MongoDB Basics
Banana's edition
Agenda
- Overview
- CRUD Operations
- Aggregation Framework
- Indexes
- Lessons learned
Overview
What is MongoDB?
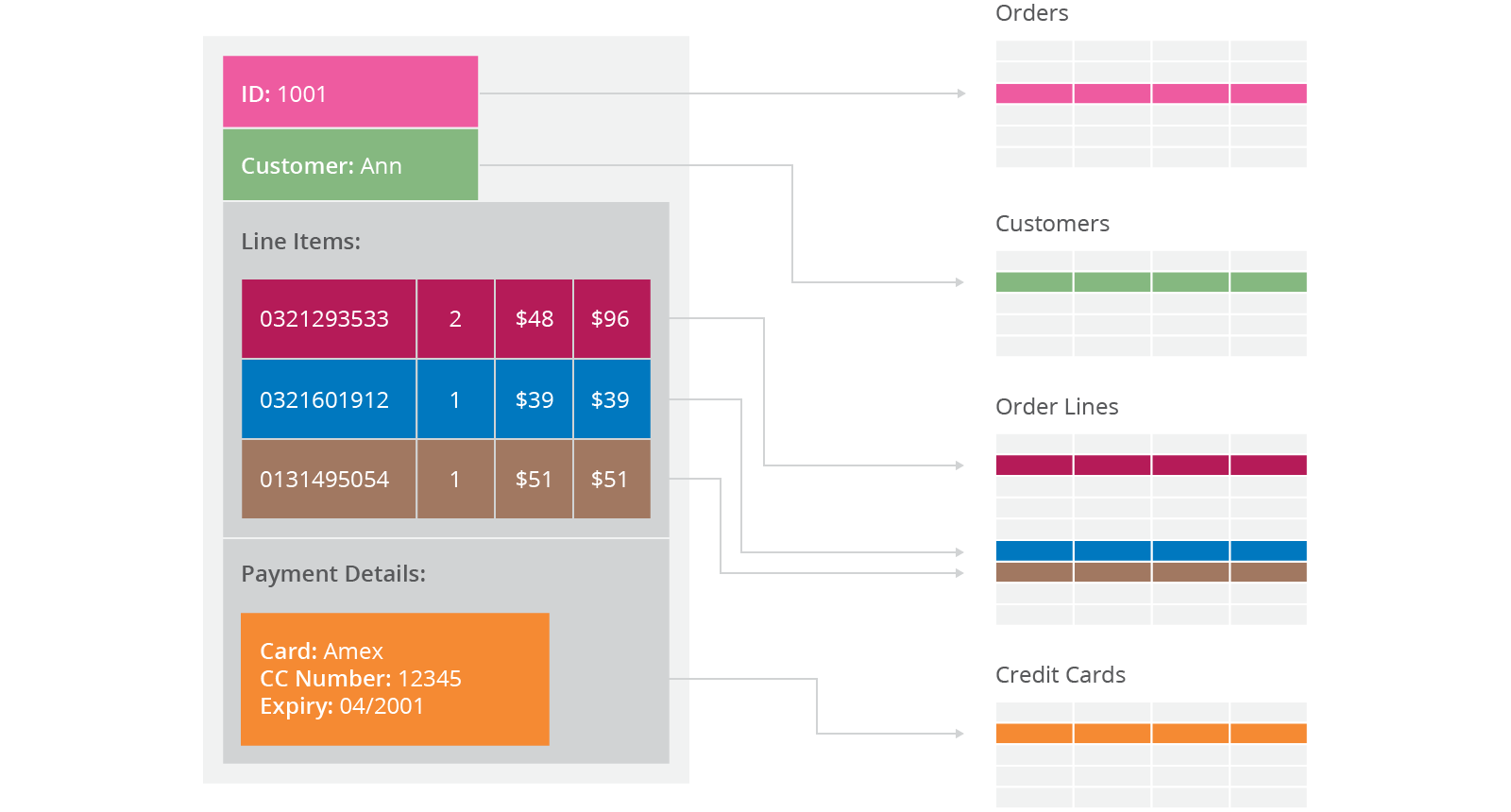
Why MongoDB?
