Monito
A scalable, extensible and robust monitoring and test-deployment solution for planetary scaled network
Context
Knowledge background
- General computer science at INSA, France
- Distributed systems at KTH : bases and advanced
- Several school/hackathon projects
Context
Thesis context
- International company
- Online services
- Large number of users (Tens of million with peaks up to 1-2 milions at a time)
- Need for high availability, requiring good monitoring
- Existing monitoring solution, but not satisfactory enough
Context
Terms definition
- Node : computer unit needed to be monitored (server, device)
- System : the entire set of nodes that need to be monitored
- Network : the structure supporting communication between the nodes.
Context
Objectives and requirements
Objectives
- Provide a service to deploy test on a system
- Being able to receive data from this system
Objectives and requirements
- Focus on the architecture and protocols responsible for the flow of data from and to the user, from and to the nodes in the system.
Requirements
- The complexity of the solution at a connection level should remain as low as possible, even with a growing number of nodes in the system.
- The load on the nodes of the system and the network should remain low, and not grow rapidly with the number of nodes in the system.
- The solution should be able to run in a non reliable network, being able to provide part or all of its services when handling network failures, until a certain point.
Objectives and requirements
Requirements (2)
- The solution should be adapted to a changing system
- The costs of the solution should be bounded
- The solution should get close to work in real-time.
Objectives and requirements
Requirements
- Network topology should not prevent the solution to run normally.
