Archiving Talk
Our needs
- Storing a diverse corpus of audio, video, pictures, books and text.
- Digital archive exists since 1985 but contains data from before. It started with the original Macintosh.
- We have data and software that:
- Is programmed in strange programming languages.
- Uses niche databases.
- Our system needs to handle a variety of Indic languages and scripts.
Jnanam DB
- ~16 years ago we started Jnanam DB
- We sent a monk to university to learn how to organize information. This was designed after he came back.
- Based on the Dublin Core.
- Objectives:
- Minimize the amount of joins.
- Able to store anything with the current schema.
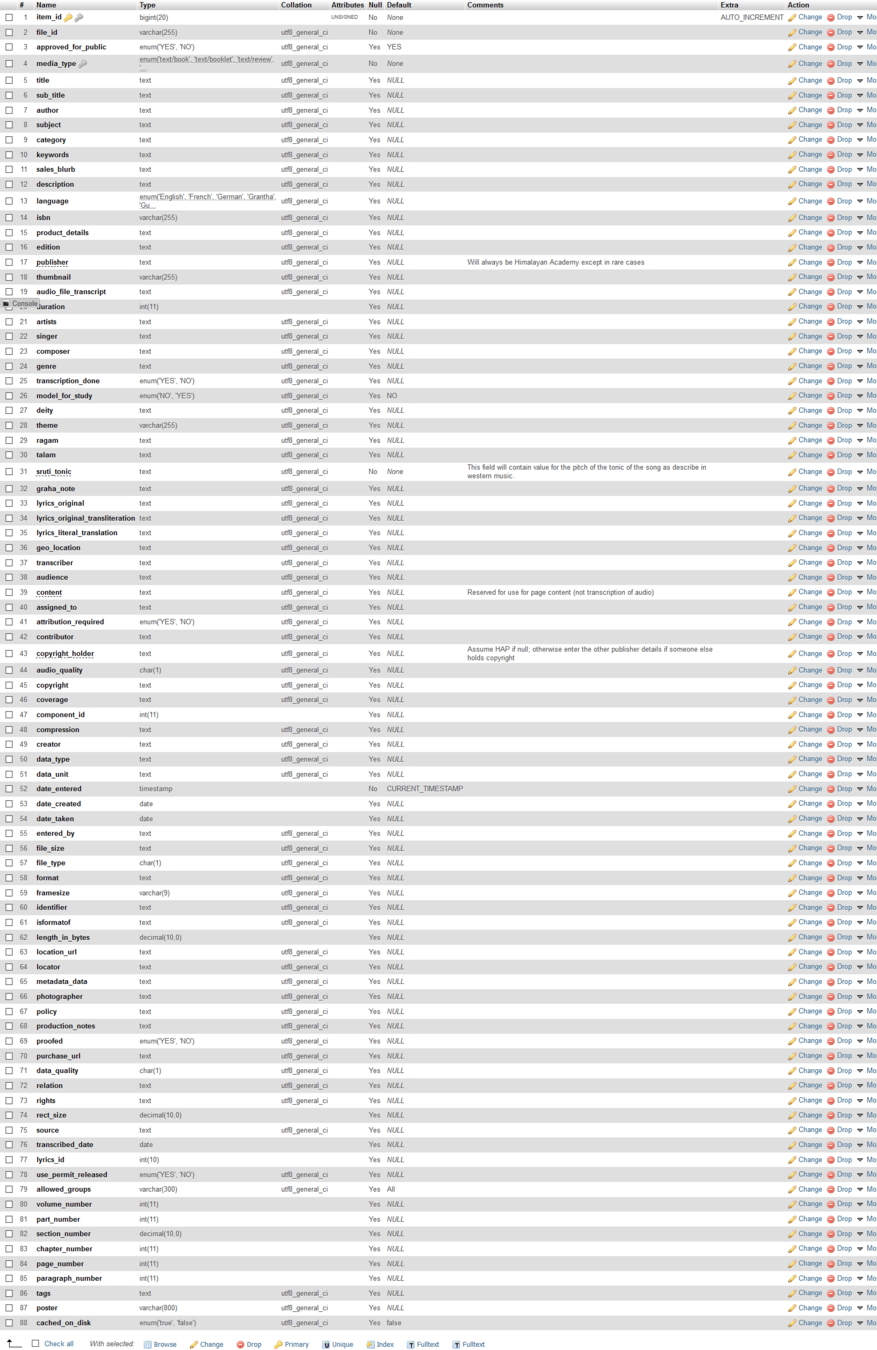
Main table called item
has 88 fields
🙀
It currently holds 8.000 items. Not much for a database.
