Mechanistic Interpretability Reading Group
Amin Mohamadi
Oct 2024
Massive Activations in Large Language Models

Activation?
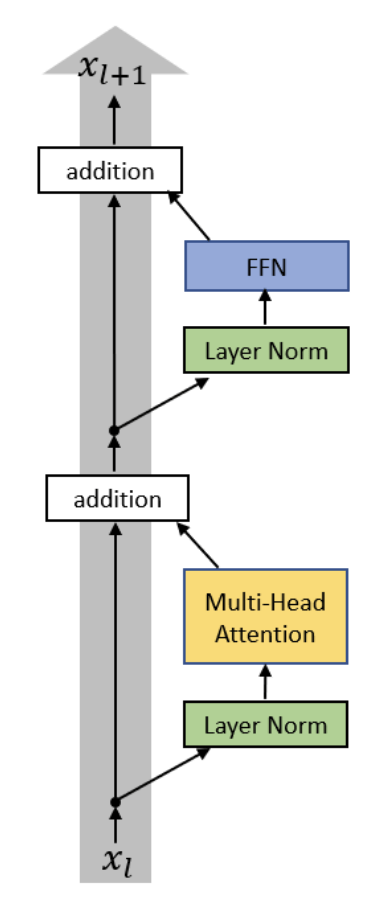
h_{l+1} = h_l + f_l(h_l) \\
h_l \in \mathbb{R}^{T \times d}
Activation?

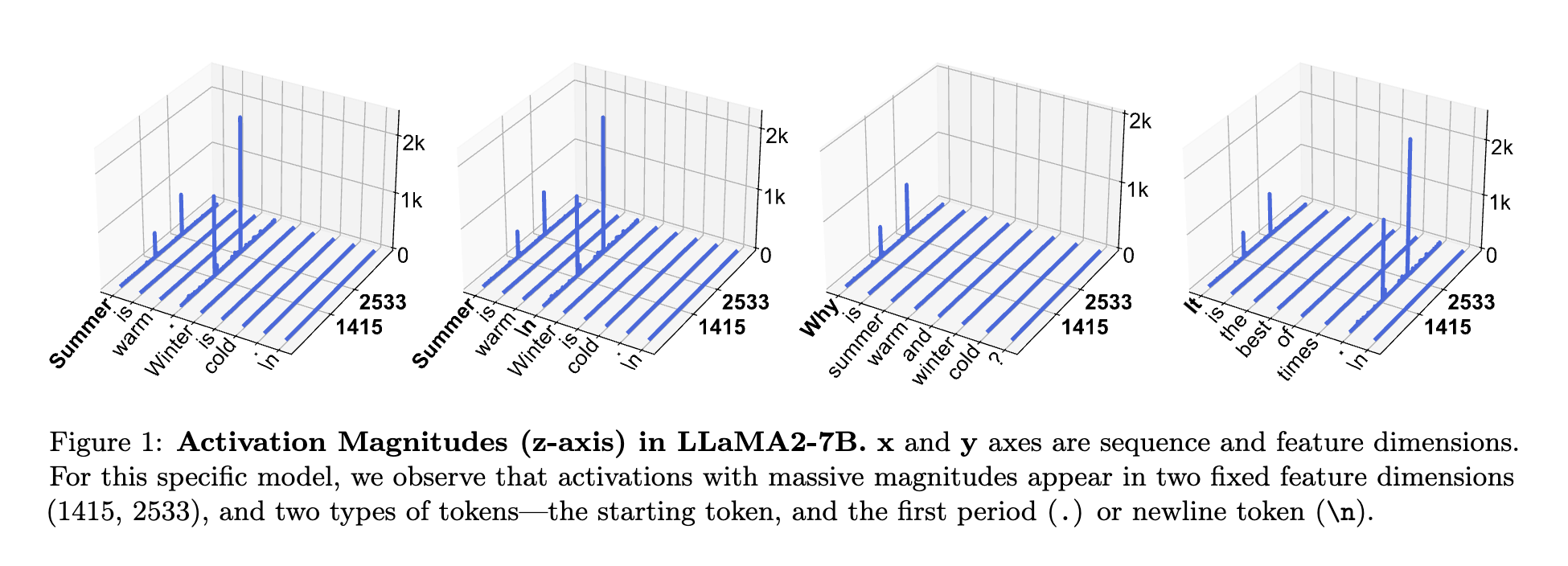
Characters of Massive Activations
- Input Agnostic! (fixed coordinates)
- >1000x times larger than median activation magnitude.