- Data must be able to be communicated without aggregation if needed.
Objectives and requirements
Methodology
Building the solution step by step
Methodology
Dividing the data flow
- Dividing dataflow and make aggregation possible (but not mandatory) : bridge nodes
- Avoiding a single node handling all the data processing by introducing a Message Queue (RabbitMQ)
Dividing the data flow
How to decide on the bridge nodes ?
Leader election over a gossip membership discovery
Gossip membership discovery
Goals
- Knowing the environment
- Handling high turnover of nodes
- Gossip protocol
Gossip membership discovery
The SWIM protocol
- Partial views
- Cycles of executions
- UDP communications
Gossip membership discovery
Overview of the protocol
- Identification of a node
- Use of a bootstrap node
- Division in several states : ALIVE, SUSPECTED, DEAD
- Heart-beat protocol with random selected neighbour
- Partial views with merge policy, a key element of the SWIM protocol
Gossip membership discovery
The SWIM protocol
Adapting the SWIM protocol
- No override possible of an DEAD node in the SWIM protocol
- Introduction of a "NEW" state
- Focus on the detection of failure, better have false positive !
Gossip membership discovery
The SWIM protocol
Results
Gossip membership discovery
The SWIM protocol
Text
Text
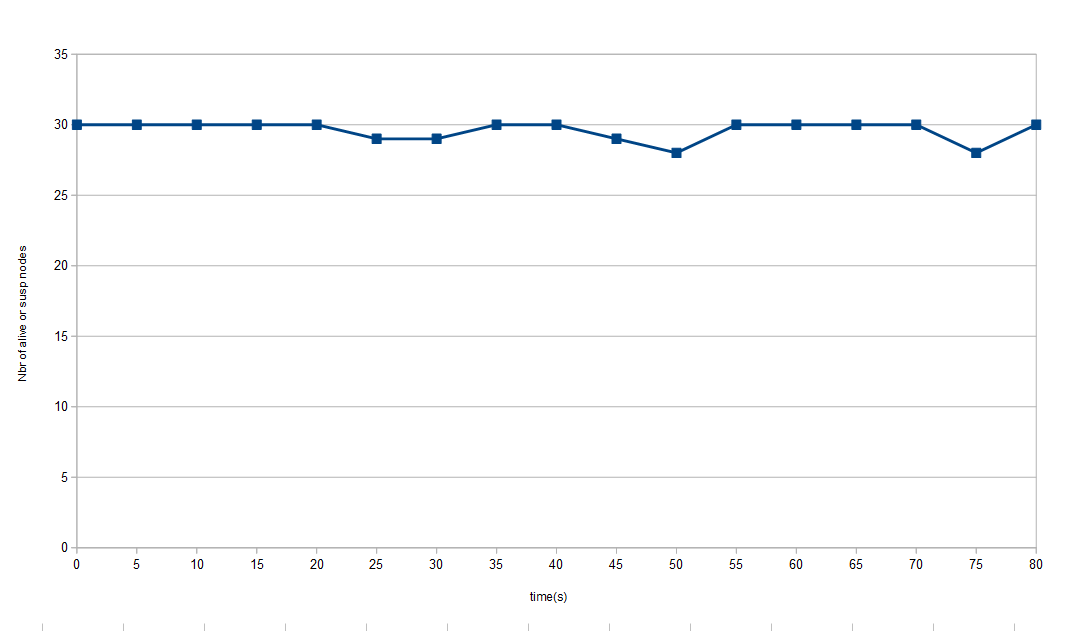
Number of alive + suspected nodes through time with a network with 7% of message drop
Results
Gossip membership discovery
The SWIM protocol
Text
Text
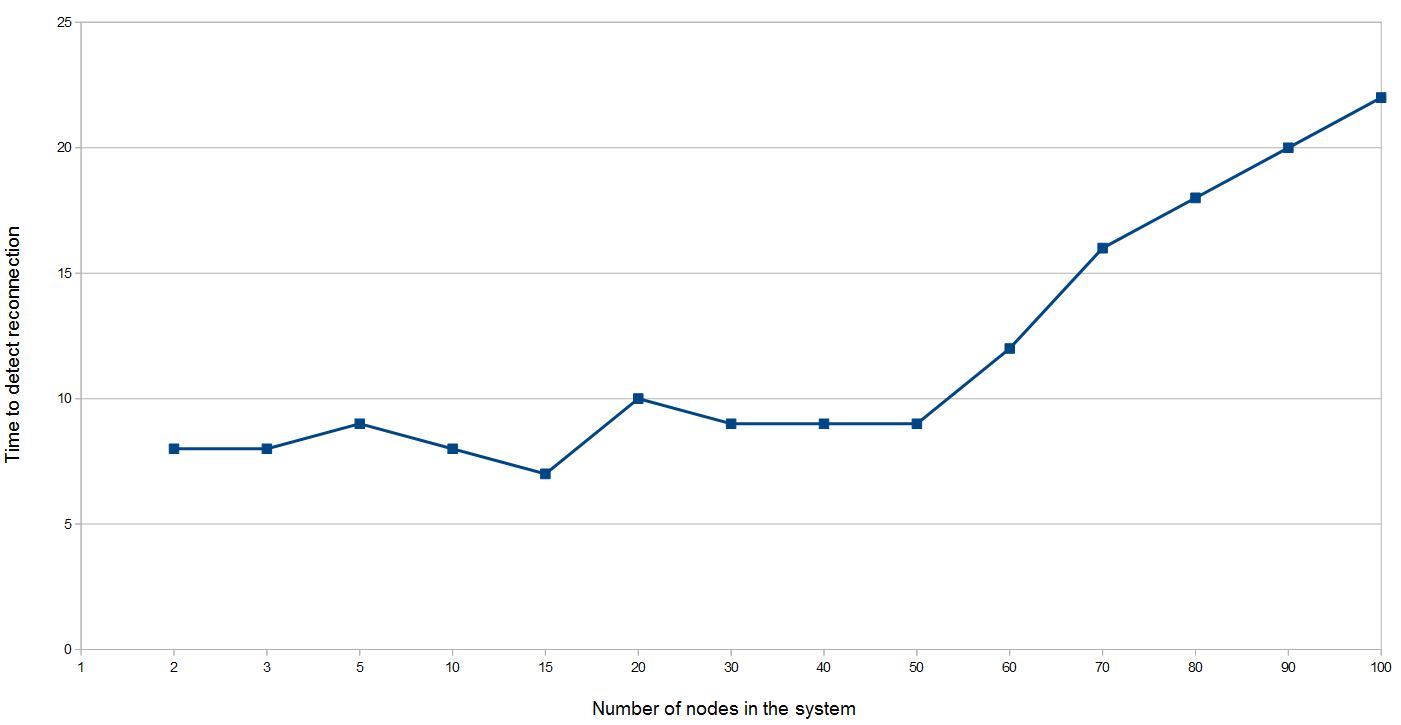
Time for a node to reconnect to the network with a growing number of nodes
Conclusion
- Reasonable load of the network thanks to the one-node-picked by cycle
- Low quantity of data exchanged (Only part of the partial view)
