Introduction to Kubernetes
Andy Repton, Mission Critical Engineer @ Schuberg Philis
@SethKarlo
arepton@schubergphilis.com
Agenda
- Intro
- Installing dependencies
- Build our clusters
- Overview of components (while we wait for the clusters to build)
- Deploying pods, replicasets, deployments, secrets, statefulsets etc
- Questions
Intro
What is Kubernetes and why do we care?

Kindly sponsored by
- They are allowing us to use their AWS account
- Anyone found to be abusing the account will be forced to buy everyone else beer!
Everyone gets a cluster!
Everybody gets a user

Commands cheat sheet: http://bit.ly/2s17Mwo
Installing dependencies
Install Kubectl
curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.6.6/bin/darwin/amd64/kubectl
Install kops
brew update && brew install kopsClone the workshop repo
git clone git@github.com:Seth-Karlo/intro-to-kubernetes-workshop.gitexport KOPS_STATE_STORE=s3://devopsdays-ams
export MYNAME=user1
export NAME=${MYNAME}.sbp-demo.com
export AWS_ACCESS_KEY_ID=$YourID
export AWS_SECRET_ACCESS_KEY=$yourkeyExport the Variables we need
kops create cluster --zones eu-west-1a --node-size t2.medium --master-size t2.medium $NAME && kops update cluster ${NAME} --yesBuild our cluster
And build
(This will take a few minutes)
kubectl get csMasters, Nodes and etcd, oh my!
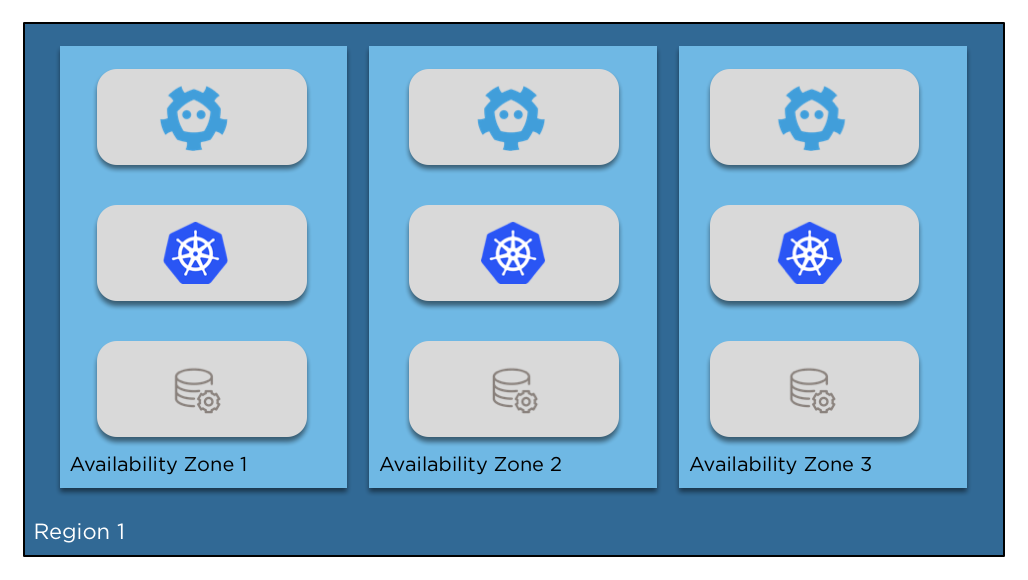
Masters, Nodes and etcd, oh my!
Master components are the brains of the cluster. They compose of:
- Kube Apiserver: runs a powerful api that all components talk to
- Kube Controller Manager: orchestrates the controllers of the cluster
- Kube scheduler: determines where pods should be scheduled
Masters, Nodes and etcd, oh my!
Node components are the brains of the individual nodes. They compose of:
- Kubelet: Talks to the container runtime to run pods, watches pods for health, gathers statistics for the nodes and the pods.
