Producer/Consumer World
Alexander Bykovsky
abykovsky@griddynamics.com
Producer/Consumer
naive implementation
Simple Producer/Consumer
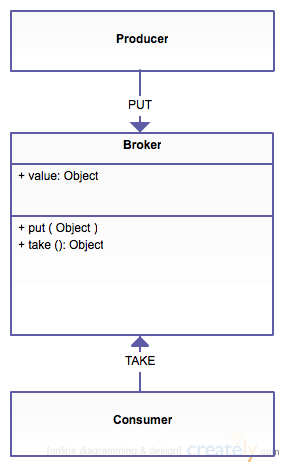
Thread 1
Thread 2
public class Broker<V> {
private V value;
public void put(V value) throws InterruptedException {
synchronized (this) {
while (this.value != null) {
this.wait();
}
this.value = value;
this.notify();
}
}
public V take() throws InterruptedException {
V result;
synchronized (this) {
while (value == null) {
this.wait();
}
result = value;
value = null;
this.notify();
}
return result;
}
}Synchronized Broker
Method types
1. Wait-free. A method is wait-free if it guarantees that every call finishes its execution in a finite number of steps.
2. Lock-free algorithm. A method is lock-free if it guarantees that infinitely often some method call fin- ishes in a finite number of steps.
3. Obstruction-free. A method is obstruction-free if, from any point after which it executes in isolation, it finishes in a finite number of steps.
Properties
1. One element message queue. Elements size = 1
2. Blocking (wait/notify in while spurious wakeup prevention loop)
3. Lock type: Intrinsic lock
4. Main problem: multiple producer/consumer
Simple P/C. Read/Write lock
3. Lock type: Intrinsic lock. Read/Write lock. (locking free read)
Simple P/C. Reentrant Lock
3. Lock type: Reentrant Lock
Simple P/C. ReentrantReadWriteLock
3. Lock type: Reentrant Lock. Read/Write lock. (locking free read)
Simple Producer/Consumer. CAS
public class CasBroker<V> {
private volatile boolean stop = false;
private AtomicReference<V> value = new AtomicReference<>();
public V take() throws InterruptedException {
V result;
do {
if(stop) throw new InterruptedException();
result = this.value.get();
} while (result == null || !value.compareAndSet(result, null));
return result;
}
public void put(V value) throws InterruptedException {
do {
if(stop) throw new InterruptedException();
} while (!this.value.compareAndSet(null, value));
}
public void stop() {
this.stop = true;
}
}
Properties
1. One element message queue. Elements size = 1.
2. Blocking using busy spin.
3. Lock type: CAS.
4. Main problem: multiple producer/consumer.
Simple Producer/Consumer. Exchanger
public class ExchangerBroker<V> {
private Exchanger<V> exchanger = new Exchanger<>();
public V take() throws InterruptedException {
return exchanger.exchange(null);
}
public void put(V value) throws InterruptedException {
exchanger.exchange(value);
}
}1. Lock type: CAS. Elimination arena
2. Only one producer/consumer as well (for producer/consumer problem)
3. False sharing prevention. @sun.misc.Contended
4. GC-less (uses pre-allocation)
Producer/Consumer
queue implementation
Queue Producer/Consumer
Thread 1
Thread 2

public class ABQBroker<V> {
private BlockingQueue<V> queue;
public void ABQBroker(int capacity) {
queue = new ArrayBlockingQueue<>(capacity);
}
public void put(V value) throws InterruptedException {
queue.put(value);
}
public V take() throws InterruptedException {
return queue.take();
}
public List<V> take(int batchSize) {
List<V> events = new ArrayList<>(batchSize);
queue.drainTo(events, batchSize);
return events;
}
}queue = new LinkedBlockingQueue<>(capacity);BlockingQueue. ABQ. LinkedBlockingQueue.
Properties
1. N element message queue. Elements size = N
2. Not lock-free
3. Lock type: ReentrantLock.
ABQ - single lock for both put/take
LBQ - lock for put and separate lock for take
4. Main problem: overflowing, reliability, scalability
TransferQueue
1. TransferQueue is the same as BlockQueue but...
2. Method transfer has the same behavior as method put but block producer until consumer consume
3. Multiple producers don't block each other
public interface TransferQueue<E> extends BlockingQueue<E> {
void transfer(E e) throws InterruptedException;
}public class TransferQueueBroker<V> {
private TransferQueue<V> queue;
public void TransferQueueBroker(int capacity) {
queue = new LinkedTransferQueue<>();
}
public void put(V value) throws InterruptedException {
queue.transfer(value);
}
public V take() throws InterruptedException {
return queue.take();
}
public List<V> take(int batchSize) {
List<V> events = new ArrayList<>(batchSize);
queue.drainTo(events, batchSize);
return events;
}
}
TransferQueue. Example
LMAX Disruptor. Generally about it. Introducing
LMAX aims to be the fastest trading platform in the world.
Disruptor has "mechanical sympathy" for the hardware it's running on, and that's lock-free.
