族語資料再延伸
鏈結開放資料的族語現況
王文岳 Allen Wang
Wikidata Taiwan
王文岳
- Wikidata Taiwan 共同發起人
- 立法院開放國會第一屆委員
- 前台灣維基媒體協會秘書長
- 李梅樹紀念館資訊組召集人
- 國家文化記憶庫社群經營研究:資訊技術協力

你有沒有想過我們做族語這麼久
但電腦可能根本不認識族語?
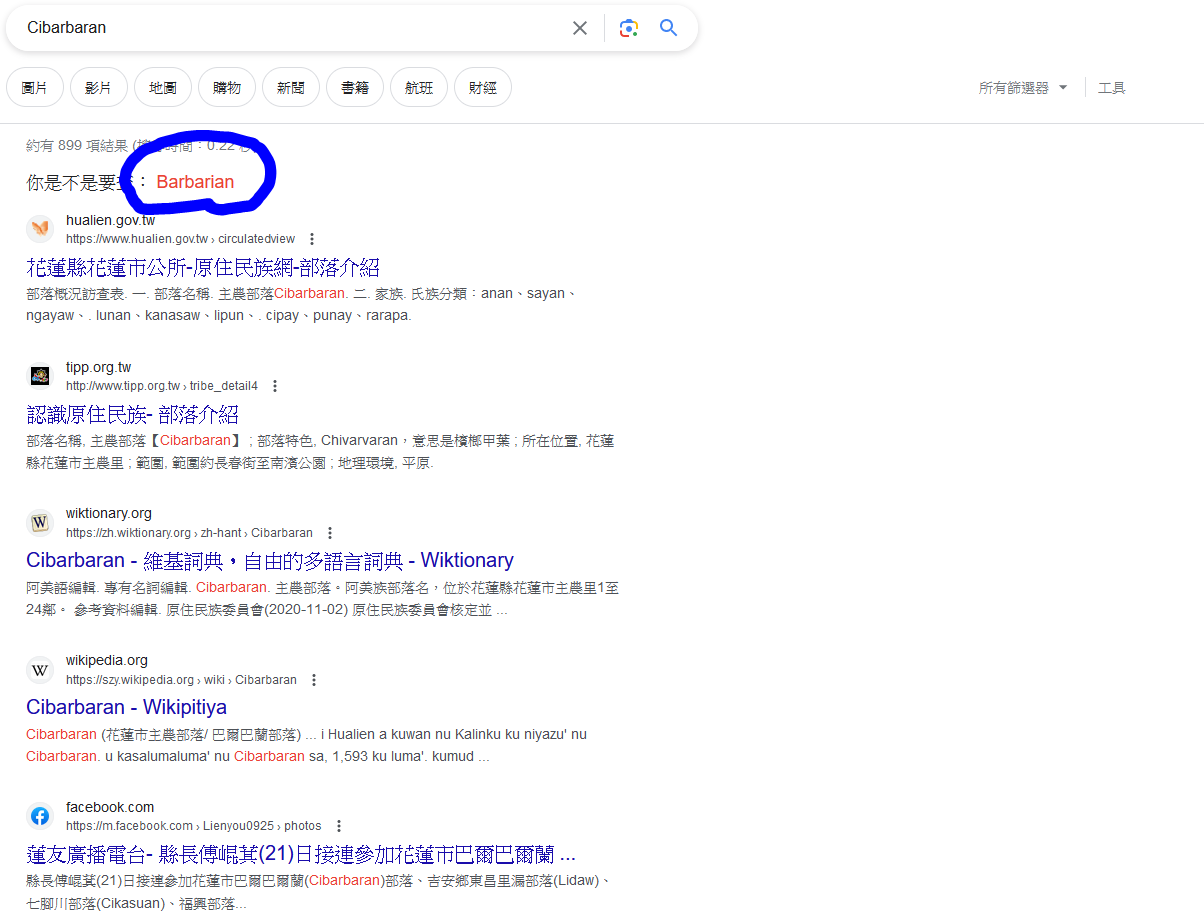

其實電腦對於族語的搜尋
多數還停留在全文檢索的概念
電腦還不認識族語
為什麼我們需要讓電腦認識族語?
內容
人
我們常說找資料真的是人在找資料嗎?
內容
Content
人
People
數位時代下內容流通
後設資料
Metadata
搜尋引擎/機器
Search Engine/Bot
搜尋行為/資料存取
人為編寫/機器生成
或是你也可以問 AI 就好
但是族語有 AI 可以問嗎?
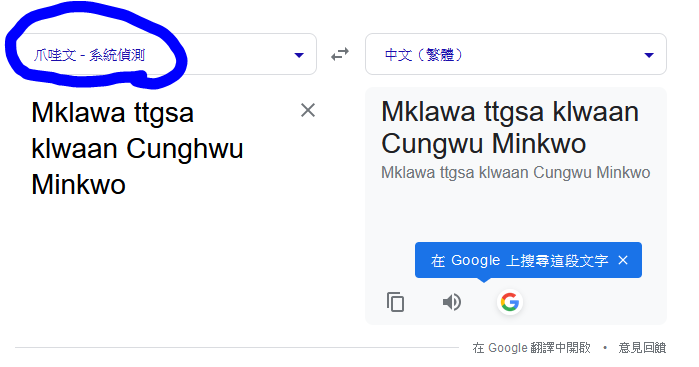
用華語查到族語
用族語查到族語
用族語查到其他語
建構族語使用的完整生態系
Wikidata.org
是美國維基媒體基金會繼維基共享資源後
第一個跨語言專案

Q
Q
P
P
P
Q
P
P
P
在 Wikidata 裡面我們不再用散文的方式在紀錄資料
而是改變成為單字、片語的方式進行
讓跨語言的資料只需要翻譯單詞或片語
就能用最低的成本做到多語言呈現


trv
tay

szy
中華民國
教育部
教育部
性質
Q697093
P31
Q2269756
Mklawa ttgsa klwaan Cunghwu Minkwo
性質
教育部
Kyo’ikbu
性質
教育部
trv
tay
en
Ministry of Education (R.O.C)
instance of
ministry of education
維基百科基於人類閱讀的需求
使得部分瑣碎資料無法被獨立紀錄與分述


機讀對於關聯的需求更甚
Wikidata 得以收錄更細節更多元的內容
提供基礎資訊的建構


Wikidata 同時透過「亦稱為」一欄
以及多語言欄位
提供跨語言對照以及權威詞彙對照的功能
樂信·瓦旦
- 音界號?
- 樂信·瓦旦? 樂信‧瓦旦?
- 拼寫不同或是各不同語言
- Losing Watan 、樂信·瓦旦
- 不同時期的姓名
- 渡井三郎、日野三郎
語言欄位連結各語言與各通同名稱
並使用唯一識別碼互相溝通
提供權威對照的功能

