Optimization Methods
for deep neural networks
Table of Contents
- Artificial Intelligence
- Machine Learning
-
Neural Networks
- Finding Optimal Parameters
-
Deep Learning
- Representation Learning
- Large Networks
- Challenges
AI & ML
-
Artificial Intelligence is the intelligence demonstrated by machines or robots, as opposed to the natural intelligence displayed by humans or animals.
-
Machine Learning is a subset of AI that utilizes advanced statistical techniques to enable computing systems to improve at tasks with experience over time.
AI & ML
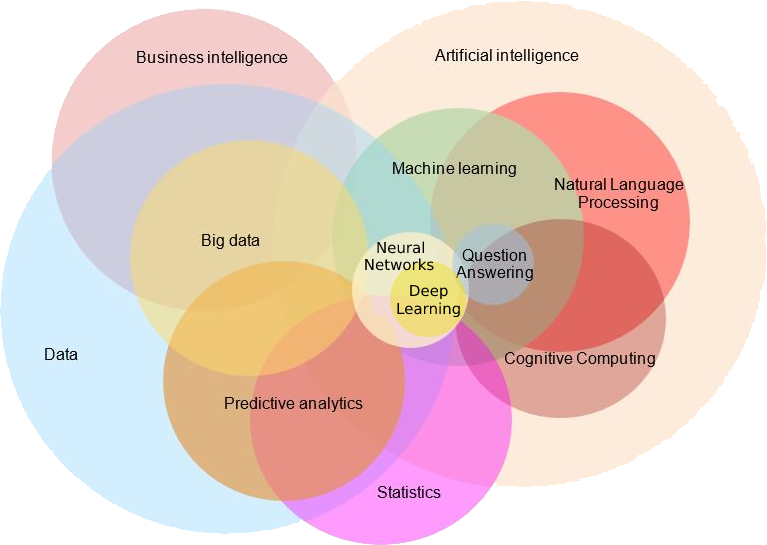
Neural Networks
Artificial Neuron
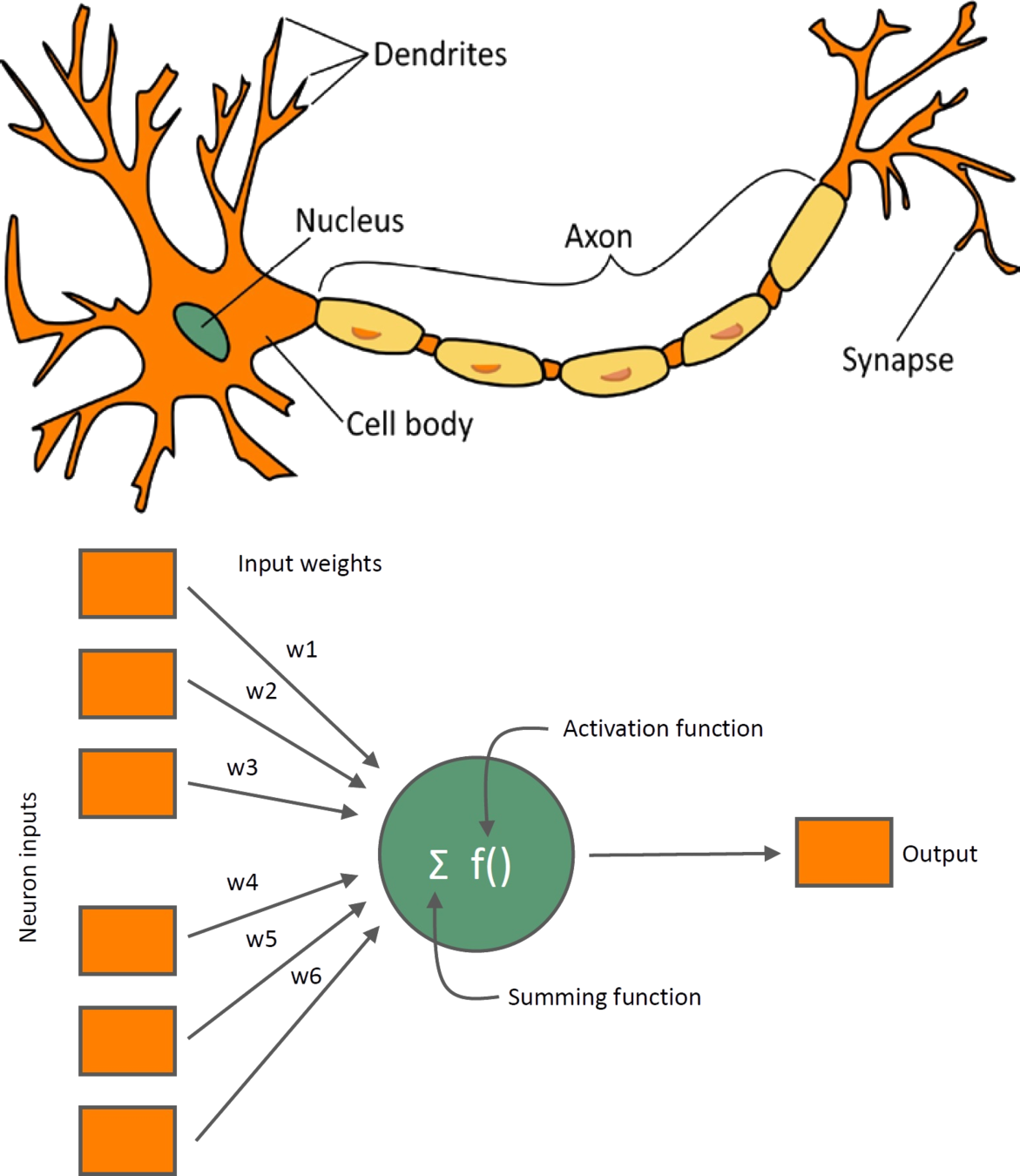
- Input vector \(x\)
- Weight vector \(w\)
- Bias variable \(b\)
- Nonlinear function \(f(x)\)
- Output variable \(y\)
$$y = f(w^T x + b)$$
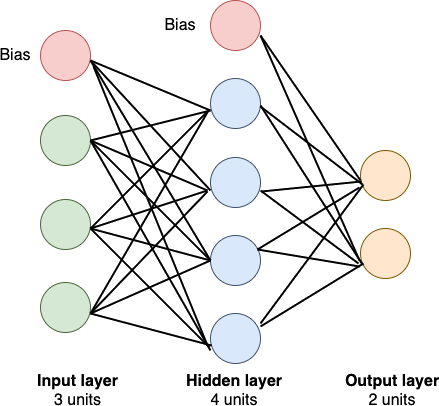
Neural Networks
- A collection of connected artificial neurons.
- Loosely models the neurons in a biological brain.