- <10 massive activations among millions of them.
- (Mostly) appear on the first token.

Which Layers?
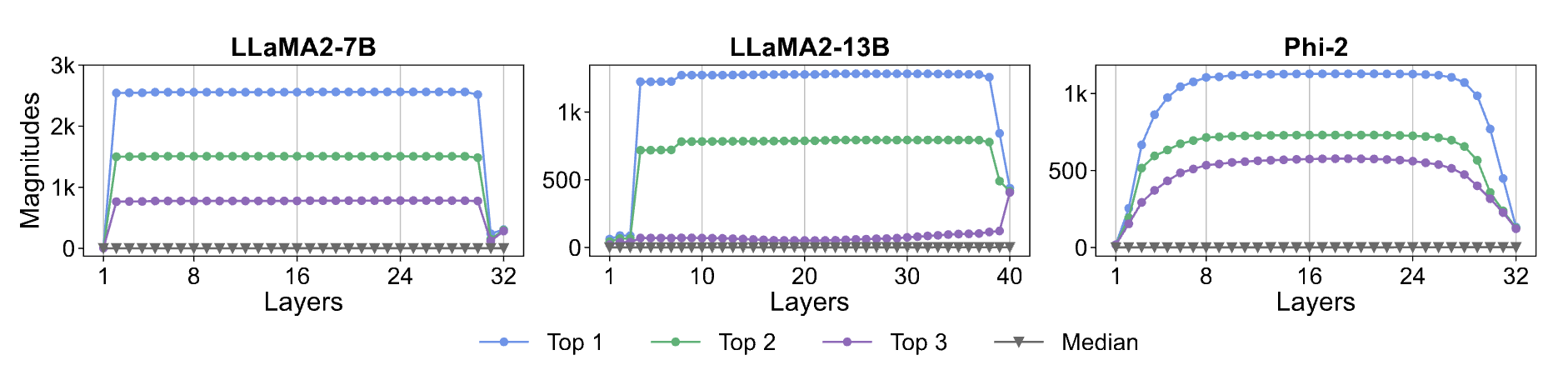
- Typically appear in the early layers.
- Stay roughly constant throughout the residual stream.
- (Somehow) get cancelled during the final layers.
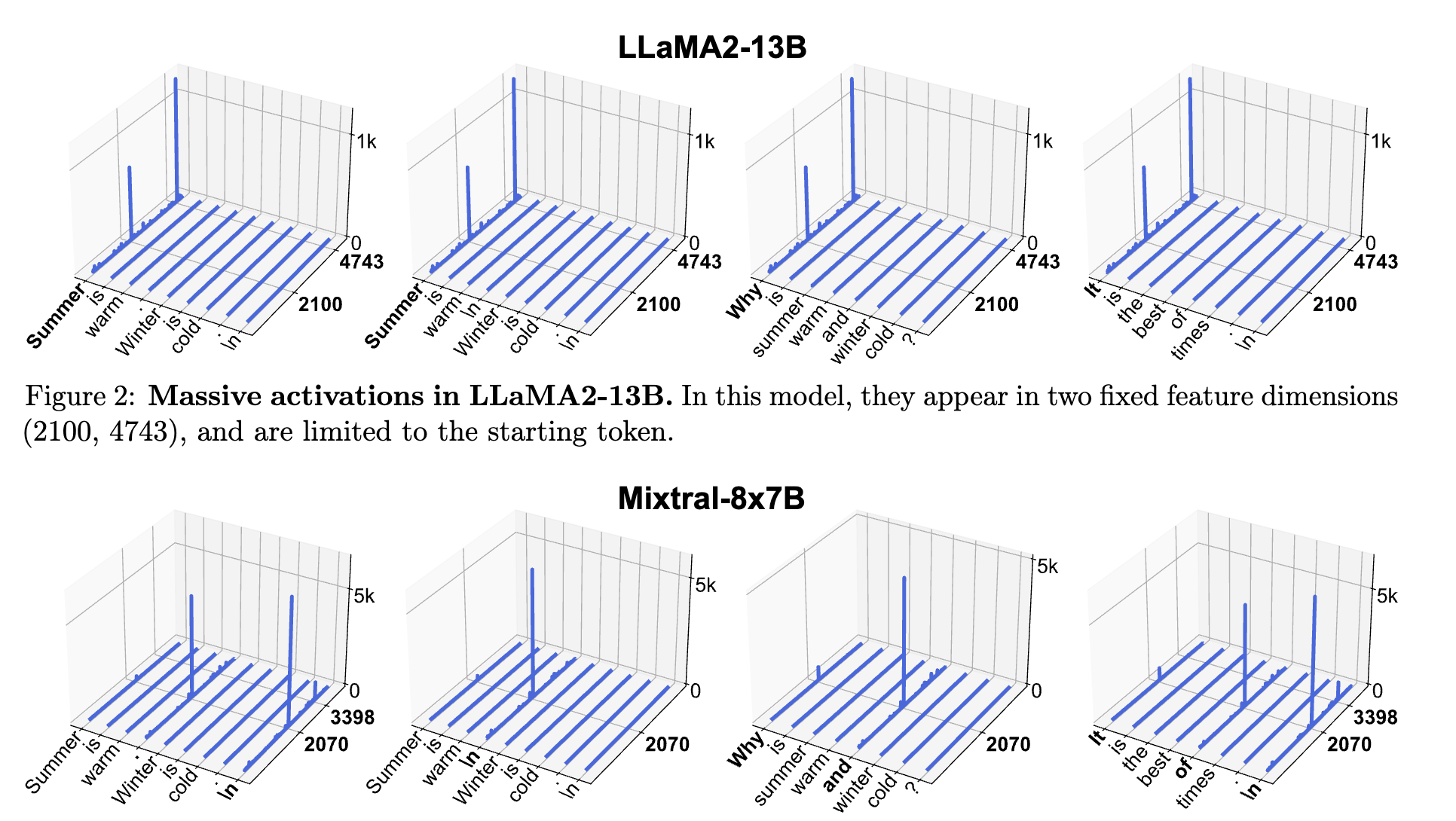
Which dimensions?
- Activation: \( h_l \in \mathbb{R}^{T \times D} \)
- Along features: a few fixed dimensions
- Along tokens:
- Starting token only (GPT2)
- Starting token and first delimiter token (LLaMA2-7B)
- Starting token and some other "semantically weak" tokens (LLaMA2-70B, Phi-2)
Massive Activations as Biases

- Algorithm:
- Change the value of massive activation at the first appearance (patch the activation)
- Feed the altered hidden state to the rest of the blocks as usual
- Evaluate the perplexity (WikiText, C4, ...)
Massive Activations as Biases

- Elimination of only a few massive activations can drastically change the performance.
- Fixing them to their empirical mean evaluated on many sentences has negligible impact.
Why these tokens?
- (Maybe) First token is always visible.
- (Maybe) Existence of massive features affects attention patterns, better to put them on "semantically meaningless" tokens.
- (Maybe) Semantic meanings might have already been transferred to other positions.
- ...
