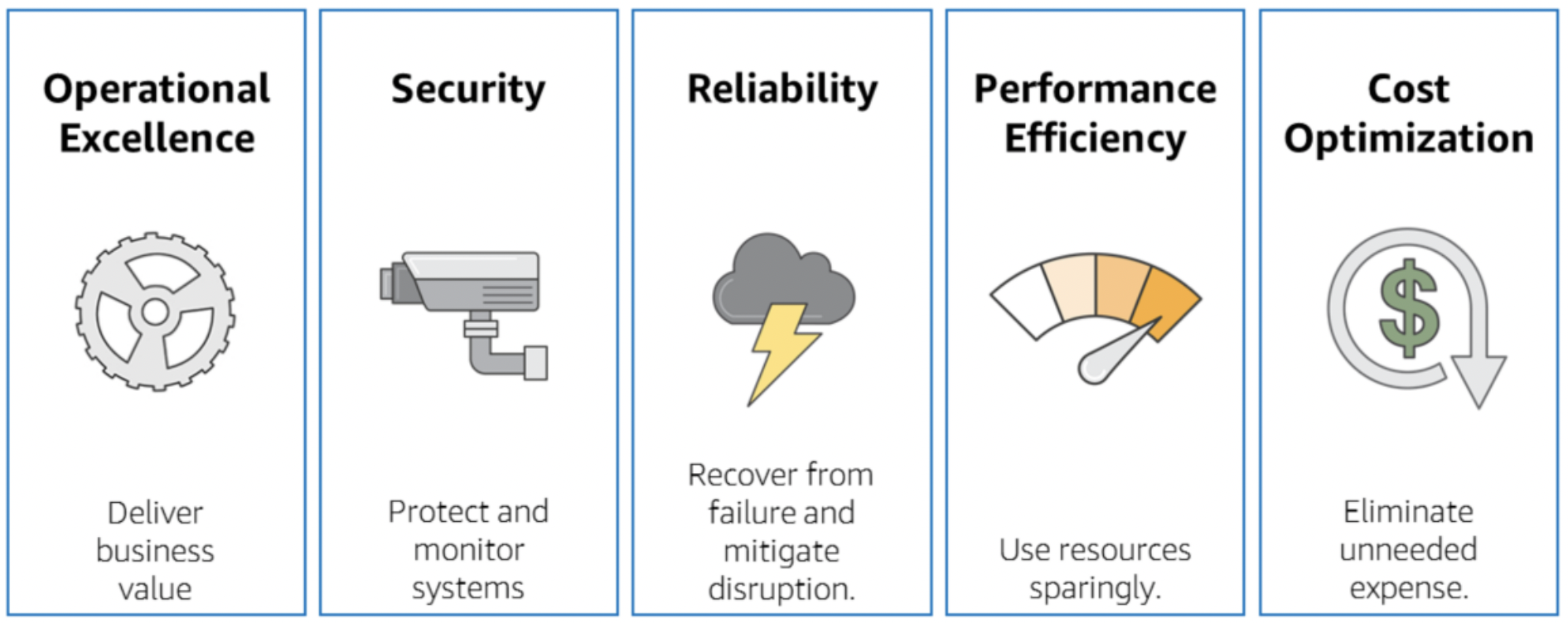
(c) 2018, Amazon Web Services
9 - Define your "just-enough" process

10 - Challenge your design (and everything else)
Kubernetes
Bonus:

Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications.

Kubernetes is
an orchestrator
library
dependencies
App
library
Containerized app
App 1
App 2
App N
Registry
Master node
Store
Dashboard/CLIs/APIs
Scheduler
Controller
Worker node
Proxy
Kubelet
App 1
Worker node
Proxy
Kubelet
App 1
App 2
Docker
Kubernetes


Kubernetes Features
1 - Management of Pods
Worker node
App 1
App 2
App N
POD
POD
2 - Replication controller
and load balancer
Worker node
POD1
POD1
Worker node
POD1
3 - Storage management
Kubernetes Features
4 - Ressource monitoring and health checking
5 - Horizontal Auto Scaling
6 - Service discovery
Kubernetes Features
7 - Networking (container to container, pod to pod, pod to external)
8 - services
9 - Rolling deployment and rollback
10 - Logging
Kubernetes Features
+ 2 (personal) bonuses
11 - Good transition to Infrastructure as Code (IaC)
12 - makes micro services architecture "less" scary
Takeaways
- Everything fails
- Build resilience not strength
- Checkout the state of the art
- Checkout cloud providers services
- Keep it simple, keep improving