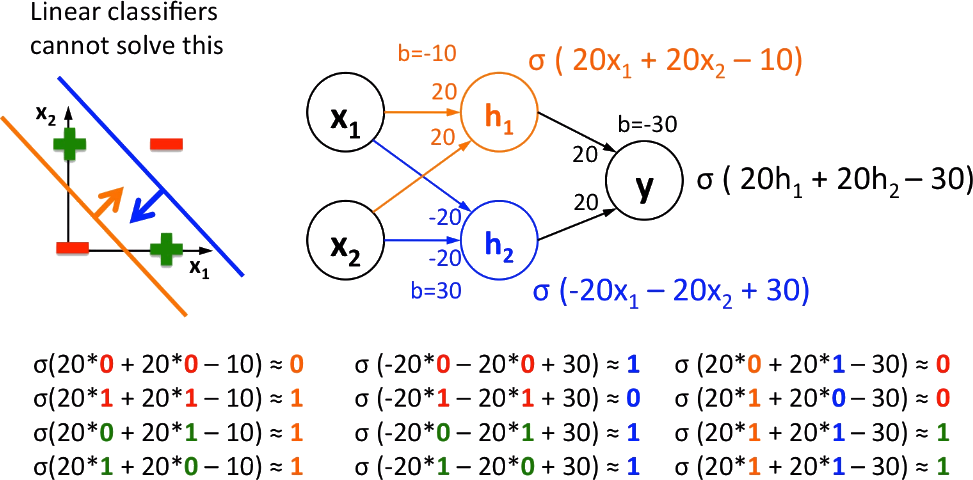
Neural Networks: XOR
Neural Networks: Matrix form

Activation Function
- A function that adds a nonlinearity to the model
- Sigmoid
$$f(x)=\frac{1}{1+e^{-\alpha x}}$$
- Tanh
$$f(x)=tanh(x) = 2\ sigmoid(2x) - 1$$
Loss Function
- A function that computes the distance between the current output of the algorithm and the expected output.
- Mean Squared Error:
$$L(y , \hat y) = \frac{1}{N}\sum_{i=1}^N(y_i - \hat y_i)^2$$
- Mean Absolute Error:
$$L(y , \hat y) = \frac{1}{N}\sum_{i=1}^N|y_i - \hat y_i|$$
Finding Optimal Parameters
If we employ:
- A differentiable activation function
- A differentiable loss function
Then to find the optimal parameters, we can use a first-order gradient-based optimization algorithm.
How to find the gradient of loss function w.r.t parameters?
Backpropagation
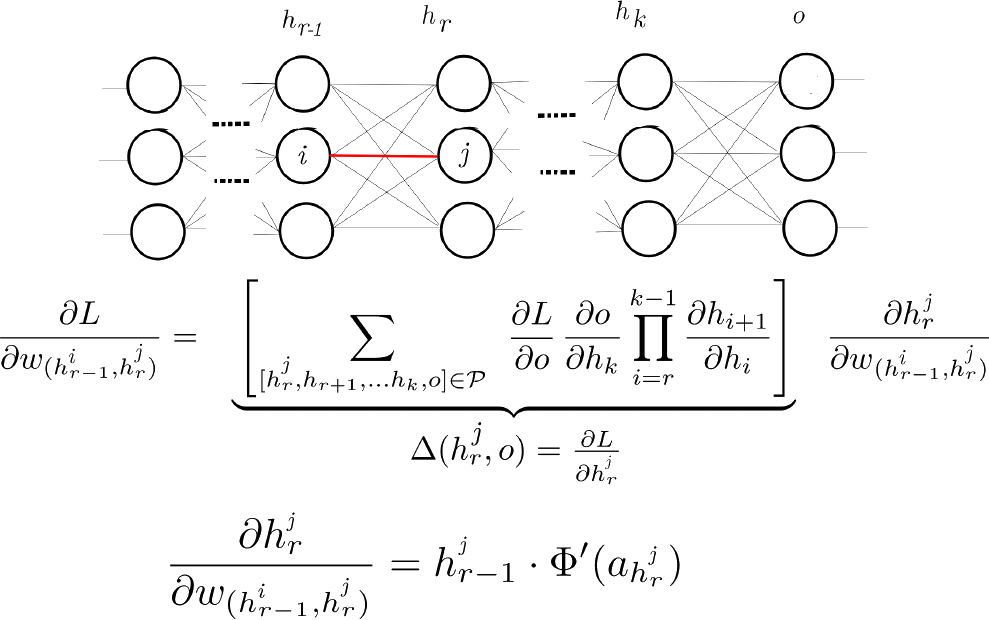
Gradient Descent
$$w^{(new)} = w^{(old)} - \eta \nabla_{w} L(w)$$
- Use the first-order derivative to minimize the loss function
- Gradient Descent algorithm:
- Momentum
$$\begin{aligned} v_t &= \gamma v_{t-1} + \eta \nabla_{w} L(w) \\ w^{(new)} &= w^{(old)} - v_t \end{aligned}$$
Gradient Descent
