Insight UBC: Deliverable 2
All code that follows should be considered as pseudo-code.
Do not copy and paste it on your project and hope that it works!
Disclaimer
Goals and specs
1. Add and remove a dataset containing information about UBC classrooms
Goals and specs
1. Add and remove a dataset containing information about UBC classrooms
rooms.zip
addDataset(...)
Parse it
Keep data structure in a variable
Save it to disk
Caching
same workflow as courses.zip BUT with different file types
InsightDatasetKind.Rooms
(kind)
Goals and specs
2. Answer queries about either UBC courses or rooms.
Goals and specs
Examples:
"what's the average of CPSC 340 ?"
2. Answer queries about either UBC courses or rooms.
Goals and specs
2. Answer queries about UBC courses. (current solution)
{
"WHERE":{
"AND": [
{ "IS":{ "courses_id": "*340*" } },
{ "IS":{ "courses_dept": "*cpsc*" }}
]
},
"OPTIONS":{
"COLUMNS":[
"courses_id", "courses_avg"
],
"ORDER":"courses_avg"
}
}Goals and specs
{"result": [
{ "courses_id": "340",
"courses_avg": 68.4 },
{ "courses_id": "340",
"courses_avg": 68.4 },
{ "courses_id": "340",
"courses_avg": 72.65 },
{ "courses_id": "340",
"courses_avg": 72.65 },
{ "courses_id": "340",
"courses_avg": 72.94 },
{ "courses_id": "340",
"courses_avg": 72.94 },
...
]}{
"WHERE":{
"AND": [
{ "IS":{ "courses_id": "*340*" } },
{ "IS":{ "courses_dept": "*cpsc*" }}
]
},
"OPTIONS":{
"COLUMNS":[
"courses_id", "courses_avg"
],
"ORDER":"courses_avg"
}
}not what we
were looking for
2. Answer queries about UBC courses. (current solution)
Goals and specs
2. Answer queries about UBC courses. (new query engine)
{
"result": [
{
"courses_id": "340",
"overallAvg": 75.69
}
]
}{
"WHERE":{
"AND": [
{ "IS":{ "courses_id": "*340*" } },
{ "IS":{ "courses_dept": "*cpsc*" }}
]
},
"OPTIONS":{
"COLUMNS":[
"courses_id", "overallAvg"
]
},
"TRANSFORMATIONS":{
"GROUP":[ "courses_id"],
"APPLY": [
{
"overallAvg": {
"AVG": "courses_avg"
}
}
]
}
}this is the right result!
Goals and specs
2. Answer queries about UBC courses. New EBNF:
QUERY ::='{'BODY ', ' OPTIONS (', ' TRANSFORMATIONS)? '}'
BODY ::= 'WHERE:{' (FILTER)? '}'
OPTIONS ::= 'OPTIONS:{' COLUMNS ', ' (SORT)?'}'
TRANSFORMATIONS ::= 'TRANSFORMATIONS: {' GROUP ', ' APPLY '}'
FILTER ::= (LOGICCOMPARISON | MCOMPARISON | SCOMPARISON | NEGATION)
LOGICCOMPARISON ::= LOGIC ':[{' FILTER ('}, {' FILTER )* '}]'
MCOMPARISON ::= MCOMPARATOR ':{' key ':' number '}'
SCOMPARISON ::= 'IS:{' key ':' [*]? inputstring [*]? '}' // inputstring may have option * characters as wildcards
NEGATION ::= 'NOT :{' FILTER '}'
LOGIC ::= 'AND' | 'OR'
MCOMPARATOR ::= 'LT' | 'GT' | 'EQ'
COLUMNS ::= 'COLUMNS:[' (key ',')* key ']'
SORT ::= 'ORDER: ' ('{ dir:' DIRECTION ', keys: [ ' key (',' key)* ']}' | key)
DIRECTION ::= 'UP' | 'DOWN'
GROUP ::= 'GROUP: [' (key ',')* key ']'
APPLY ::= 'APPLY: [' (APPLYKEY (', ' APPLYKEY )* )? ']'
APPLYKEY ::= '{' key ': {' APPLYTOKEN ':' key '}}'
APPLYTOKEN ::= 'MAX' | 'MIN' | 'AVG' | 'COUNT' | 'SUM'
key ::= string '_' string
inputstring ::= [^*]* // zero or more of any character except asterisk.Activity #1
Take a few minutes and discuss with your partner what strategies could be used to integrate the new data set into your existing solution.