- Kube proxy: dynamically rewrites iptables to shuttle traffic in and out of the node
Masters, Nodes and etcd, oh my!
Etcd is a replicated key value store that acts as the state store and clustering manager for kubernetes. Access to this is effectively root access on the cluster, so it should be protected and secured.
Pods
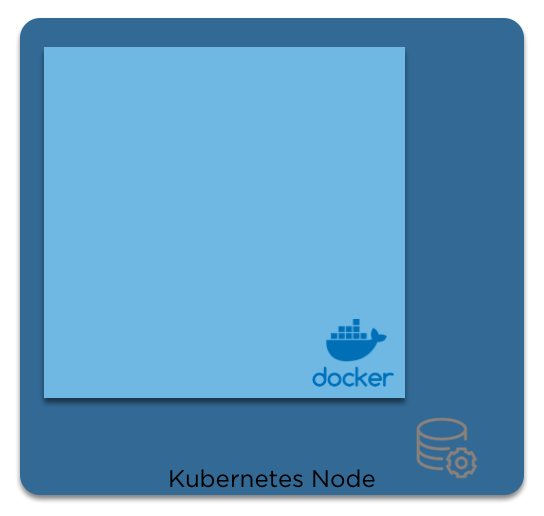
When we think of 'Bottom Up', we start with the node:

Pods
Then we add the container runtime
Pods
And then the containers
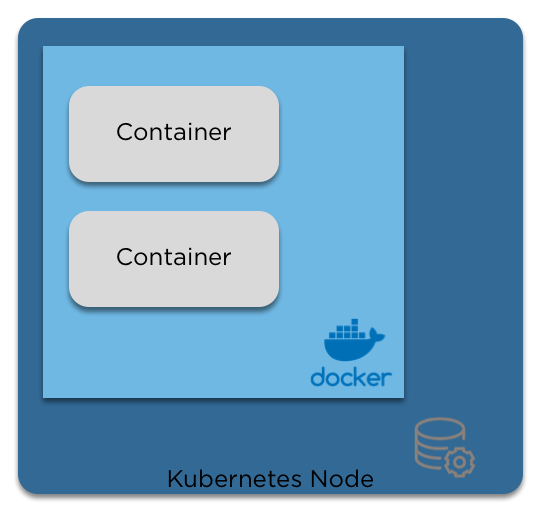
Pods
When we move from the 'physical' layer to kubernetes, the logical wrapper around containers is a pod

Pods
- Pods are the basic building blocks of Kubernetes.
- A pod is a collection of containers, storage and options dictating how the pod should run.
- Pods are mortal, and are expected to die in order to rebalance the cluster or to upgrade them.
- Each pod has a unique IP in the cluster, and can listen on any ports required for your application.
Pods support Health checks and liveness checks. We’ll go through those later
Deploy a pod
$ kubectl create -f pod/pod.yamlCheck it's running:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
pod 1/1 Running 0 11sRun a command inside the pod:
$ kubectl exec -it pod bash
[root@pod /]# ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=51 time=0.925 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=51 time=0.961 ms
^C
--- 8.8.8.8 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.925/0.943/0.961/0.018 msKill your pod:
$ kubectl delete pod pod
pod "pod" deletedReplica Sets
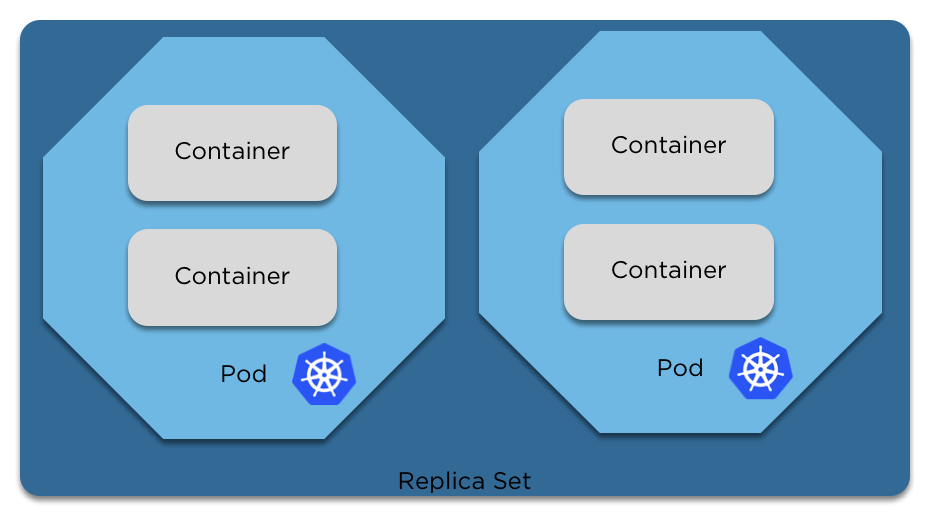
Replica Sets
- Replica sets define the number of pods that should be running at any given time.