- Document Oriented Storage
- Index on any attribute
- Replication and high availability
- Auto-sharding
- Rich queries
- Fast in-place updates
- Professional support by MongoDB
Terminology and Concepts
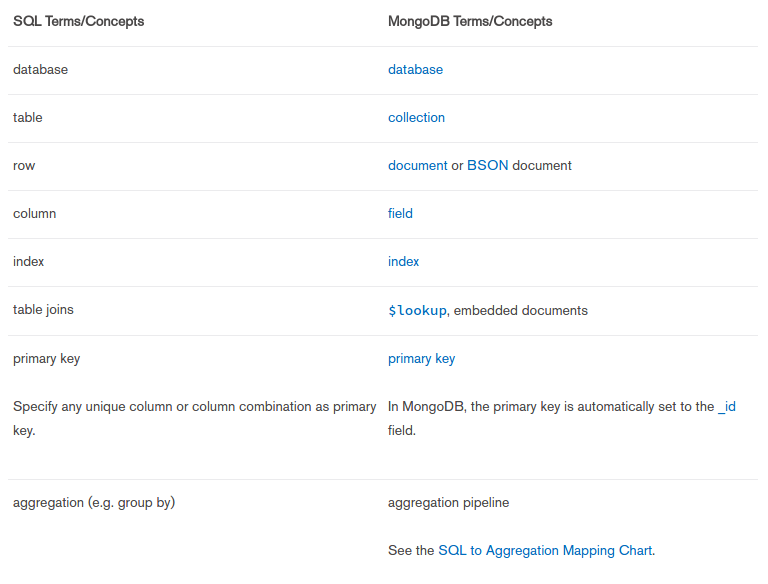
Teorema CAP
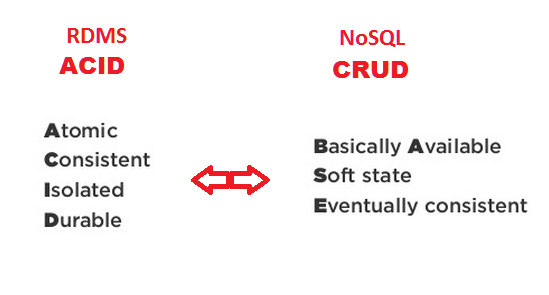
ACID vs BASE
CRUD Operations
Create Operations
- db.collection.insertOne()
- db.collection.insertMany()

Read Operations

- db.collection.find()
- db.collection.findOne()
Read Operations - findOne
db.getCollection('users')
.findOne({username: 'kimkardashian'})
############################ VS ############################
db.getCollection('users')
.find({username: 'kimkardashian'}).limit(1)
Read Operations- find
# state = California AND user_type = celebrity
db.users.find(
{state: 'California', user_type: 'celebrity'}
)
# select all - show only username and followers_count
db.users.find(
{},
{username: 1, followers_count: 1}
)
# select all - show all fields except _id and user_id
db.useres.find(
{},
{user_id : 0, _id: 0}
)Read Operations - Query criteria
########### $gt
# users with more than 1m of followers
db.users.find({followers_count: {$gt: 1000000}})
########### $in
# users related with zara
db.users.find({related_brands: {$in: ['zara']}})
Comparison query operators
$eq, $neq, $gt, $gte, $lt, $lte, $in, $nin
############ exists
# users with the "state" field
db.users.find({state: {$exists: 1}})
############ type
# users with text in the biography
db.users.find({biography: {$type: 2}})Read Operations - Query criteria
Element query operators (exists, type)
############ nor
# documents that:
# price field not equal to 1.99 and sale field not equal to true
# or price field not equal to 1.99 but do not contain the sale field
# or do not contain the price field but sale field not equal to true
# or do not contain the price field and do not contain the sale field
db.inventory.find(
{
$nor: [
{ price: 1.99 },
{ sale: true } ]
}
)Read Operations - Query criteria
Logical query operators (or, and, not, nor)
Read Operations - Query criteria
Logical query operators
$and ????

Read Operations - Query criteria
Logical query operators
$and ????
# users with # followers between 1M and 2M
db.users.find(
{
followers_count: {$gt: 1000000},
followers_count: {$lt: 2000000}
})db.users.find(
{
$and: [
{followers_count: {$gt: 100000}},
{followers_count: {$lt: 200000}}
]
})Read Operations - Query criteria
Logical query operators
$and ????