It's GC less.
It's optimized to work with single producer and multiple consumers.
LMAX Disruptor. Really fast
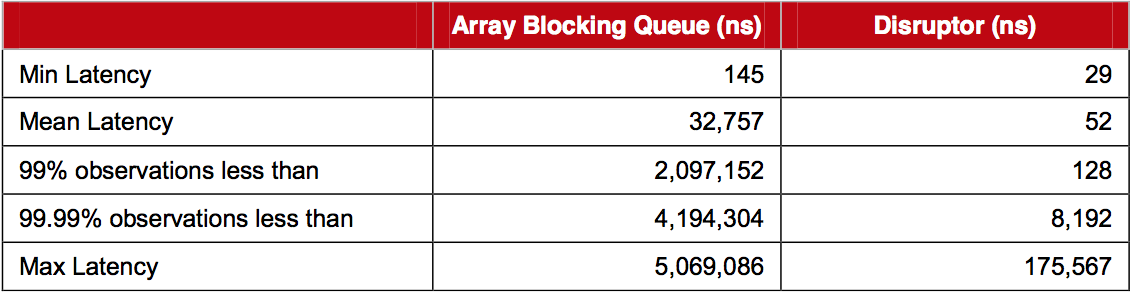
Mean latency per hop for the Disruptor comes out at 52 nanoseconds compared to 32,757 nanoseconds for ArrayBlockingQueue. Profiling shows the use of locks and signalling via a condition variable are the main cause of latency for the ArrayBlockingQueue.
LMAX Disruptor
Data structure: ring buffer
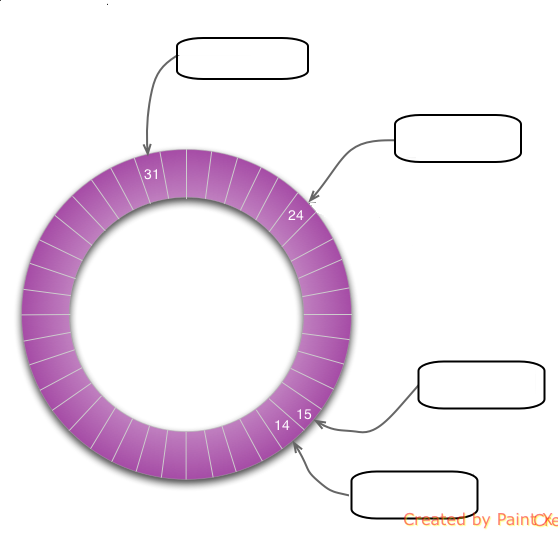
Producer
Producer
Consumer3
Consumer2
Consumer
Consumer3
Consumer2
Consumer1
Consumer3 will be in busy spin
Producer and Consumers don't block each other
LMAX Disruptor. Algorithm
1. Lets get Single Producer/Single Consumer queue
2. Modify wait strategy: condition wait -> busy spin
3. Elements size is a power of 2
4. Change Volatile -> lazySet to remove store/load barrier
5. Add padding or @Contended
6. Add elements pre-allocation and redundant write elimination
LMAX Disruptor. Simple approximation
final T[] elements = T[capacity];
volatile long head, tail;//should be optimized by @Contended
public void put(final T item) {
while (head - tail == elements.length) {/*spin until not full*/}
elements[tail & elements.length] = item;//could be optimized by pre-allocation
tail = tail + 1;//could be optimized by lazySet
}
public T take() {
while (head == tail) {/*spin until not empty*/}
final int index = head & elements.length;
final T item = elements[index];
elements[index] = null;//could be optimized by pre-allocation
head = head + 1;//could be optimized by lazySet
return item;
}LMAX Disruptor. SingleProducerSequencer
protected long nextValue = -1;
protected long cachedValue = -1;
protected volatile Sequence consumerSequence;
public long next(int n) {
if (n < 1) {
throw new IllegalArgumentException("n must be > 0");
}
long currentValue = this.currentValue;
long nextSequence = currentValue + n;
long wrapPoint = nextSequence - this.bufferSize;
long startValue = this.consumerPrevValue;
if (wrapPoint > startValue || startValue > currentValue) {
long minSequence;
while (wrapPoint > (minSequence = Math.min(consumerSequence.get(),
currentValue))) {
UNSAFE.park(false, 1L);
}
this.consumerPrevValue = minSequence;
}
this.currentValue = nextSequence;
return nextSequence;
}GC basics
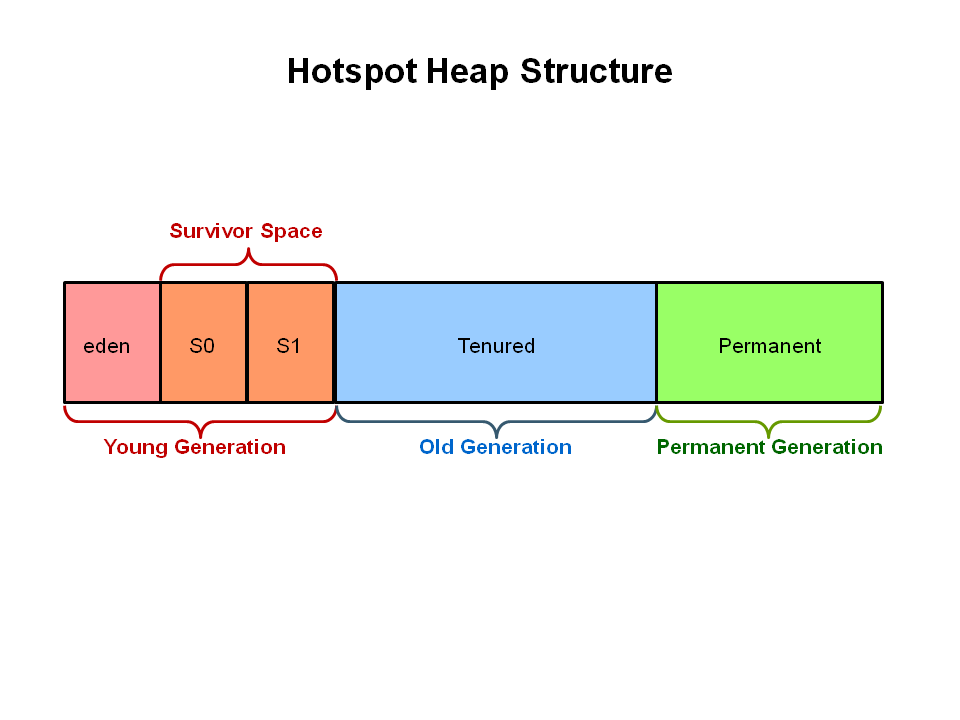
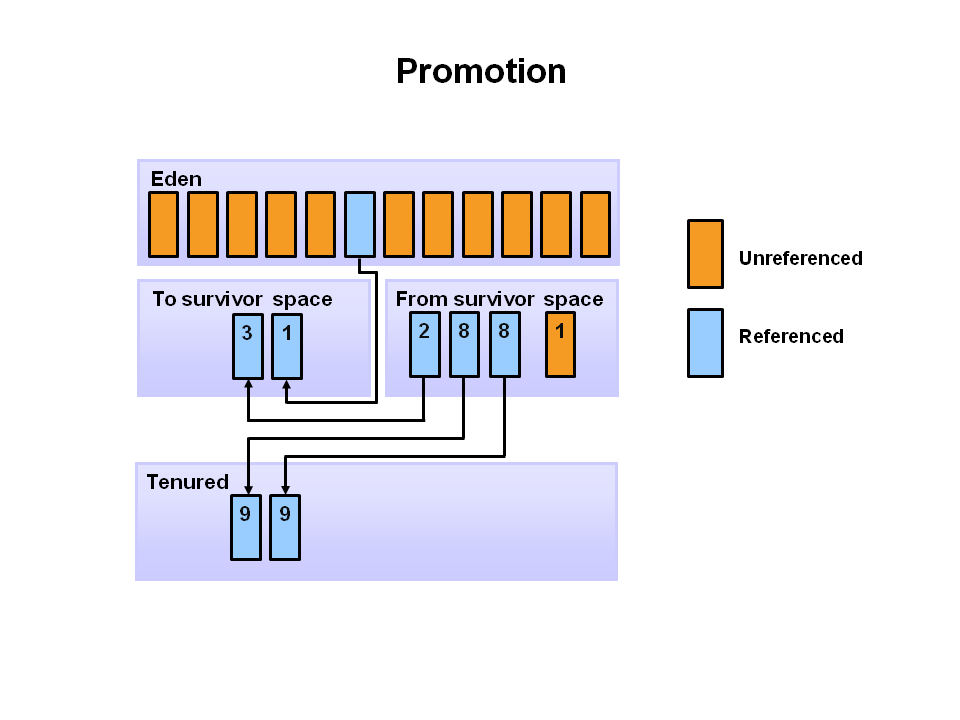
GC basics. Object movement
@Mutable
public class Data {
long longValue;
long dateTimeValue;
boolean boolValue;
char[] strValue;
public void mutate(long longValue, long dateTimeValue, boolean boolValue,
char[] strValue) {
...
}
}
Mutable and primitive types
Disruptor Technical Paper: Garbage collectors work at their best when objects are either very short-lived or effectively immortal.
Disruptor<Data> disruptor = new Disruptor<>(new MyEventFactory(),
BUFFER_SIZE, consumerExecutor,
ProducerType.SINGLE, new YieldingWaitStrategy());
RingBuffer<Data> ringBuffer = disruptor.getRingBuffer();
public class Producer<Container extends Mutable<Data>, Data> {
private final RingBuffer<Container> ringBuffer;
public Producer(RingBuffer<Container> ringBuffer){
this.ringBuffer = ringBuffer;
}
private final EventTranslatorOneArg<Container, Data> TRANSLATOR
= (event, sequence, data) -> {
event.setValue(data);
};
public void onData(Data data) {
ringBuffer.publishEvent(TRANSLATOR, data);
}
}
LMAX Disruptor. Producer
Properties
1. N element message queue. Elements size = N
2. Blocking
3. Lock-free. Why is it not wait-free? We've got busy spin in 1xN and CAS in NxN mode.
4. GC-less (uses pre-allocation)
5. Main problem: optimized for one producer
Producer/Consumer
queue scaling
1. Lets check how different queues scale
2. Lets change producer/consumer count equally
3. We'll set enough queue capacity and monitor queue to not allow queue to be empty or full all the time.
Question: how does synchronized (intrinsic lock) scale?
Queue scaling
ABQ performance
Throughput
producer/consumer count
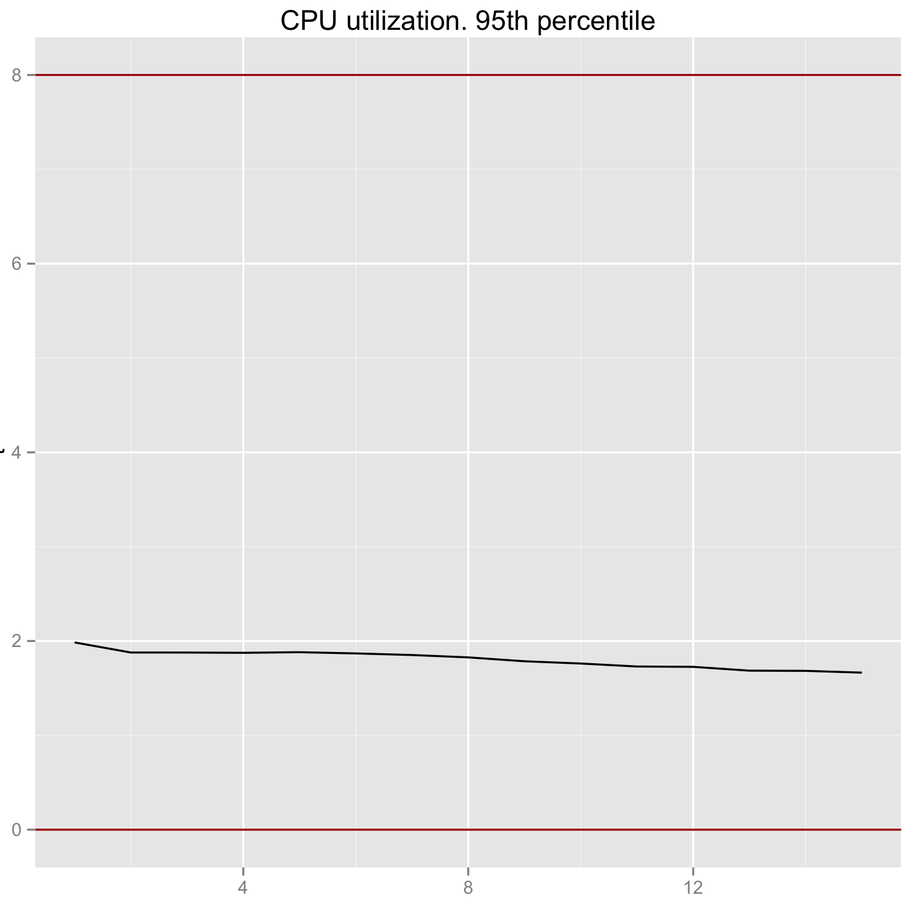
CPU Load
producer/consumer count
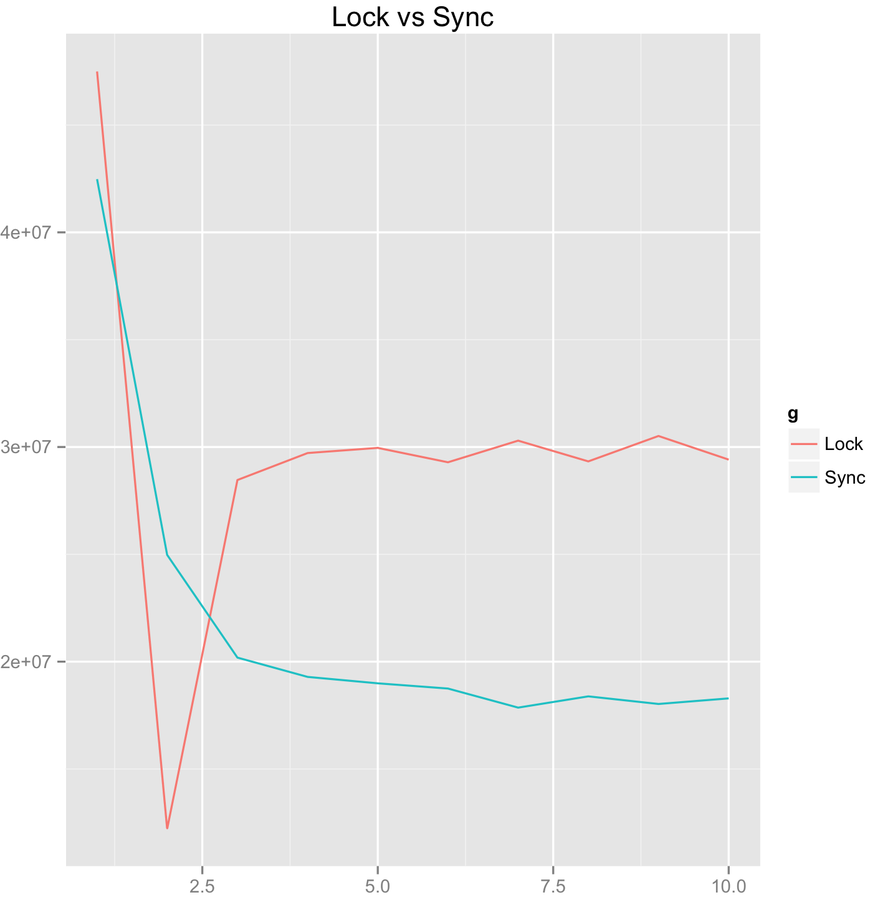
ReentrantLock vs Synchronized
Throughput
threads count
CPU Load
threads count
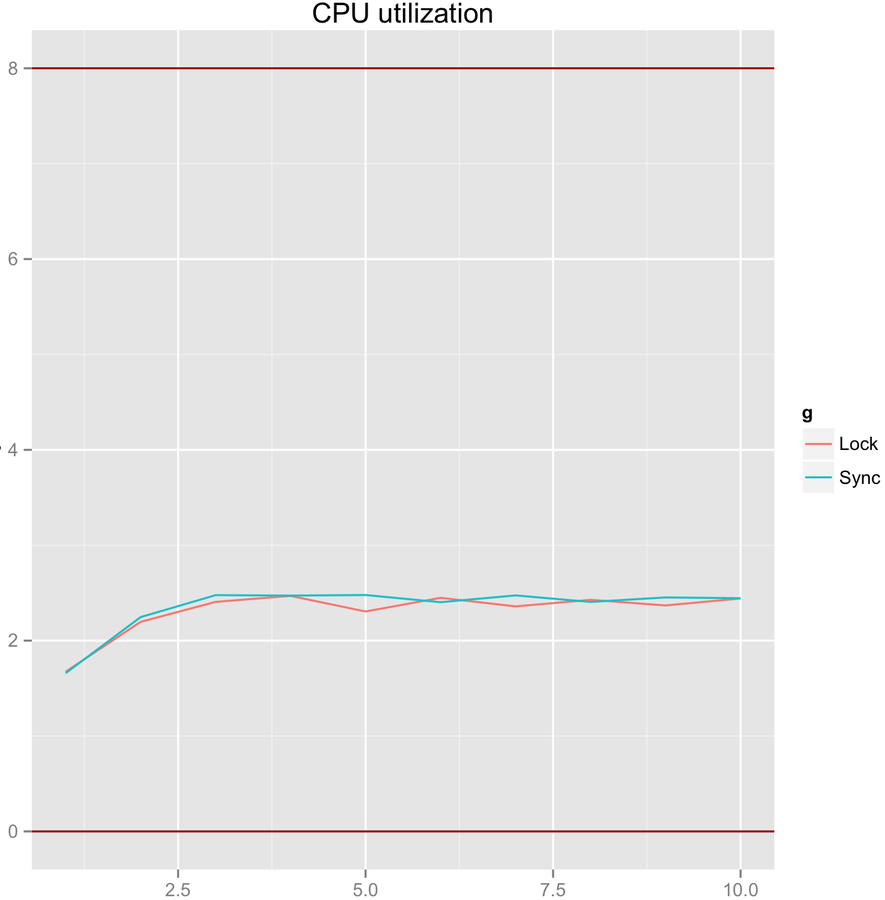
The Cost of Locks
The focus of this experiment is to call a function which increments a 64-bit counter in a loop 500 million times. This can be executed by a single thread on a 2.4Ghz Intel Westmere EP in just 300ms if written in Java.

