[Transfer Learning (A+B+C) in Fractional All-Convolutional Network :: Research]
Graduation Project Presentation
Abhishek Kumar 2013ecs07
Department Of Computer Science and Engg.
Shri Mata Vaishno Devi University
Acknowledgement
- My Mentor: Mr. Manoj Kumar and Mr. Rahul Vishwakarma
- Alexey Dosovitskiy(Department of Computer Science University of Freiburg) and Benjamin Graham(Dept of Statistics, University of Warwick) for their help
- My teachers at our college and Teammates at MateLabs
- My colleagues and all those who supported me
Abstract and Overview
- I have tried combining the idea of fractional max pooling and All Convolutional Neural Network to achieve state of the art accuracy on CIFAR10 dataset.
- Applied Transfer Learning to the above network, studied the concept of A+B+C model Achieved 93% accuracy on CIFAR10 dataset (almost state of art)
- Still working on the transfer learning hypothesis to make it better and efficient to implement
Outline
- Timeline of the project
- Intro to NN and CN
- Fractional Max Pooling
- Striving for simplicity, the ALL-CNN model
- Transfer Learning
- Scope of the project
- Conclusion
****I have covered each section of the article in detail in the file submitted.
Timeline Of the Project
December-January
Study and Understand the details of CNN and DL
March
Training the models with different sets of hyperparameters
February
Started applying the All CNN and Fractional Max Pooling Model
April
With the stored weights, applying it to the Transfer Learning application
April
Preparing the report and finalizing the results
Deep Learning and CNN Intro
Oh Yes, Deep Learning is here
Yes, A big Yes