# brands with more than 1M of followers
# or celebrities with more than 200k followers
db.getCollection('users_copy').find(
{$or:
[
{$and: [
{user_type: 'brand'},
{followers_count: {$gte: 1000000}}
]},
{$and: [
{user_type: 'celebrity'},
{followers_count: {$gte: 200000}}
]}
]
})Read Operations - Query criteria
Array query operators
############# all
db.users.find(
{related_brands:
{$all: ['zara', 'mango']}
}
)
############# in
db.users.find(
{related_brands:
{$in: ['zara', 'mango']}
}
)
############# size
db.users.find({related_brands: {$size: 5}})Read Operations - Cursor modifiers
############# count
db.users.find({country:"USA"}).count()
############# limit
db.users.find({country:"USA"}).limit(5)
############# sort
db.users.find({country:"USA"})
.sort({'username':1, followers_count: -1})
############# pretty
b.users.find({username: 'kimkardashian'}).pretty()
The order of keys matters in MongoDB
Read Operations
db.books.find().pretty()
Read Operations
The order of keys matters in MongoDB
{
"_id" : ObjectId("58b4af99245cbeab4ab25b51"),
"title" : "Woe from Wit",
"meta" : {
"author" : "A. Griboyedov",
"year" : 1823
}
}The order of keys matters in MongoDB
db.books.find(
{ meta:
{ year: 1823, author: "A. Griboyedov" }
}
).count()db.books.find(
{ meta:
{ author: "A. Griboyedov", year: 1823 }
}
).count()01Read Operations
Update Operations
- db.collection.updateOne()
- db.collection.updateMany()
- db.collection.replaceOne()

Update Operations - upsert
db.people.updateMany(
{ name: "Andy" },
{
name: "Andy",
rating: 1,
score: 1
},
{ upsert: true }
)If set to true, creates a new document when no document matches the query criteria.
Create/Update Operations - save
Updates an existing document or inserts a new document, depending on its document parameter.
db.products.save( { item: "book", qty: 40 } )
> WriteResult({ "nInserted" : 1 })
db.inventory.updateMany(
{ _id: 1 },
{ $addToSet: { tags: ["accessories", "camera"] } }
){ _id: 1, item: "polarizing_filter", tags: [ "electronics", "camera" ] }db.inventory.updateMany(
{ _id: 2 },
{ $addToSet: {
tags: {
$each: [ "camera", "electronics", "accessories" ] }
}
}
){ "_id" : 1, "item" : "polarizing_filter",
"tags" : [ "electronics", "camera", [ "accessories", "camera" ] ] }
{ "_id" : 1, "item" : "polarizing_filter",
"tags" : [ "electronics", "camera", "accessories" ] }
Update Operations - arrays
Delete Operations

db.characters.bulkWrite(
[
{ insertOne :
{
"document" :
{
"_id" : 4, "char" : "Dithras", "class" : "barbarian", "lvl" : 4
}
}
},
{ insertOne :
{
"document" :
{
"_id" : 5, "char" : "Taeln", "class" : "fighter", "lvl" : 3
}
}
},
{ updateOne :
{
"filter" : { "char" : "Eldon" },
"update" : { $set : { "status" : "Critical Injury" } }
}
},
{ deleteOne :
{ "filter" : { "char" : "Brisbane"} }
},
{ replaceOne :
{
"filter" : { "char" : "Meldane" },
"replacement" : { "char" : "Tanys", "class" : "oracle", "lvl" : 4 }
}
}
]
);Bulk Write Operations
{
"acknowledged" : true,
"deletedCount" : 1,
"insertedCount" : 2,
"matchedCount" : 2,
"upsertedCount" : 0,
"insertedIds" : {
"0" : 4,
"1" : 5
},
"upsertedIds" : {
}
}Bulk Write Operations
Bulk Write Operations
- Ordered list of operations: executes the operations serially.
- Unordered list of operations: can execute the operations in parallel, but is not guaranteed.
- By default, bulkWrite() performs ordered operations.
To specify unordered write operations, setordered : false in the options document.
Aggregation
Aggregation Pipeline

Aggregation Expressions
- Data is processed in RAM
-
You can use indexes to improve performance in the various stages. In addition, it has an internal optimization phase.
