Gülçin Yıldırım
5432...MeetUs! Milano 2016

Ansible loves PostgreSQL
select * from me;
Postgres DBA @ 2ndQuadrant
MSc Comp. & Systems Eng. @ Tallinn University of Technology
BSc Maths Eng. @ Yildiz Technical University
Writes blog on 2ndQuadrant blog
Does some childish paintings
Loves independent films
What is Ansible?
Simple, agentless and powerful open source IT automation tool
- Provisioning
- Configuration Management
- Application Deployment
- Continuous Delivery
- Security & Compliance
- Orchestration
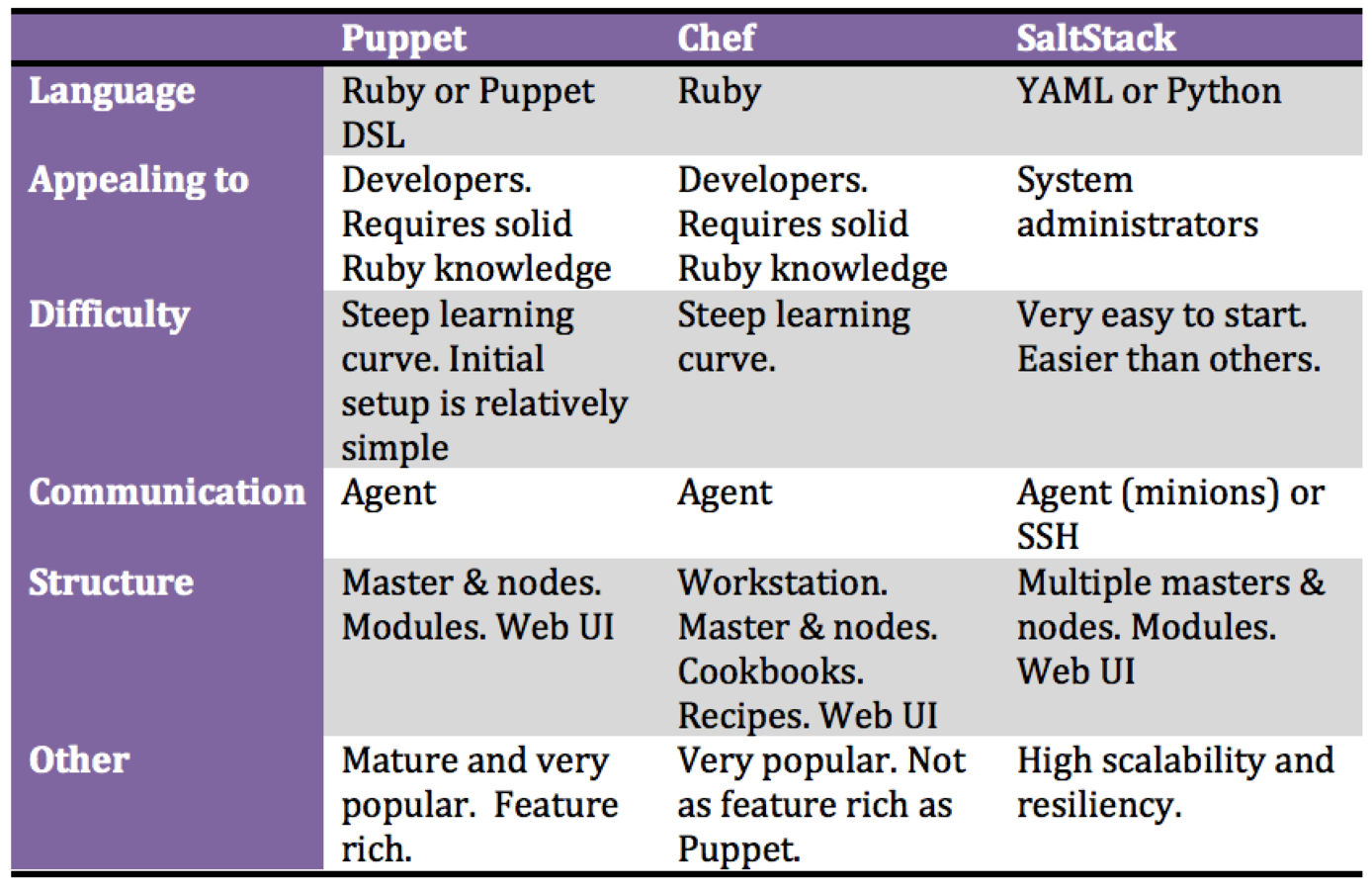
What are the options?