亦稱為 欄位同時也可以處理單一語言代碼下
多語言、多部落稱呼不同的問題
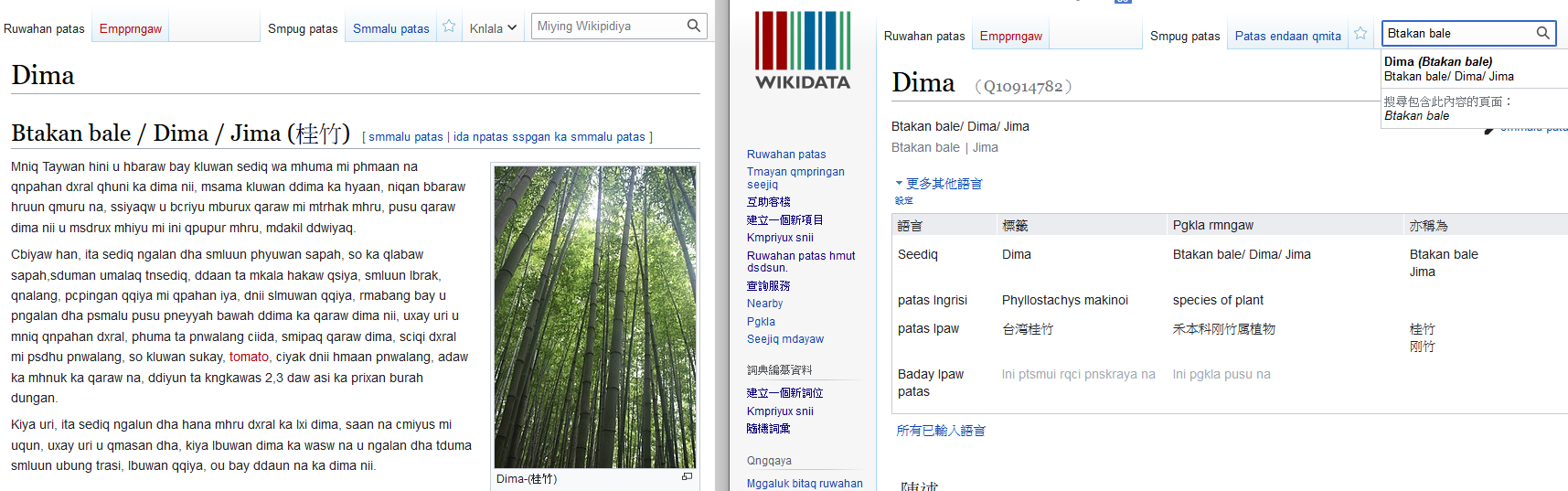
Wikidata 也能用於跨資料庫的檢索!
A資料庫
B資料庫
資料Z-B
資料Z-A
要確定兩者的通同性
就需要進行對照工作
在許多時候我們都可能需要進行資料庫對照
像是資料庫匯入、多資料庫整合等等
當只有兩個資料庫時
對照工作或許是可行的
但是當有數十個甚至更多的資料庫時...
同時對照工作還會牽涉到組織權責問題
大量增加成本跟可能的阻礙
A資料庫
B資料庫
資料Z-B
資料Z-A
加入 Wikidata 做為第三方
各資料庫之間對照只需要滿足與 Wikidata 之間的對照
就能在與其他資料庫進行對照
資料Z-W
QNNNNNNN
Wikidata
B資料庫
OSM
河川代碼
242000
10553609
花蓮溪
Q707891
Wikidata
XXXXX
阿美語/賽德克語/撒奇萊雅語/....
XXXXX
環境/水文/水保資料
XXXXX
文化/交通/觀光資料
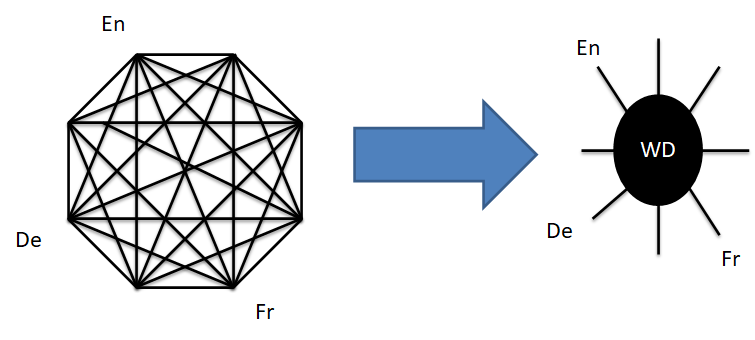
在維基媒體計畫內部
Wikidata 也扮演著多語言/多計畫資料整合對照
導出
應用
對照
跨域檢索
隨著資料的快速擴展
串聯多元資料庫/集將會是資料整合的關鍵

