

A Systematic Search for Main-Sequence Dipper Stars with ZTF
Andy Tzanidakis, James Davenport in Collaboration with LINCC Frameworks and DiRAC
atzanida@uw.edu // andytza.github.io // AndyTza


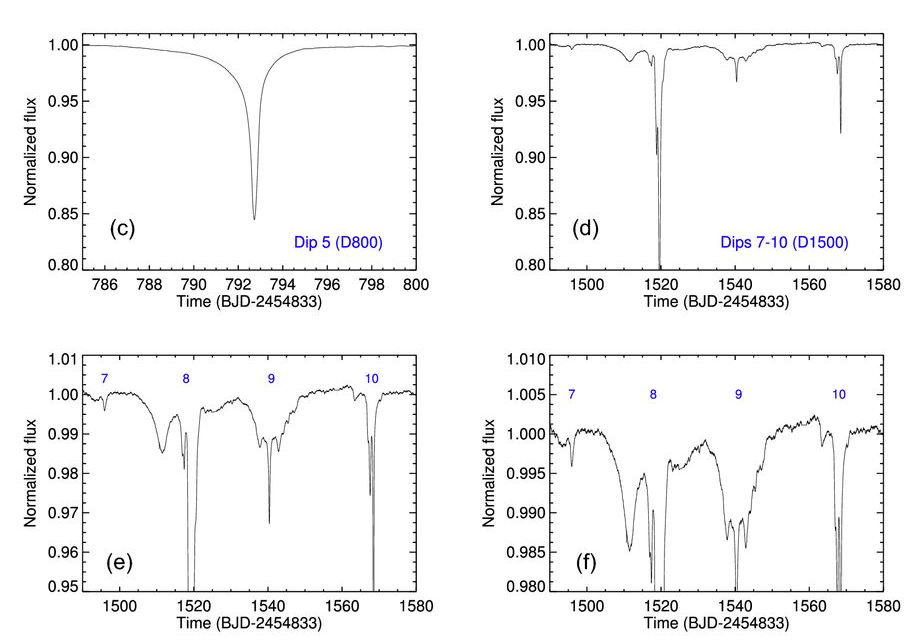
Boyajian Star
Boyajian et al. (2016)
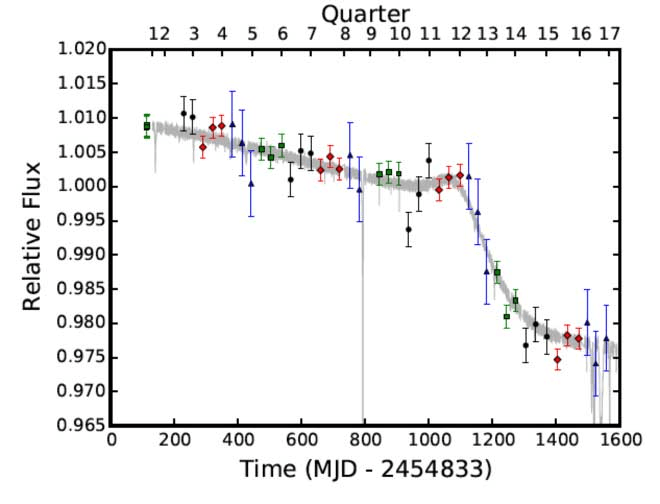
B. Montet & J. Simon (2016)
Boyajian Star
- Ordinary F3V star
- Irregular photometric (non-periodic) dimming events (~hrs-yrs)
- No IR excess
Boyajian Star
- Ordinary F3V star