producer/consumer count
Throughput
producer/consumer count
CPU Load
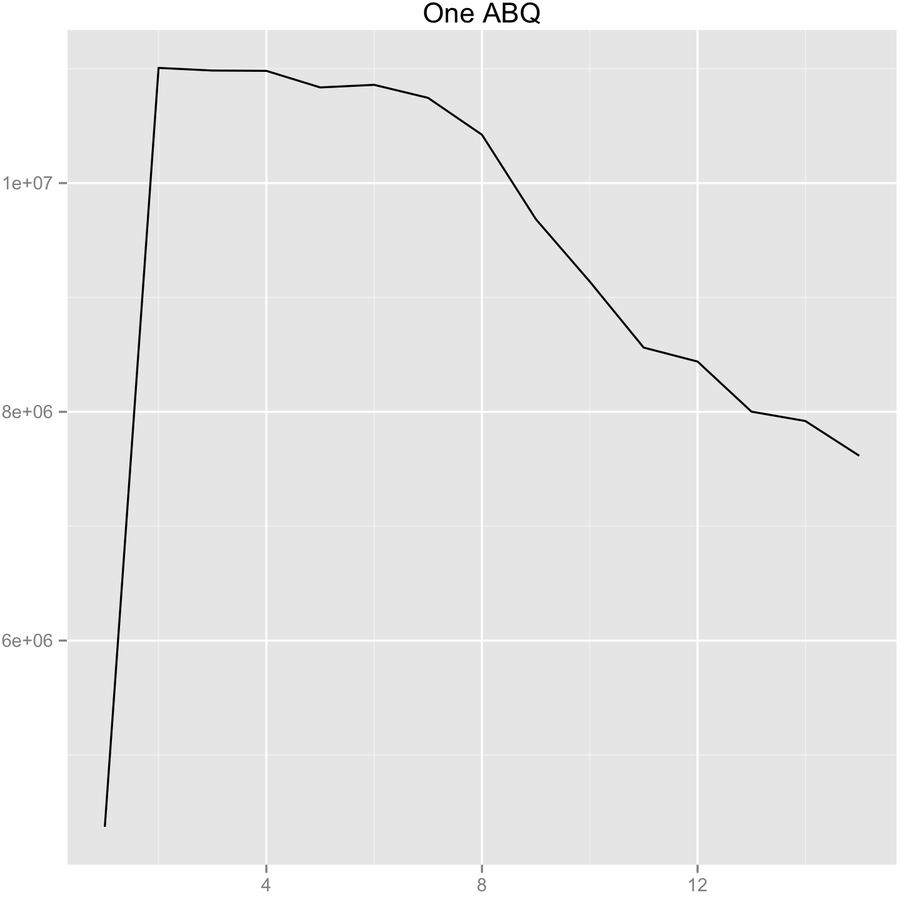
Max CPU utilization ABQ performance. Three ABQ
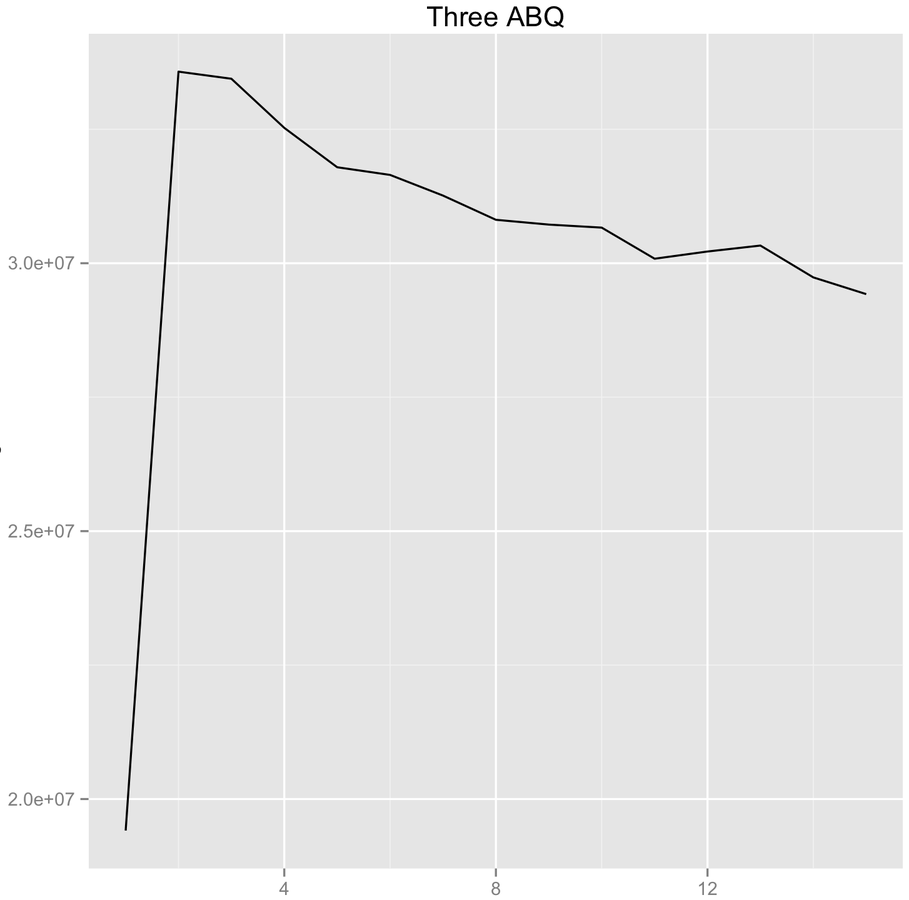
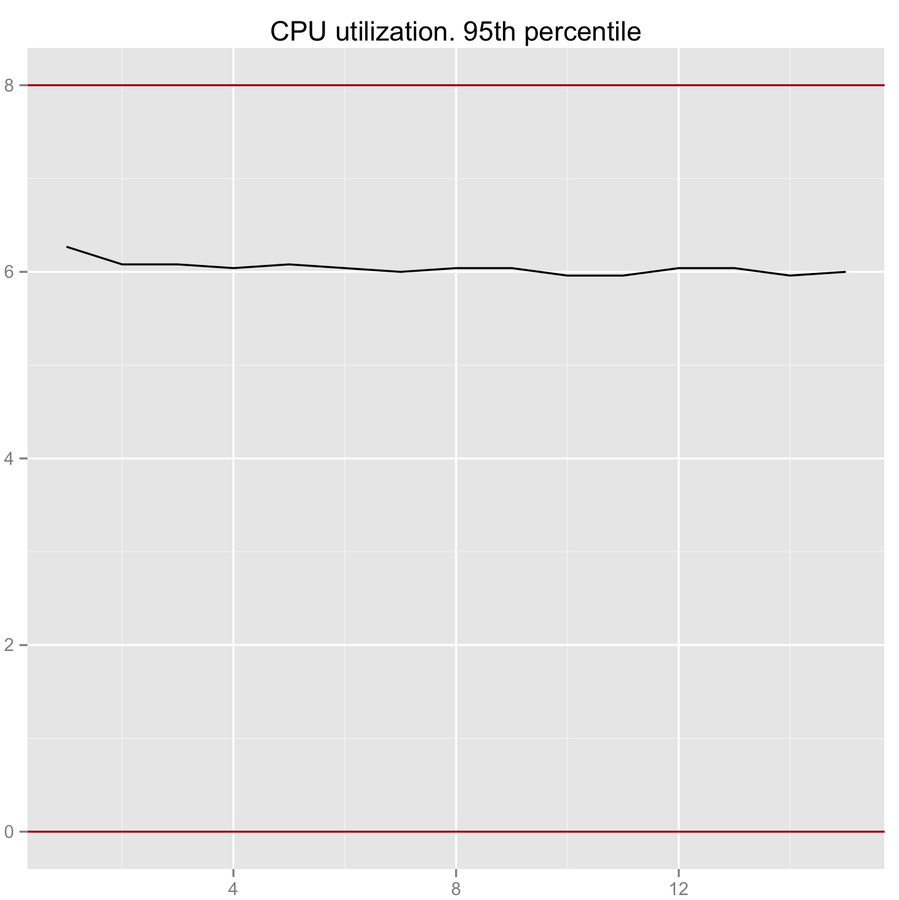
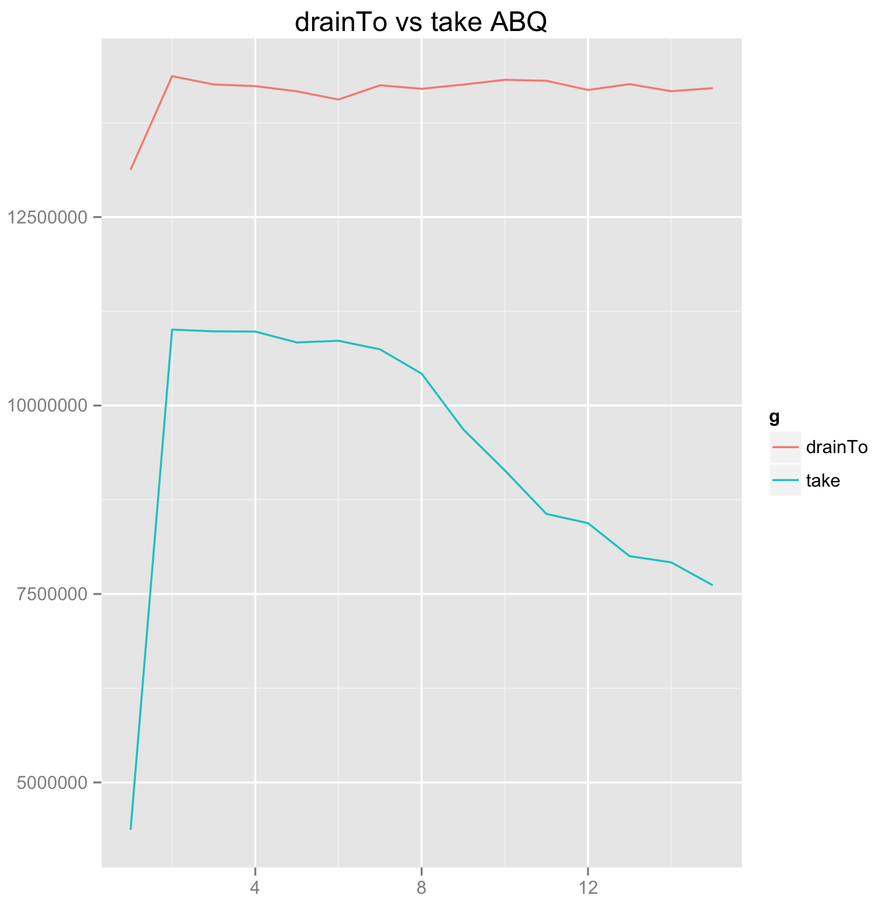
drainTo/take ABQ
Throughput
producer/consumer count
producer/consumer count
Throughput
producer/consumer count
CPU Load
