Policy Gradients
(aka Como Aprender a Jugar Pong y no Fracasar en el Intento)
Pong
Acciones:
Arriba, Abajo
Recompensas:
+1 cuando si la pelota rebasa al oponente
-1 si la pelota rebasa al agente
Episodio:
Si la pelota rebasa al agente o al oponente 21 veces, el episodio termina

Open Gym AI
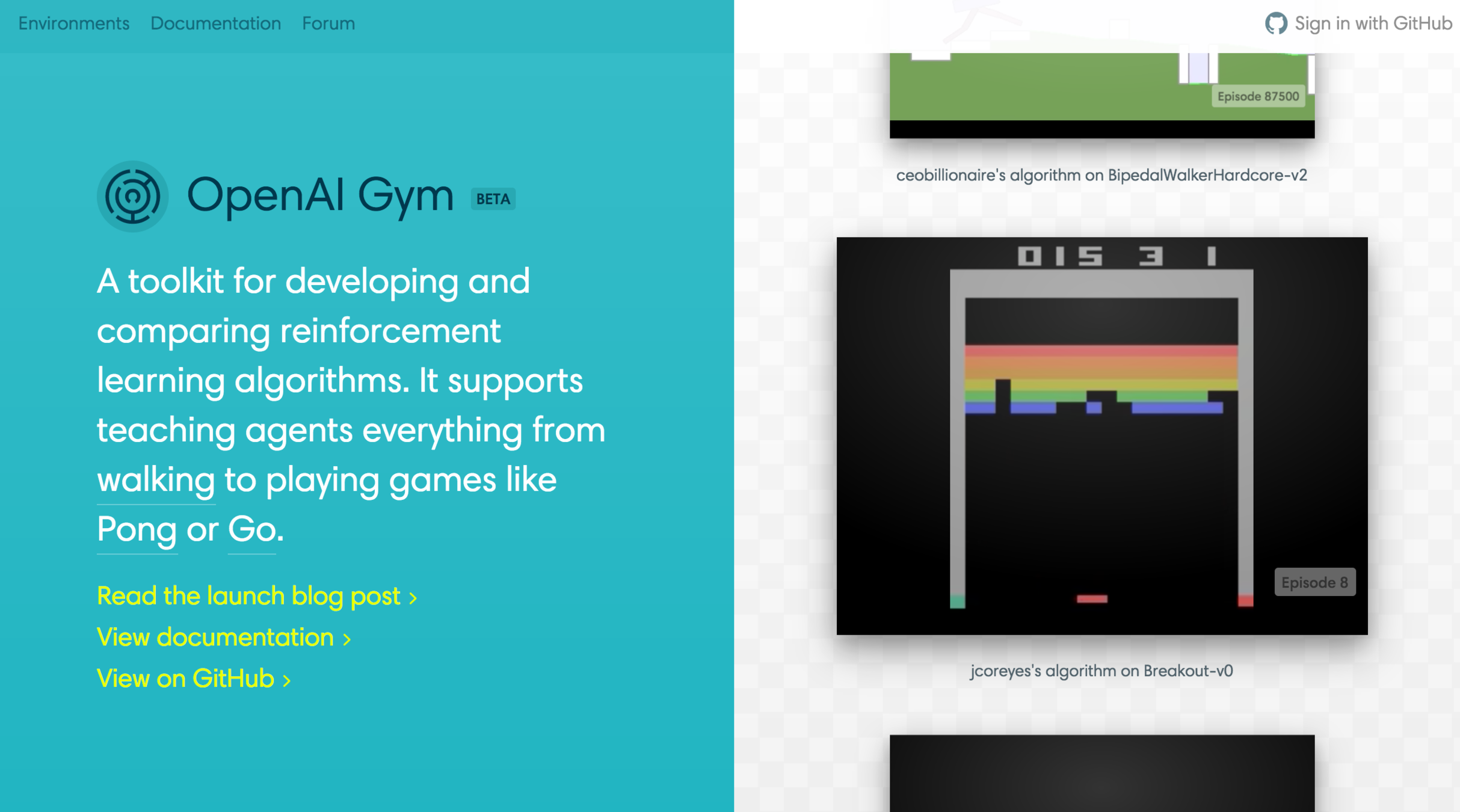
Policy Network
Preprocessing


210\times160\times3\rightarrow 80\times80
\rightarrow
Policy Network
W1:\mathbb{R}^{6400}\rightarrow \mathbb{R}^{200}
W2:\mathbb{R}^{200}\rightarrow \mathbb{R}
ReLU:\mathbb{R}\rightarrow \mathbb{R}^+
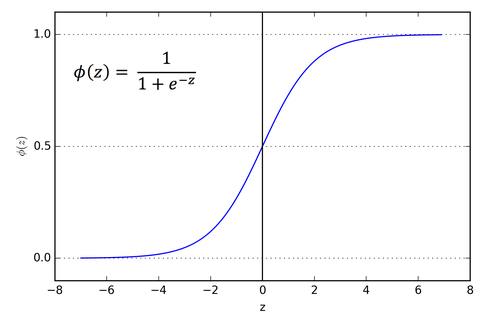
\phi:\mathbb{R}^+\rightarrow [0,1]
Aprendizaje Supervisado
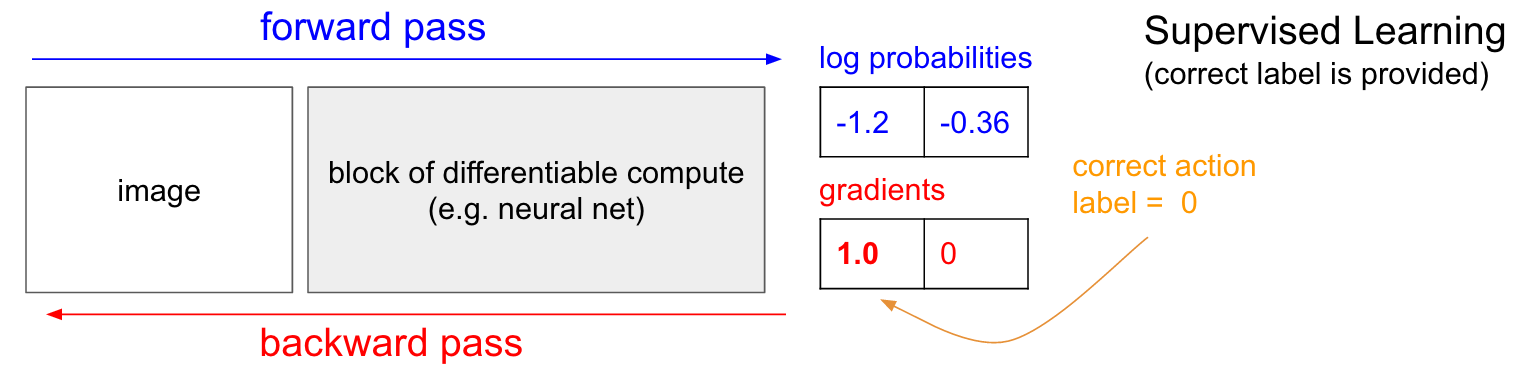