Share your strategy (not your code) with other teams.
- Are they equal?
- How they differ?
- Which one better suits our problem?
- Wait. Do we have a problem? What is our problem?
10~15 min
addDataset(...)
new code
kind?
existing code
parse courses
parse rooms
Keep data structure in a variable
Save it to disk
Activity #1. Do we have a problem?
return new Promise(function (fulfill, reject) {
try {
const myZip = new Zip();
if (kind === InsightDatasetKind.Courses) {
// Extract the content
zip = myZip.extract();
for (file in files inside zip) {
try{
contents = file.getContent();
for (section in results) {
// do something
}
} catch (err) {
// do something
}
});
// more code here
} else if (kind === InsightDatasetKind.Rooms) {
// We are just going to copy and paste the code above and generate ourselves a problem
} else {
// keep doing the same strategy until our code is doomed
}
// more code here
// even more code
// ...
} catch (err) {
// do something
}
});Do we have a problem?
return new Promise(function (fulfill, reject) {
try {
const myZip = new Zip();
if (kind === InsightDatasetKind.Courses) {
// Extract the content
zip = myZip.extract();
for (file in files inside zip) {
try{
contents = file.getContent();
for (section in results) {
// do something
}
} catch (err) {
// do something
}
});
// more code here
} else if (kind === InsightDatasetKind.Rooms) {
// Extract the content
zip = myZip.extract();
for (file in files inside zip) {
try{
contents = file.getContent();
for (rooms in results) {
// do something
}
} catch (err) {
// do something
}
});
// more code here
} else {
// keep doing the same strategy until our code is doomed
}
// more code here
// even more code
// ...
} catch (err) {
// do something
}
});1. software readability
2. software maintainability
3. software testability
Do we have a problem?

A few words about code complexity
<sneak peak of the next tutorial>
Jack the Ripper will claim his 5th victim in the DatasetController district....
return new Promise(function (fulfill, reject) {
try {
const myZip = new JSZip();
if (kind === InsightDatasetKind.Courses) {
// Extract the content
zip = myZip.extract();
for (file in files inside zip) {
try{
contents = file.getContent();
for (section in results) {
// do something
}
} catch (err) {
// do something
}
});
} else if (kind === InsightDatasetKind.Rooms) {
// We are just going to copy and paste the code above and generate ourselves a problem
} else {
// keep doing the same strategy until our code is doomed
}
// more code here
// even more code
// ...
} catch (err) {
// do something
}
});return new Promise(function (fulfill, reject) {
try {
const myZip = new JSZip();
if (kind === InsightDatasetKind.Courses) {
// Extract the content
zip = myZip.extract();
for (file in files inside zip) {
contents = this.parseCoursesFile(file);
});
} else if (kind === InsightDatasetKind.Rooms) {
// We are just going to copy and paste the code above and generate ourselves a problem
} else {
// keep doing the same strategy until our code is doomed
}
// more code here
// even more code
// ...
} catch (err) {
// do something
}
});calls the method that encapsulates the behavior of parsing a single file
private parseCoursesFile(file): <figure out this type> {
const result = <something>;
try{
contents = file.getContent();
for (section in results) {
// do something
}
} catch (err) {
// do something
}
return result;
}Refactoring
Is the process of restructuring existing code without changing its behavior -- Wikipedia
Extract method: roughly moves some code to a smaller and well contained method
Activity #2
Now that we have a glimpse about how to encapsulate some of the dataset behavior into methods. Discuss with your partner about at least 3 methods that you can extract for the addDataset method.
- Does this help you integrating the new rooms dataset?