-
It runs in native code written in C ++
- "Flexible, functional and easy to learn"
db.people.aggregate(
{
$match: {
isActive: true
}
},
{
$project: {
isActive: 1,
name: 1,
mainAddress: "$address.primary"
}
});Aggregation Expressions
db.people.aggregate(
{
$group: {
_id: {
gender: "$gender"
},
averageAge: {
$avg: "$age"
},
count: {
$sum: 1
}
}
});Aggregation Expressions
db.inventory.aggregate( [ { $unwind : "$sizes" } ] )Aggregation Expressions - $unwind
{ "_id" : 1, "item" : "ABC1", "sizes" : "S" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "M" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "L" }{ "_id" : 1, "item" : "ABC1", sizes: [ "S", "M", "L"] }{ "_id" : 1, "item" : "abc", "price" : 12, "quantity" : 2 }
{ "_id" : 2, "item" : "jkl", "price" : 20, "quantity" : 1 }
{ "_id" : 3 }Aggregation Expressions - $lookup
{ "_id" : 1, "sku" : "abc", description: "product 1", "instock" : 120 }
{ "_id" : 2, "sku" : "def", description: "product 2", "instock" : 80 }
{ "_id" : 3, "sku" : "ijk", description: "product 3", "instock" : 60 }
{ "_id" : 4, "sku" : "jkl", description: "product 4", "instock" : 70 }
{ "_id" : 5, "sku": null, description: "Incomplete" }
{ "_id" : 6 }Orders
Inventory
db.orders.aggregate([
{
$lookup:
{
from: "inventory",
localField: "item",
foreignField: "sku",
as: "inventory_docs"
}
}
])Aggregation Expressions - $lookup
Aggregation Expressions - $lookup
{
"_id" : 1,
"item" : "abc",
"price" : 12,
"quantity" : 2,
"inventory_docs" : [
{ "_id" : 1, "sku" : "abc", description: "product 1", "instock" : 120 }
]
}
{
"_id" : 2,
"item" : "jkl",
"price" : 20,
"quantity" : 1,
"inventory_docs" : [
{ "_id" : 4, "sku" : "jkl", "description" : "product 4", "instock" : 70 }
]
}
{
"_id" : 3,
"inventory_docs" : [
{ "_id" : 5, "sku" : null, "description" : "Incomplete" },
{ "_id" : 6 }
]
}Map Reduce

While the custom JavaScript provide great flexibility compared to the aggregation pipeline, in general, map-reduce is less efficient and more complex than the aggregation pipeline.
Map Reduce
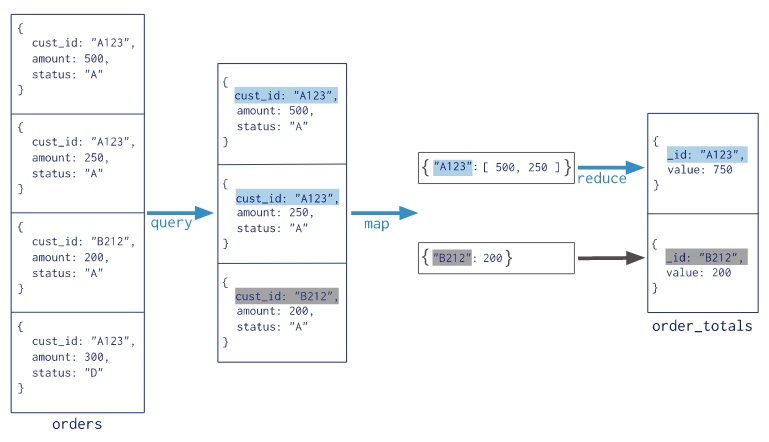
Map Reduce - Example
{
_id: ObjectId("50a8240b927d5d8b5891743c"),
cust_id: "abc123",
ord_date: new Date("Oct 04, 2012"),
status: 'A',
price: 25,
items: [ { sku: "mmm", qty: 5, price: 2.5 },
{ sku: "nnn", qty: 5, price: 2.5 } ]
}Return the Total Price Per Customer
Map Reduce - Example
Return the Total Price Per Customer
# 1- Define the map function to process each input document:
var mapFunction1 = function() {
emit(this.cust_id, this.price);
};
# 2- Define the reduce function:
var reduceFunction1 = function(keyCustId, valuesPrices) {
return Array.sum(valuesPrices);
};
# 3- Perform the map-reduce on all documents
db.orders.mapReduce(
mapFunction1,
reduceFunction1,
{ out: "map_reduce_example" }
)Indexes
Before creating indexes
-
Understand your data
-
How your queries will be
-
Create as few indexes as possible
-
Put your highly selective fields first in the index
-
Check your current indexes before creating new ones
Create index

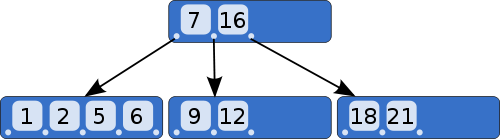
B-Tree
Index types
Single Field
{
"_id": ObjectId("570c04a4ad233577f97dc459"),
"score": 1034,
"location": { state: "NY", city: "New York" }
}db.records.createIndex( { score: 1 } )
db.records.find( { score: 2 } )
db.records.find( { score: { $gt: 10 } } )The sort order (i.e. ascending or descending) of the index key does not matter
Index types
Compound Index
{
"_id": ObjectId(...),
"item": "Banana",
"category": ["food", "produce", "grocery"],
"location": "4th Street Store",
"stock": 4,
"type": "cases"
}db.products.createIndex( { "item": 1, "stock": 1 } )
db.products.find( { item: "Banana" } )
db.products.find( { item: "Banana", stock: { $gt: 5 } } )The order of fields has significance