What are the options?
Why Ansible?
- Agent-less architecture (no agent is required, everything is done by using SSH, ssh for communication)
- No centralized server, no client-side agents
- SSH based
- Configuration as data, not code (YAML files)
- Batteries included
- Full conf. management, deployment and orchestration
- Custom modules can be written in any programming language.
- JSON input/output is sufficient to integrate a module into Ansible.
Life before Ansible
Multiple ssh, control panels, editing config files manually.

Let's install Ansible
Debian or Ubuntu:
apt-get install python-dev python-setuptools
easy_install pip
pip install ansible boto
Mac OS X:
sudo easy_install pip
sudo pip install ansible boto
Code of this talk
github.com/gulcin/pgconfeu2015
This example:
- Provision Amazon VPC and EC2 instances
- Install latest PostgreSQL packages
- Setup a streaming replication with 1 master and 2 standbys
- Add a new standby server
Building Blocks
Typically,
our solutions executes tasks for an inventory,
utilizing some modules,
using or populating some variables,
processing some file templates,
in a playbook,
which can be organized in roles.

Inventory
- Tells Ansible about hosts it should manage
- Hostnames, IPs, ports, SSH parameters
- Server specific variables
- 2 common ways to provide Ansible an inventory:
- Hosts are grouped. They can belong to multiple groups
- Groups can also belong to multiple groups
Inventory
Below inventory file in INI format contains 3 hosts under 2 groups.
There is also a 3rd group which contains other groups and all of the hosts.
# "master" group with 1 host
[master]
postgresql-master ansible_ssh_host=10.0.0.5 ansible_ssh_user=ubuntu
# "standby" group with 2 hosts
[standbys]
postgresql-standby-01 ansible_ssh_host=10.0.0.10 ansible_ssh_user=ubuntu
postgresql-standby-02 ansible_ssh_host=10.0.0.11 ansible_ssh_user=ubuntu
# the "replication" group contains both "master" and "standbys" groups
[replication:children]
master
standbysModule
- Modules provide Ansible means to control or manage resources on local or remote servers.
- They perform a variety of functions. For example a module may be responsible for rebooting a machine or it can simply display a message on the screen.
- Ansible allows users to write their own modules and also provides out-of-the-box core or extras modules.
- Core
- Extras
Module
Some of the most commonly used modules are:
-
File handling: file, stat, copy, template
-
Remote execution: command, shell
-
Service management: service
-
Package management: apt, yum, bsd, ports
- Source control systems: git, subversion
Task
Tasks are responsible for calling a module with a specific set of parameters.
Each Ansible task contains:
- a descriptive name [optional]
- a module to be called
- module parameters
- pre/post-conditions [optional]
- processing directives [optional]
They allow us to call Ansible modules and pass information to consecutive tasks.
Task
Below task invokes the "file" module by providing 4 parameters. It ensures 3 conditions are true:
- /var/lib/postgresql exists as a directory
- owner of /var/lib/postgresql is "postgres"
- group of /var/lib/postgresql is "postgres"
If it doesn't exist, Ansible creates the directory and assigns owner & group. If only the owner is different, Ansible makes it "postgres".
- name: Ensure the data folder has right ownership
file: path="/var/lib/postgresql" state=directory owner=postgres group=postgres
Task
Following example shows relationships between tasks. The first task checks if a device exists and the second task mounts the device depending on the result from the first task.
Please note "register" and "when" keywords.
- name: Check if the data volume partition exists
stat: path=/dev/sdc1
register: partition
- name: Ensure the PostgreSQL data volume is mounted
mount: src=/dev/sdc1 name="/var/lib/postgresql/9.4" fstype=ext4 state=mounted
when: partition.stat.exists is defined and partition.stat.existsVariable
Variables in Ansible are very useful for reusing information. Sources for variables are:
- Inventory: We can assign variables to hosts or groups (group vars, host vars).
- YAML files: We can include files containing variables.
- Task results: Result of a task can be assigned to a variable using the register keyword as shown in the previous slide.
- Playbooks: We can define variables in Ansible playbooks (more on that later).
- Command line: (-e means extra variable // -e "uservar=gulcin")
Variable
There is also discovered variables (facts) and they can be found by using setup module:
- All of the output in json: bios_version, architecture, default_ipv4_address, ansible_os_family, etc.