- Irregular photometric (non-periodic) dimming events (~hrs-yrs)
- No IR excess
Not in line with ISM, exoplanets, stellar chromospheric variability...
Boyajian Star Theories
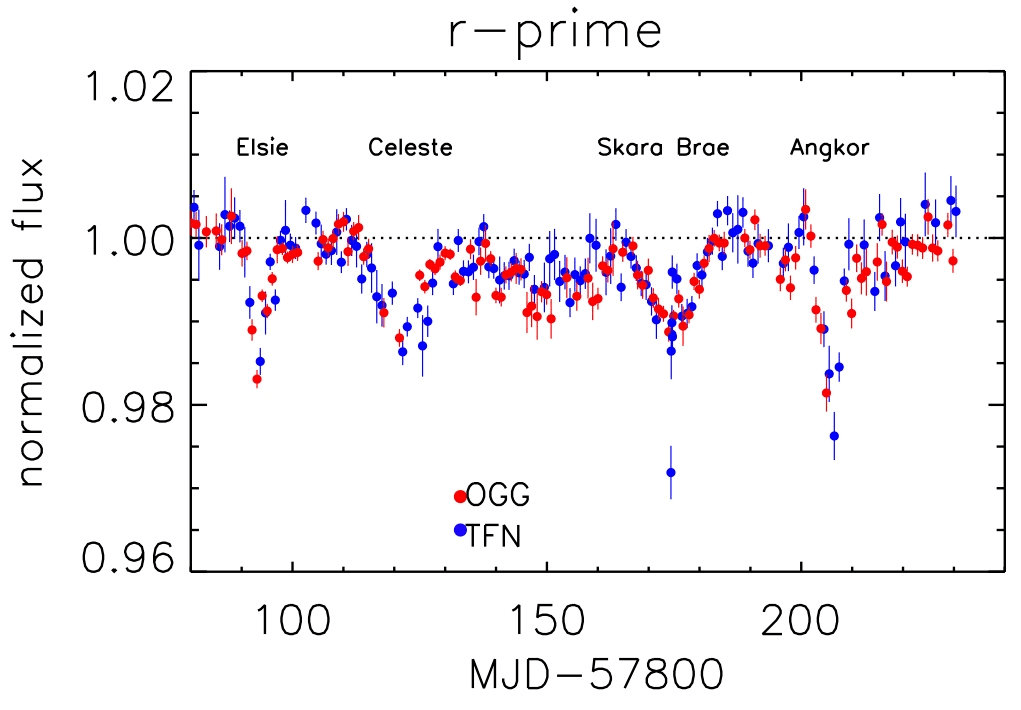
Boyajian et al. (2018)
NASA
NASA
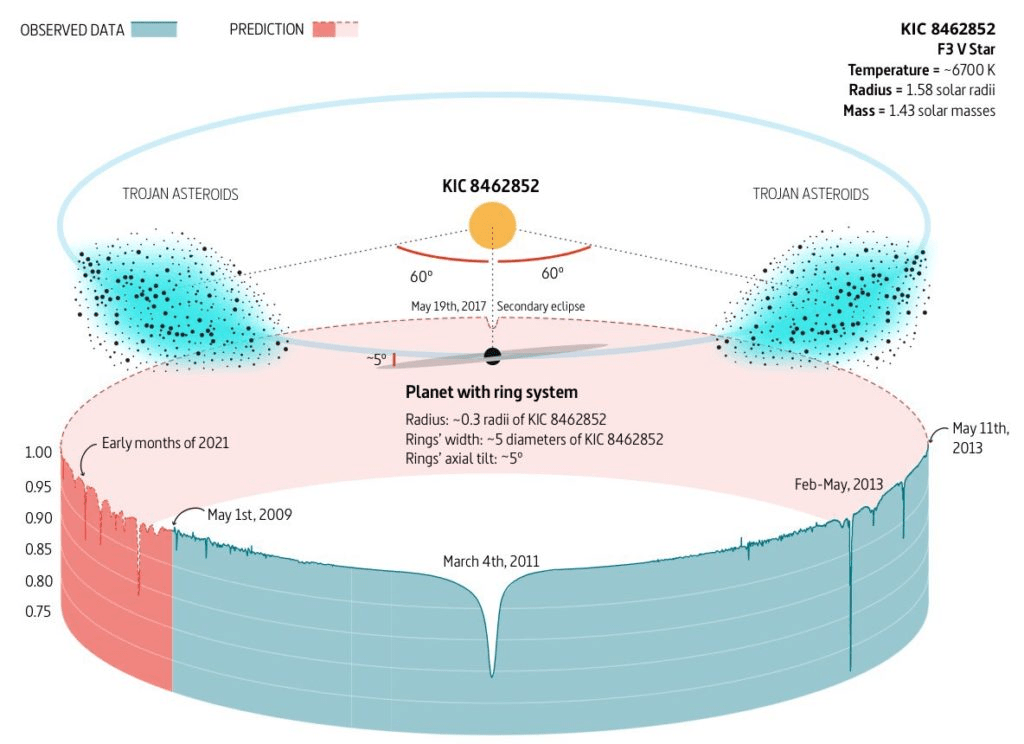


Interstellar comet swarms
(Makarov and Goldin 2016)
Ringed planet with Trojan asteroid swarm
(Ballesteros et al. 2017)
Destruction of a secondary body or planet engulfment
(Metzger et al. 2017)