- With a replica set, if a pod dies or is killed and the replica set no longer matches the required number, the scheduler will create a new pod and deploy it inside the cluster.
- If too many pods are running, the replica set will delete a pod to bring it back to the correct number.
- Replica sets can be adjusted on the fly, to scale up or down the number of pods running.
Deploy a replica set
$ kubectl create -f replicaset.yml
replicaset "replica-set" createdCheck your pod
$ k get pods
NAME READY STATUS RESTARTS AGE
replica-set-l3zbz 1/1 Running 0 1mDelete your pod
$ k delete pod replica-set-l3zbz
pod "replica-set-l3zbz" deletedCheck your pods again
$ k get pods
NAME READY STATUS RESTARTS AGE
replica-set-z0pp4 1/1 Running 0 1mLet's upgrade our replicaset (I've given you an old version of nginx)
$ kubectl edit replicaset replica-set
1 # Please edit the object below. Lines beginning with a '#' will be ignored,
2 # and an empty file will abort the edit. If an error occurs while saving this file will be
3 # reopened with the relevant failures.
4 #
5 apiVersion: extensions/v1beta1
6 kind: ReplicaSet
7 metadata:
8 creationTimestamp: 2017-06-26T10:02:34Z
9 generation: 1
10 labels:
11 app: replica-set
12 name: replica-set
13 namespace: default
14 resourceVersion: "1724"
15 selfLink: /apis/extensions/v1beta1/namespaces/default/replicasets/replica-set
16 uid: 9339e8f5-5a56-11e7-8817-0a75658e3054
17 spec:
18 replicas: 1
19 selector:
20 matchLabels:
21 app: replica-set
22 template:
23 metadata:
24 creationTimestamp: null
25 labels:
26 app: replica-set
27 spec:
28 containers:
29 - image: nginx:latest
30 imagePullPolicy: IfNotPresent
31 name: replica-set
32 ports:
33 - containerPort: 80
34 name: web
35 protocol: TCP
36 readinessProbe:
37 failureThreshold: 3
38 periodSeconds: 10
39 successThreshold: 1
40 tcpSocket:
41 port: 80
42 timeoutSeconds: 1
43 resources: {}
44 terminationMessagePath: /dev/termination-log
45 terminationMessagePolicy: File
46 dnsPolicy: ClusterFirst
47 restartPolicy: Always
48 schedulerName: default-scheduler
49 securityContext: {}
50 terminationGracePeriodSeconds: 30
51 status:
52 availableReplicas: 1
53 fullyLabeledReplicas: 1
54 observedGeneration: 1
55 readyReplicas: 1
56 replicas: 1Change
- image: nginx:1.12- image: nginx:1.13to
Let's check our pod:
$ k get pods
NAME READY STATUS RESTARTS AGE
replica-set-z0pp4 1/1 Running 0 4mAnd the image:
$ kubectl delete pod replica-set-z0pp4
pod "replica-set-z0pp4" deleted
$ kubectl describe pod | grep Image:
Image: nginx:1.13Hmm, that's odd. Let's delete the pod and check the new one
$ kubectl describe pod | grep Image:
Image: nginx:1.12Editing a replica set has no impact on running pods, only new ones
Deployments
- A Deployment is a copy of a replica set and pods.