Neural Network
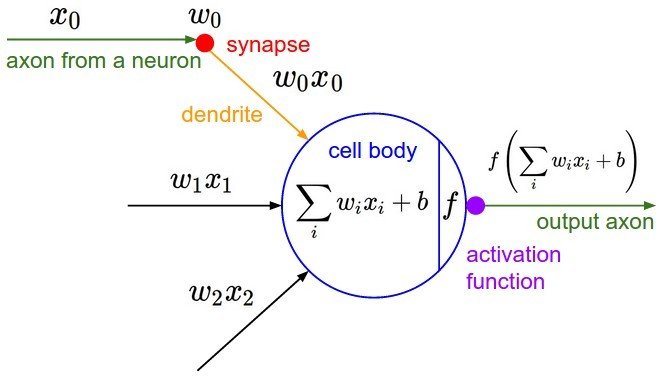
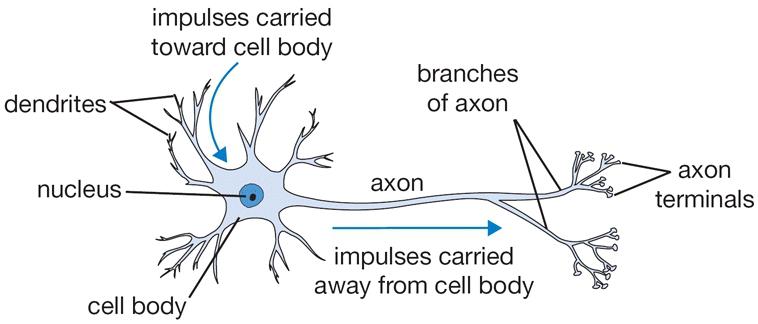
NN as a Brain analogy
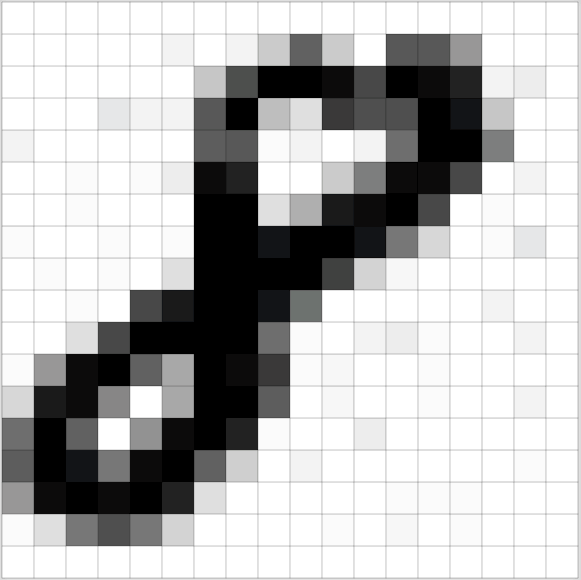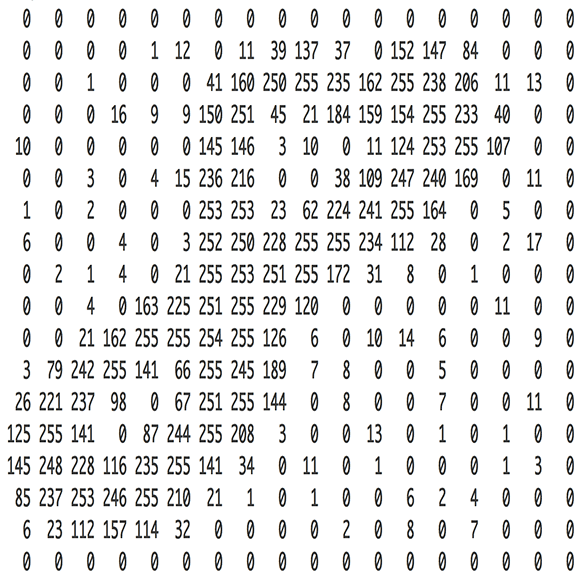
Image as an Array
Convolutional Neural Network
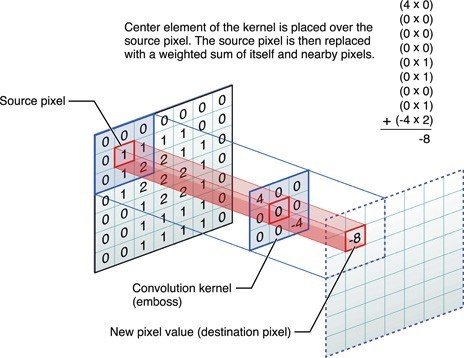
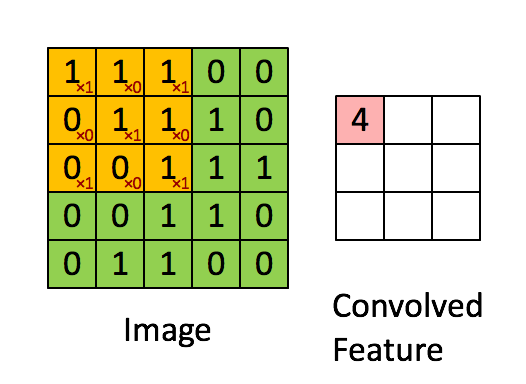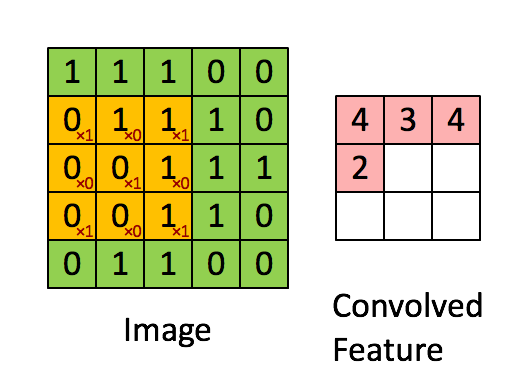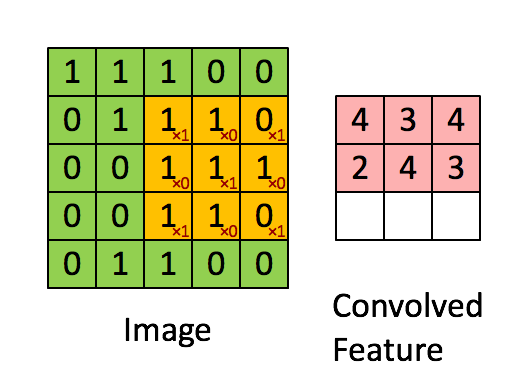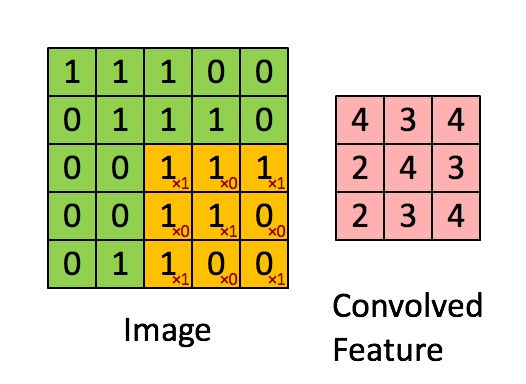
A brief idea of how a CNN works
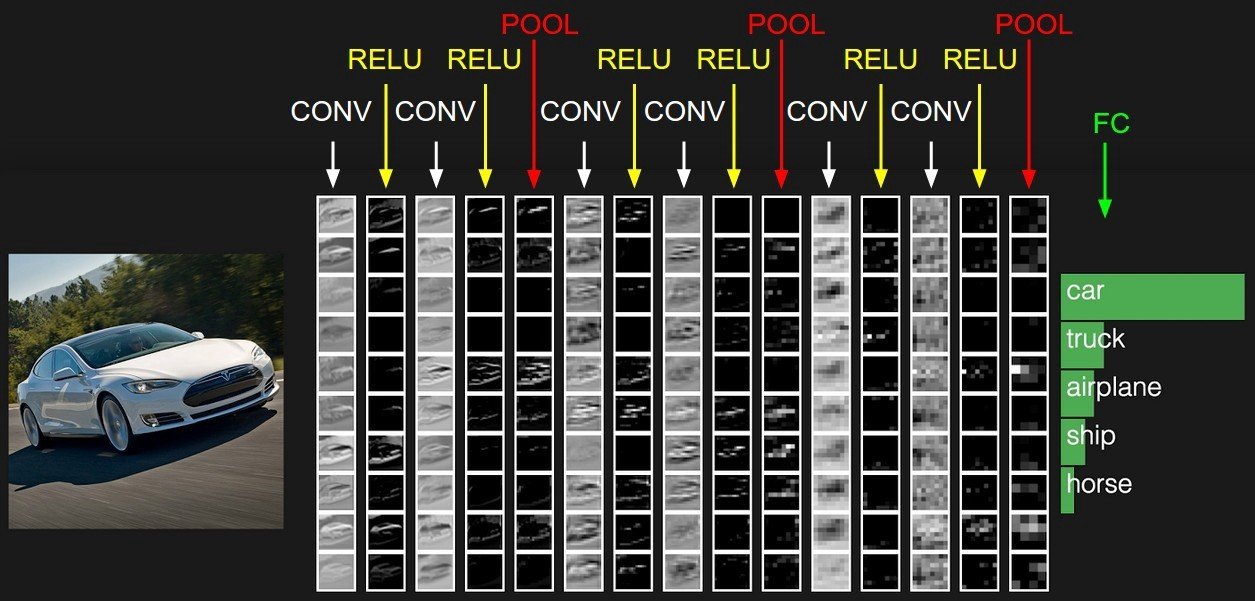
Text
A CNN model
Here are the components of a CNN model
- Convolution
- Non Linearity (in this example Relu)
- Pooling or Subsampling
- Classification
Parameter 1
Pooling Layer
Fractional Max Pooling
-
Advantages of MP2 is that it is Fast and Quickly reduces the size of the hidden layer also it encodes a degree of invariance with respect to translations and elastic distortions.
-
Issues with MP2 is that it has disjoint nature of pooling regions and since its size decreases rapidly, stacks of back-to-back CNNs are needed to build deep networks.