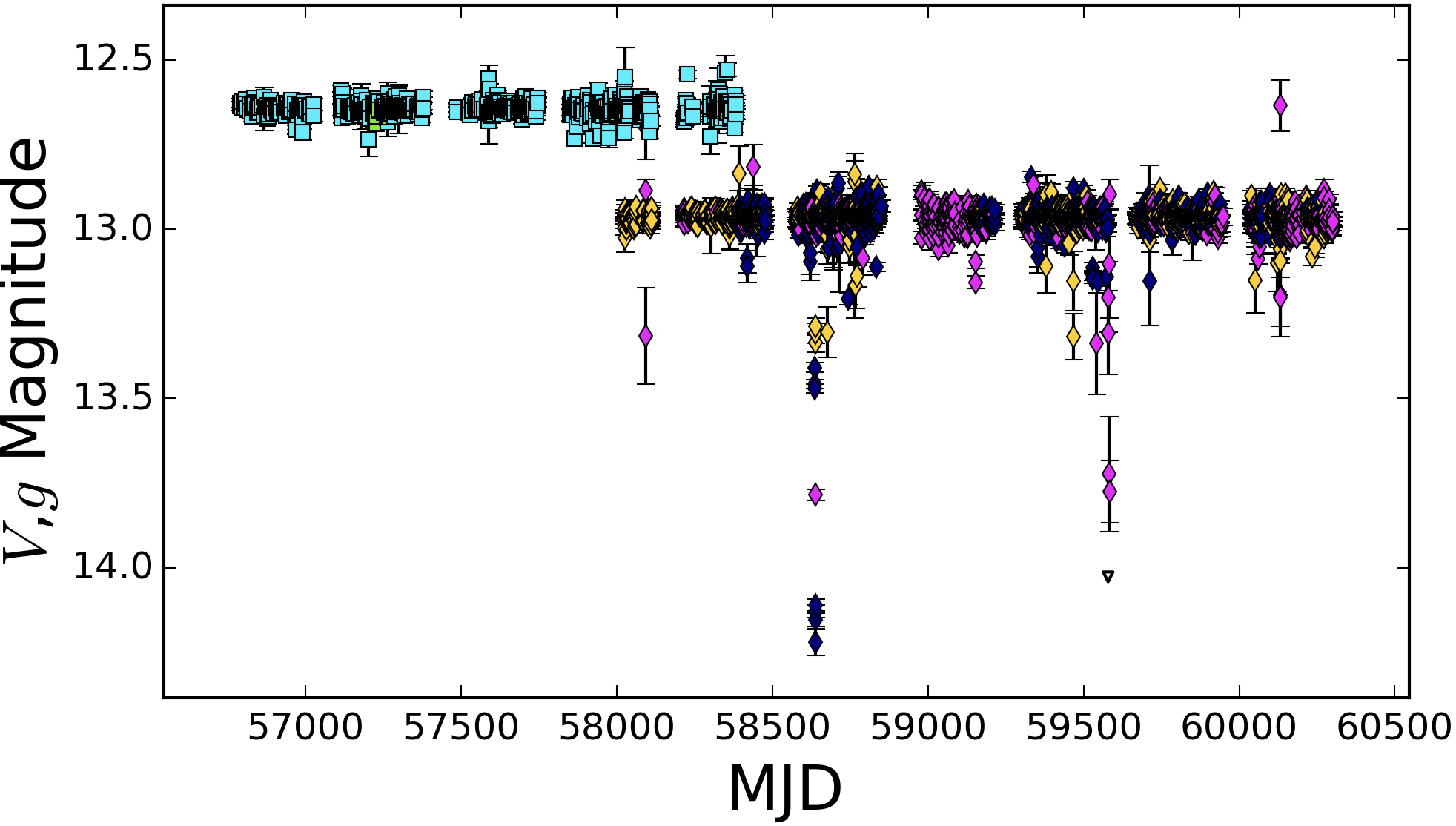
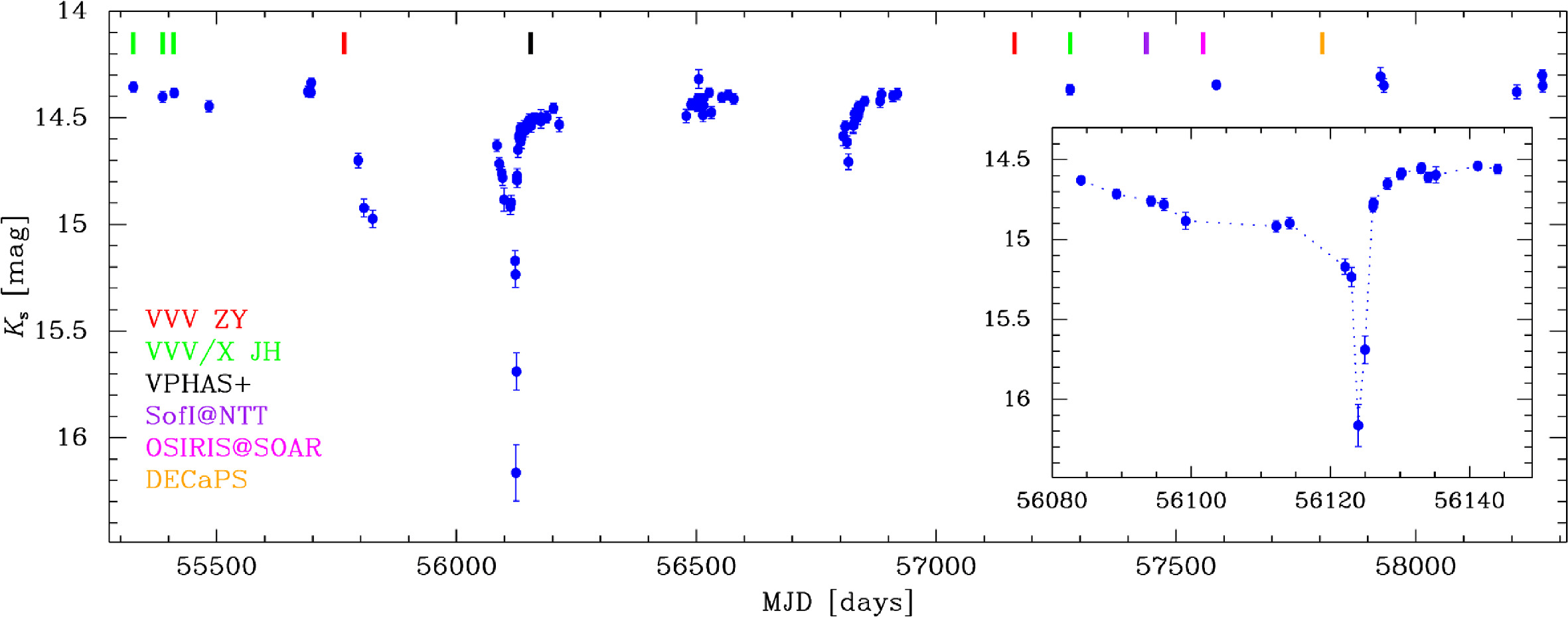
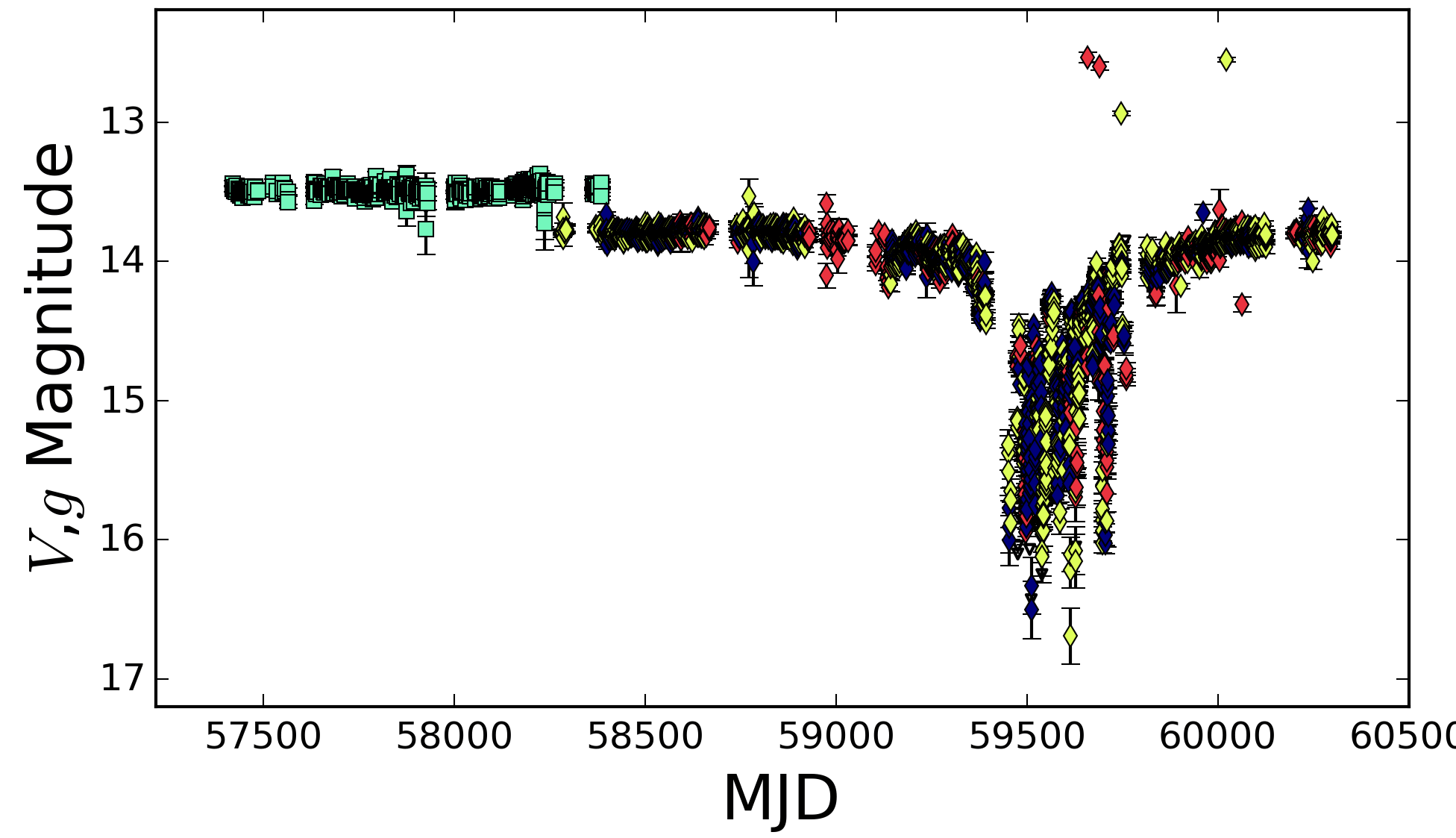
VVV-WIT-07, Saito et al. (2018)
ASASSN-V J2139, Jayasinghe et al. (2019; ATel)
ASASSN-21qj, Kenworthy et al. (2023)
Growing Population of MS dippers
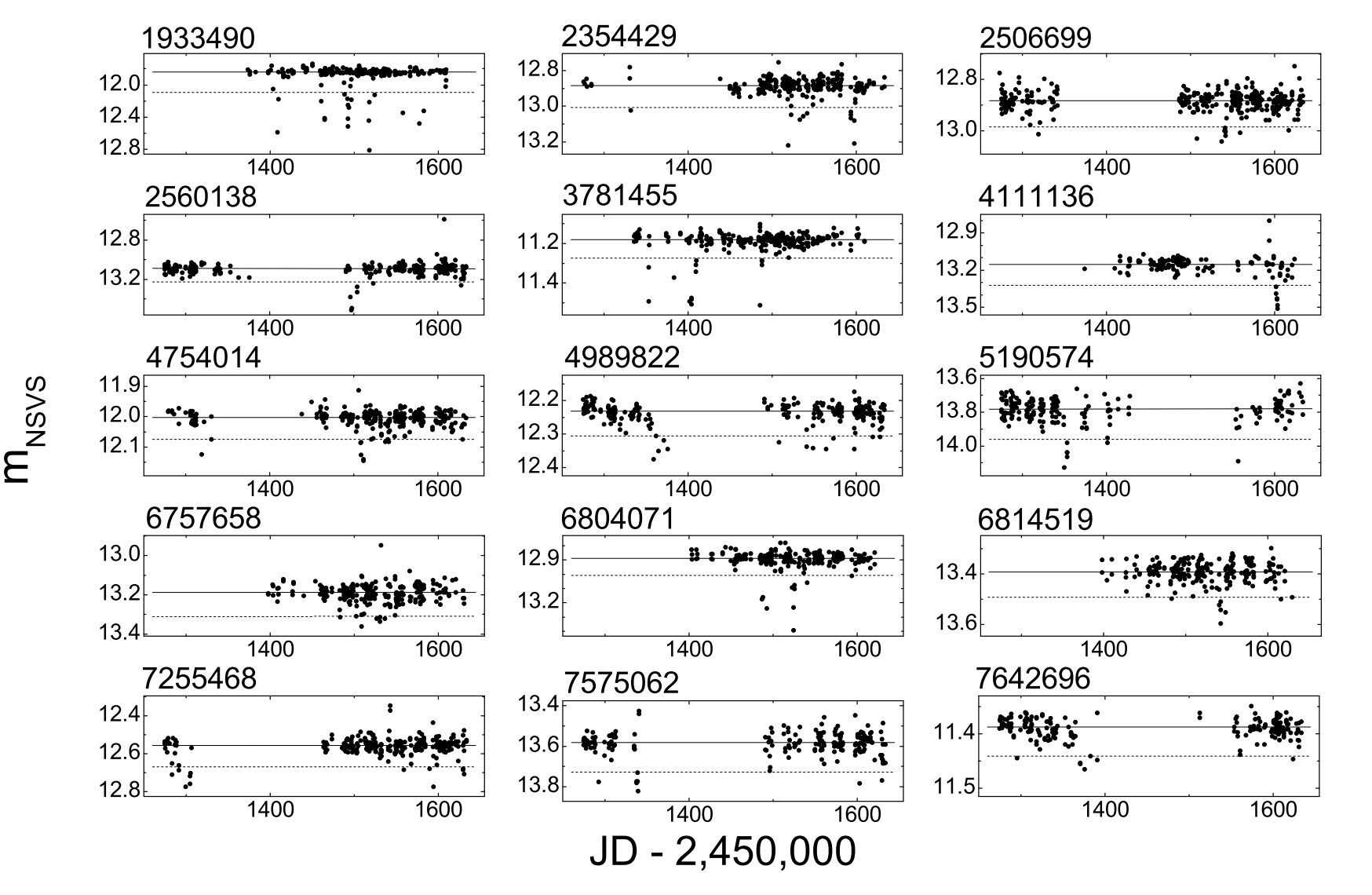
- Searched 2.3 million stars using the Northern Sky Variable Survey (NSVS) by Schmidt (2019)
- 21 dipper candidates out of 2.3 million. Cluster in MS or RGB stars.