- Robust to network failures
- Robust to nodes failure and turnover
- However, topology limited
Gossip membership discovery
The SWIM protocol
Reliable broadcast
A difficult task
- Need to ensure global message broadcast
- Difficult task because of diverse failures
- Hard to keep track of nodes that received the message
Reliable broadcast
Using SWIM
- Using the partial view
- Broadcast to a subpart of the partial view
- Cascade re-broadcast
- Maximum of rounds, and only-once broadcast
Reliable broadcast
Results
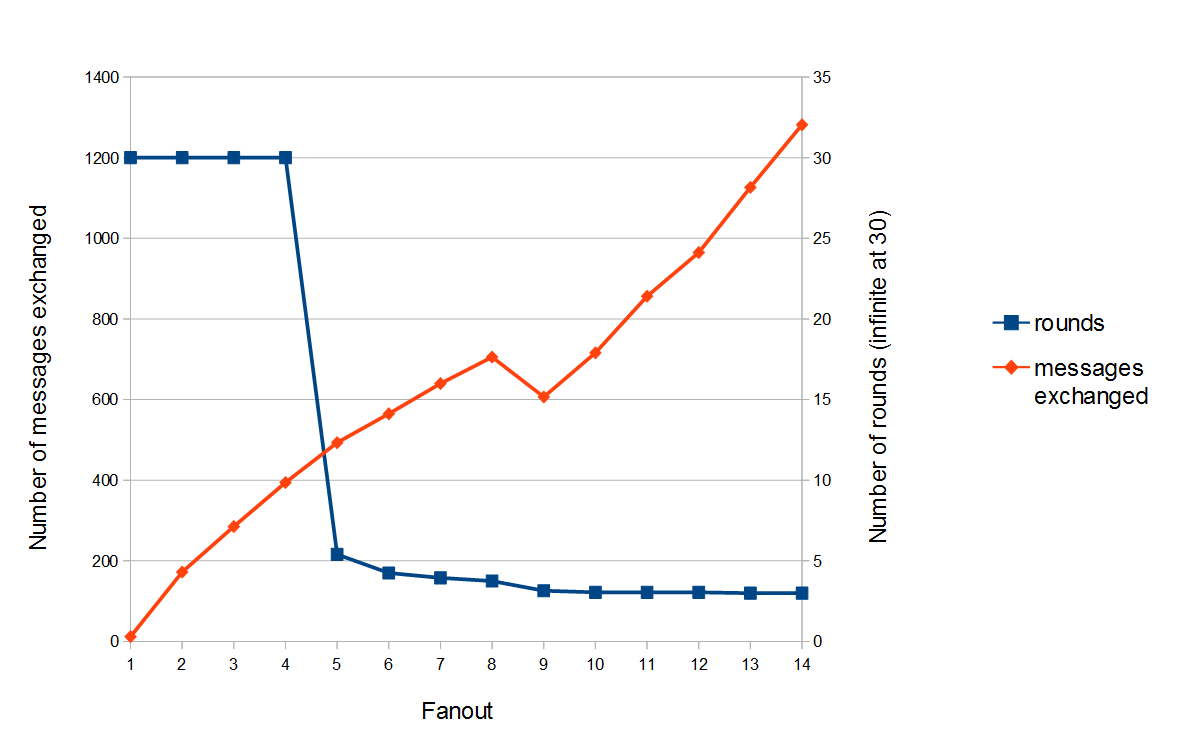
Number of rounds and messages needed to broadcast a message to all the group with an increasing fanout
Reliable broadcast
Results
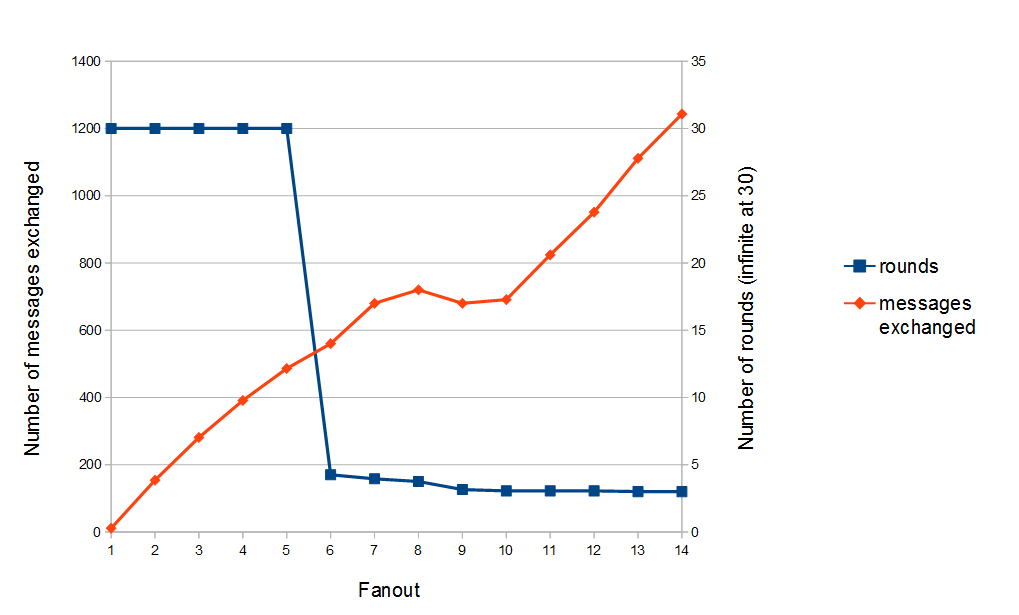
Number of rounds and messages needed to broadcast a message to all the group with an increasing fanout and 7% of message drop
Reliable broadcast
Conclusion
- No additional components
- Close to real time
- Overload and scalability subject to discussion : avoid to broadcast large messages, delay when re-broadcasting
- Robust to failures
Reliable broadcast
Leader election
A multiple leader election
- Existence : among all the nodes of the system, there is eventually at least N nodes that are aware of being a leader, and these nodes are non-faulty.
- Weak agreement : among all the nodes of the system, all the non-faulty nodes are eventually aware of the existence of at least N leaders, and those leaders are not require to be the same from one node to another.
Leader election
The tools
- Every node has the knowledge of a partial view of the network, and is able to know which node are likely to be non-faulty in this view
- The failure of nodes can be eventually detected.
- A high-probability reliable broadcast provide a fast messaging to all the nodes of the system.