Index types
Multikey Index: index the content stored in arrays
{ _id: 5, type: "food", item: "aaa", ratings: [ 5, 8, 9 ] }
{ _id: 6, type: "food", item: "bbb", ratings: [ 5, 9 ] }
{ _id: 7, type: "food", item: "ccc", ratings: [ 9, 5, 8 ] }
{ _id: 8, type: "food", item: "ddd", ratings: [ 9, 5 ] }
{ _id: 9, type: "food", item: "eee", ratings: [ 5, 9, 5 ] }db.inventory.createIndex( { ratings: 1 } )
db.inventory.find( { ratings: [ 5, 9 ] } )Index types
Text Indexes: supports searching for string content in a collection
- A collection can have at most one text index
- You can index multiple fields for the text index
- Starting in MongoDB 3.2, MongoDB introduces a version 3 of the text index (improved case insensitivity, diacritic insensitivity & additional delimiters for tokenization)
Index types
Text Indexes - example
db.articles.insert(
[
{ _id: 1, subject: "coffee", author: "xyz", views: 50 },
{ _id: 2, subject: "Coffee Shopping", author: "efg", views: 5 },
{ _id: 3, subject: "Baking a cake", author: "abc", views: 90 },
{ _id: 4, subject: "baking", author: "xyz", views: 100 },
{ _id: 5, subject: "Café Con Leche", author: "abc", views: 200 },
{ _id: 6, subject: "Сырники", author: "jkl", views: 80 },
{ _id: 7, subject: "coffee and cream", author: "efg", views: 10 },
{ _id: 8, subject: "Cafe con Leche", author: "xyz", views: 10 }
]
)
db.articles.createIndex( { subject: "text" } )Index types
Text Indexes - example
# Search string of coffee
db.articles.find( { $text: { $search: "coffee" } } )
# Search string of three terms delimited by space, "bake coffee cake"
db.articles.find( { $text: { $search: "bake coffee cake" } } )
# Searches for the phrase coffee shop
db.articles.find( { $text: { $search: "\"coffee shop\"" } } )
# Searches for documents that contain the words coffee
# but do not contain the term shop
db.articles.find( { $text: { $search: "coffee -shop" } } )
# The following query specifies es, i.e. Spanish, as the language that
# determines the tokenization, stemming, and stop words
db.articles.find(
{ $text: { $search: "leche", $language: "es" } }
)
# Case sensitive search for the phrase Café Con Leche
db.articles.find( {
$text: { $search: "\"Café Con Leche\"", $caseSensitive: true }
} )
# Diacritic sensitive text search on the term CAFÉ,
# or more precisely the stemmed version of the word
db.articles.find( { $text: { $search: "CAFÉ", $diacriticSensitive: true } } )
Index Properties
Sparse Indexes
Only contain entries for documents that have the indexed field, even if the index field contains a null value
db.scores.createIndex(
{ score: 1 } ,
{ sparse: true }
)Index Properties
Sparse Indexes
# is using the index...
db.scores.find( { score: { $lt: 90 } } )
# is not using the index...
db.scores.find().sort( { score: -1 } )
# you can explicitly specify the index...
db.scores.find().sort( { score: -1 } ).hint( { score: 1 } )db.scores.createIndex(
{ score: 1 } ,
{ sparse: true }
)Index Properties
Partial Indexes (New in version 3.2)
Only index the documents in a collection that meet a specified filter expression
db.restaurants.createIndex(
{ cuisine: 1, name: 1 },
{ partialFilterExpression: { rating: { $gt: 5 } } }
)Index Properties
Partial Indexes (New in version 3.2)
db.restaurants.createIndex(
{ cuisine: 1, name: 1 },
{ partialFilterExpression: { rating: { $gt: 5 } } }
)# is using the index...
db.restaurants.find( { cuisine: "Italian", rating: { $gte: 8 } } )
# is not using the index...
db.restaurants.find( { cuisine: "Italian", rating: { $lt: 8 } } )
db.restaurants.find( { cuisine: "Italian" } )Partial indexes offer a superset of the functionality of sparse indexes. If you are using MongoDB 3.2 or later, partial indexes should be preferred over sparse indexes.