Effects on Attention
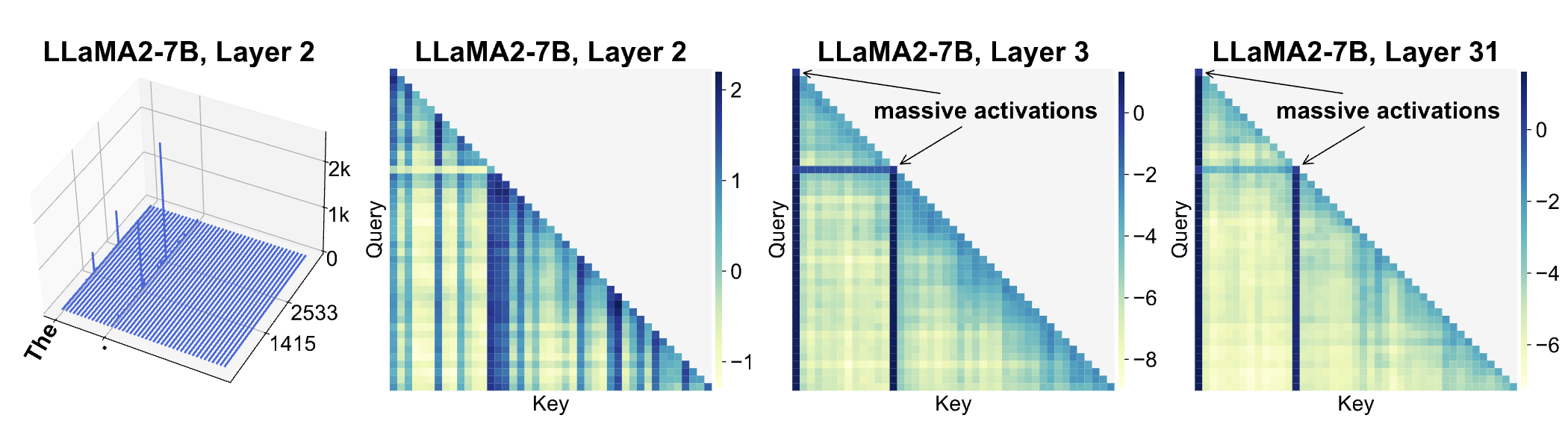
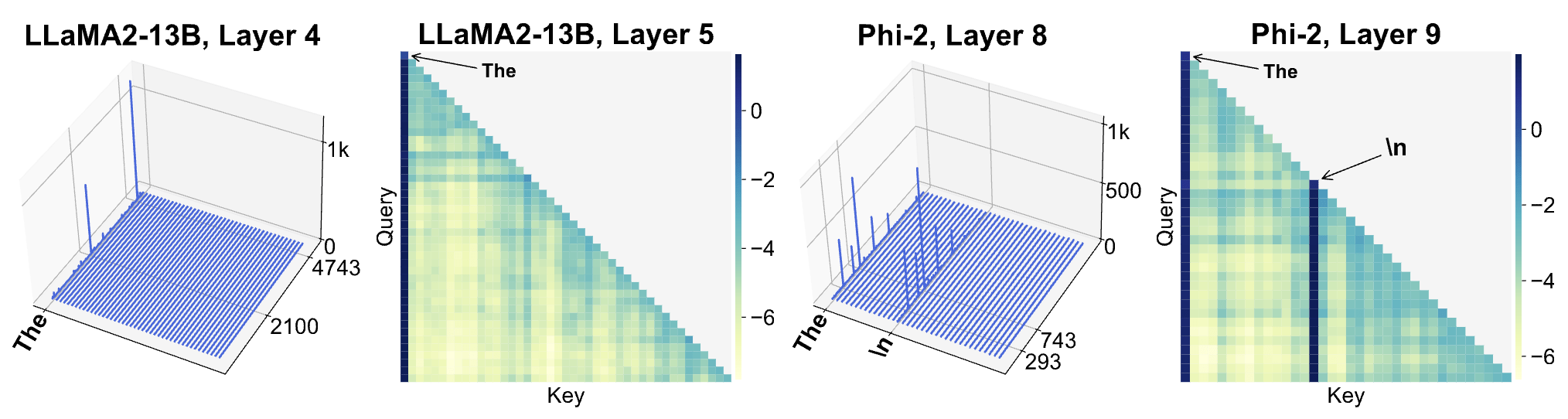
Effects on Attention
What is an attention sink?
- A surprisingly large amount of attention score is allocated to the initial tokens, irrespective of their relevance to the language modeling task. We term these tokens “attention sinks". Despite their lack of semantic significance, they collect significant attention scores.
"Efficient Streaming Language Models with Attention Sinks"
Xiao et al. 2023.