\partial{L_i} / \partial{f_j} = y_{ij} - \sigma(f_j)
L_i = \sum_j y_{ij} \log(\sigma(f_j)) +
(1 - y_{ij}) \log(1 - \sigma(f_j))
Aprendizaje por Refuerzo
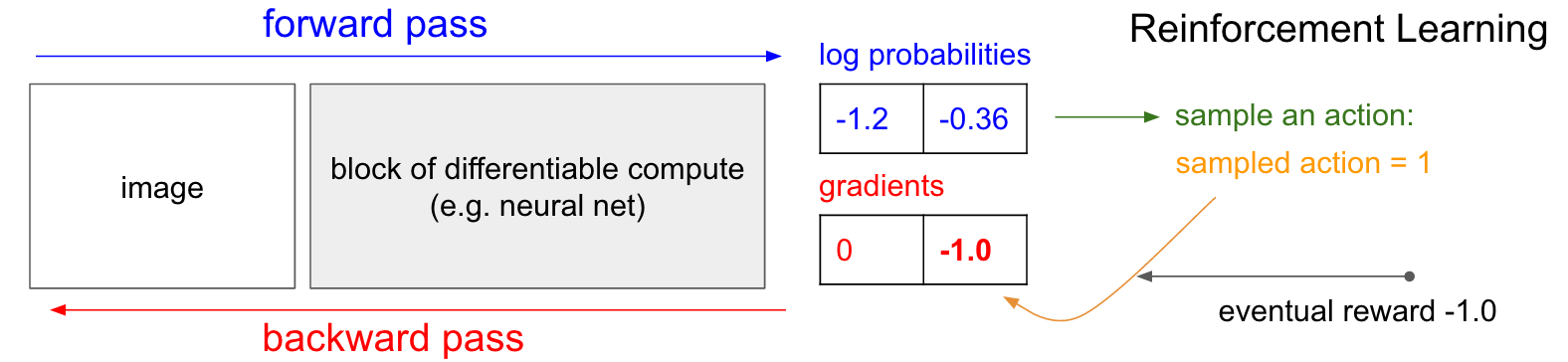
\partial{L_i} / \partial{f_j} = y_{ij} - \sigma(f_j)
L_i = \sum_j y_{ij} \log(\sigma(f_j)) +
(1 - y_{ij}) \log(1 - \sigma(f_j))
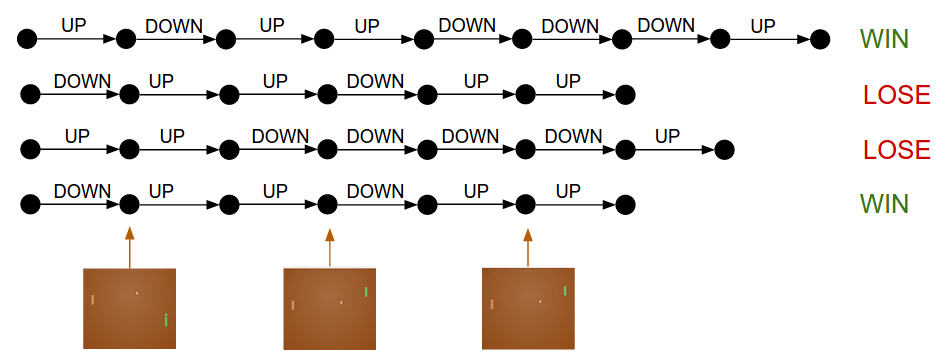
Policy Gradients
Referencias
https://gist.github.com/karpathy/a4166c7fe253700972fcbc77e4ea32c5
http://karpathy.github.io/2016/05/31/rl/
http://cs231n.github.io/neural-networks-2/#losses
Código fuente:
Explicación:
Nota sobre redes neuronales:
Capítulo 13 del libro (Second Edition 2017)
Sutton, R. S., Barto, A. G., Reinforcement Learning: An Introduction. MIT Press, 1998.