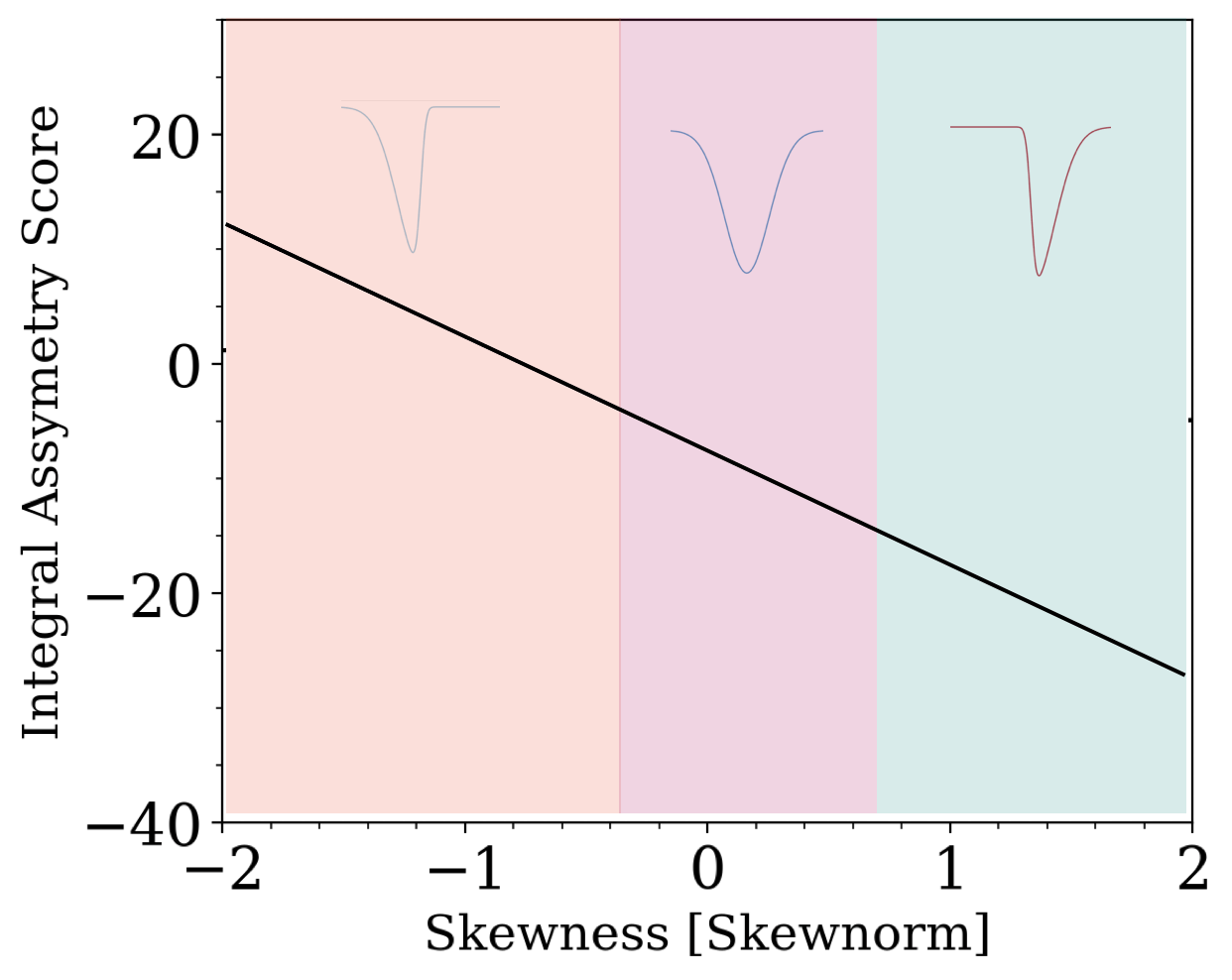
- Phenomenologically separated by slow and fast dipper events
- Clusters in MS and RG stars. However, RG dips are likely to be a completely different phenomenology?
✅
✅
✅
✅
Schmidt (2019)
VVV-WIT-07, Saito et al. (2018)
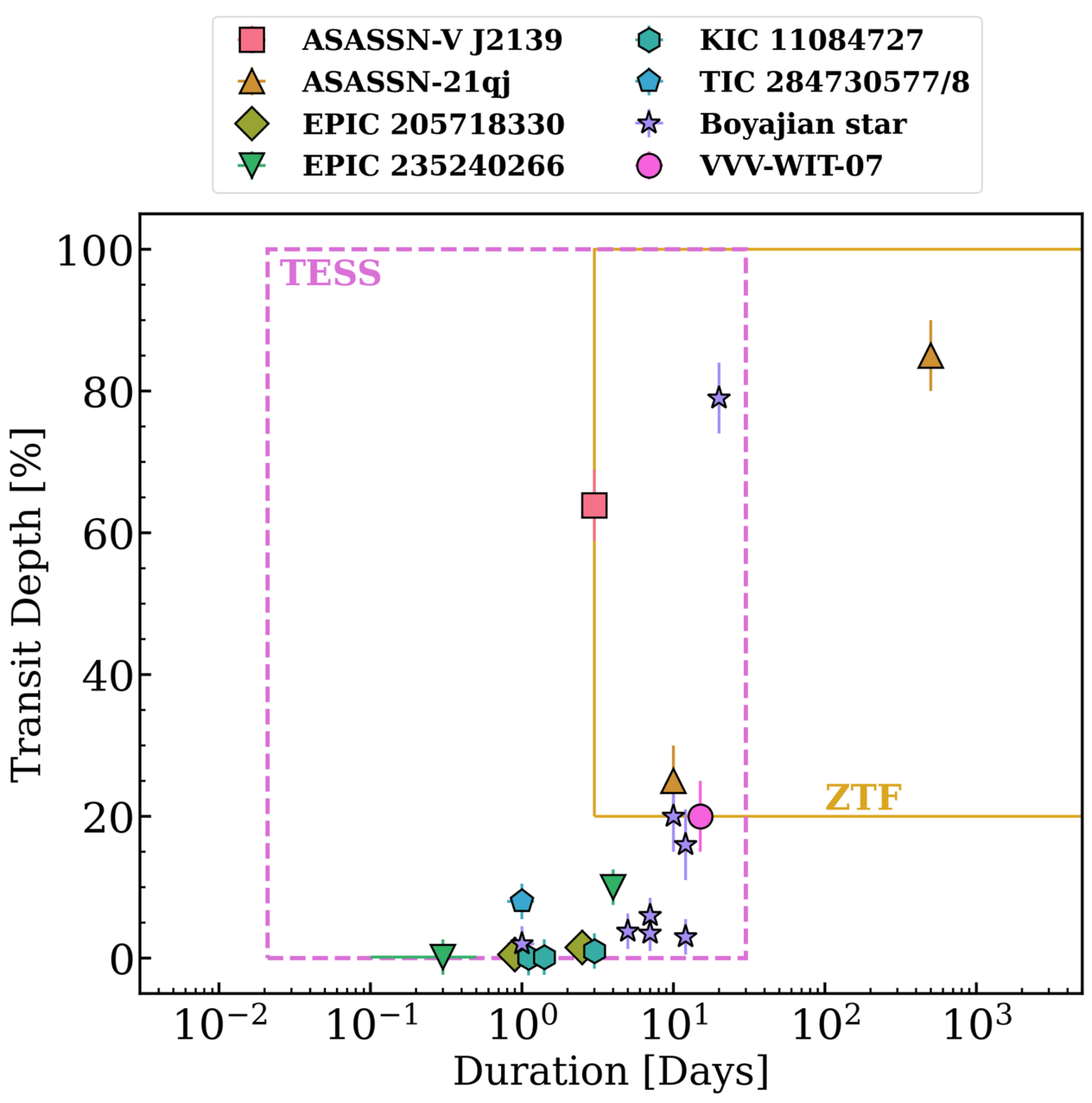
Why ZTF?