- How can you be sure that your code still works after refactoring?
~5 min
Activity #2
- Does this help you integrating the new rooms dataset?
Your code should be open for extension, but close for modification [more to come]
Test suites! Never change your code if you don't have tests that cover that functionality
- Methods e.g.
- parseCourses ( zip )
- parseCoursesFile ( file )
- parseRooms ( zip )
- parseRoomsFile ( file )
- saveToDisk ( your datasets data structure )
- How can you be sure that your code still works after refactoring?
Activity #2
D2 - Further clarifications
The rooms dataset
index.htm
/campus/
/campus/discover/
/campus/discover/buildings-and-classrooms/
/campus/discover/buildings-and-classrooms/AAC
/campus/discover/buildings-and-classrooms/ACEN
/campus/discover/buildings-and-classrooms/ACU
/campus/discover/buildings-and-classrooms/AERL
/campus/discover/buildings-and-classrooms/ALRD
...
- Files in HTML format, parsable using the parse5 package
- Each file other than index.htm represents a building and its rooms
- All buildings linked from the index should be considered valid buildings
zip.files
?
?
single file
e.g. AAC
your datastructure
parse5 datastructure
parse5
const document = parse5.parse(<my file>) as parse5.AST.Default.Document;** code snippet taken from http://inikulin.github.io/parse5/
* sample html/output taken from http://astexplorer.net/#/1CHlCXc4n4
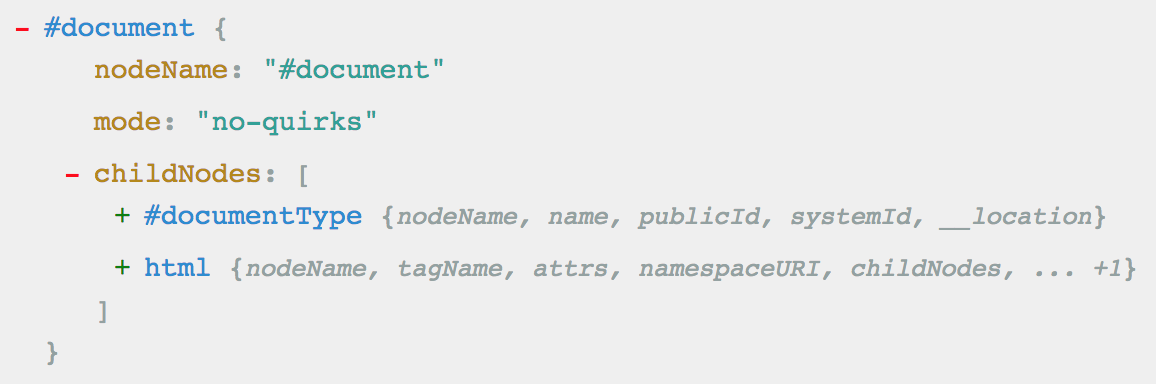
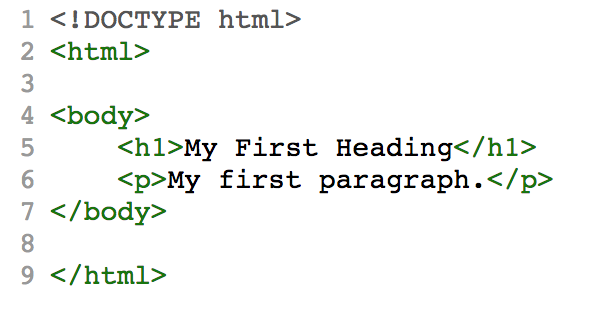
<html><body><h1><p>My first headingMy first paragraph
- Inspect the html files in the dataset, take a look at them and try to find useful information
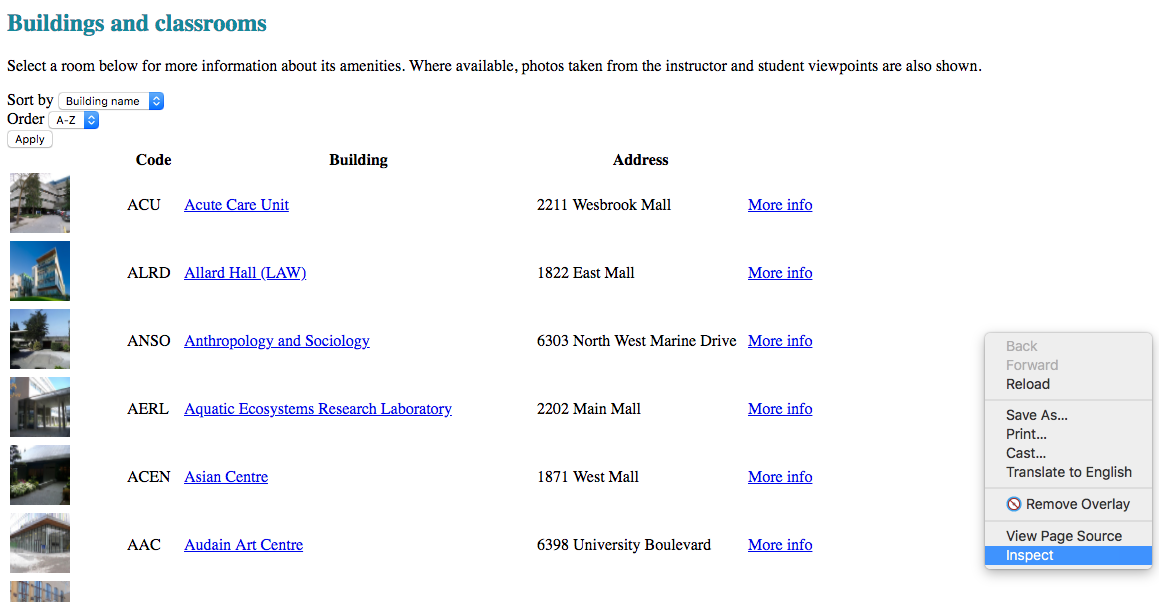
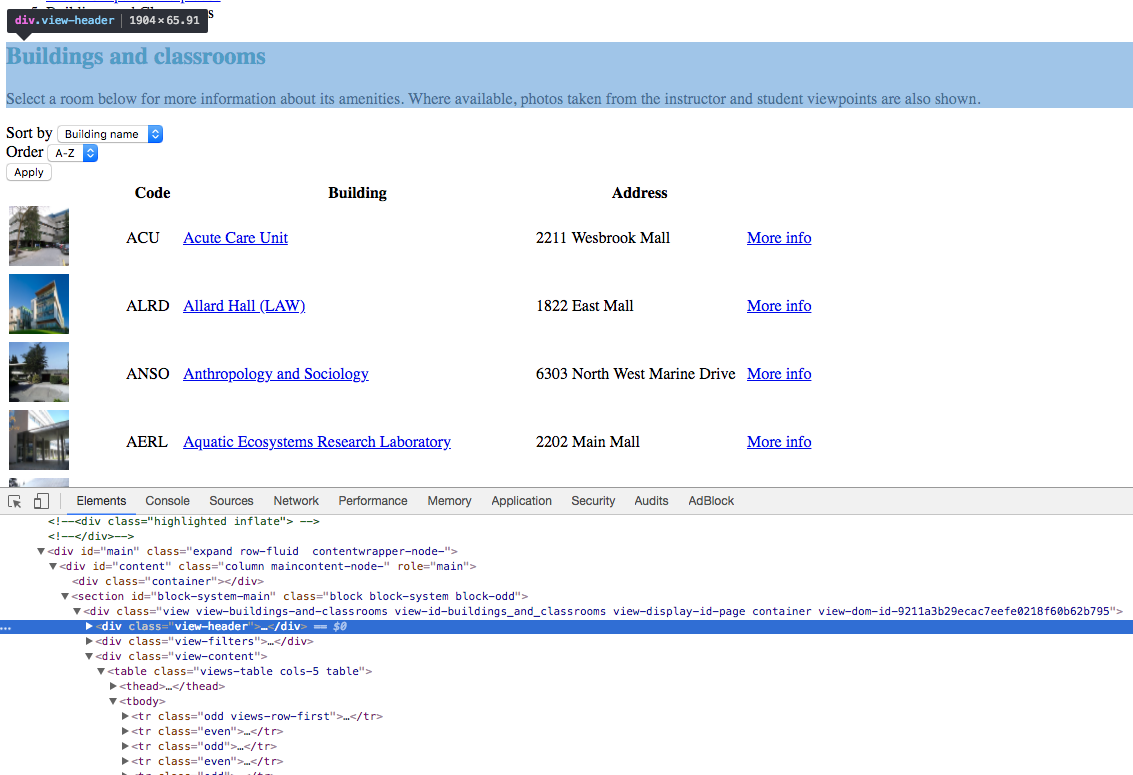
tree node for that element
current html element that I'm inspecting
Demo
HTTP

GET http://skaha.cs.ubc.ca:11316/api/v1/team666/6245%20Agronomy%20Road%20V6T%201Z46245 Agronomy Road V6T 1Z46245%20Agronomy%20Road%20V6T%201Z4address
URL-encoded address
status: 200,
body: {"lat":49.26125,"lon":-123.24807}request
response
* Take a look at https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol for a more comprehensive explanation of HTTP
client
server
const request = require('request');
request({
method: 'GET',
uri: 'http://skaha.cs.ubc.ca:11316/api/v1/team6/6245%20Agronomy%20Road%20V6T%201Z4',
gzip: true
}).on('response', function(response) {
console.log("status: " + response.statusCode);
}).on('data', function(data) {
// decompressed data as it is received
console.log('decoded chunk: ' + data)
});status: 200
decoded chunk: {
"lat":49.26125,
"lon":-123.24807
}* https://github.com/request/request
* This code will not work in your project ! You are supposed to use the http package instead of request.
HTTP
const request = require('request');
request({
method: 'GET',
uri: 'http://skaha.cs.ubc.ca:11316/api/v1/???',
gzip: true
}).on('data', function(data) {
// decompressed data as it is received
console.log('decoded chunk: ' + data)
}).on('response', function(response) {
console.log("status: " + response.statusCode);
});status: 404
decoded chunk: {
"code":"ResourceNotFound",
"message":"/api/v1/ does not exist"
}HTTP
* https://github.com/request/request
* This code will not work in your project ! You are supposed to use the http package instead of request.
Query Aggregation
[
{ "courses_uuid": "1", "courses_instructor": "Jean", "courses_avg": 90, "courses_title" : "310"},
{ "courses_uuid": "2", "courses_instructor": "Jean", "courses_avg": 80, "courses_title" : "310"},
{ "courses_uuid": "3", "courses_instructor": "Casey", "courses_avg": 95, "courses_title" : "310"},
{ "courses_uuid": "4", "courses_instructor": "Casey", "courses_avg": 85, "courses_title" : "310"},
{ "courses_uuid": "5", "courses_instructor": "Kelly", "courses_avg": 74, "courses_title" : "210"},
{ "courses_uuid": "6", "courses_instructor": "Kelly", "courses_avg": 78, "courses_title" : "210"},