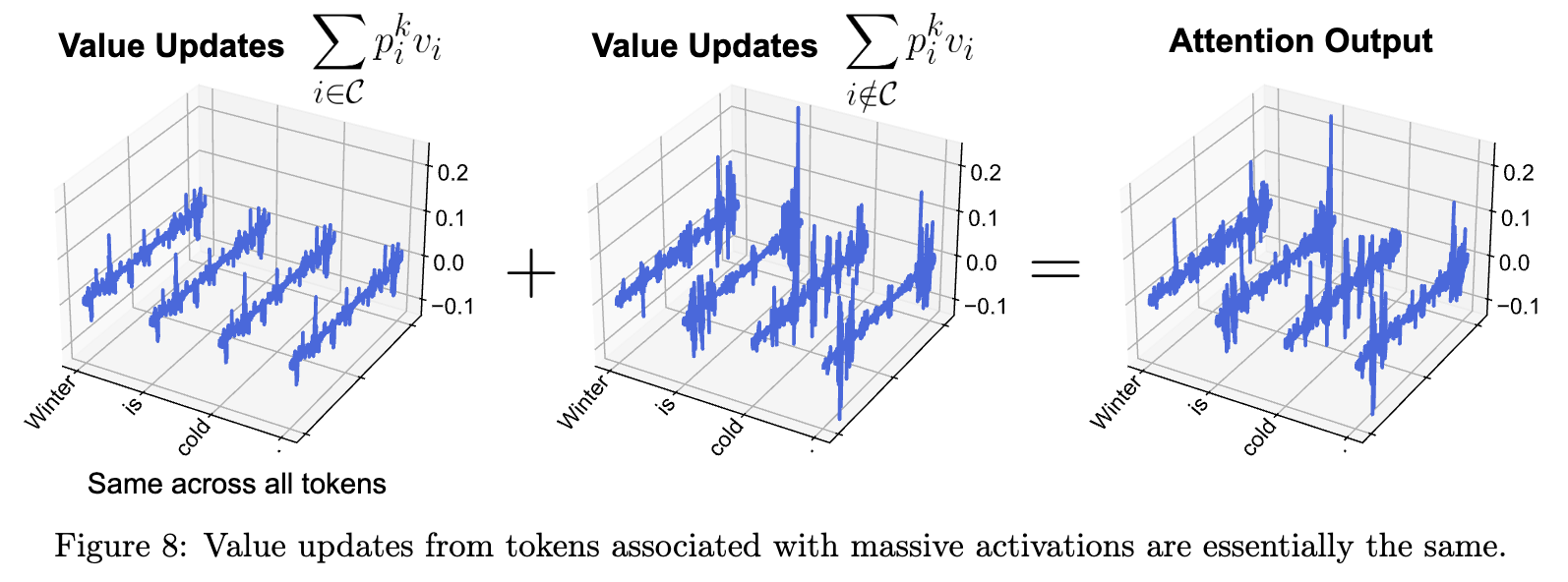
Massive Activations as Implicit Attention Biases
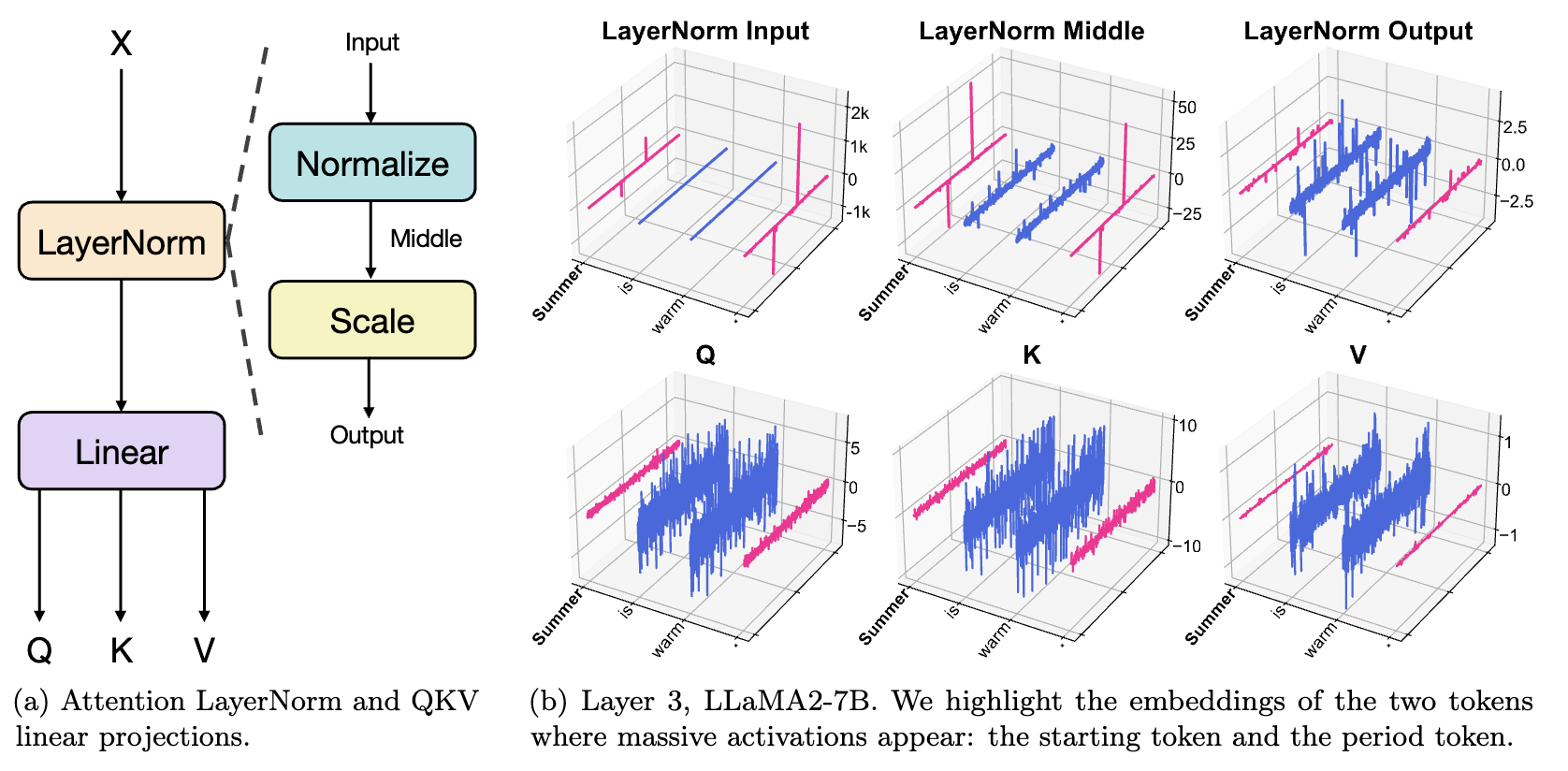
Massive Activations as Implicit Attention Biases
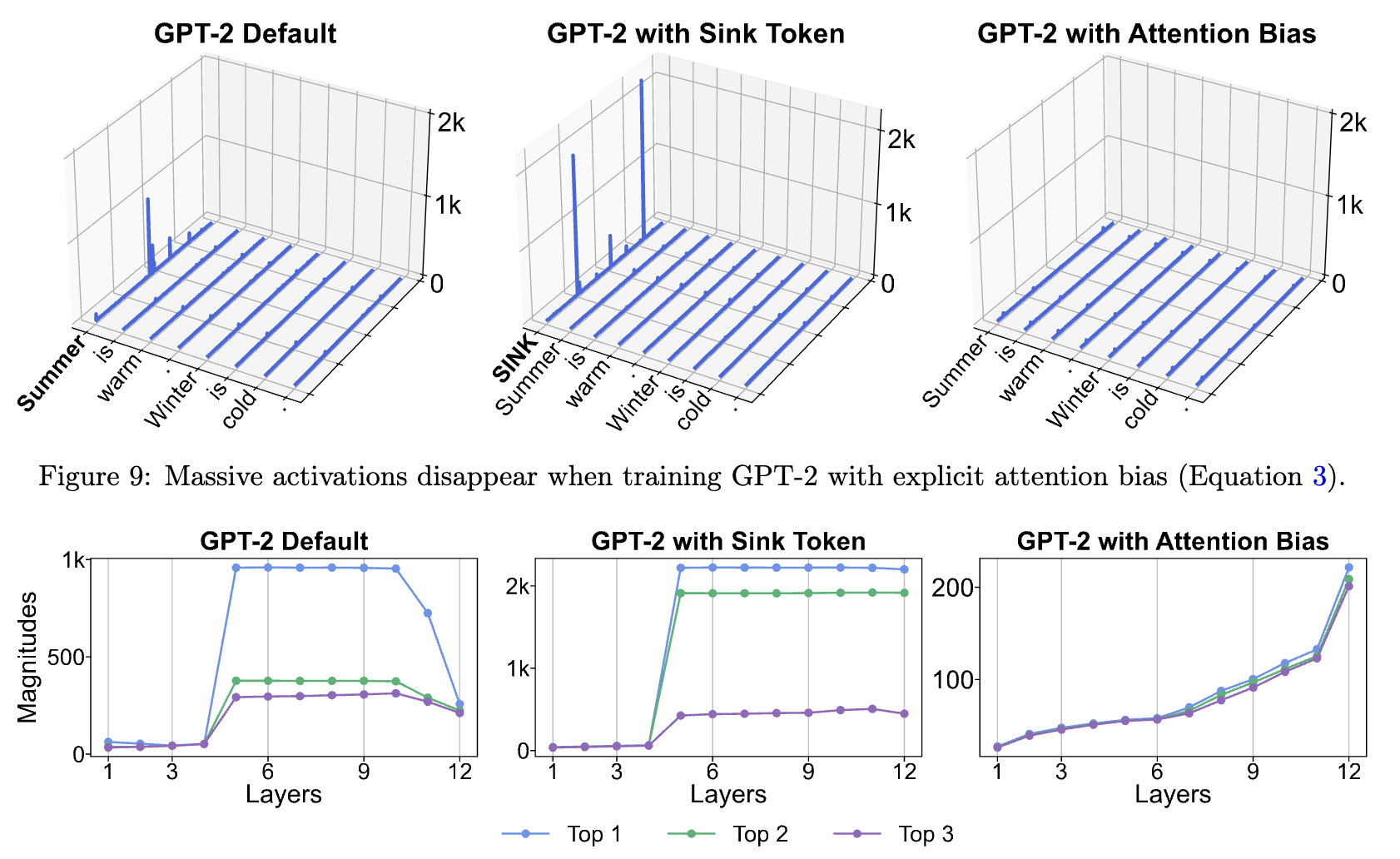
Explicit Attention Biases Eliminate Massive Activations
- Massive activation seems to be implementing some form of bias in attention.