Each record has a type
'text/book',
'text/booklet',
'text/review',
'text/quote',
'audio/chant',
'audio/inspiredtalk',
'audio/song',
'audio/podcasts',
'audio/instrumental',
'audio/shum',
'app',
'video/pubdesk',
'video/travel',
'video/teaching',
'video/ritual',
'video/building',
'video/talk',
'video/news',
'external/page',
'art/photography',
'art/painting',
'art/drawing',
'art/vector',
'slideshow/external',
'slideshow/galleria',
'slideshow/vr',
'audio/book'
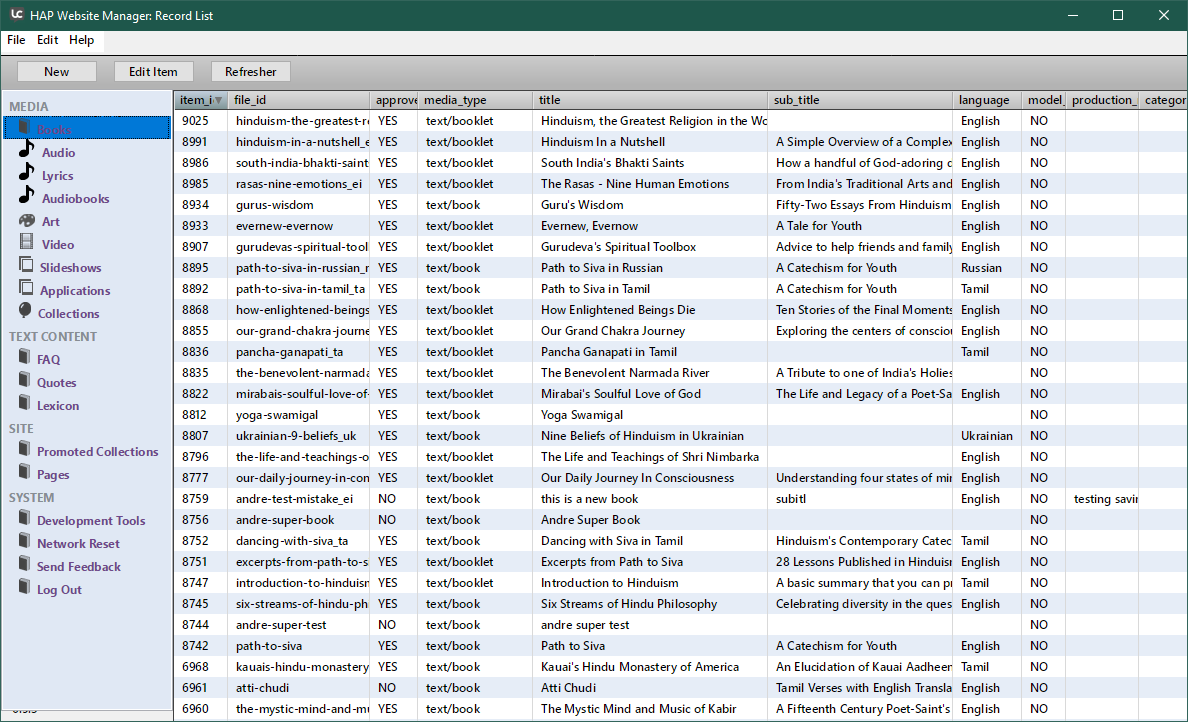
We have our own desktop app to manage the database