On average ZTF covers ∼3750 square degrees per hour with a median limiting magnitude of r∼20.6 mag, g∼20.8 mag (Dekany et al. 2020; Bellm et al. 2019)
ZTF cadences typically span 1-3 day cadences with ~1-10% photometric precision
ZTF is a good TD survey to conduct a systematic search of Boyajian star analogs and searching techniques for LSST & Roman
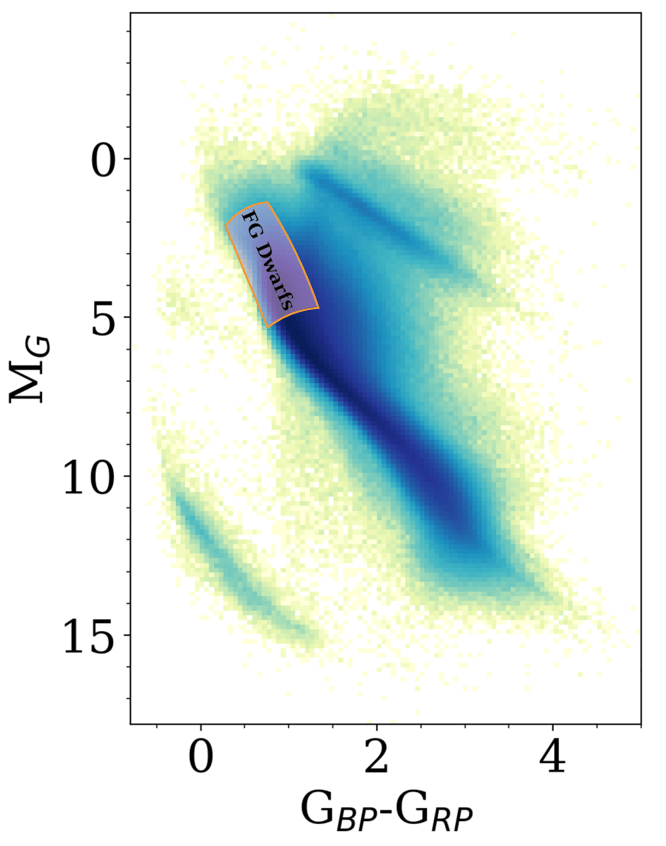
Our Sample
Phase-I:
- FG main-sequence stars in Gaia DR3 + ZTF
- ~4.5M stars
Phase-II:
- AFGKM main-sequence stars in Gaia DR3 + ZTF
- >8M stars
*Astrometric solutions and stellar parameters derived from the Apsis processing chain developed in Gaia DPAC CU8 (Ulla et al. 2022)
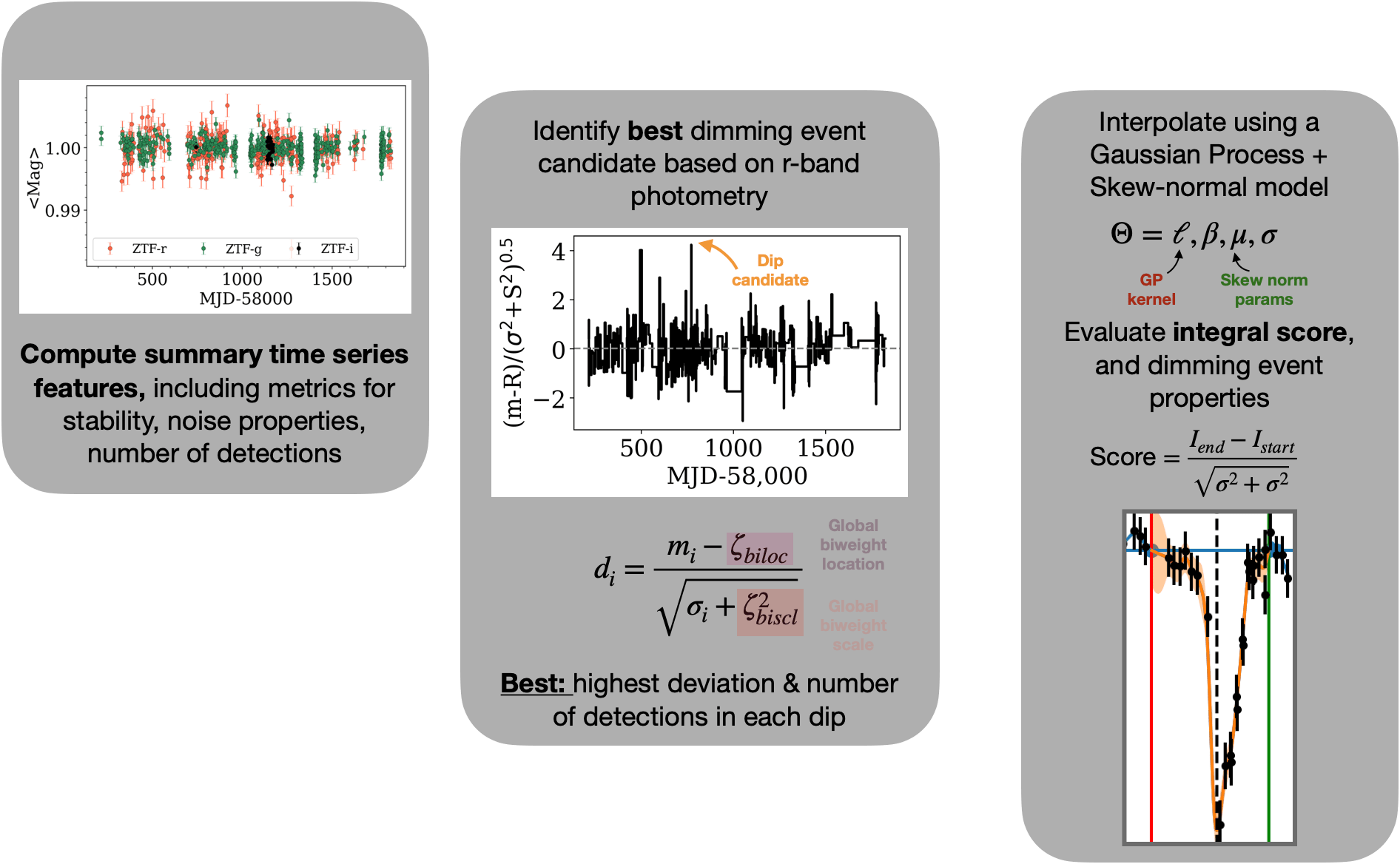
Full ZTF DR14 Photometry
Identify Event
Scoring
Preliminary Workflow
Tzanidakis et al. (2024; in-prep)
Gaia DR3



Customizable Python time-series evaluation routines (e.g. fitting, time-series features, ...)
ZTF (src) DR14
ZTF DR14
LSDB
Fast object catalog operations and querying
TAPE
Bridges object
and source catalogs
Large Survey DataBase
Timeseries Analysis & Processing Engine
LSDB
#Load ZTF, Gaia, and ZTF sources hipscats # note data3/ for epyc
gaia = lsdb.read_hipscat("/epyc/data3/hipscat/test_catalogs/gaia_symbolic")
# load ZTF object table
ztf = lsdb.read_hipscat("/epyc/data3/hipscat/catalogs/ztf_axs/ztf_dr14")
# Load ZTF DR14 sources
ztf_sources = lsdb.read_hipscat("/epyc/data3/hipscat/catalogs/ztf_axs/ztf_source")# Crossmatch & query: Gaia + ZTF object
_all_sky_object = gaia.crossmatch(ztf).query(
"nobs_g_ztf_dr14 > 50 and nobs_r_ztf_dr14 > 50 and \
parallax_gaia > 0 and parallax_over_error_gaia > 5 and \
teff_gspphot_gaia > 5380 and teff_gspphot_gaia < 7220 and logg_gspphot_gaia > 4.5 \
and logg_gspphot_gaia < 4.72 and classprob_dsc_combmod_star_gaia > 0.5").compute()
>> Wall time: ~30-1:30 hrs# Join xmatch Gaia+ZTF obj with ZTF source
_sources = _sample_hips.join(
ztf_sources, left_on="ps1_objid_ztf_dr14", right_on="ps1_objid")
>> Wall time: 2-4 minutesAstronomy eXtensions for Spark
AXS API was sluggish, and lacked user-friendly data exploration features 😫
