Learning to Race in Hours with Reinforcement Learning

Antonin Raffin
Outline
I. Reinforcement Learning 101
II. Learning to drive in minutes
III. Learning to race in hours
Donkey Car Sim




Controls
on-board camera
RL 101

Goal: maximize sum of rewards
Reward Example
Is the car still on the road?
+1
-10
yes
no
RL in Practice
RL Tips and Tricks (RLVS21): https://rl-vs.github.io/rlvs2021/

Questions?
Learning to Drive in Minutes
Challenges
- minimal number of sensors
- variability of the scene (light, shadows, other cars, ...)
- oscillations
- limited computing power
- communication delay
- sample efficiency

Decoupling Features Extraction from Policy Learning

Learning a State Representation

Real Car
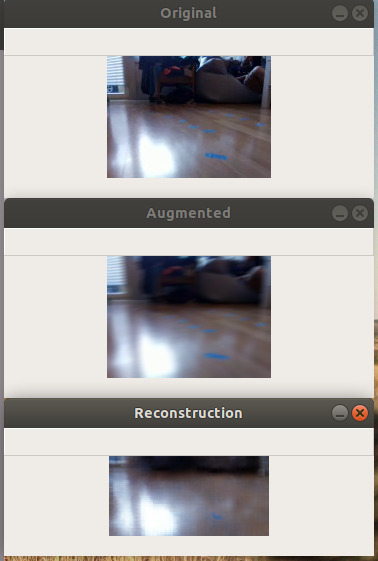
Exploring the Latent Space

Questions?
Reward?
Primary
Secondary
stay on the track
smooth driving
Reward Hacking
+1 for every timestep without crash
minimize steering diff
minimal throttle
no steering / constant steering
maximize distance travelled
zig-zag driving
Solution?
+1 for every step without crash + const x throttle
-10 - const x throttle (on crash)
reward =
Smooth Control

- clip steering diff
- continuity cost:
- to be continued...
(steering - last\_steering)^2
Be careful with Markov assumption!
Terminations
- crash (user intervention)
- timeout (need to be handled)
- to be continued...
RL Library: Stable Baselines3
- Reliable implementations
- User friendly
- Active community
- Extensive documentation
- RL Zoo for training
- Algo: TQC (sample efficient)
Result
Learning to Race in Hours
- new sensor: speed
- new objective

Reward
- proxy: maximize speed
- penalize crashes
Smooth Control
- generalized State-Dependent Exploration (gSDE)
- condition reward on smoothness
- reduce max steering
- history wrapper
reward = reward \cdot (1 - delta\_steering) - continuity\_cost
Terminations
- after n hits (crash)
- low speed (stuck)
Result
live demo