You can use variables in tasks, templates themselves and you can iterate over using with_type functions.
ansible -i hosts.ini -m setup hostname- name: Ensure PostgreSQL users are present
postgresql_user:
state: present
name: "{{ item.name }}"
password: "{{ item.password }}"
role_attr_flags: "{{ item.roles }}"
with_items: postgresql_usersTemplate
We can think templates as our configuration files. Ansible lets us use the Jinja2 template engine for reforming and parameterising our files.
The Jinja2 templating engine offers a wide range of control structures, functions and filters..
Some of useful capabilities of Jinja2:
- for-loops
- join(), default(), range(), format()
- union(), intersect(), difference()
- | to_json, | to_nice_yaml, | from_json, | from_yml
- | min, | max, | unique, | version_compare, | random
Template
*:*:*:{{ postgresql_replication_user.name }}:{{ postgresql_replication_user.password }}
Let's check our pgpass.j2 template:
Let's have a look at pg_hba.conf.j2 file, too:
# Access to user from local without password, from subnet with password
{% for user in postgresql_users %}
local all {{ user.name }} trust
host all {{ user.name }} {{ ec2_subnet }} md5
{% endfor %}
# Replication user for standby servers access
{% for standby_ip in postgresql_standby_ips %}
host replication {{ postgresql_replication_user.name }} {{ standby_ip }}/32 md5
{% endfor %}
Playbook
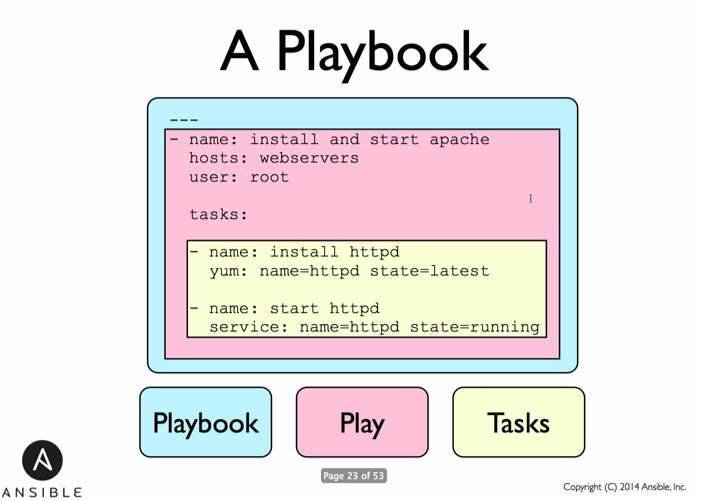
-
Playbooks contains Plays
-
Plays contain Tasks
- Tasks call Modules and may (optionally) trigger handlers (run once, run at the end)
-
Plays contain Tasks
Playbook
If Ansible modules are the tools in your workshop, playbooks are your design plans.
- Ansible playbooks are written using the YAML syntax.
- Playbooks may contain more than one plays
- Each play contains:
- name of host groups to connect to
- tasks it needs to perform.
Strict dependency ordering: everything in file performs in a sequential order. (Before v.2)
Playbook
Let's look at our playbook example (main.yml):
---
- name: Ensure all virtual machines are ready
hosts: 127.0.0.1
connection: local
vars_files: # load default variables from YAML files below
- 'defaults/postgresql.yml'
- 'defaults/aws.yml'
tasks:
- include: 'tasks/provision.yml' # load infrastructure setup tasks
- name: Ensure all required PostgreSQL dependencies ready
hosts: postgresql-all # manage all PostgreSQL servers
sudo: yes
sudo_user: root
vars_files:
- 'defaults/postgresql.yml'
- 'defaults/aws.yml'
tasks:
- include: 'tasks/postgresql.yml' # load PostgreSQL setup tasks
...Role
You absolutely should be using roles. Roles are great. Use roles. Roles! Did we say that enough? Roles are great.