非洲的伊博族也透過 Wikidata 建構伊博語資料集
並正在討論如何應用在未來的新專案「節錄維基百科」
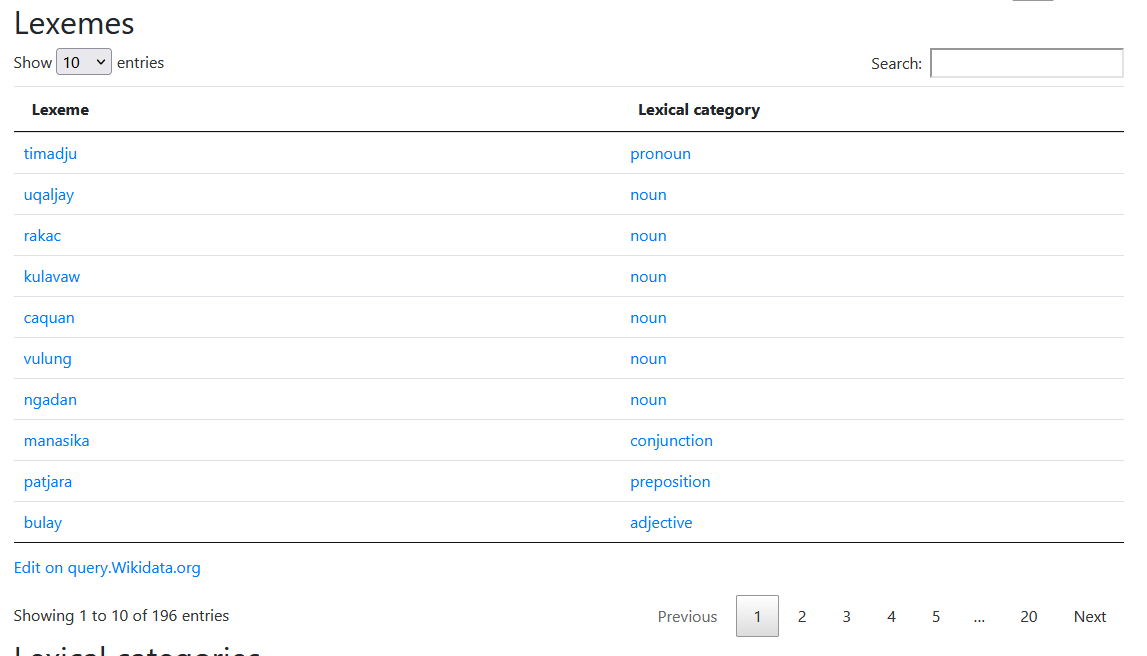
排灣維基用戶組則透過 Wikidata Lexemes 功能
來保存排灣語中各語言的用法
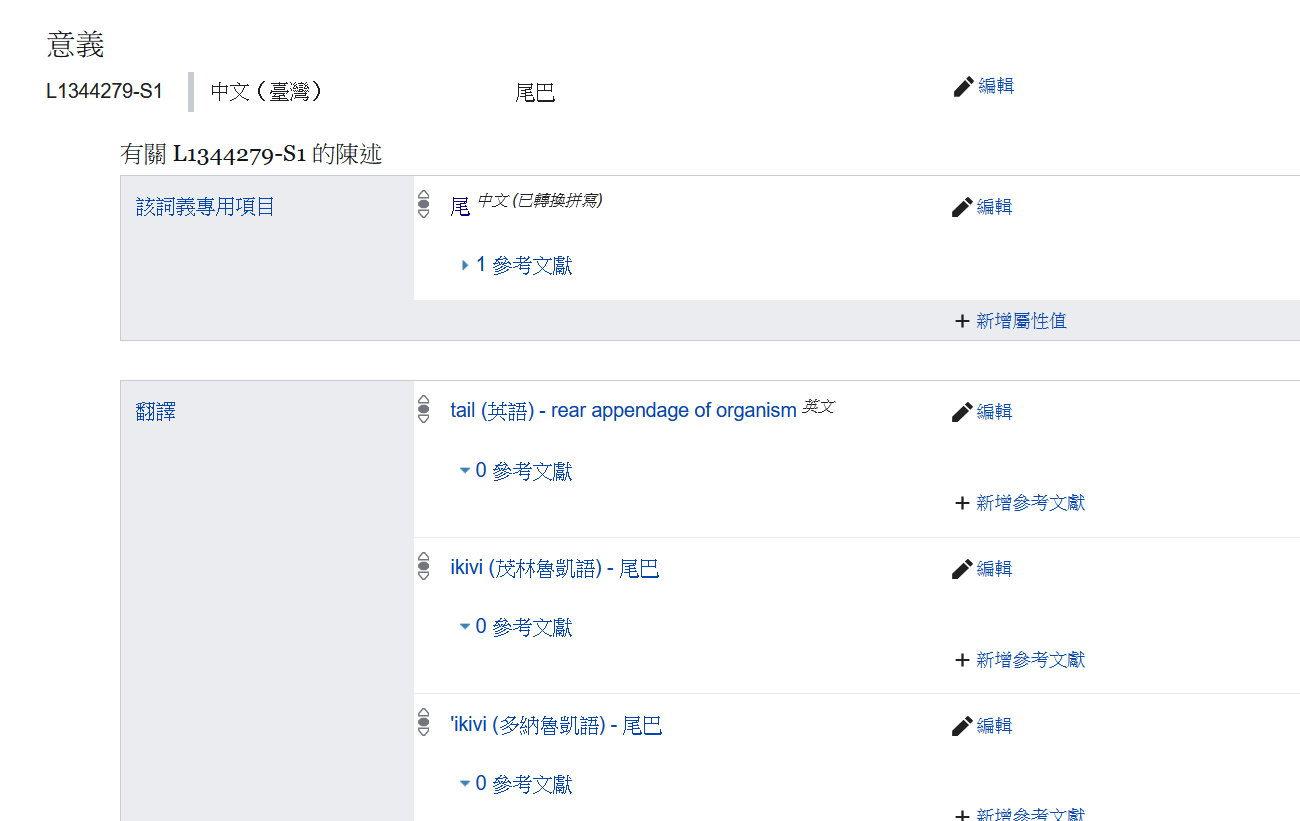
與萬山魯凱社群合作
試做萬山魯凱、茂林魯凱、多納魯凱與英文對譯以及發音錄音
過去我們也曾帶撒奇萊雅社群協助
翻譯 Wikidata 上面各 item 的名稱