Leader election
Elections needed
- The number of leaders in the system drops below N leaders : Leaders take care of electing a new node
- All the leaders are dead, and an election should rebalance the number of leader again : highest ID in partial view
Leader election
Elections done by specific protocols and broadcast
Results
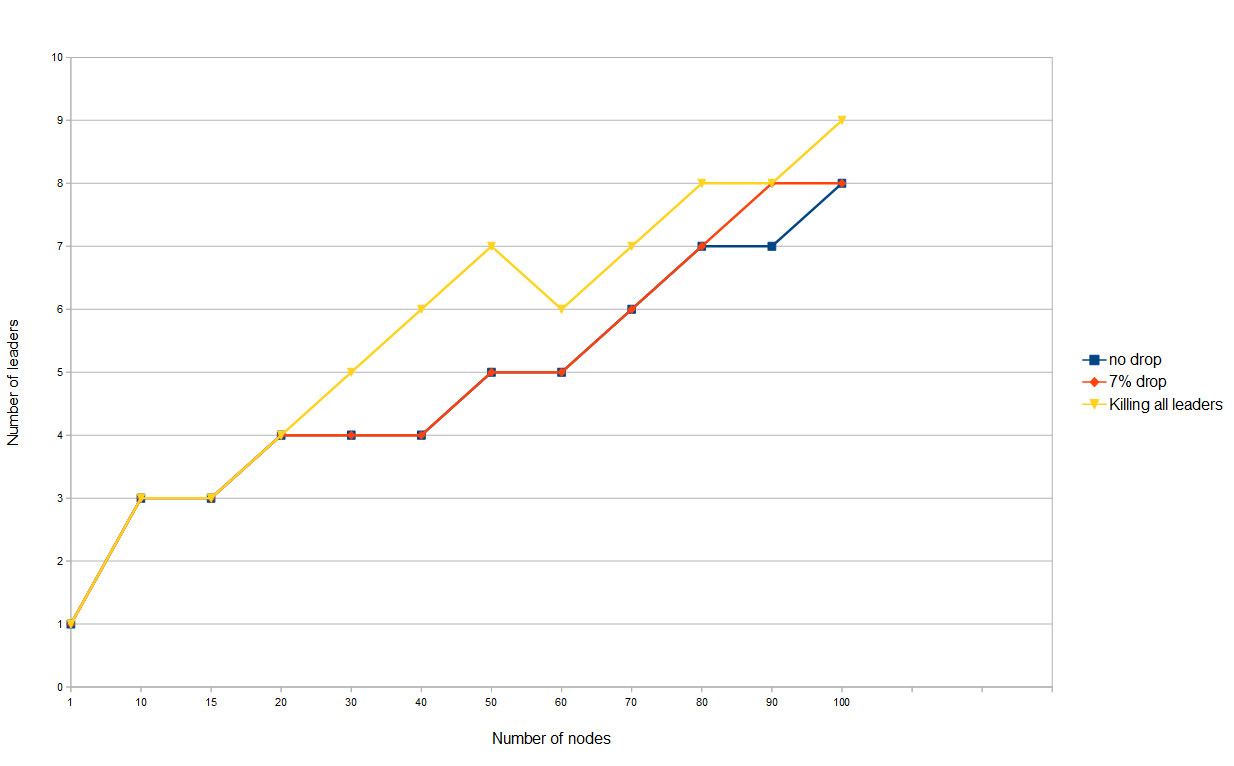
Leader election
Number of leaders with a growing number of nodes and different network settings
Conclusion
- No additional components
- Close to real time
- Scaling well since built on top of scaling protocols
- Robust to failures
- Growing number of connections and data on the network not increasing more than linearly
Leader election
The use of leaders to ensure data flow