- Adaptive Moment Estimation (Adam):
$$\begin{aligned} g_t &= \nabla_{w_t} L(w_t)\\ m_t &= \beta_1 m_{t-1} + (1 - \beta_1) g_t \\ v_t &= \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 \\ w^{(new)} &= w^{(old)} - \dfrac{\eta}{\sqrt{\hat{v}^{(old)}} + \epsilon} \hat{m}^{(old)} \end{aligned}$$
Second-Order Optimizers
- Broyden–Fletcher–Goldfarb–Shanno algorithm (BFGS)
- Approximates the Hessian matrix of the loss function
- Limited Memory BFGS algorithm (LBFGS)
Deep Learning
Representation Learning
Representation Learning
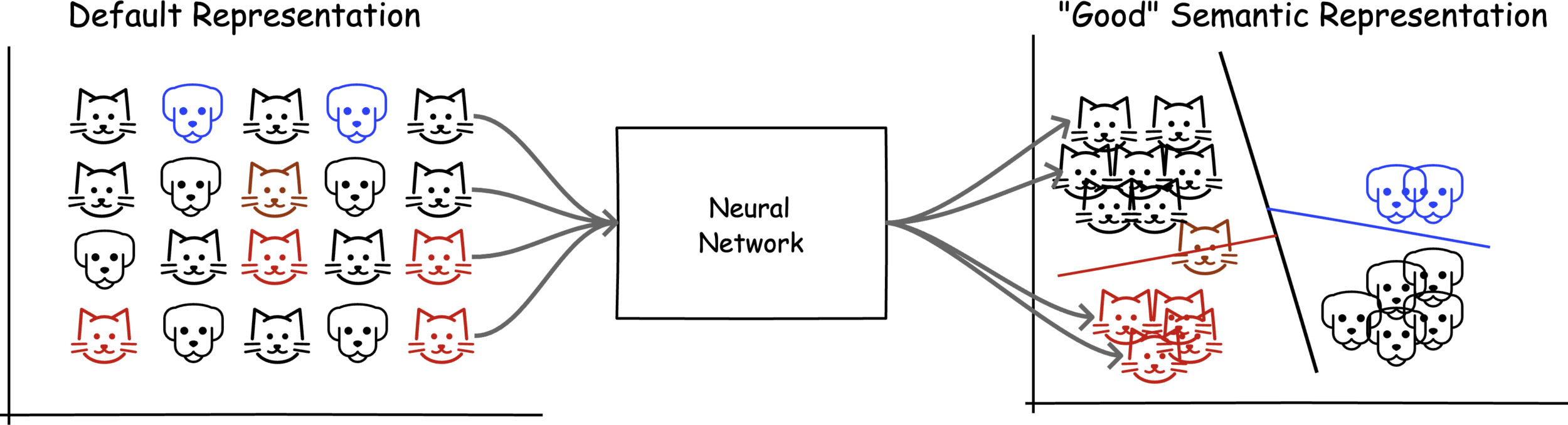
Representation Learning
- Convolutional Neural Networks
- ResNet
- VGG
- Recurrent Neural Networks
- LSTM
- GRU
Large Networks
| Task | Dataset | Architecture | # of params |
|---|---|---|---|
| Language Modelling | WikiText-103 | GLM-XXLarge | 10B |
| Machine Translation | WMT2014 French-English | GPT-3 | 175B |
| Image Classification | ImageNet | ViT-MoE-15B | 14.7B |
| Object Detection | COCO | YOLO-V3 | 65M |
Challenges
-
Computationally Expensive
-
Use more efficient optimizers, momentum, adam, etc.
-
-
Vanishing & Exploding Gradients
- Use better activation functions
- Develop new architectures