-
The advantage of Fractional Max Pooling is that it reduces the spatial size of the image by a factor of α, where α ∈ (1, 2) also it introduces randomness in terms of choice of pooling region.
Pooling Layers are to reduce the spatial dimensionality of the intermediate layers
Fractional Max Pooling
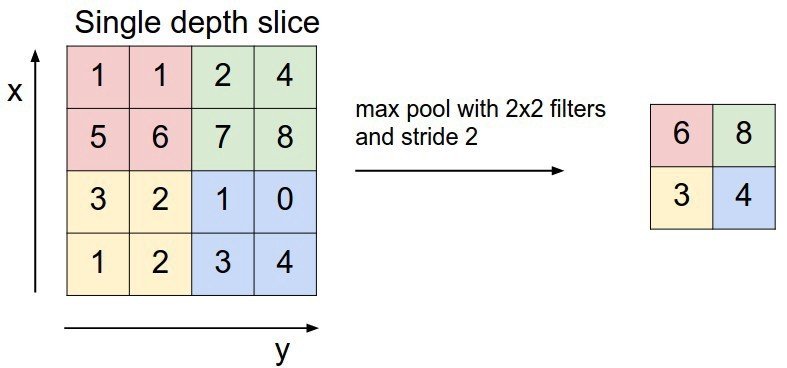
A visual demo of Max Pooling where we reduce the dimension while keeping the important feature in-tact
Fractional Max Pooling
-
The good performance in the Fractional Max-Pooling is achieved by a combination of using spatially-sparse CNN with fractional max-pooling and small filters (and network in
network ) which enable building a deep network even when the input image spatial size is small. - Hence in regular CNN network, simply replace regular max pooling with fractional max pooling does not necessarily give you a better performance.
Conclusion
Alternatively, A better approach
An another Convolution layer instead of Pooling
All CNN Model
- Remove all the Pooling Layers
- Remove the fully connected Layer