- Let's add learnable bias dimensions to \(k, v\).
\text{Attention}(Q, K, V; \, \mathbf{k}', \mathbf{v}') =
\text{softmax}\left( \frac{Q \left[K^T \, \mathbf{k}'\right]}{\sqrt{d}} \right)
\begin{bmatrix}
V \\
\mathbf{v}'^T
\end{bmatrix}
Is It A Language Thing?
Is It A Language Thing?

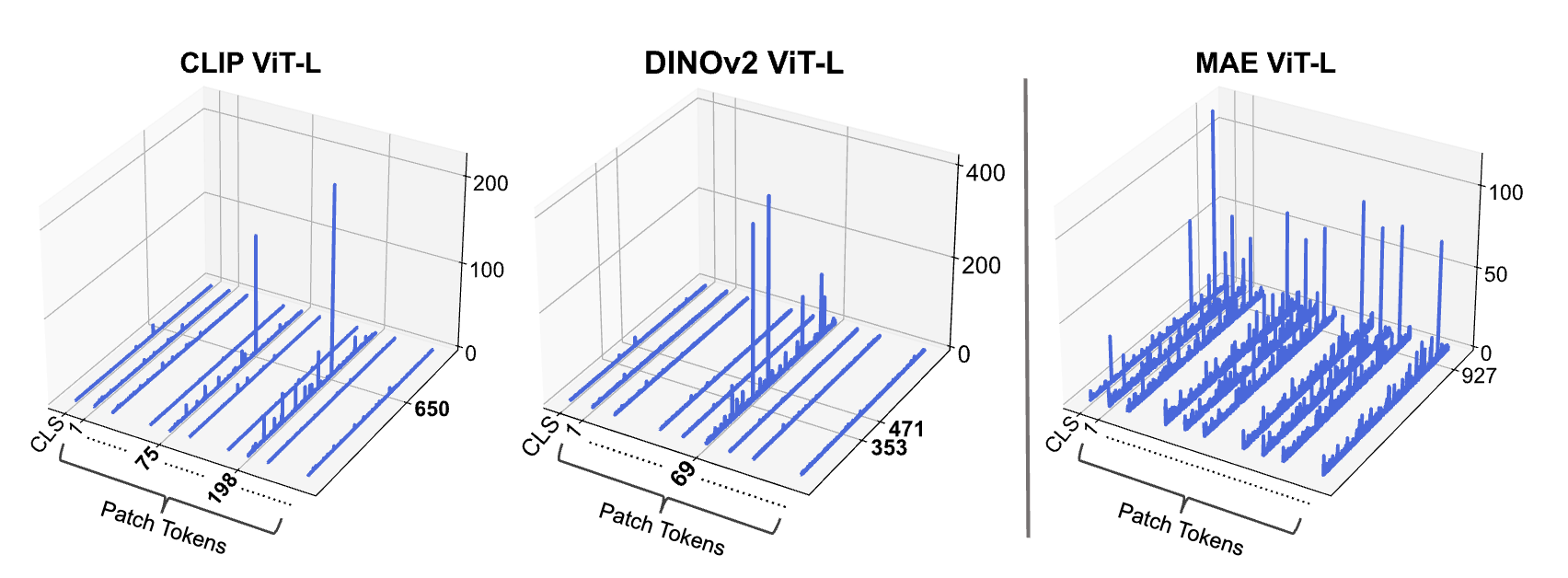
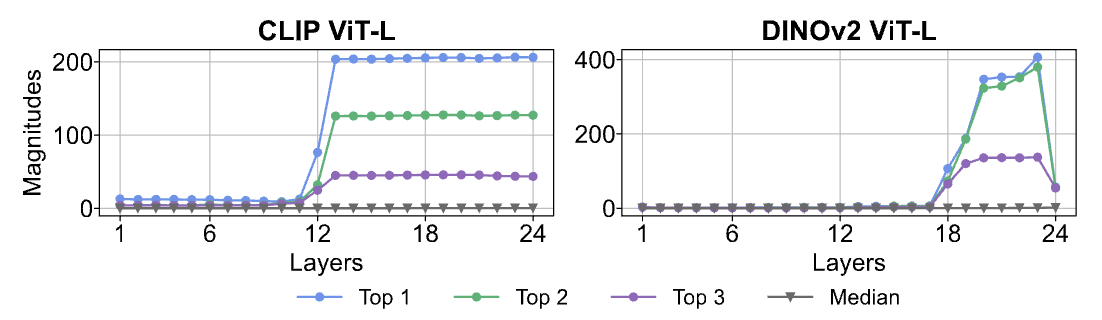
- Massive activation are present in many, but not all ViTs.
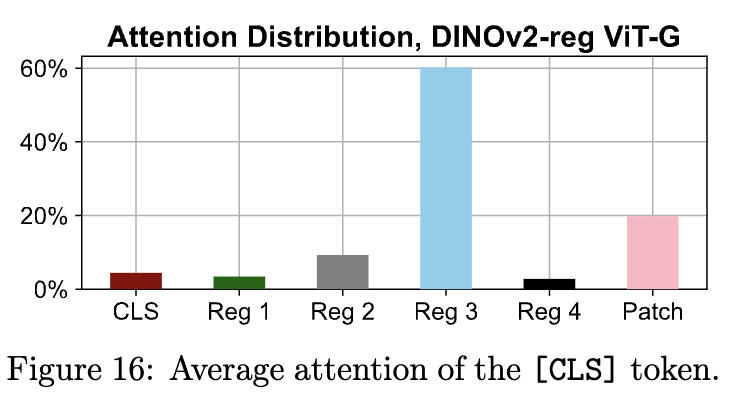
- When available, massive activations typically show up in "register" tokens (patches).
- Similar to LLMs, they significantly affect the attention map.
My Questions
- Why do massive activations exist? Is this an expressivity problem in transformers, or is it an optimization-related issue?
- How do transformers store information about "how to cancel massive activations"?
- Does Explicit Attention Bias solve the problem, or does it "hide" it?