def spark_start(local_dir):
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName("LSD2")
.config("spark.sql.warehouse.dir", local_dir)
.config('spark.master', "local[10]") # num workers
.config('spark.driver.memory', '80G') # 128
.config('spark.local.dir', local_dir)
.config('spark.memory.offHeap.enabled', 'true')
.config('spark.memory.offHeap.size', '150G') # 256
.config("spark.sql.execution.arrow.enabled", "true")
.config("spark.driver.maxResultSize", "15G")
.config("spark.driver.extraJavaOptions", f"-Dderby.system.home={local_dir}")
.enableHiveSupport()
.getOrCreate()
)
return spark
spark_session = spark_start("/epyc/users/atzanida/spark-tmp/")
catalog = axs.AxsCatalog(spark_session)
# Load catalogs
gr3 = catalog.load("gaia_dr3_source")
ztf = catalog.load("ztf_dr14")
match = gaia_region.crossmatch(ztf)
match_final = match.where((match['teff_gspphot']>=5_380) & # limit on G0 dwarfs
(match['teff_gspphot']<=7_220) & # limit on F9 dwarfs
(match['logg_gspphot']>=4.5) &
(match['logg_gspphot']<=4.72) &
(match['classprob_dsc_combmod_star']>0.9) & # 90% prob it's a star
(match['parallax_over_error'] >= 5) & # high SNR parallaxes &
(match['nobs_r']>100) & (match['nobs_g']>100)).select("ra", "dec", "pmra",
'pmdec', 'parallax', 'parallax_over_error',
'phot_g_mean_mag', 'bp_rp', 'source_id',
'teff_gspphot', 'logg_gspphot',
'ag_gspphot',
'nobs_r', 'nobs_g',
'mjd_r', 'mjd_g',
'mag_r', 'mag_g',
'magerr_r', 'magerr_g',
"catflags_r", "catflags_g",
"mean_mag_r", "mean_mag_g")LSDB + TAPE
from tape import Ensemble, ColumnMapper
# Initialize an Ensemble
ens = Ensemble(memory_limit=1e11, n_workers=12)
ens.client_info()# ColumnMapper Establishes which table columns map to timeseries quantities
colmap = ColumnMapper(
id_col='_hipscat_index',
time_col='mjd',
flux_col='mag',
err_col='magerr',
band_col='band')
ens.from_dask_dataframe(
source_frame=_sources._ddf,
object_frame=_sample_hips._ddf,
column_mapper=colmap,
sync_tables=False, # Avoid doing an initial sync
sorted=True, # If the input data is already sorted by the chosen index
sort=False)source catalog
object catalog