- If a deployment changes, the cluster will automatically create a new replica set with the new version and will automatically live upgrade your pods.
- A deployment can also be rolled back to a previous version if there is an error.
Deploying a wordpress site
We'll add Volumes and Secrets to our pods
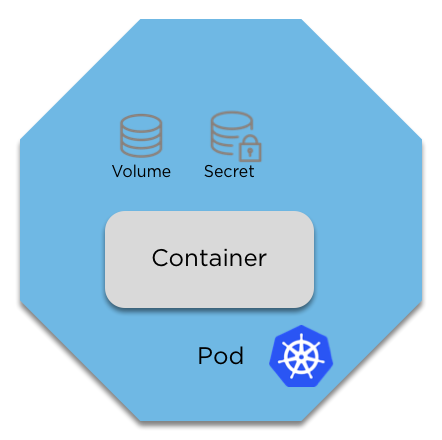
Deploying a wordpress site
$ kubectl create -f persistent-disk.yml
persistentvolumeclaim "mysql-pv-claim" createdWe will use persistent volumes for our mysql database
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
mysql-pv-claim Bound pvc-31415c4d-5a59-11e7-8817-0a75658e3054 20Gi RWO gp2 55sCreating secrets
- A secret is a base64 encoded string or file that is stored in the kubernetes API.
- You can mount secrets as files inside pods, or make them available as environment variables to the pods.
- Secrets are not encrypted, and by default are available to every pod in the same namespace, so be careful when putting sensitive information into them.
$ kubectl create secret generic mysql-pass --from-file=password.txt
secret "mysql-pass" createdCreating a secret to hold our mysql password
Deploying mysql
$ kubectl create -f mysql-deployment.yaml
service "wordpress-mysql" created
deployment "wordpress-mysql" created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
wordpress-mysql-1894417608-2k4rm 1/1 Running 0 41sNow deploy mysql
And check the logs
$ kubectl logs wordpress-mysql-1894417608-2k4rm | tail -1
2017-06-26 10:23:22 0 [Note] mysqld (mysqld 5.6.36) starting as process 1 ...Deploying wordpress
$ kubectl create -f wordpress-deployment.yaml
service "wordpress" created
persistentvolumeclaim "wp-pv-claim" created
deployment "wordpress" createdNow deploy wordpress
And check the logs
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
wordpress-1595585052-9m5vm 1/1 Running 0 55s
wordpress-mysql-1894417608-2k4rm 1/1 Running 0 6m
$ kubectl logs wordpress-1595585052-9m5vm
WordPress not found in /var/www/html - copying now...
WARNING: /var/www/html is not empty - press Ctrl+C now if this is an error!
+ ls -A
lost+found
+ sleep 10
Complete! WordPress has been successfully copied to /var/www/html
AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 100.96.2.8. Set the 'ServerName' directive globally to suppress this message
AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 100.96.2.8. Set the 'ServerName' directive globally to suppress this message
[Mon Jun 26 10:29:00.980026 2017] [mpm_prefork:notice] [pid 1] AH00163: Apache/2.4.10 (Debian) PHP/5.6.30 configured -- resuming normal operations
[Mon Jun 26 10:29:00.980053 2017] [core:notice] [pid 1] AH00094: Command line: 'apache2 -D FOREGROUND'Services
- Services expose your pods to other pods inside the cluster or to the outside world.
- A service uses a combination of labels and selectors to match the pods that it’s responsible for, and then will balance over the pods.
- Using a service IP, you can dynamically load balance inside a cluster using a service of type ‘ClusterIP’ or expose it to the outside world using a ‘NodePort’ or a ‘LoadBalancer’ if your cloud provider supports it.
- Creating a service automatically creates a DNS entry, which allows for service discovery inside the cluster.