Requirements
- Every data from a node should reach the message queue at least once
- The data should reach the message queue in real-time
- Aggregation should be provided if needed
- Filtering should be provided
- Monito requirements
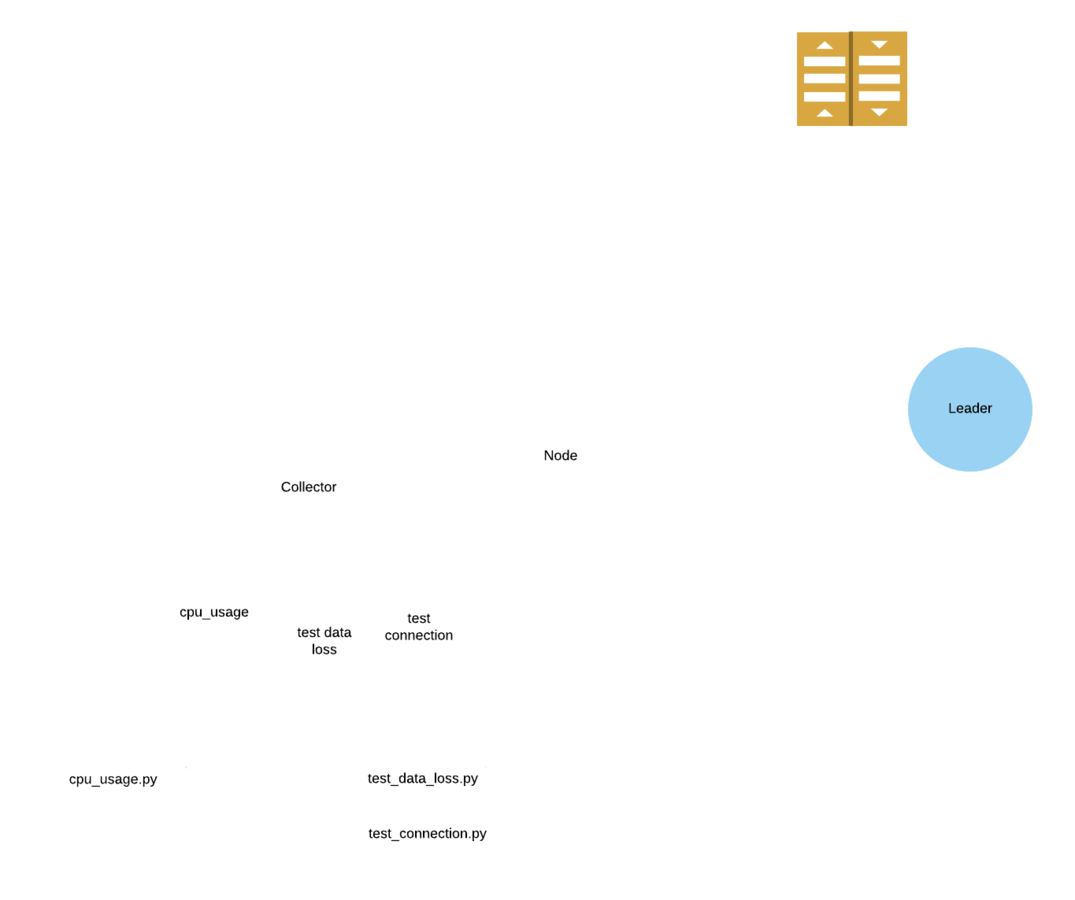
The use of leaders to ensure data flow
Current architecture
The leader as a buffer
Results
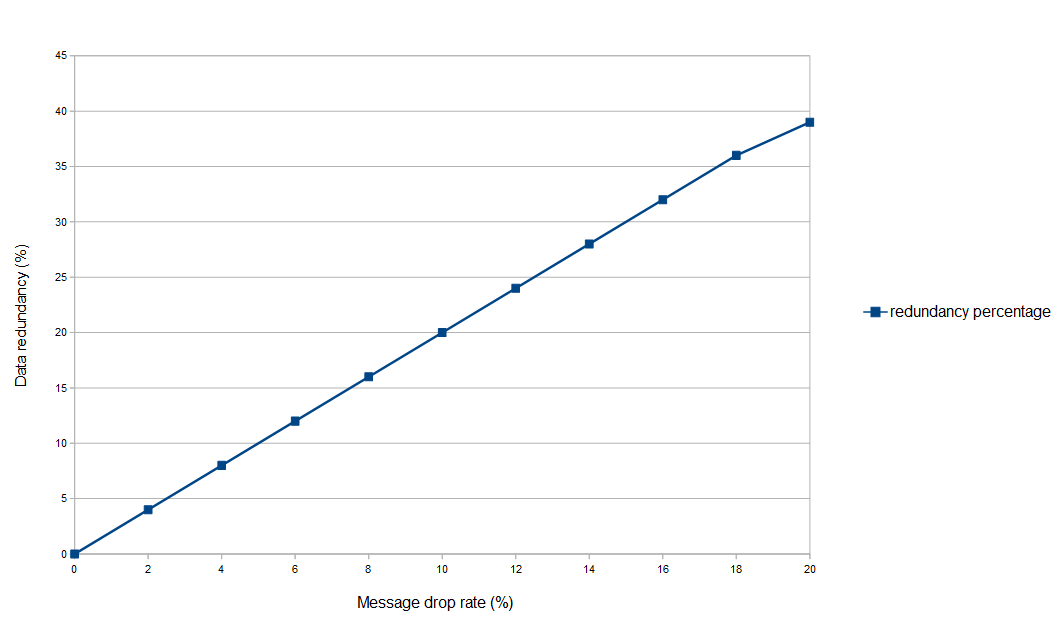
The use of leaders to ensure data flow
Percentage of data redundancy with an increasing rate of message drop on the network
Results
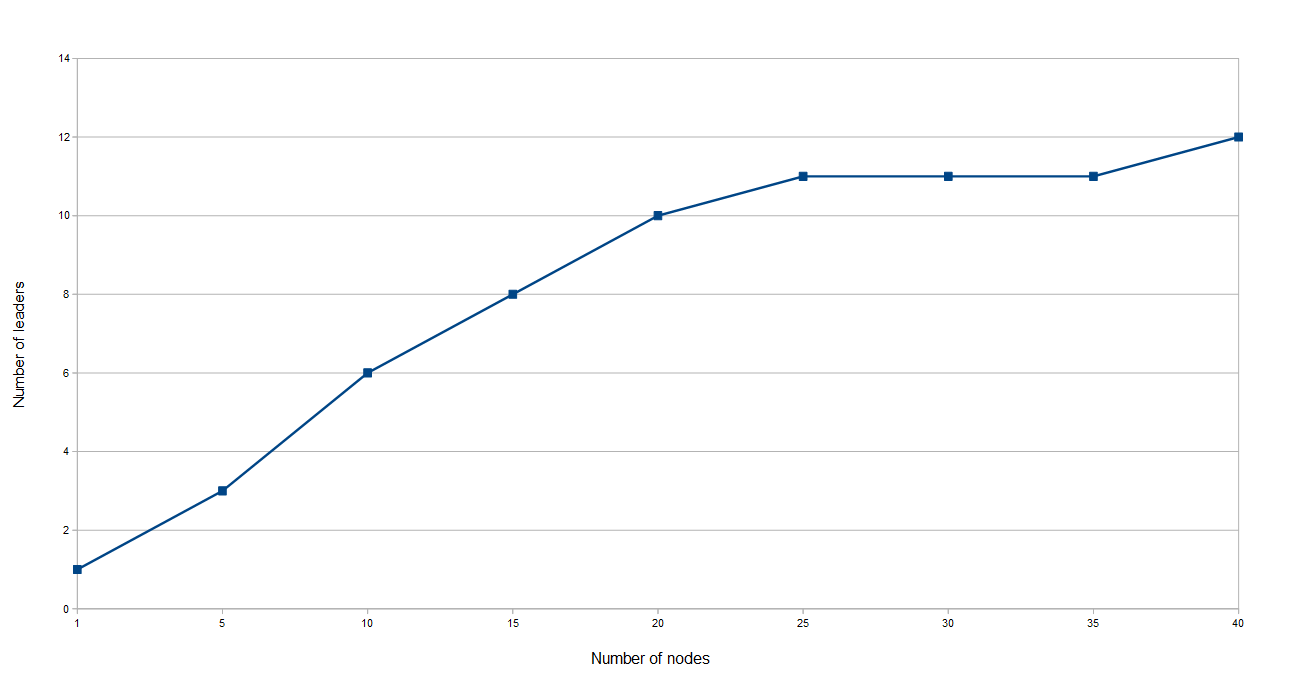
The use of leaders to ensure data flow
Number of leaders with an increasing number of nodes in the system, and stressful data flow conditions
Conclusion