LMAX Disruptor performance
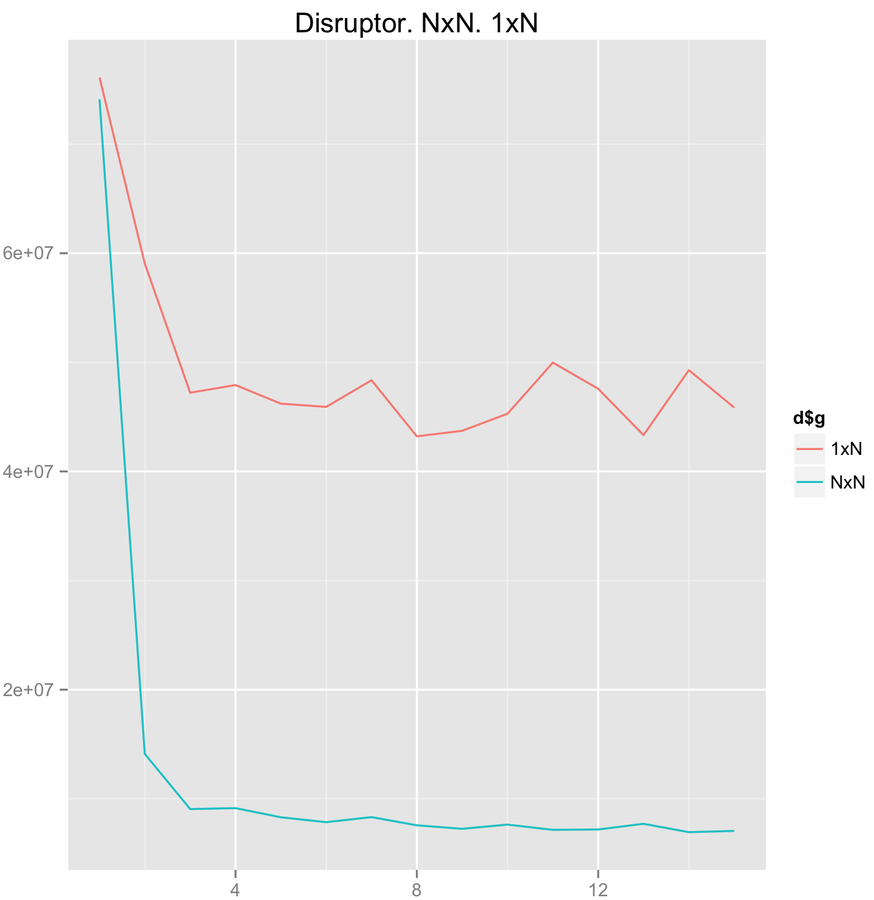
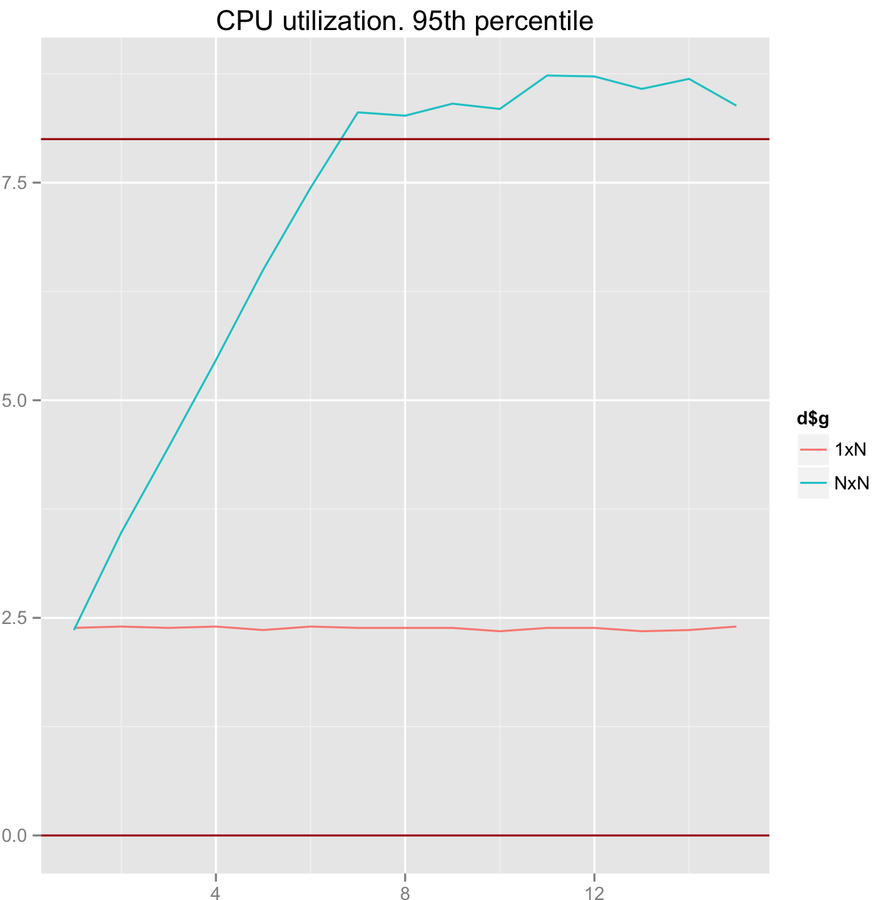
CAS scalability
1. CAS is more cheaper lock than synchronized or ReentrantLock.
2. On the other hand In high load environment CAS implies only more contention and CPU utilization.
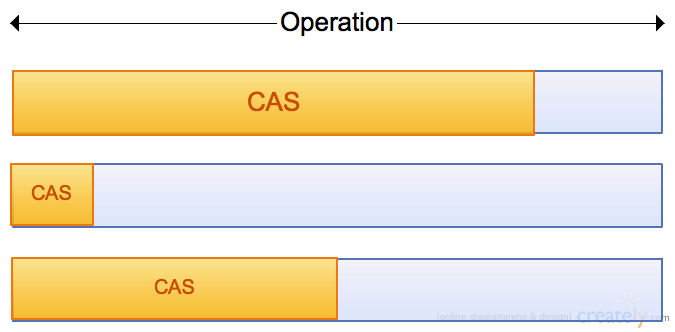
High contention
Small ratio
Optimal ratio
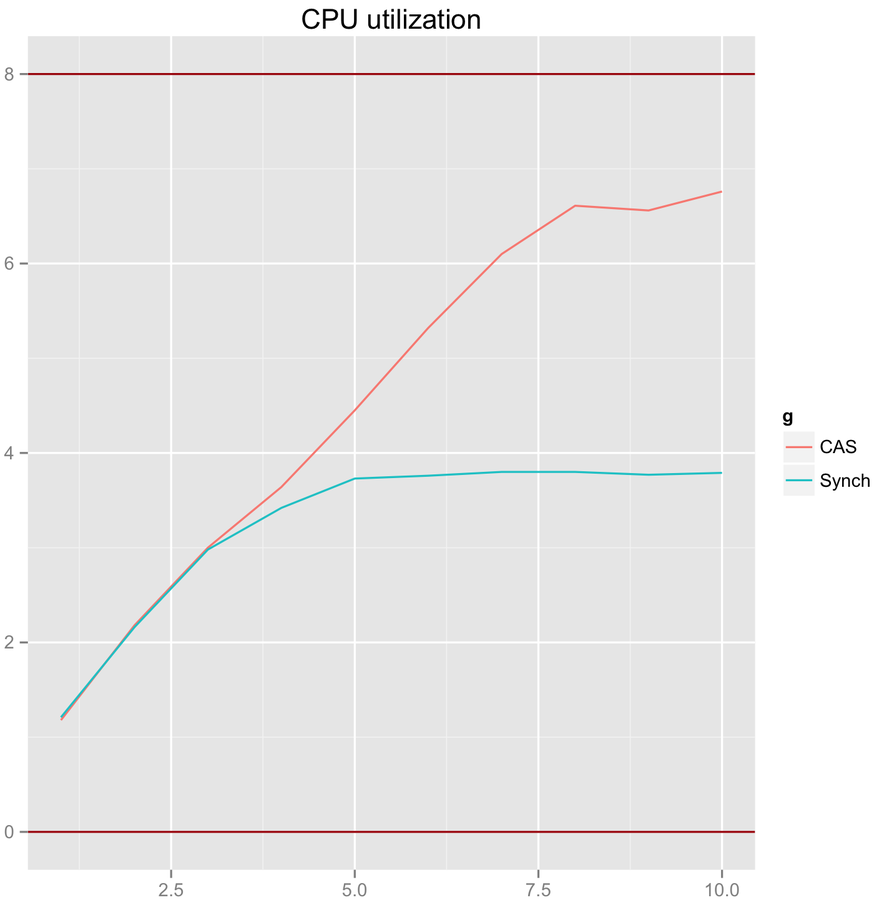