Let's check this out.
All CNN Model
Convolution instead of Pooling?
Global average pooling instead of FC?
Results
93% accuracy on CIFAR10 without extensive Data Augmentation
Almost state of the art**
Transfer Learning
The magic begins...
CNN visualization
Layer 1 and 2 (the initial ones)

CNN visualization
Layer 3 (the intermediate ones)

CNN visualization
Layer 4 and 5 (the last ones)

Now comes transfer of knowledge/features
Introduction to Inception and my Hypothesis
Inception: The lifeline of Google (model A, the general features)
A model with specific features (model B, the intermediate)
Model C, very specific to our Dataset
A small intro to inception
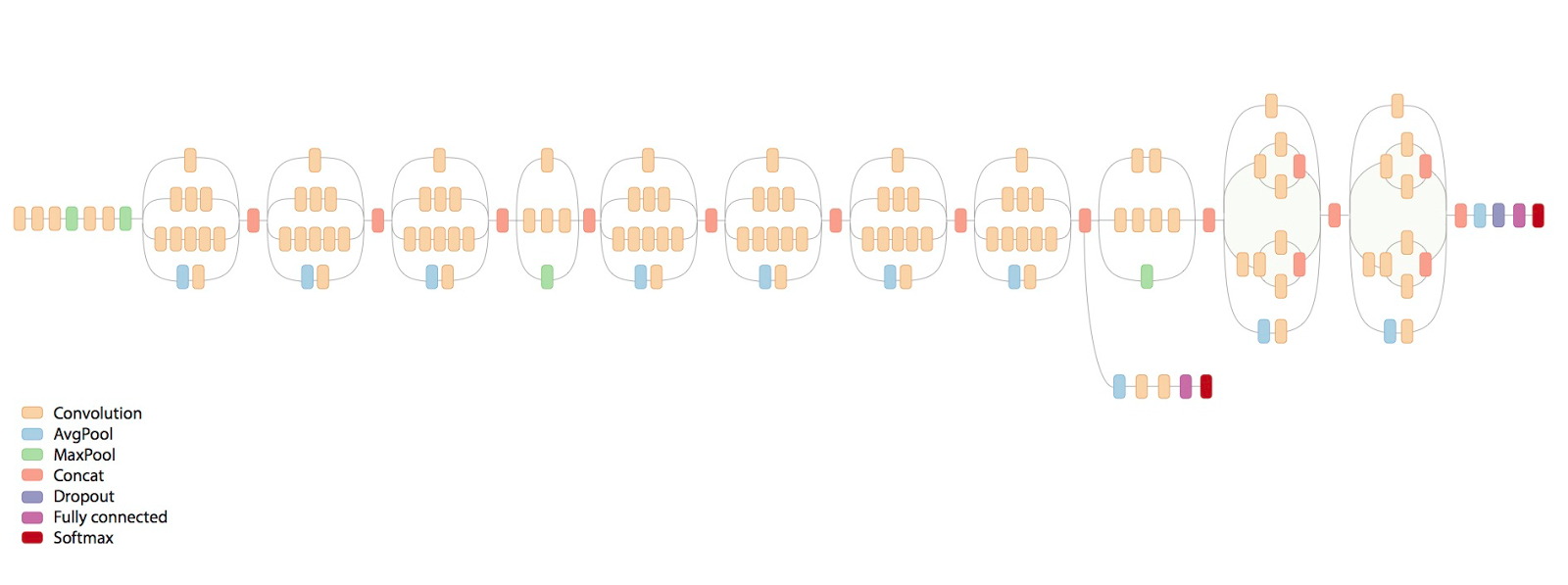
- A 152 layer network
- Trained on imagenet (1000 classes)
- Conventional CNN architecture with 1*1 window size
Results of A+B

Results of A+B
-
B3B – the first 3 layers are copied from baseB and frozen. The remaining five higher layers are initialized randomly.
-
A3B – the first 3 layers are copied from baseA and frozen. The remaining five layers are initialized randomly
-
B3B+, like B3B but the first three layers are subsequently fine-tuned during training.
-
A3B+, like A3B but the first three layers are subsequently fine-tuned during training.
Architecture
Results of A+B+C
- For a small network due to dependency of the layers, it performs very poorly
- Consider VGG16, the model size is reduced by almost 300% with only 2-3% compromise in accuracy
- Fine tunning is 2-10 times as faster as normal transfer Learning
Results of A+B+C
Still working to get some substantial results...
Future work and Scope
- Industries and Research
- The time reduction in training and fine tuning(especially when large dataset is there)
- Almost negligible compromise on accuracy
Yes, this is a revolution, the next big thing maybe

Thank you and Have a Happy Day