- Scales well : aggregation and leader number
- Robust to failures
- Close to real time
- Load on nodes divided among leaders
- No additional components
The use of leaders to ensure data flow
The data flow, base of a test deployment protocol
Objectives
Send a test to all the nodes in the system
- Send a test to a specific node in the system
The data flow, base of a test deployment protocol
CDN based protocol
- Following a previous attempt not described here
- Uses a CDN as an external component to provide security
- Based on broadcasting of test description
The data flow, base of a test deployment protocol
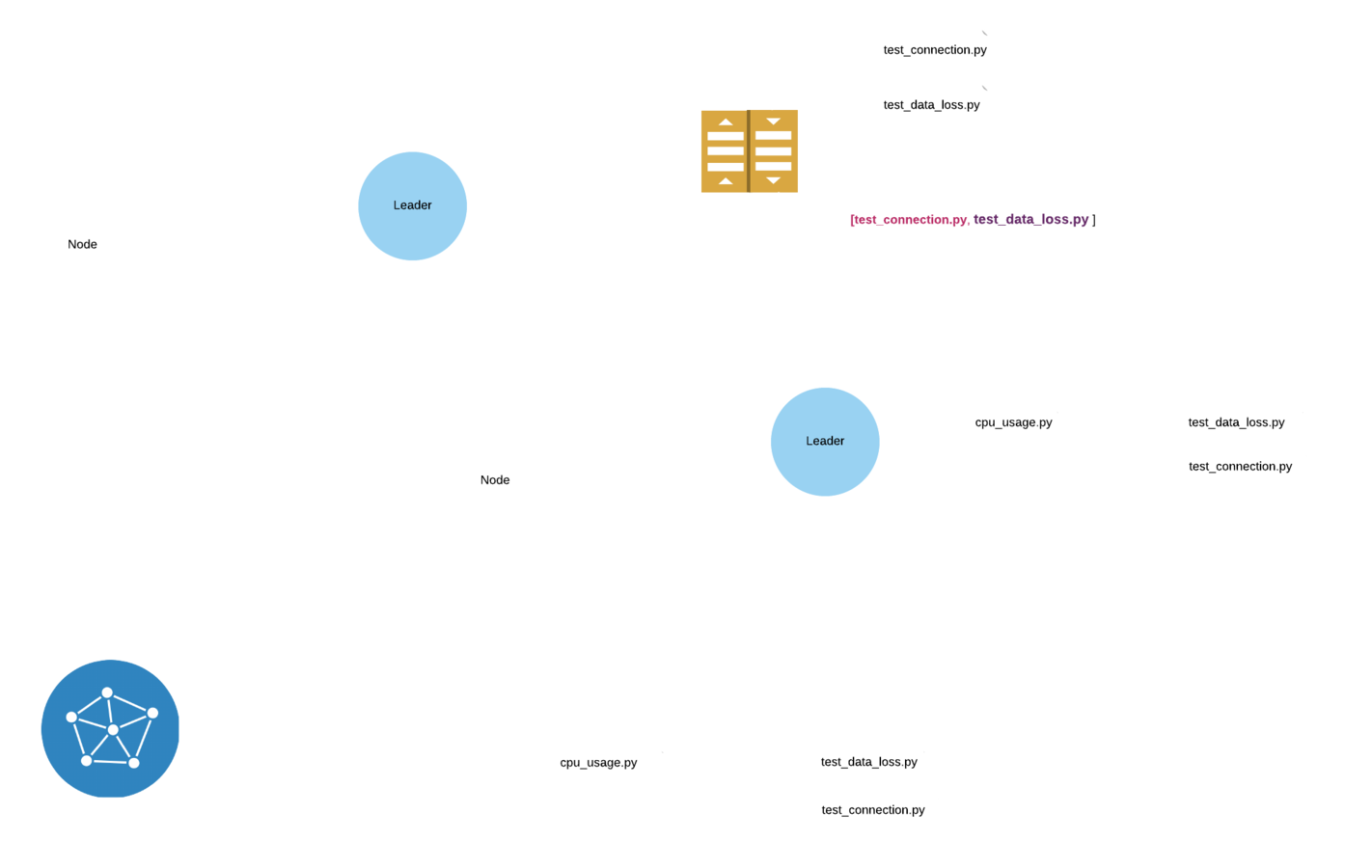
The data flow, base of a test deployment protocol
CDN based protocol
What if leaders die before broadcasting ?