TAPE + Custom Processing
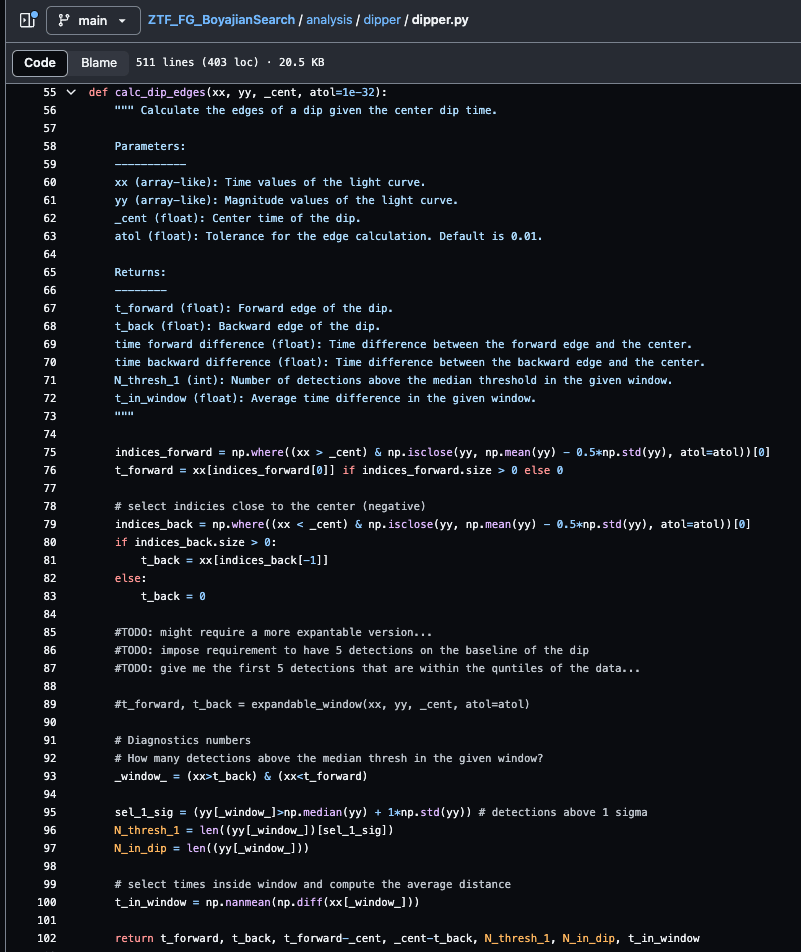
# Define DataFrame with loc and scale as meta
my_meta = pd.DataFrame(columns=column_names, dtype=float)
# apply calc_biweight function
calculate = ens.batch(
evaluate,
'mjd_ztf_source', 'mag_ztf_source',
'magerr_ztf_source', 'catflags_ztf_source',
'band_ztf_source', 'ra_ztf_source', 'dec_ztf_source',
meta=my_meta,
use_map=True,
compute=False)ens.assign(table='object', **kwargs)Custom Python time-series calculations/pipeline
# demo tool estimate the nearest neighbour given ra, dec
my_tools.estimate_gaiadr3_density(131.1, 22.3,
table=Gaia,
radius=30*u.arcseconds)LSDB Hipscat table functionality
`assign` to object table
Data Exploration
# Explore tables
demo_table = ens.object.head(500_000, npartitions=30_000)
# Alternative
demo_table = ens.object.sample(frac=0.01).compute()
lc1 = ens.source.loc[352445905963581440].compute()
>> Wall time: 1-3 seconds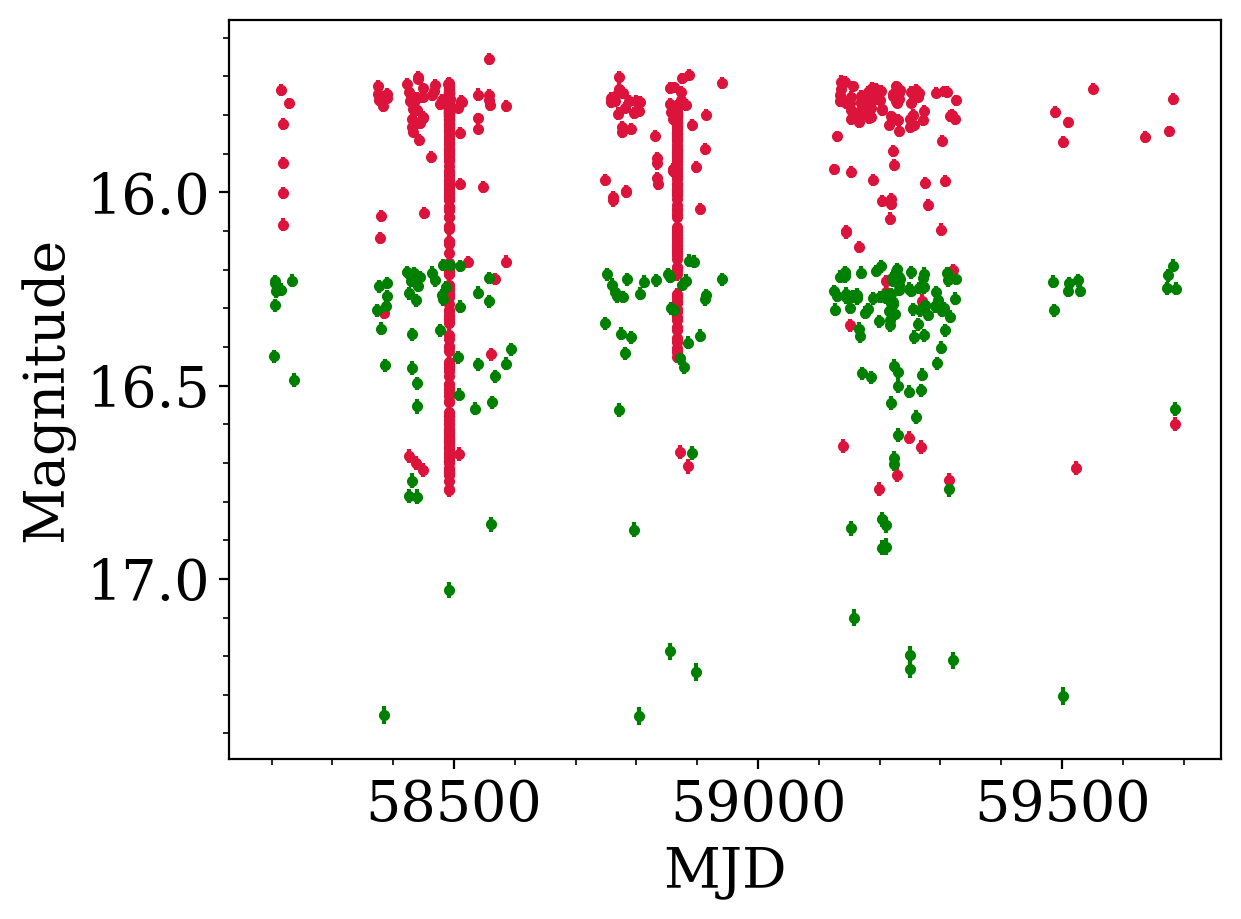
# Load the entire objec table
full_table = ens.object.compute()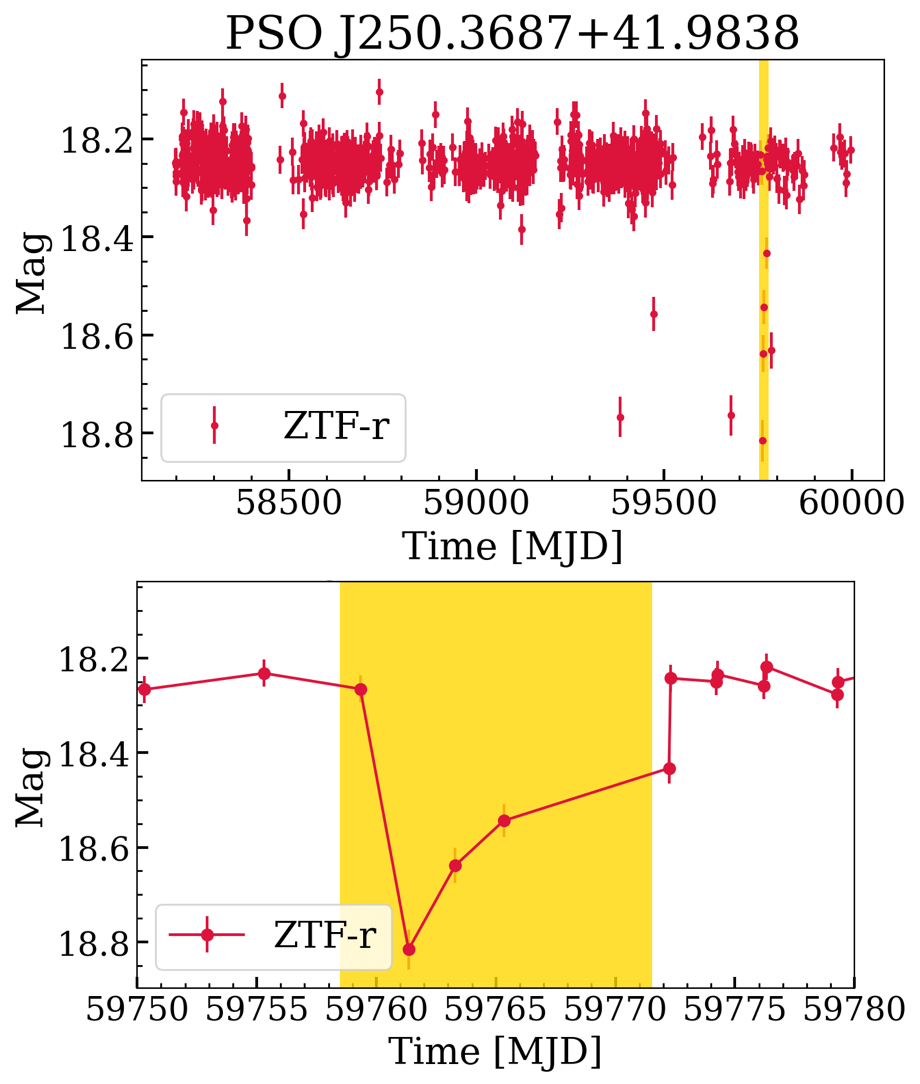
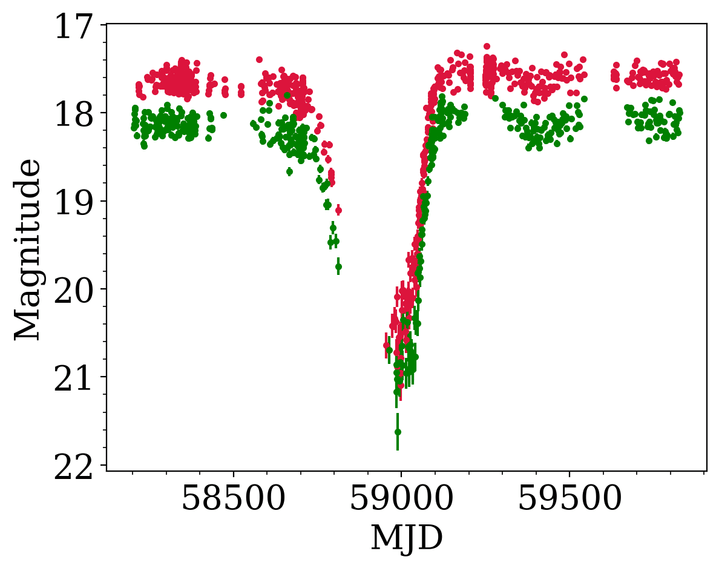
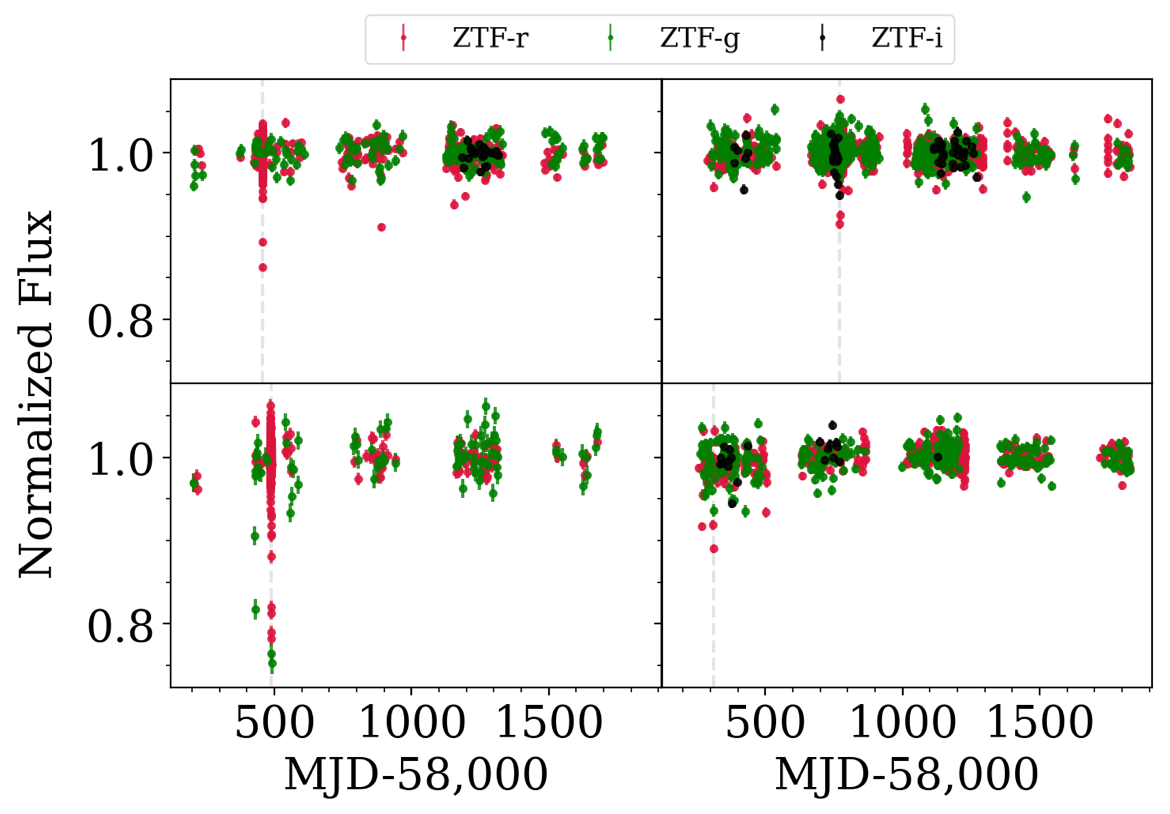
New Candidates! 😱
Candidate 1
Candidate 2
Candidate 3
Candidate 4
Tzanidakis et al. (2024; in-prep)
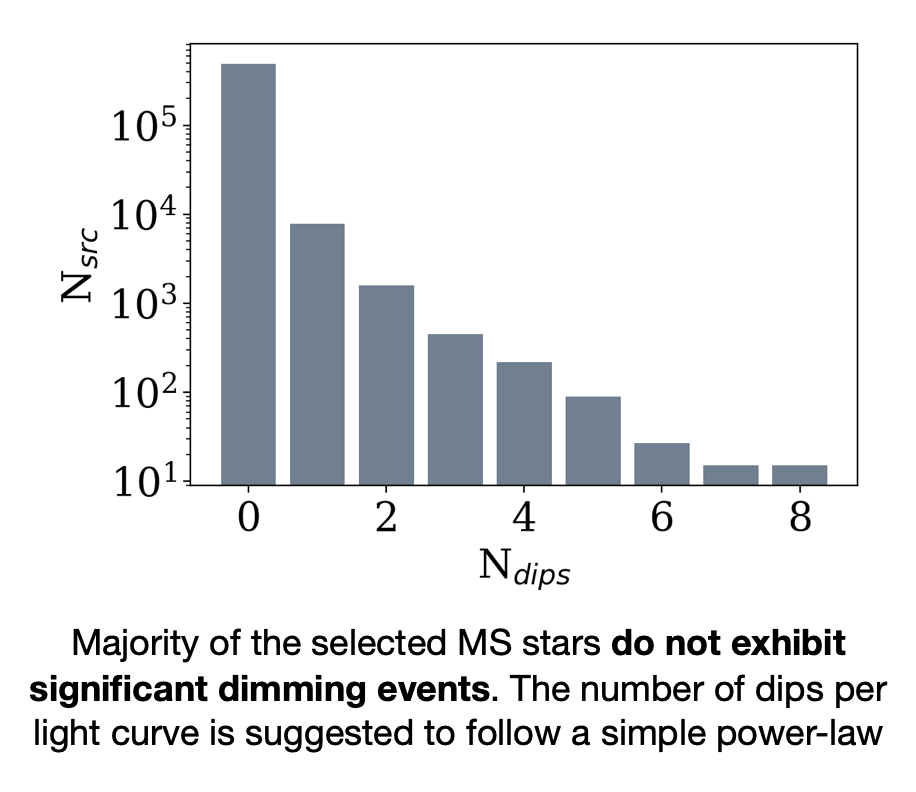
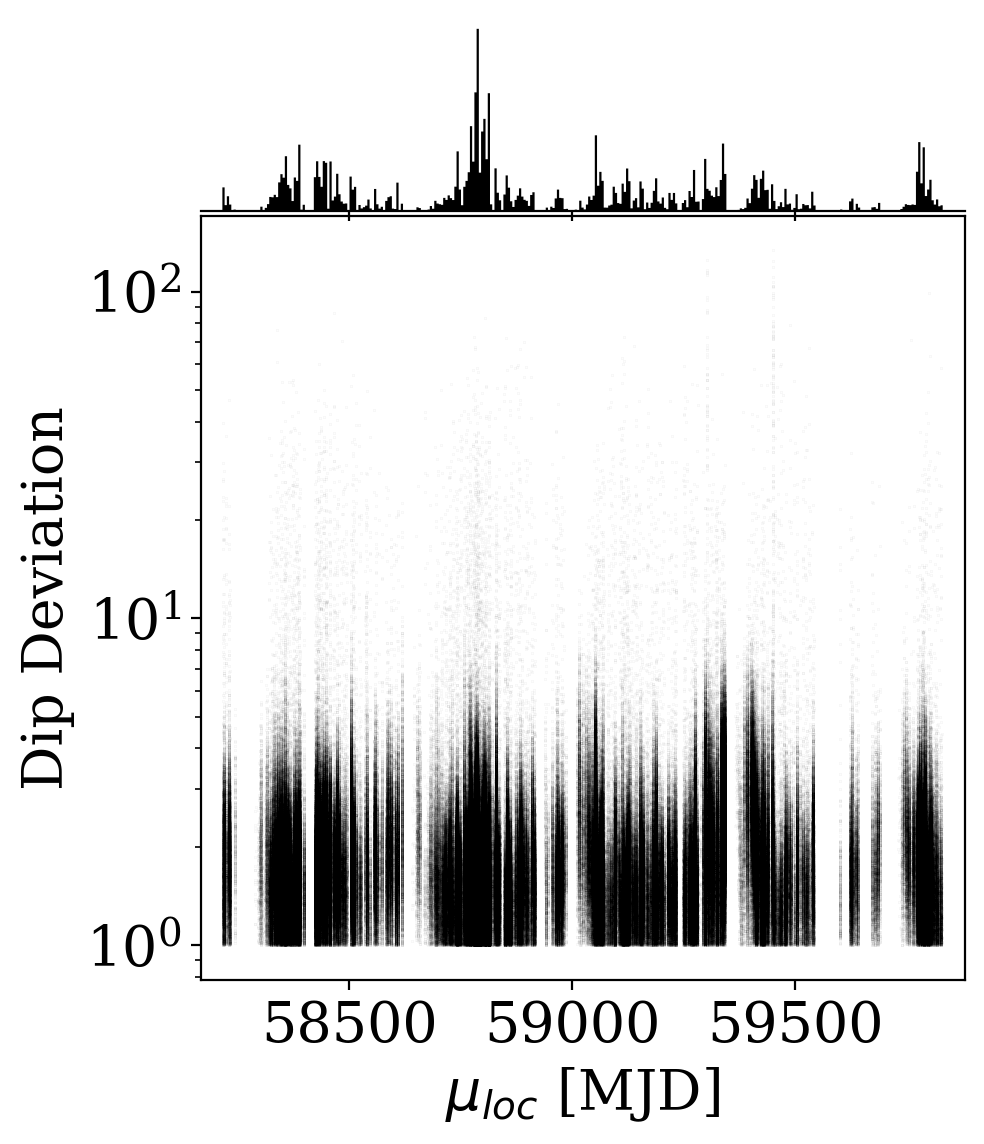
Flexible and fast data exploration allows us to probe unwanted systematic effects 👇
catname = "I/360"
catalogue_ivoid = f"ivo://CDS.VizieR/{catname}"
# the actual query to the registry
voresource = registry.search(ivoid=catalogue_ivoid)[0]
voresource.describe(verbose=True)External Tables: LSDB + TAPE
Gaia DR3 Part 6. Performance verification
Short Name: I/360
IVOA Identifier: ivo://cds.vizier/i/360
Access modes: conesearch, hips#hips-1.0, tap#aux, web
Multi-capabilty service -- use get_service()
Gaia Data Release 3 (Gaia DR3) will be released on 13 June 2022. The Gaia DR3
catalogue builds upon the Early Data Release 3 (released on 3 December 2020)
and combines, for the same stretch of time and the same set of observations,
these already-published data products with numerous new data products such as