CAS scalability. Optimal ratio
Throughput
threads count
CPU Load
threads count
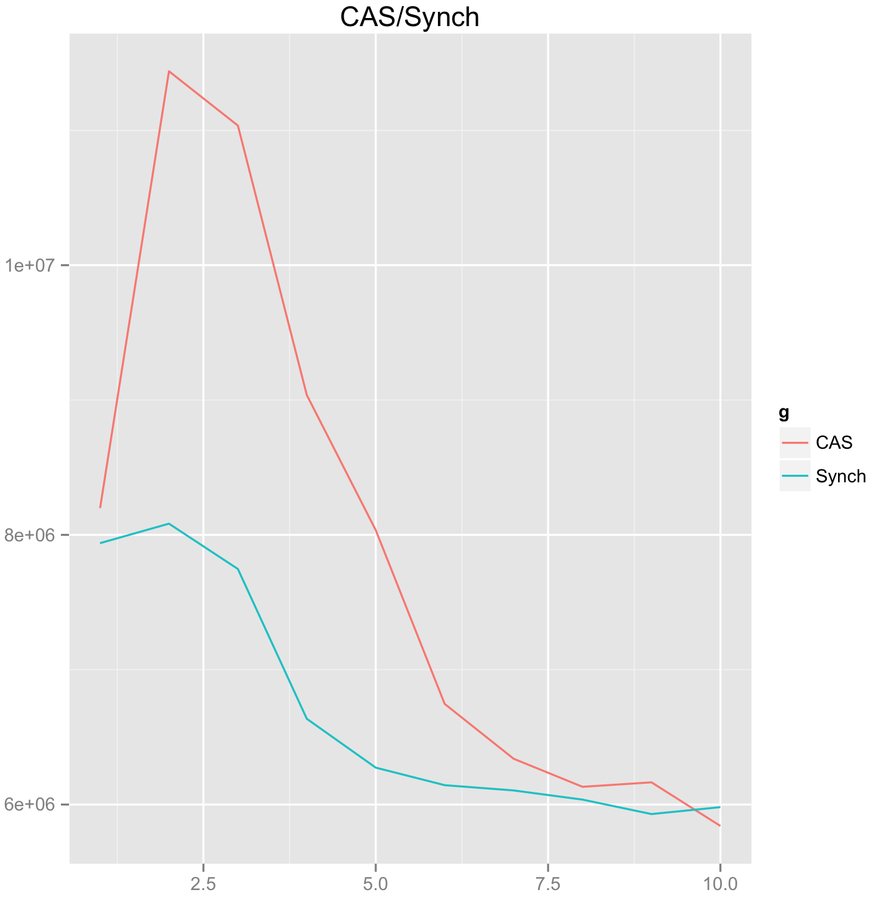
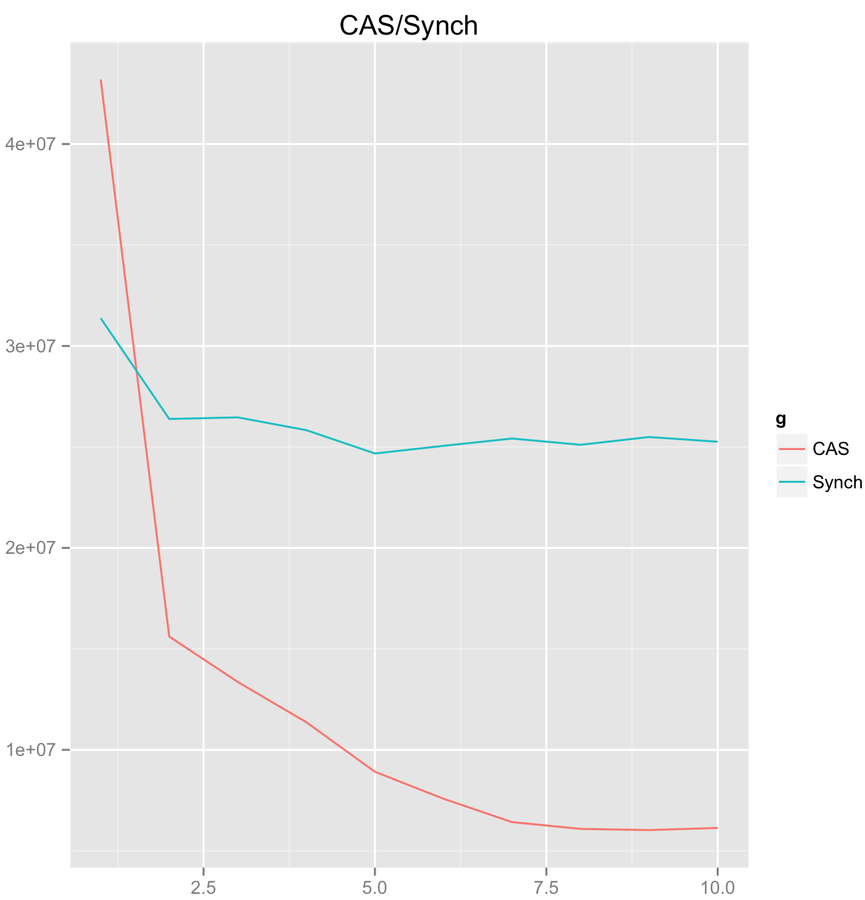
CAS scalability. High contention
Throughput
threads count
CPU Load
threads count
CAS. Backoff techniques
Exponential backoff is an algorithm that uses feedback to multiplicatively decrease the rate of some process, in order to gradually find an acceptable rate.