In Ansible,
- playbooks organize tasks
- roles organize playbooks
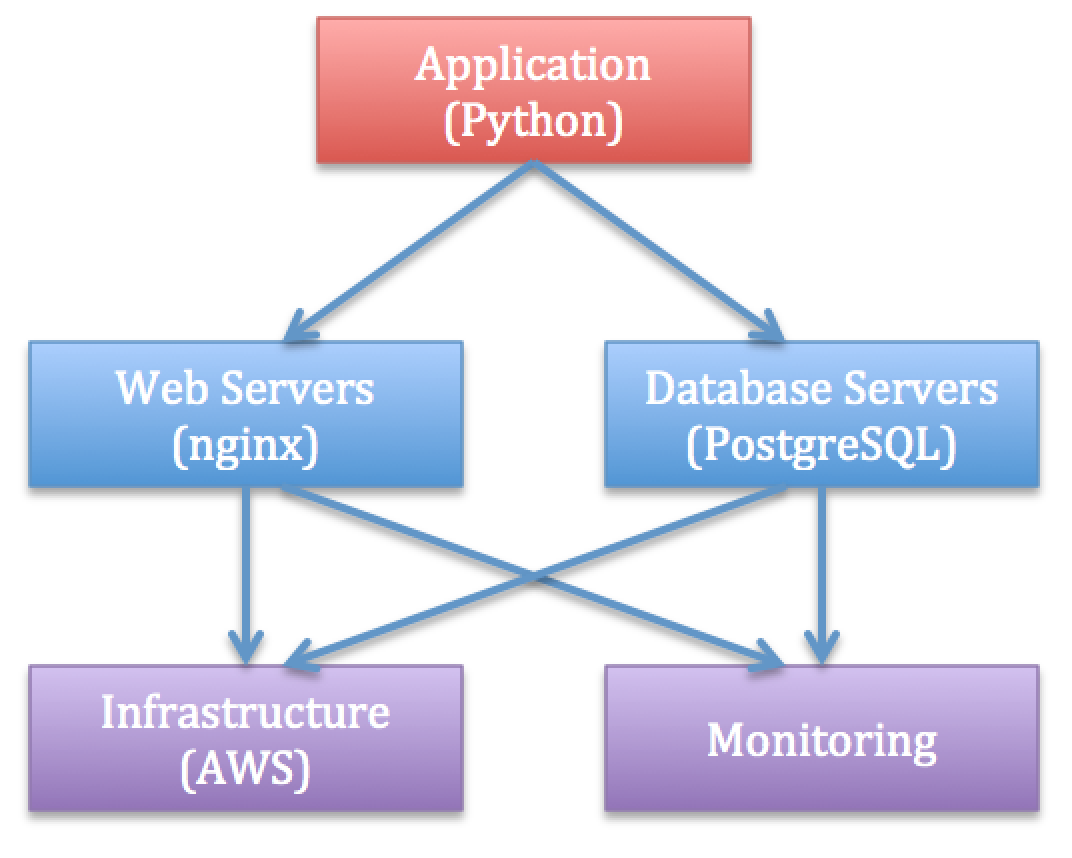
Imagine that we have lots of independent resources to manage (e.g., web servers, PostgreSQL servers, logging, monitoring, AWS, ...).
Putting everything in a single playbook may result in an unmaintainable solution.
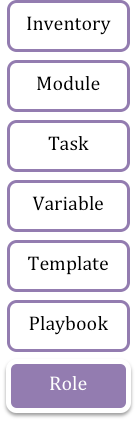
Role
Here you can see a dependency graph and the corresponding role directory structure:

How to Invoke Ansible?
To work with Ansible, we have 2 main alternatives;
- Running ad-hoc commands
- Running playbooks
Let's check them out one by one.
Ad-hoc Commands
We can call any Ansible module from the command line, anytime.
The ansible CLI tool works like a single task. It requires an inventory, a module name, and module parameters.
For example, given an inventory file like:
[dbservers] db.example.com
Now we can call any module.
Ad-hoc Commands
We can check uptimes of all hosts in dbservers using:
ansible dbservers -i hosts.ini -m command -a "uptime"
Here we can see the Ansible output:
gulcin@apathetic ~ # ansible dbservers -i hosts.ini -m command -a "uptime"
db.example.com | success | rc=0 >>
21:16:24 up 93 days, 9:17, 4 users, load average: 0.08, 0.03, 0.05
How to Run Playbooks?
For more complex scenarios, we can create playbooks or roles and ask Ansible to run them.
When we run a playbook or a role, Ansible first gathers a lot of useful facts about remote systems it manages. These facts can later be used in playbooks, templates, config files, etc.
We can use the ansible-playbook CLI tool to run playbooks.
How to Run Playbooks?
Given an inventory file like this:
[dbservers]
db.example.com
We may have a playbook that connects to hosts in dbservers group, executes the uptime command, and then displays that command's output.
