GROUP
3

Shefali Bansal
Tanya Sharma
Arvind Srinivasan
Aarushi Sharma
Arkav Banerjee
Simran Singh
The Team
WHY SENTIMENTAL ANALYSIS?
WHY SENTIMENTAL ANALYSIS?
- Adjust marketing strategy
- Develop product quality
- Improve customer service
- Crisis management
- Lead generation
- Sales Revenue
SENTIMENT ANALYSIS
This section deals with the preprocessing of the dataset to extract the necessary features for seamless modelling
TEXT PREPROCESSING
-
Tokenisation
-
Normalisation
-
Punctuations
-
Stopwords
-
Lemmatizing
-
Stemming
-
VOCABULARY BUILDING
sklearn.feature_extraction.text.CountVectorizer
max_features : int or None
analyzer : string, {‘word’, ‘char’, ‘char_wb’} or callable
ngram_range : tuple (min_n, max_n)
max_df : float in range [0.0, 1.0] or int, default=1.0
min_df : float in range [0.0, 1.0] or int, default=1
LSTM
Long Short Term Memory
PROBLEM UNDER FOCUS
To analyse the reviews from the Yelp Dataset and classify them as being positive, negative or neutral reviews using the Long Short Term Memory Model.
SENTIMENT
ANALYSIS
WHat is LSTM?
Long short-term memory (LSTM) units (or blocks) are a building unit for layers of a recurrent neural network (RNN). A RNN composed of LSTM units is often called an LSTM network.
A common LSTM unit is composed of a cell, an input gate, an output gate and a forget gate.
Can remove or add Information with the help of structures known as Gates. Sends information optionally.
WHY USE LSTM?
There is the problem of long term dependencies in RNN.
Sometimes, we only need to look at recent information to perform the present task.
- In such cases, RNNs are pretty useful.
Sometimes, we need more context, or more older information.
- In such cases, RNNs do not perform well. (even though theoretically its possible, needs a lot of tuning of parameters and may not be generalised, due to possibility of GD Vanishing)
SENTIMENT ANALYSIS
This section deals with the preprocessing of the training dataset such that the data can be fitted over the Model under focus.
DATA PREPROCESSING
CHECKING DATA
First Check if any null values exist in the dataframe.
If found, drop any row found with inconsistency.
Remove everything other than alphabetical text such that there is no inconsistency between type of data in a column of a Dataframe.
Then perform Tokenisation.
TOKENISATION
Keras represents each word as a number, with the most common word in a given dataset being represented as 1, the second most common as a 2, and so on.
This is useful because we often want to ignore rare words, as usually, the neural network cannot learn much from these, and they only add to the processing time.
If we have our data tokenized with the more common words having lower numbers, we can easily train on only the N most common words in our dataset, and adjust N as necessary.
TOKENISER
Tokenizer
keras.preprocessing.text.Tokenizer(num_words=None, filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~ ', lower=True, split=' ', char_level=False, oov_token=None)
Text tokenization utility class.
This class allows to vectorize a text corpus, by turning each text into either a sequence of integers (each integer being the index of a token in a dictionary) or into a vector where the coefficient for each token could be binary, based on word count, based on tf-idf...
Arguments
- num_words: the maximum number of words to keep, based on word frequency. Only the most common num_words words will be kept.
- filters: a string where each element is a character that will be filtered from the texts. The default is all punctuation, plus tabs and line breaks, minus the ' character.
- lower: boolean. Whether to convert the texts to lowercase.
- split: str. Separator for word splitting.
- char_level: if True, every character will be treated as a token.
- oov_token: if given, it will be added to word_index and used to replace out-of-vocabulary words during text_to_sequence calls
By default, all punctuation is removed, turning the texts into space-separated sequences of words (words maybe include the ' character). These sequences are then split into lists of tokens. They will then be indexed or vectorized.
0 is a reserved index that won't be assigned to any word.
SENTIMENT ANALYSIS
Explains how the Model approaches the problem when certain parameters that influence the accuracy or convergence of the model are tuned.
MODEL
INSIGHTS
PARAMETERS
- hidden_nodes = This is the number of neurons of the LSTM. If you have a higher number, the network gets more powerful. Howevery, the number of parameters to learn also rises. This means it needs more time to train the network.
- timesteps = the number of timesteps you want to consider. E.g. if you want to classify a sentence, this would be the number of words in a sentence.
- input_dim = the dimensions of your features/embeddings. E.g. a vector representation of the words in the sentence
- dropout_value = To reduce overfitting, the dropout layer just randomly takes a portion of the possible network connections. This value is the percentage of the considered network connections per epoch/batch.