//~Constant Backoff by Thread.yield()
public void casMethod() {
Integer current, next;
boolean result;
do {
current = unsafeValue;
next = current + 1;
result = unsafe
.CAS(this, offset, current, next);
if(!result) Thread.yield();
//unsafe.park(false, 1);
} while (!result);
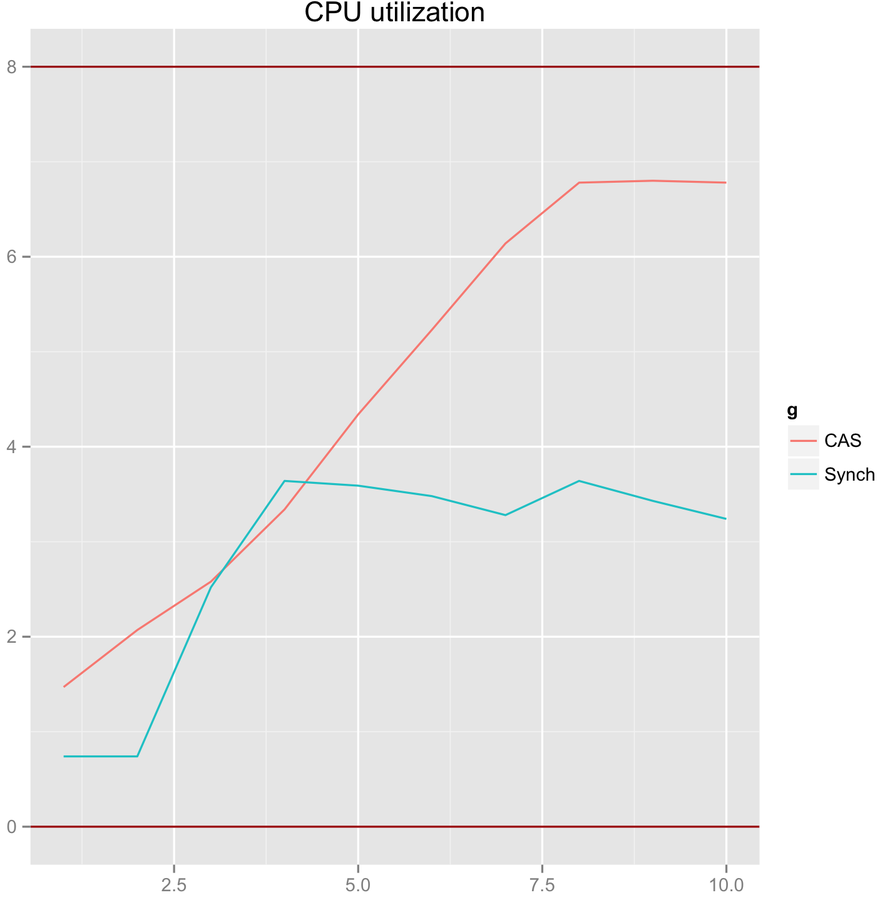
}CAS scalability. High contention with Backoff
Throughput
threads count
CPU Load
threads count
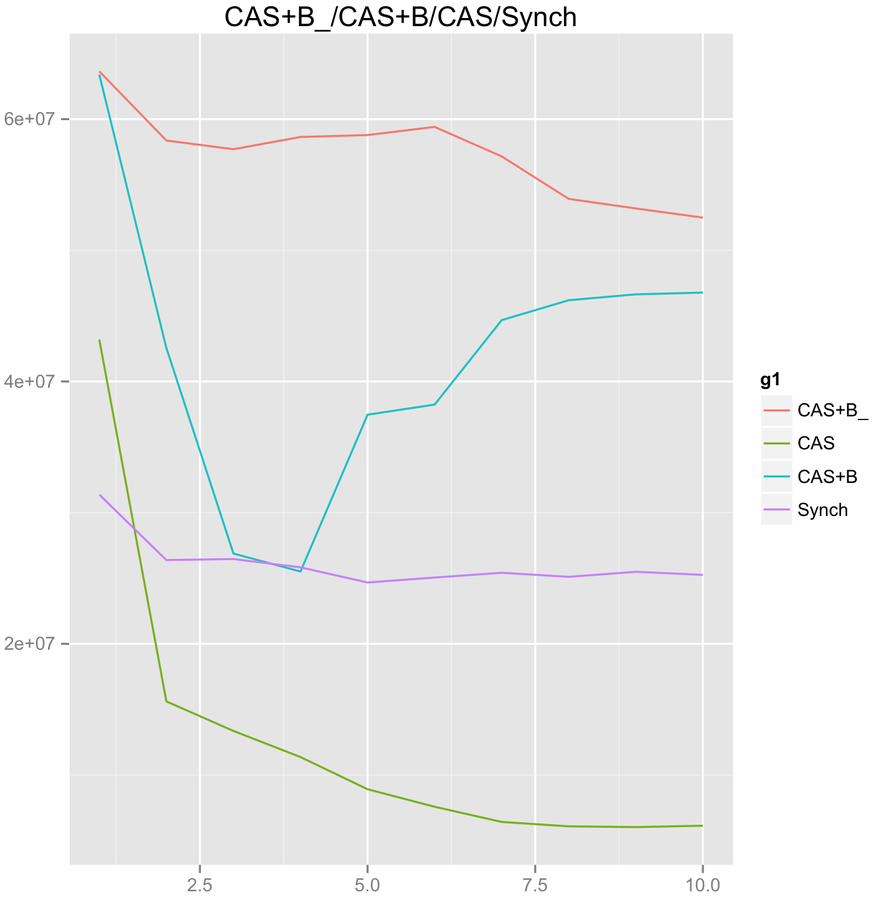
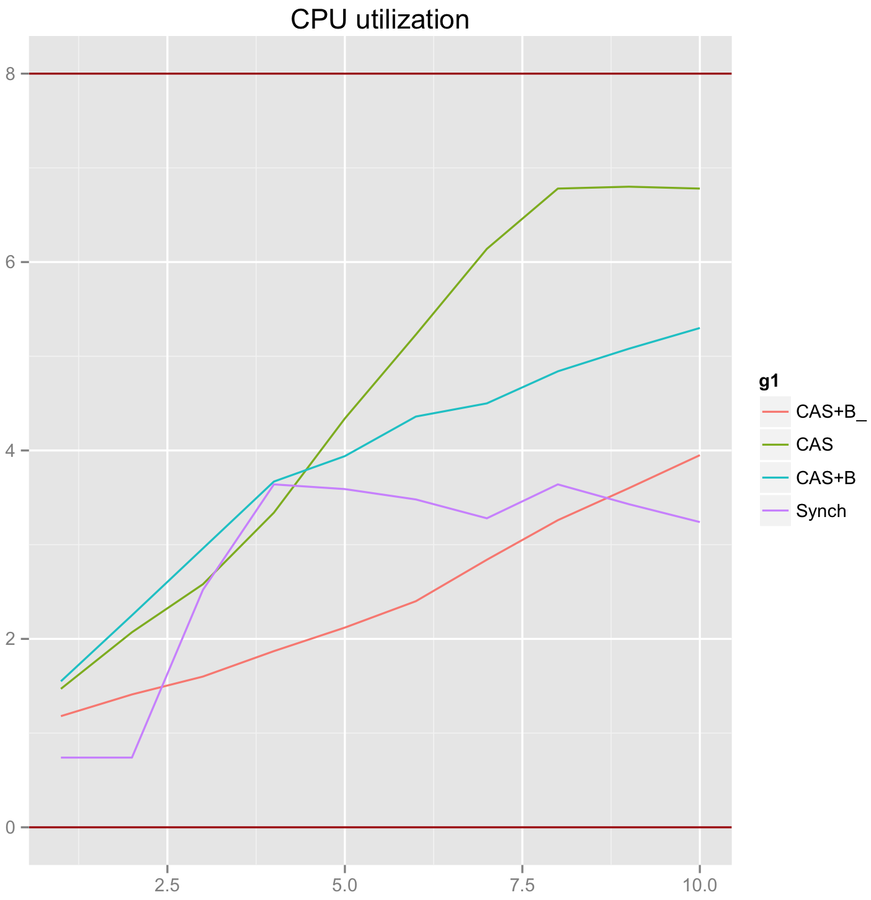
CAS+B_ = UNSAFE.park(false, 1), CAS+B = Thread.yield()
Max CPU utilization performance
1. LMAX Disruptor. ~2.2e+08 (4x1x1)
2. ABQ. ~3.3e+07 (3x2x2)
3. CAS. ~2.2e+07 (3x1x1)
4. Exchanger ~1.8e+07 (3x1x1)
5. LBQ ~1.6e+07 (2x3x3)
7. Synchronized ~7.0e+05 (6x1x1)
Conclusions
1. Do test scaling. Most solutions have some limit
2. Decompose. Test each part separately. ReentrantLock
has worse performance than synchronized if threads = 2
3. Consider using several queues instead of one. And guarantee threads count limit
4. Modern solutions such LMAX Disruptor work better but it's more difficult to implement and support them
Producer/Consumer
queue solutions
Questions
1. Scalability
2. Reliability
3. Faul-tolerance
Disruptor. Reliability, Fault-tolerance
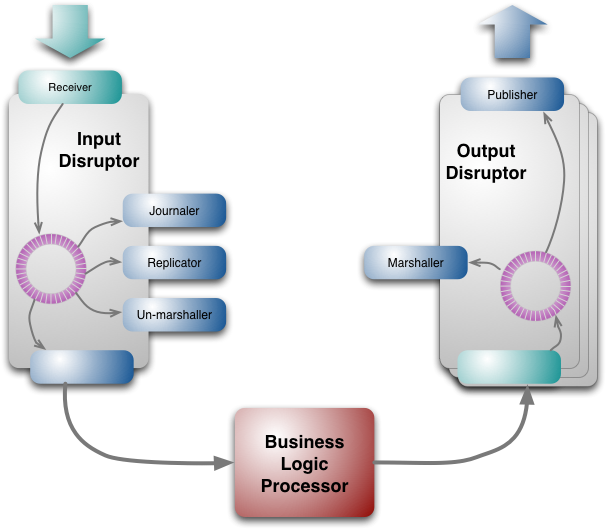
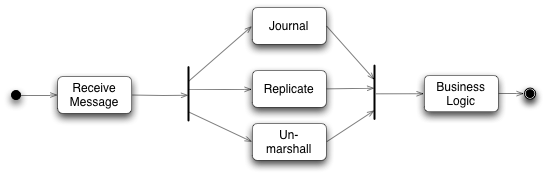
Details
Journaler is durable - Reliability
Replicator syncs nodes - Fail-over
Multiple instances
Actors. Akka
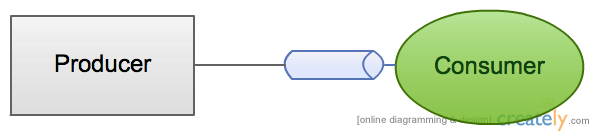
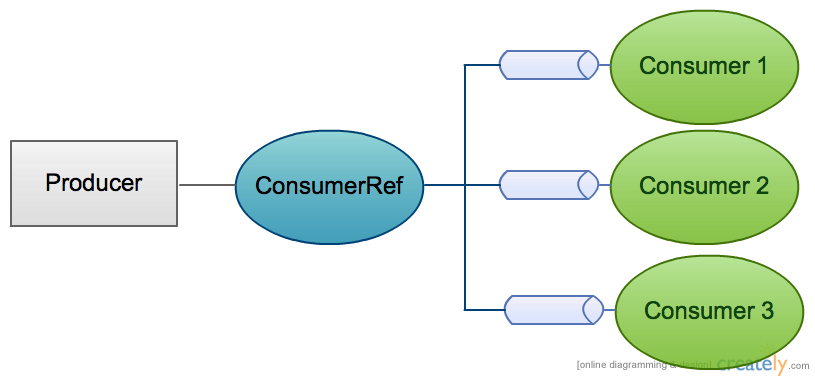
Akka. Router. Dispatcher. Mailbox
Router = Actor instance count/Consumer/Queue count
Dispatcher = How many threads? How are they creating?