Now let's create a simple playbook to see how it can be ran.
How to Run Playbooks?
Here is the main.yml file for the playbook we just described:
---
- hosts: dbservers
tasks:
- name: retrieve the uptime
command: uptime
register: command_result # Store this command's result in this variable
- name: Display the uptime
debug: msg="{{ command_result.stdout }}" # Display command output here
How to Run Playbooks?
Now we can run the playbook and see it's output here:
gulcin@apathetic ~ $ ansible-playbook -i hosts.ini main.yml
PLAY [dbservers] **************************************************************
GATHERING FACTS ***************************************************************
ok: [db.example.com]
TASK: [retrieve the uptime] ***************************************************
changed: [db.example.com]
TASK: [Display the uptime] ****************************************************
ok: [db.example.com] => {
"msg": " 15:54:47 up 3 days, 14:32, 2 users, load average: 0.00, 0.01, 0.05"
}
PLAY RECAP ********************************************************************
db.example.com : ok=3 changed=1 unreachable=0 failed=0
Postgres modules
My blog post covers Ansible PostgreSQL modules: Ansible Loves PostgreSQL
You can find the related Postgres modules' examples on my github repo.
-
postgresql_db: Creates/removes a given db.
-
postgresql_ext: Adds/removes extensions from a db.
-
postgresql_user: Adds/removes users and roles from a db.
-
postgresql_privs: Grants/revokes privileges on db objects (table, sequence, function, db, schema, language, tablespace, group).
- postgresql_lang: Adds, removes or changes procedural languages with a db.
Creates/removes a given db. In Ansible terminology, it ensures that a given db is present or absent.
- Required param: name
- Connection params: login_host, port,login_user, login_password
- Important param: state (present or absent)
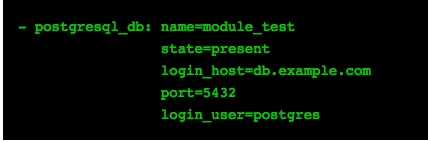
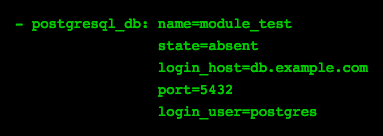
Create db module_test
Remove db module_test
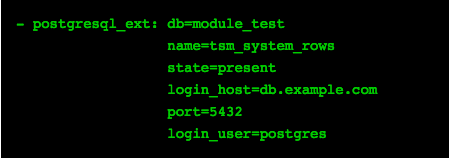
Adds/removes extensions from a db. PostgreSQL offers a wide range of extensions which are extremely helpful.
- Mandatory params: db and name (for extension)
- Other params: state and connection params (login_host, port) as in postgres_db
Adds/removes users and roles from a db.
Parameters: name (mandatory), state, connection params, db, password, priv, role_attr_flags ([NO]SUPERUSER, [NO]CREATEDB..)
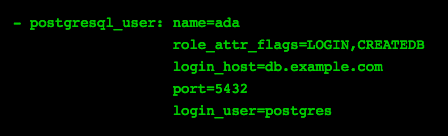

Creates user
Alters role and gives login and createdb
Grants/revokes privileges on db objects (table, sequence, function, db, schema, language, tablespace, group).
- Required params: database, roles
- Important opt. params: type (i.e. table,sequence,function), objs, privs (i.e. ALL; SELECT, UPDATE, INSERT)

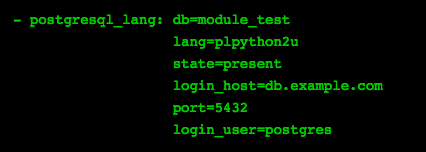
Adds, removes or changes procedural languages with a db.
One of the very powerful features of PostgreSQL is its support for virtually any language to be used as a procedural language.
Params: lang (mandatory), db, connection params, state, cascade, trust
AWS modules
Ansible provides more than 50 modules for provisioning and managing Amazon Web Services resources.
http://docs.ansible.com/ansible/list_of_cloud_modules.html
We have modules for:
- EC2 (Virtual machine instances)
- AMI (Virtual machine images)
- ELB (Load balancers)
- VPC (Networking infrastructure)
- EBS (Storage infrastructure)
- ...
AWS modules
Ansible AWS modules are developed using Boto.
Boto is a Python package that provides interfaces to Amazon Web Services.