extended objects and non-single stars.
Subjects: I/360
Waveband Coverage: optical
More info: https://cdsarc.cds.unistra.fr/viz-bin/cat/I/360# get the first table of the catalogue
first_table_name = 'I/360/goldf'
# execute a synchronous ADQL query
tap_service = voresource.get_service("tap")
tap_records = voresource.get_service("tap").run_sync(
f'SELECT TOP 90000 * FROM "{first_table_name}"')
tbl = tap_records.to_table()
# LSDB Hipscat format:
my_table = lsdb.from_dataframe(tbl, catalog_name='my_table',
ra_column='RA_ICRS',
dec_column='DE_ICRS')
VizieR:
LSDB catalog object!
User API Suggestions
Priority
Documentation & Turorials
Gaia DR3 Part 6. Performance verification
Short Name: I/360
IVOA Identifier: ivo://cds.vizier/i/360
Access modes: conesearch, hips#hips-1.0, tap#aux, web
Multi-capabilty service -- use get_service()
Gaia Data Release 3 (Gaia DR3) will be released on 13 June 2022. The Gaia DR3
catalogue builds upon the Early Data Release 3 (released on 3 December 2020)
and combines, for the same stretch of time and the same set of observations,
these already-published data products with numerous new data products such as
extended objects and non-single stars.
Subjects: I/360
Waveband Coverage: optical
More info: https://cdsarc.cds.unistra.fr/viz-bin/cat/I/360Table documentation

PSF Cutout
Catalogs

Data Representation

DASK
error log
Other
TD surveys


Conclusions
Special thanks to Neven Caplar, Wilson Beebe, Doug Branton, Andy Connolly, and the LINCC Frameworks team 🙏
We are conducting the largest systematic search for main-sequence/Boyajian star analogs with ZTF and Gaia.
Both Large Survey DataBase (LSDB) and Timeseries Analysis & Processing Engine (TAPE), are pivotal tools for the success of this study - providing: data exploration, discovery, and rapid analysis
Our preliminary pipeline using LSDB + TAPE has already revealed several new and exciting main-sequence dipper candidates!!
1.
2.
3.
Project can be found on GitHub: github.com/dirac-institute/ZTF_FG_BoyajianSearch
Andy Tzanidakis // atzanida@uw.edu
Backup Slides
Data