Mailbox = Queue implementation (e.g. ABQ, Disruptor)
Properties
1. Actors programming model. (No synchronize code or working with complex concurrent data structure)
2. Configurable. Modular (Router, Dispatcher, Mailbox)
3. Scalable across network (Akka remoting)
4. Fault Tolerant
Multithreading scalability with Balancer

1. Naive approach
2. Thread.currentThread().getId() mod count.
Better. But it gives random results.
3. Thread binding
threads count
Throughput
threads count
CPU Load
Randomizing performance
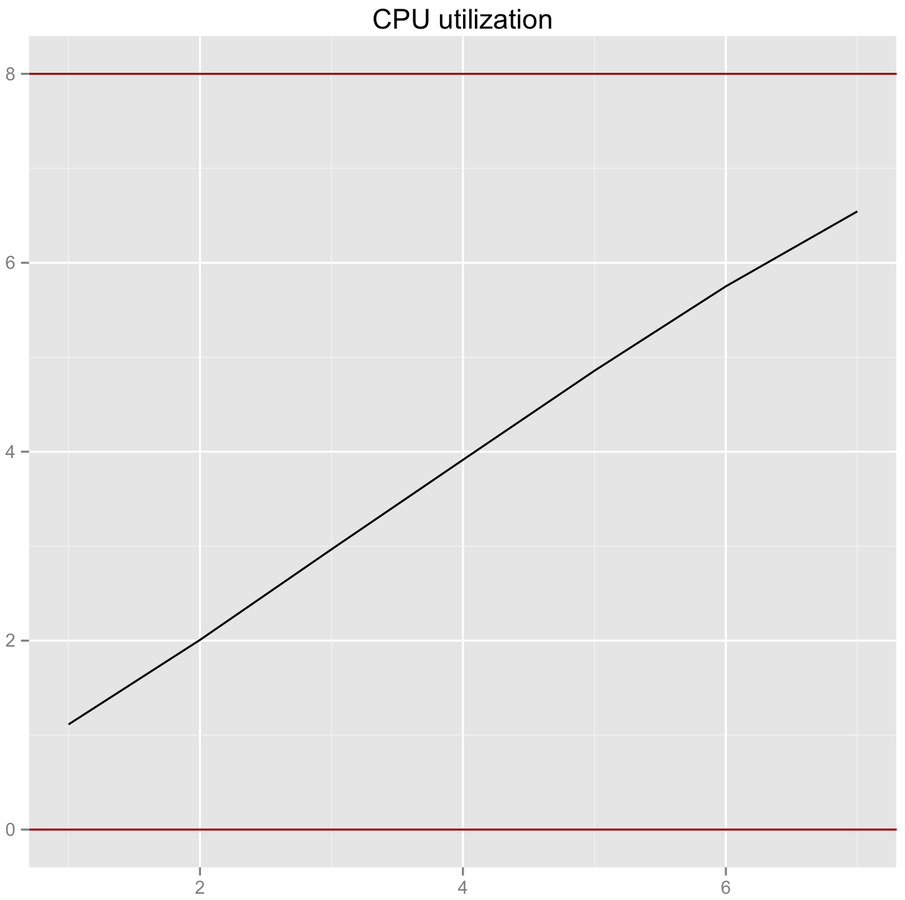
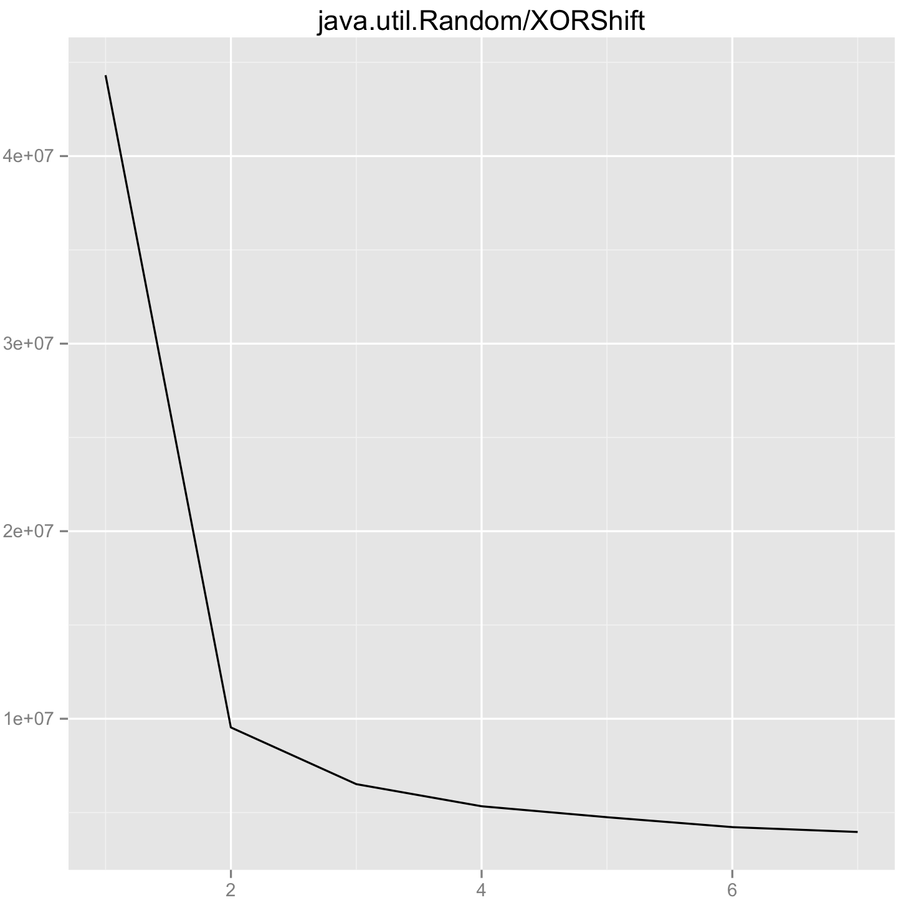
Multithreading scalability. Questions
1. What if n/m != integer?
2. What if I don't have Thread pool?
3. What if load can vary from time to time?
Counting network
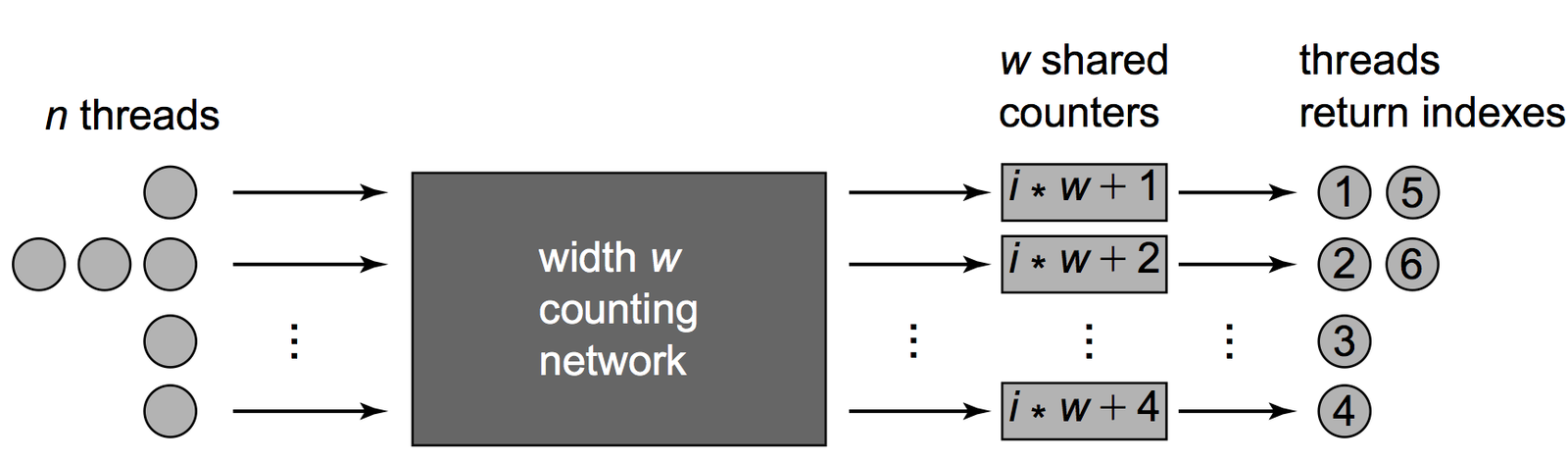
A balancer is a simple switch with two input wires and two output wires, called the top and bottom wires (or sometimes the north and south wires)
Known algorithm: Bitonic Counting Network
Also there is Sorting network
Diffraction Trees or counting trees
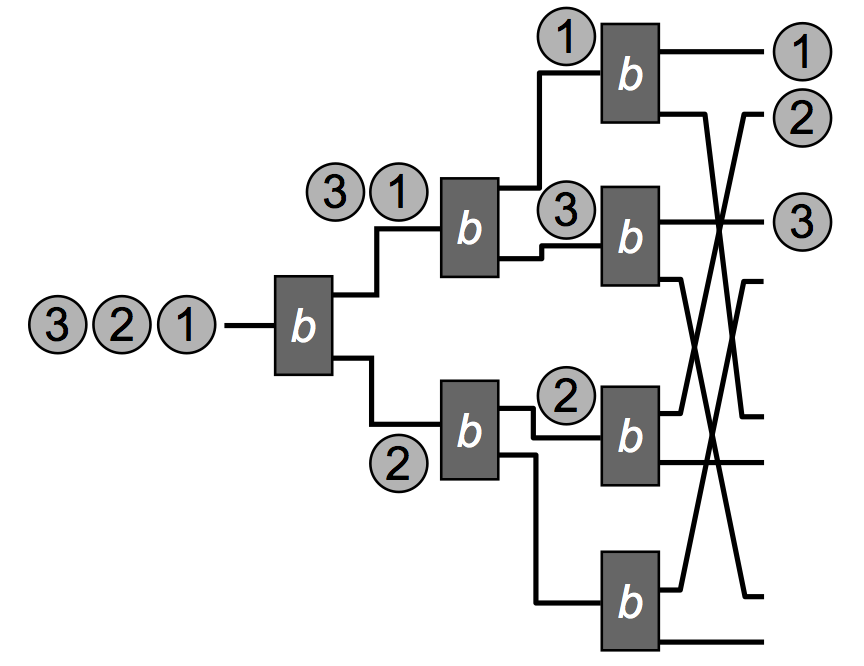
It's distributed technique for shared counting.