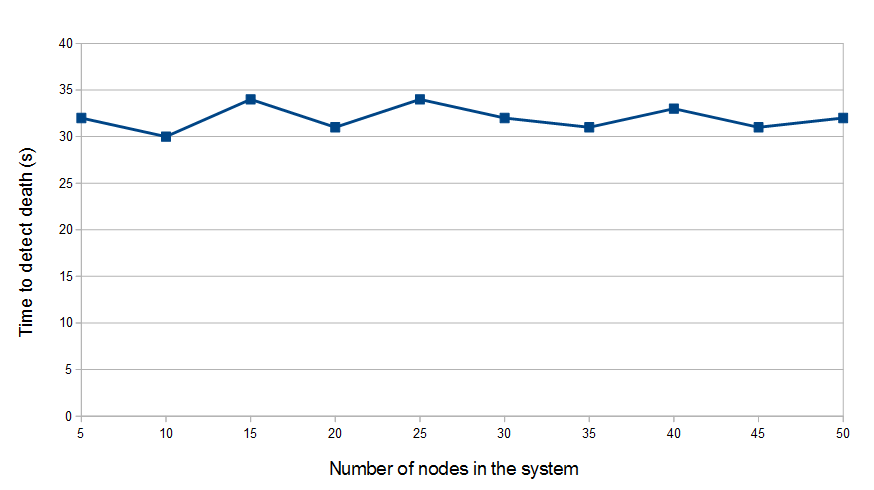
Time to detect a leader's death with a growing number of nodes in the system
The data flow, base of a test deployment protocol
CDN based protocol
Test pulling
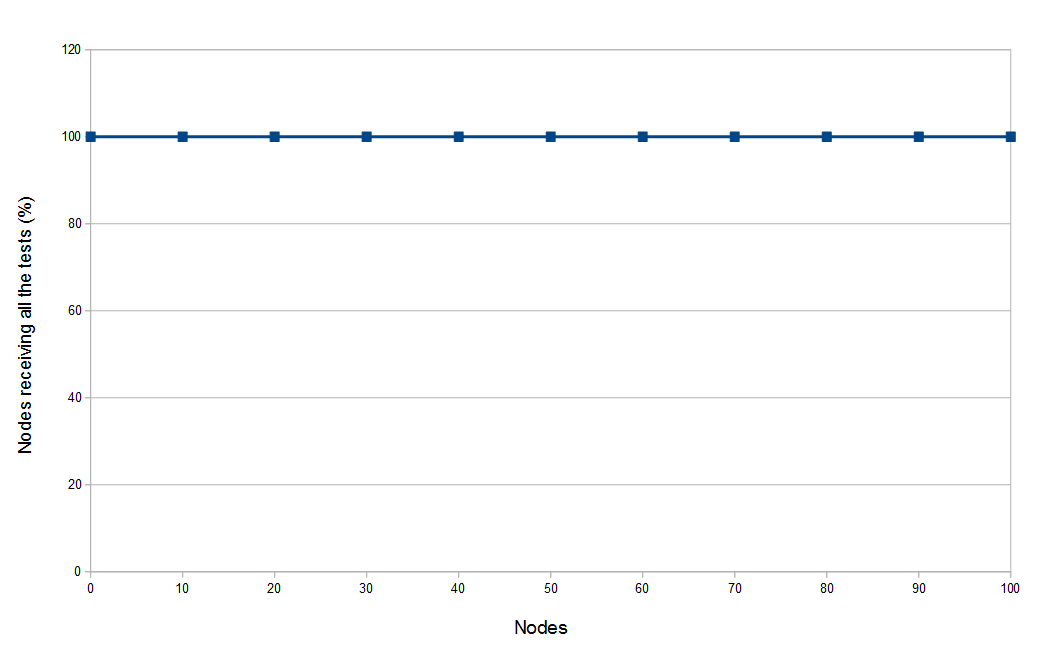
Percentage of nodes receiving tests after a deployment cycle with a growing number of nodes
The data flow, base of a test deployment protocol
CDN based protocol
Failure events
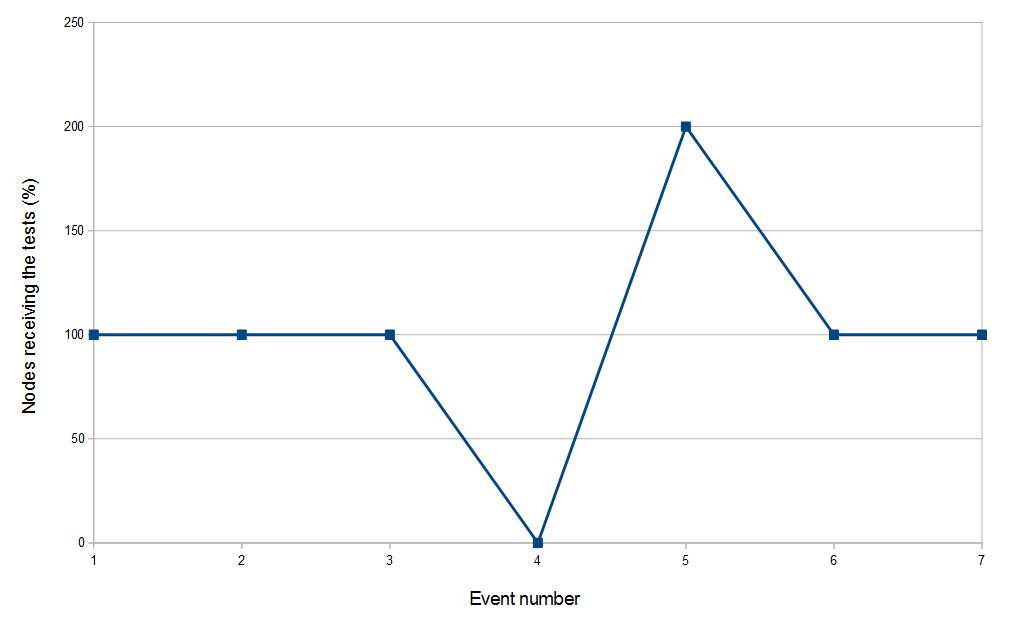
Percentage of nodes receiving tests after failures event
The data flow, base of a test deployment protocol
CDN based protocol
Conclusion
- This time requires external component if CDN solution is used
- Still robust, scalable, close to real time.
Scaling the election leader protocol
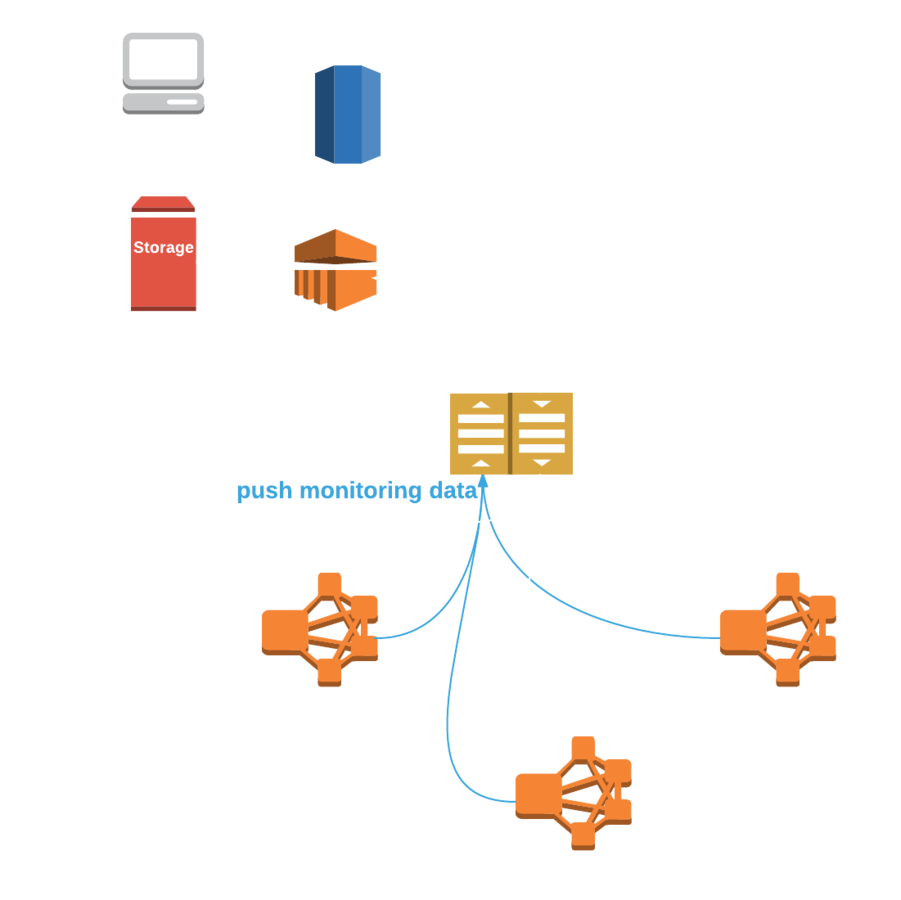
Global architecture
Close-up
Conclusion
- Bootstrap node becomes a critical element !
- Passive participant not overloaded
- Still need some user imput to pre-divide the groups : Help facing the topology problems
Future work
- More measurement, especially in network load
- Improve the broadcast algorithm (Decreasing fanout)
- Bullet Three
- Impact of partial view distribution
- Bootstrap node related problems (node management...)
- Resign leader from election protocol
Future work
Conclusion
Global conclusion
- Number of connections and load remain low or linearly evolving
- Robust to network and node failures
- Low number of additional components
- Close to real time
- Aggregation possible
Topology sensible but Bootstrap node solve it
Some facts ?
Thesis facts:
- Around 12 000 - 14 000 lines of python code
- Tests:
- On local machine (with Mininet, 4 cores dedicated at 2.7Ghz)
- On amazon cloud for scaling

Timeline: