Compiler Flow
PyTorch model
TensorFlow model
TVM Compiler
Relay graph
Optimizer
Relay graph
(optimized)
Codegen
shared library(.so)
Runtime
Hardware
Compiler Flow
PyTorch model
TensorFlow model
TVM Compiler
Relay graph
Optimizer
Relay graph
(optimized)
Codegen
shared library(.so)
Runtime
Hardware
- Unify multiple different DNN representations into a single intermediate representation (IR)
Compiler Flow
PyTorch model
TensorFlow model
TVM Compiler
Relay graph
Optimizer
Relay graph
(optimized)
Codegen
shared library(.so)
Runtime
Hardware
- break computation to smaller chunks which fit on the hardware
- a series of loop transformation - tiling, unrolling, etc.
TVM AutoTuner - Simulated annealing
Reinforcement Learning based optimizer
cost-model based on simulator
Compiler Flow
PyTorch model
TensorFlow model
TVM Compiler
Relay graph
Optimizer
Relay graph
(optimized)
Codegen
shared library(.so)
Runtime
Hardware
- Generate systolic ISA instructions from Relay graph
- Upstream support with TVM: new operators in PyTorch requires no extra effort
Offload computation to accelerator
Execute unsupported operations on CPU
Compiler Flow
PyTorch model
TensorFlow model
TVM Compiler
Relay graph
Optimizer
Relay graph
(optimized)
Codegen
shared library(.so)
Runtime
Hardware
TVM Runtime schedules operations to CPU or accelerator
Accelerator runtime configures the accelerator to perform a certain operation
TVM Stack
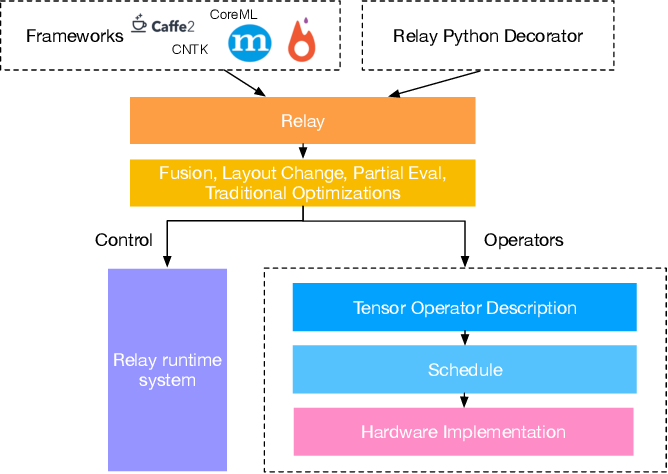
- Once custom codegen is registered to TVM Backend, any subgraph(operations) supported will be offloaded to the accelerator
Bring Your Own Codegen
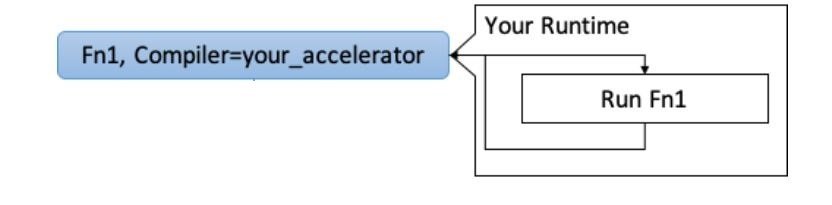
- The Relay graph is partitioned into different operation(s) according to predefined patterns.
- The compiler outputs the instruction according to the accelerators ISA and tags the operations to run in the accelerator