Wikidata 人文應用案例

使用 wikidata 做為關鍵字檢索依據


將文本資料庫化後
進行結構化資料的分析與圖像化

結構資料再處理與應用


MoMA 透過 Wikidata 與 Wikipedia 來提供基礎資訊
資料庫不再只服務人
服務機器的資料庫將是趨勢
越來越多資料庫導入機讀特性
在提高閱覽次數的同時
也是改善後續維護的方式
在每天都有1300萬"人"在看維基百科時
同時分別有540萬與快800萬個"機器人"
正看著 Wikidata 與 Wikipedia
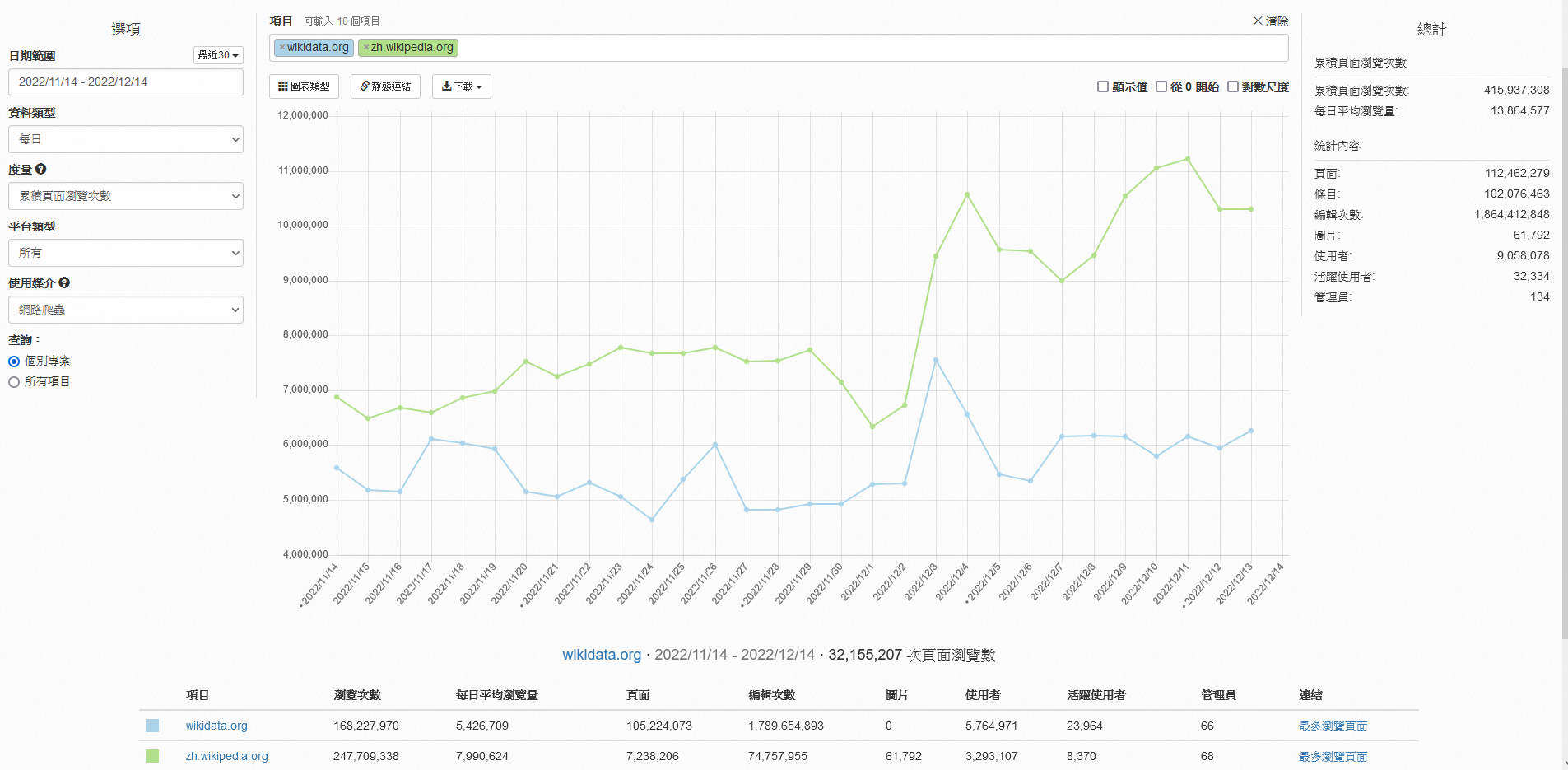
機讀友善可創造
更多轉譯與應用的可能性

除了與人協作以外
更是與機器人協作