Index Properties
Unique Indexes
Reject duplicate values for the indexed field
db.members.createIndex(
{ groupNumber: 1, lastname: 1, firstname: 1 },
{ unique: true }
)Unique Partial Indexes - New in version 3.2.
If you specify both the partialFilterExpression and a unique constraint, the unique constraint only applies to the documents that meet the filter expression.
Index Properties
TTL Indexes (Time-To-Live)
Automatically remove documents from a collection after a certain amount of time or at a specific clock time
db.eventlog.createIndex(
{ "lastModifiedDate": 1 },
{ expireAfterSeconds: 3600 }
)Covered Query
An index covers a query when both of the following apply:
- all the fields in the query are part of an index, and
- all the fields returned in the results are in the same index
# index
db.inventory.createIndex( { type: 1, item: 1 } )
# cover query
db.inventory.find(
{ type: "food", item:/^c/ },
{ item: 1, _id: 0 }
)It doesn't work with multi-key and field-embedded indexes
Explain
db.collection.find().explain()Verbose options:
- queryPlanner: default
- executionStats: stats for the winner plan
- allPlansExecution: stats for all candidate plans
Explain
# without index...
db.getCollection('posts').find(
{username: 'kimkardashian', timestamp: {$gte: 1483228800}}
).explain('executionStats'){
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "instagram.posts",
[...]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 49,
"executionTimeMillis" : 2956,
"totalKeysExamined" : 0,
"totalDocsExamined" : 2644172,
[...]
},
}Explain
# with 2 simple index...
db.getCollection('posts').createIndex({username: 1})
db.getCollection('posts').createIndex({timestamp: -1})
# query
db.getCollection('posts').find(
{username: 'kimkardashian', timestamp: {$gte: 1483228800}}
).explain('executionStats'){
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "instagram.posts",
[...]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 49,
"executionTimeMillis" : 38,
"totalKeysExamined" : 3670,
"totalDocsExamined" : 3670,
[...]
},
}Explain
# with a compound index...
db.getCollection('posts').createIndex({username: 1, timestamp: -1})
# query
db.getCollection('posts').find(
{username: 'kimkardashian', timestamp: {$gte: 1483228800}}
).explain('executionStats'){
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "instagram.posts",
[...]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 49,
"executionTimeMillis" : 124,
"totalKeysExamined" : 49,
"totalDocsExamined" : 49,
[...]
},
}Explain
# with a compound index...
db.getCollection('posts').createIndex({username: 1, timestamp: -1})
# with a covered query
db.getCollection('posts').find(
{username: 'kimkardashian', timestamp: {$gte: 1483228800}},
{username: 1, timestamp: 1}
).explain('executionStats'){
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "instagram.posts",
[...]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 49,
"executionTimeMillis" : 0,
"totalKeysExamined" : 49,
"totalDocsExamined" : 49,
[...]
},
}Not Indexable Queries

Lessons learned
"sometimes you win,
sometimes you learn"

The document model - very important!!
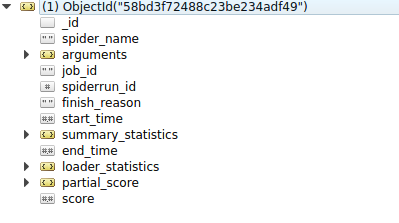
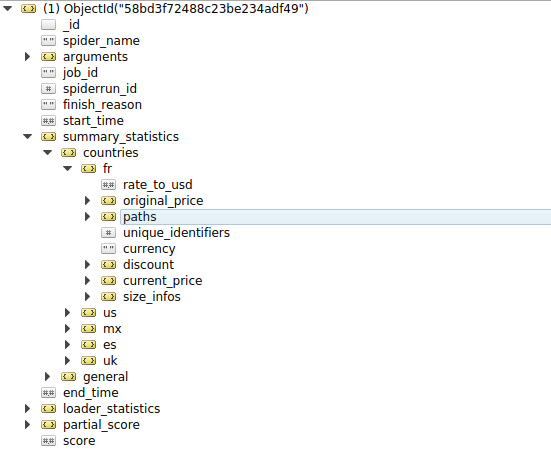
The document model - very important!!