Bitonic counting networks have width w < n and depth O(log w^2). Diffraction trees has depth O(log w)
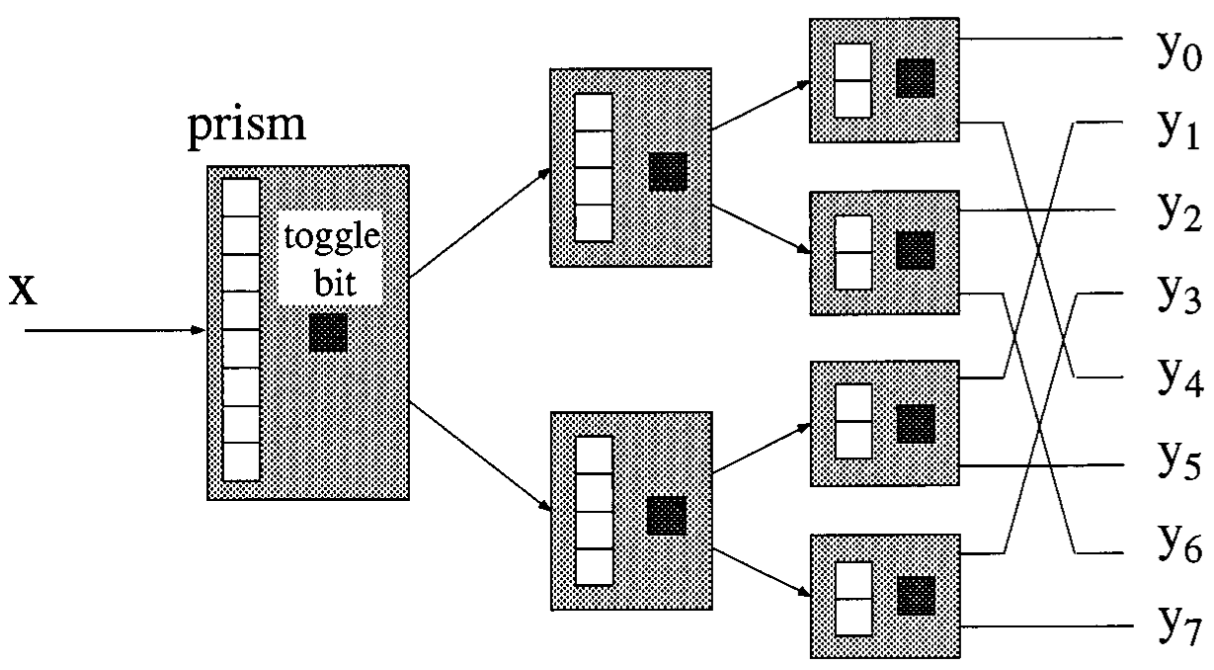
Diffraction Trees or counting trees
Introduces diffraction prism to eliminate contention on toggle bit
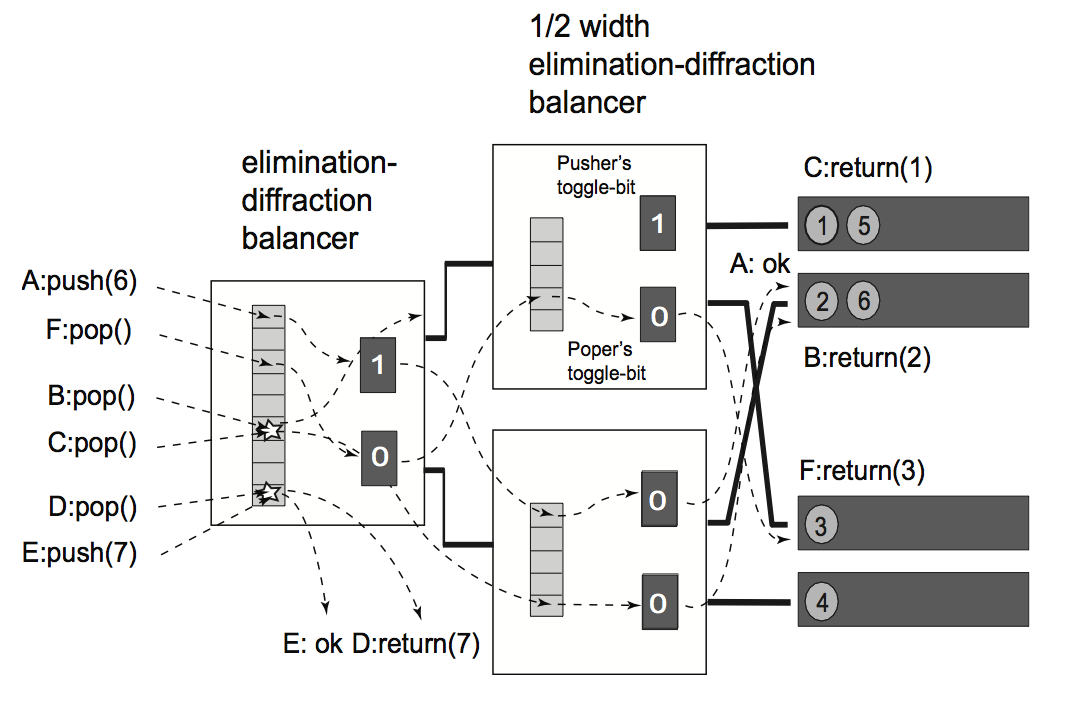
Elimination-Diffraction Trees
Producer/Consumer
external
queue implementation
Description
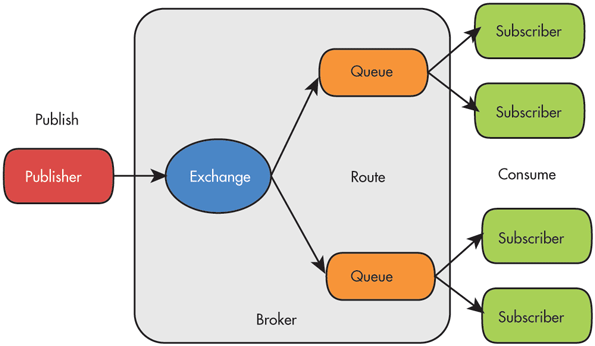
AMQP
Two protocols: AMQP, JMS
Motivation
1. Also implementation of producer/consumer
2. Reliable, fault tolerant, scalable solution. Transactional.
3. Interoperable. Connect subsystems which are implemented of different technologies stack
4. In case of AMQP two subsystems could have different queue clients
5. In case of using ESB you can connect different queue implementations
Solutions
1. Integrated to JEE server or Standalone?
2. Implementations



How to choose?
1. What are required properties?
2. Implementation. Decomposition
Network IO
Memory
queue
Disk
IO
Clustering
Transactional
Faul Tolerance
...
Other components
HornetQ
Netty NIO
RabbitMQ
Erlang Thread model
Erlang Thread model
Special cases
Events stream processing
Kafka


How much Apache Flume is high-throughput?
LinkedBlocking Queue
Transactional
2 LinkedBlocking Queue (put, take)
+ synchronized
1. It's not the best sink solution. What if I'd like to use Storm?
2. What If I don't need transactional?
Netcat source
NIO. Channels
What about Apache Kafka?
Consequent Write on
Disk
Clustering. Replication
Using ZooKeeper
NIO. Channels
No serialization protocol
There are only consequent write and read
Kafka. Cons
1. There is no support JMS, AMQP
2. It's not transactional
3. There is almost no Memory queue.
4. Maintain only Topics
Conslusion
- Consumer/producer world is very powerful
- Learn more. Make decision based on your deep knowledges about a solution
- Decompose. Study well. Decide what you should pay
References
1. Java Concurrency in Practice by Brian Goetz.
2. The Art of Multiprocessor Programming by Maurice Herlihy.
3. Руслан Черёмин — Disruptor и прочие фокусы.
4. The LMAX. Architecture. http://martinfowler.com/articles/lmax.html
5. Disruptor: High performance alternative to bounded queues for exchanging data between concurrent threads by Martin Thompson.
6. Java Message Service by Mark Richards.