Exposing our wordpress to the world
$ kubectl get svc wordpress
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
wordpress 100.70.168.153 <none> 80/TCP 3mLet's edit that and make it type 'LoadBalancer'
$ kubectl edit svc wordpress
service "wordpress" edited
$ kubectl get svc wordpress -o wide
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
wordpress 100.70.168.153 a252b84715a5a11e788170a75658e305-2028720367.eu-west-1.elb.amazonaws.com 80:30867/TCP 4m app=wordpress,tier=frontendAt the moment our service is type 'ClusterIP'
Upgrading our Wordpress
$ kubectl edit deployment wordpressChange the image from image: wordpress:4.7.3-apache to image: wordpress:4.8.0-apache (the latest)
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
wordpress-1321513498-zjmql 0/1 Terminating 0 3m
wordpress-1595585052-93wzw 1/1 Running 0 4sWe can upgrade our pods automatically
Stateful Sets
- StatefulSets (formerly PetSets) are a way to bring up stateful applications that require specific startup rules in order to function.
- With a StatefulSet, the pods are automatically added to the Cluster DNS in order to find each other.
- You can then add startup scripts to determine the order in which the pods will be started, allowing a main db to start first and for workers to join to the main.
Deploying CockroachDB
$ kubectl create -f statefulsets/
service "cockroachdb-public" created
service "cockroachdb" created
poddisruptionbudget "cockroachdb-budget" created
statefulset "cockroachdb" createdWatch your pods start up
$ kubectl get pods -w
NAME READY STATUS RESTARTS AGE
cockroachdb-0 0/1 Init:0/1 0 4sPodDisruptionBudgets
One of the resources created is a 'PodDisruptionBudget'
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: cockroachdb-budget
labels:
app: cockroachdb
spec:
selector:
matchLabels:
app: cockroachdb
minAvailable: 67%If using the 'eviction' type rather than a 'delete' (which statefulsets use), this will prevent you from deleting too many pods.
Testing our CockroachDB cluster
$ kubectl run -it --rm cockroach-client --image=cockroachdb/cockroach --restart=Never --command -- ./cockroach sql --host cockroachdb-public --insecure
root@cockroachdb-public:26257/> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| crdb_internal |
| information_schema |
| pg_catalog |
| system |
+--------------------+
(4 rows)
root@cockroachdb-public:26257/> CREATE DATABASE IF NOT EXISTS dodams;
root@cockroachdb-public:26257/> CREATE TABLE IF NOT EXISTS dodams.demo (k STRING PRIMARY KEY, v STRING);
CREATE TABLE
root@cockroachdb-public:26257/> UPSERT INTO dodams.demo VALUES('Devops', 'Days'), ('Amsterdam', 'Loves');
INSERT 2
root@cockroachdb-public:26257/> SELECT * FROM dodams.demo;Test kill a pod
$ kubectl delete pod cockroachdb-2
pod "cockroachdb-2" deletedWill self heal, in the correct order:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
cockroachdb-0 1/1 Running 0 29m
cockroachdb-1 1/1 Running 0 6m
cockroachdb-2 1/1 Running 0 33sOther resources
- DaemonSets
- ConfigMaps
- Operators
DaemonSets
- A daemonset is a special type of deployment that automatically creates one pod on each node in the cluster. If nodes are removed or added to the cluster, the daemonset will resize to match.
- Daemonsets are useful for monitoring solutions that need to run on each node to gather data for example.
ConfigMaps
- A config map is a file that is stored inside the kubernetes API.
- You can mount a config map inside a pod to override a configuration file, and if you update the config map in the API, kubernetes will automatically push out the update file to the pods that are consuming it.
- Config maps allow you to specify your configuration separately from your code, and with secrets, allow you to move the differences between your DTAP environments into the kubernetes API and out of your docker container
Operators
- Operators are a new way of running complex stateful applications on Kubernetes by moving the logic of setting up and maintaining an application into a separate pod and utilising the etcd cluster behind kubernetes for state storage and clustering.