MongoDB as attribute of PostgreSQL...
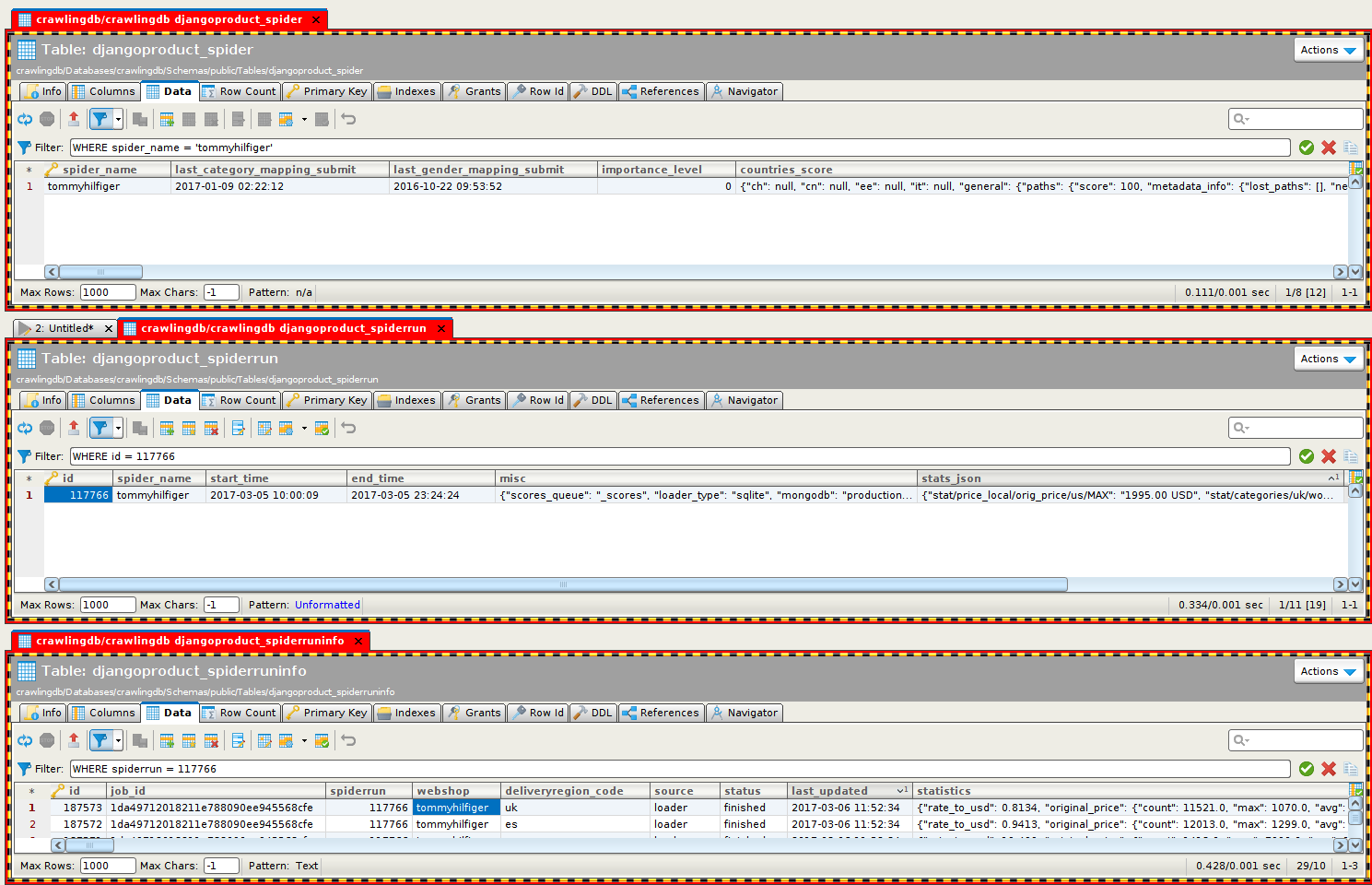
MongoDB in production needs maintenance tasks
