Solr on Cloud
Tallinn University of Technology
Introduction to Development in Cloud by Anton Vedešin
Road Management Team
What is ?
Solr is the popular, blazing-fast open source enterprise search platform built on Apache Lucene™.
Solr powers the search and navigation features of many of the world's largest internet sites.
What is not ?



Key aspects of
- highly reliable
- scalable
- fault tolerant
- provides distributed indexing
- replication
- load-balanced querying
- automated failover and recovery
- centralised configuration

Why we need ?
- optimised for search
- larges volumes of documents
- text-centric
- results sorted by relevance
- read-dominant
- document-oriented
- flexible schema


How it works?
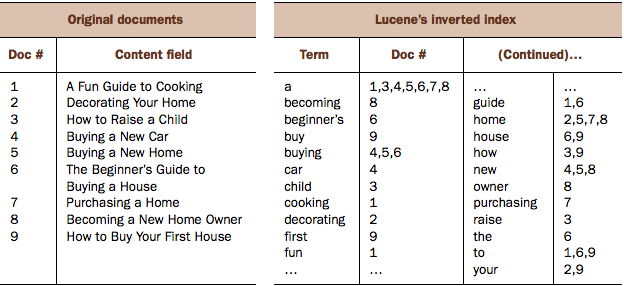
All terms in the index map to one or more documents.
Terms in the inverted index are sorted in ascending lexicographical order
Inverted index
Finding sets of documents
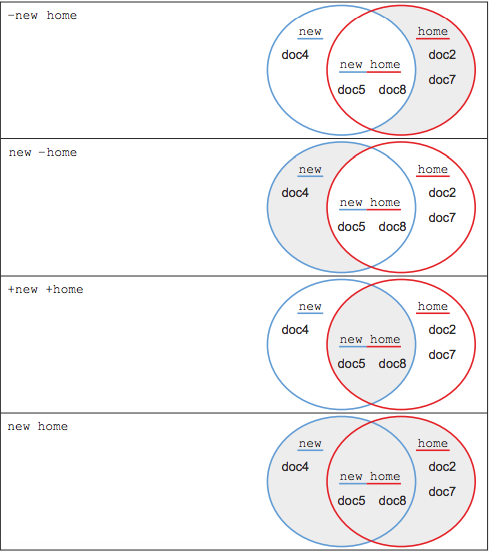
Relevancy calculation
- term frequency (tf)
- inverse document frequency (idf)
- term boosts (t.getBoost)
- field normalisation (norm)
- coordination factor (coord)
- query normalisation (queryNorm)
Score

Inverse term frequency (itf)
Not all search terms or created equal !


Unstructured data

Text-centric data

Read-dominant

Document-oriented

Flexible schema

Keyword search
- relevant results must be returned quickly
- spelling correction is needed
- autosuggestions save keystrokes
- synonyms of query terms must be recognised
- phrase handling is needed
- queries with common words must be handled
- show more results if the top results aren’t satisfactory
Ranked retrieval
Faceted search
Scalable

cache management
concurrent queries
CPU & I/O constraints
query throughput
number of documents indexed
replicas
shards
Fault-tolerant

number of documents indexed

Geospatial search

Multilingual support

Near real-time search (NRT)

Data modeling features
- Result grouping/field collapsing
- Flexible query support
- Joins
- Document clustering
- Importing rich document formats such as PDF, Word
- Importing data from relational databases
flat denormalised document
Other important features
- Atomic updates with optimistic concurrency
- Real-time get
- Write-durability using a transaction log
SolrCloud
- centralised configuration
- distributed indexing with no SPoF
- automated failover to a new shard leader
- queries can be sent to any node in a cluster to trigger a full, distributed search across all shards, with failover and load-balancing support built in.
fault-tolerance & high availability
Not to use !
- request a large result set
- do deep analytic tasks
- querying across relationships
- document-level security

References

Thank you!

Who?
Postgres DBA @ 2ndQuadrant
Studying MSc Comp. & Systems Eng. @ Tallinn University of Technology
Studied BSc Maths Eng. @ Yildiz Technical University
Writes blog on 2ndQuadrant blog
Does some childish paintings
Loves independent films