For more complex workflows, we can use the ec2.py script to discover dynamic inventories for our playbooks:
- Download ec2.py and ec2.ini from github.com/ansible/ansible/tree/devel/contrib/inventory
- cp ec2.py /etc/ansible/hosts
- cp ec2.ini /etc/ansible
- chmod +x /etc/ansible/hosts
Playbook structure
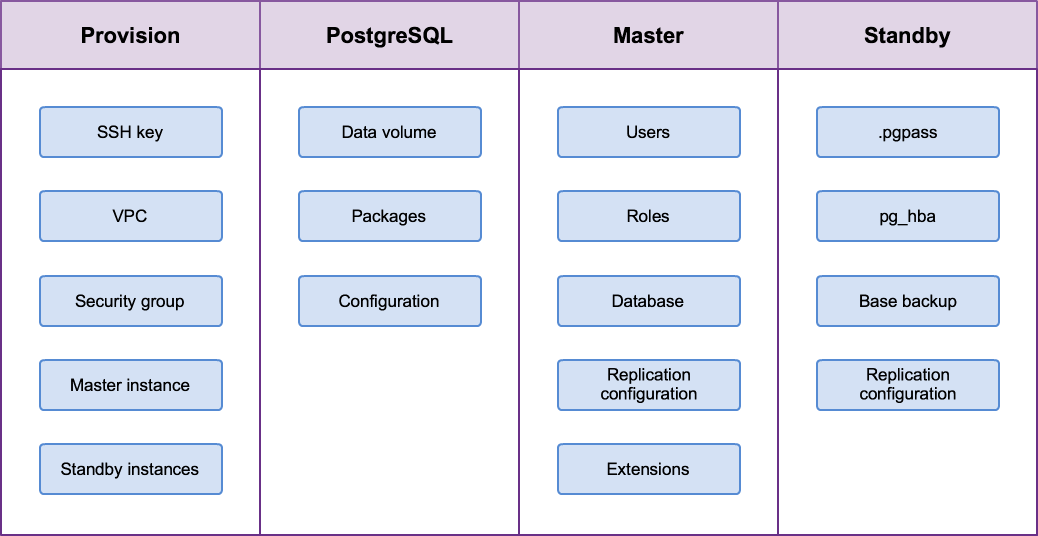
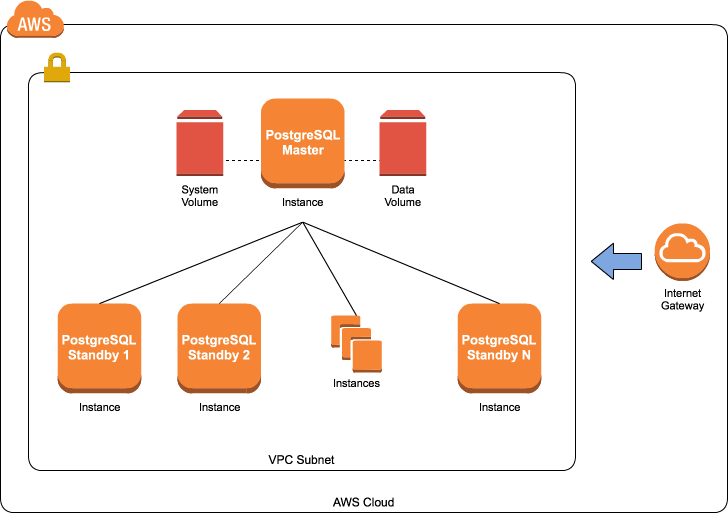
Playbook AWS architecture
Action!

First run
New standby server
Conclusion
Ansible loves PostgreSQL and Ansible has a very active community.
<wishlist>
That's why more PostgreSQL modules would be helpful for everyone.
Making contributions to Ansible will be appreciated :)
</wishlist>
Questions?

Huge Thanks!
References
Ansible quick start video http://www.ansible.com/videos
Review: Puppet vs Chef vs Ansible vs Salt http://www.infoworld.com/article/2609482/data-center/data-center-review-puppet-vs-chef-vs-ansible-vs-salt.html
Managing PostgreSQL with Ansible in EC2 https://www.safaribooksonline.com/library/view/velocity-conference-2013/9781449371630/part22.html
Jinja2 for better Ansible playbooks and templates
https://blog.codecentric.de/en/2014/08/jinja2-better-ansible-playbooks-templates/
Edmund The Elephant https://dribbble.com/shots/2223604-Edmund-The-Elephant