{ "courses_uuid": "7", "courses_instructor": "Kelly", "courses_avg": 72, "courses_title" : "210"},
{ "courses_uuid": "8", "courses_instructor": "Eli", "courses_avg": 85, "courses_title" : "210"},
]
Query Aggregation
{
"WHERE": {
"GT": { "courses_avg": 70 }
},
"OPTIONS": {
"COLUMNS": ["courses_title", "overallAvg"]
},
"TRANSFORMATIONS": {
"GROUP": ["courses_title"],
"APPLY": [{
"overallAvg": {
"AVG": "courses_avg"
}
}]
}
}Query Aggregation
[
{ "courses_uuid": "1", "courses_instructor": "Jean", "courses_avg": 90, "courses_title" : "310"},
{ "courses_uuid": "2", "courses_instructor": "Jean", "courses_avg": 80, "courses_title" : "310"},
{ "courses_uuid": "3", "courses_instructor": "Casey", "courses_avg": 95, "courses_title" : "310"},
{ "courses_uuid": "4", "courses_instructor": "Casey", "courses_avg": 85, "courses_title" : "310"},
{ "courses_uuid": "5", "courses_instructor": "Kelly", "courses_avg": 74, "courses_title" : "210"},
{ "courses_uuid": "6", "courses_instructor": "Kelly", "courses_avg": 78, "courses_title" : "210"},
{ "courses_uuid": "7", "courses_instructor": "Kelly", "courses_avg": 72, "courses_title" : "210"},
{ "courses_uuid": "8", "courses_instructor": "Eli", "courses_avg": 85, "courses_title" : "210"},
]
210 group310 group[
{ "courses_uuid": "1", "courses_instructor": "Jean",
"courses_avg": 90, "courses_title" : "310"},
{ "courses_uuid": "2", "courses_instructor": "Jean",
"courses_avg": 80, "courses_title" : "310"},
{ "courses_uuid": "3", "courses_instructor": "Casey",
"courses_avg": 95, "courses_title" : "310"},
{ "courses_uuid": "4", "courses_instructor": "Casey",
"courses_avg": 85, "courses_title" : "310"},
][
{ "courses_uuid": "5", "courses_instructor": "Kelly",
"courses_avg": 74, "courses_title" : "210"},
{ "courses_uuid": "6", "courses_instructor": "Kelly",
"courses_avg": 78, "courses_title" : "210"},
{ "courses_uuid": "7", "courses_instructor": "Kelly",
"courses_avg": 72, "courses_title" : "210"},
{ "courses_uuid": "8", "courses_instructor": "Eli",
"courses_avg": 85, "courses_title" : "210"},
]avg: 77.25avg: 87.5let aux = [
{x:1, y:1}, {x:2, y:2}, {x:1, y:1},
{x:4, y:2}, {x:3, y:3}, {x:6, y:3},
{x:4, y:3}, {x:-1, y:3}, {x:5, y:2},
{x:1, y:2}, {x:2, y:2}, {x:3, y:1},
{x:4, y:2}, {x:-2, y:3}, {x:2, y:4},
{x:4, y:1}, {x:2, y:3}, {x:1, y:5},
{x:9, y:3},
]Activity #3
- Suppose you are given the grouped set below where each element has 2 coordinates, x and y.
- Someone decided to apply the LINEAR function to that group
- Write a method that computes the LINEAR
10~15 min
var linear = (acc, cur) => acc + Math.pow(cur.x, 2) / Math.abs(cur.y - 6)
aux.reduce(linear, 0)Activity #3
- for loop
var acc = 0;
for (cur of aux) {
acc += Math.pow(cur.x, 2) / Math.abs(cur.y - 6)
}- reduce
both achieve the same result
- Linear is not protected against divisions by 0 [{ x: ?, y = 6}].
What happens in that case?
[{x:2, y:6}, {x:3, y:4}].reduce(linear, 0)
InfinityGeneral tips and advice
#D1

#D1
D2 postponed tasks


Me trying to assist you in the day of the deadline
team that finished before grace period
Start early. Fail early.
Have enough time to fix things.
#1
Midterms season may start soon.
Make a schedule.
Divide your time.
#2
Whenever you have a problem, try to:
1. Describe what you're trying to do
2. Describe what is happening
3. Write a test case that encapsulate 1 and 2
4. Work using that single test as means to isolate your problem
#3
D2 - Extra slides
Debuging demo
.on('data', function(data) {
// decompressed data as it is received
console.log('decoded chunk: ' + data)
})HTTP
* Network courses cover this in more detail

complete response body does not fit the bandwidth
Hence, we break it small chunks that can be sent through the pipeline.
The client has to rebuild the response on its own.
Thankfully, our response is small enough to fit in a single package