- As you will see, there is no need to specify the batch_size. Keras will automatically take care of it. The other parameters include learning_rate, decay and momentum which is used to improve model accuracy.
GENERATED MODEL
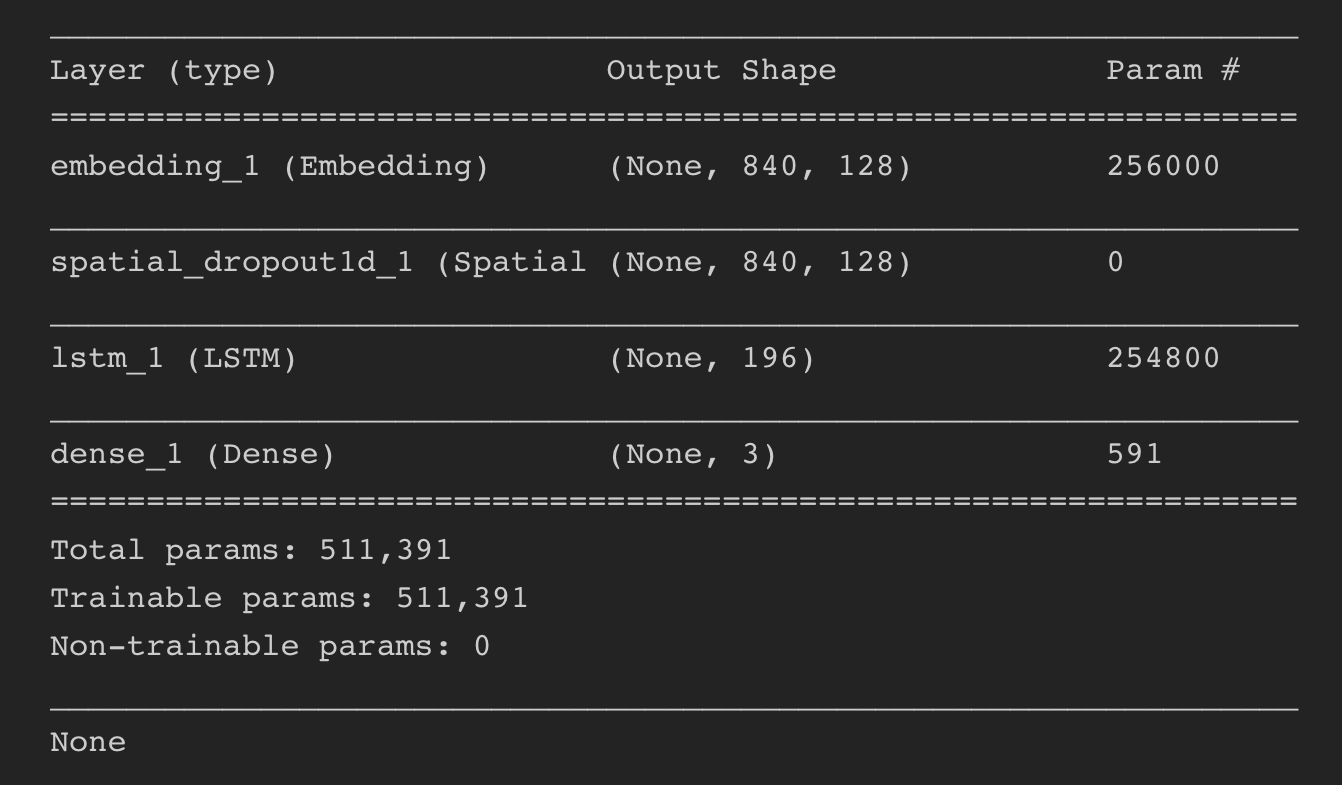
WHat is EMBEDDING?
- Embedding layer is a simple matrix multiplication that transforms words into their corresponding word embeddings.
- The weights of the Embedding layer are of the shape (vocabulary_size, embedding_dimension). For each training sample, its input are integers, which represent certain words. The integers are in the range of the vocabulary size. The Embedding layer transforms each integer i into the ith line of the embedding weights matrix.
- In order to quickly do this as a matrix multiplication, the input integers are not stored as a list of integers but as a one-hot matrix.
(nb_words, vocab_size) x (vocab_size, embedding_dim) = (nb_words, embedding_dim)
sentiment analysis
To verify that the model is accurately predicting the expected result for the test data set along with the validation accuracy that is obtained with the validation data set and the training dataset.
plotting
the model
WORKING ON A SAMPLE
As you can see, we are working on a sample of 10,000 data from the Dataset.
DIAGNOSTIC PLOTS FOR SAMPLE
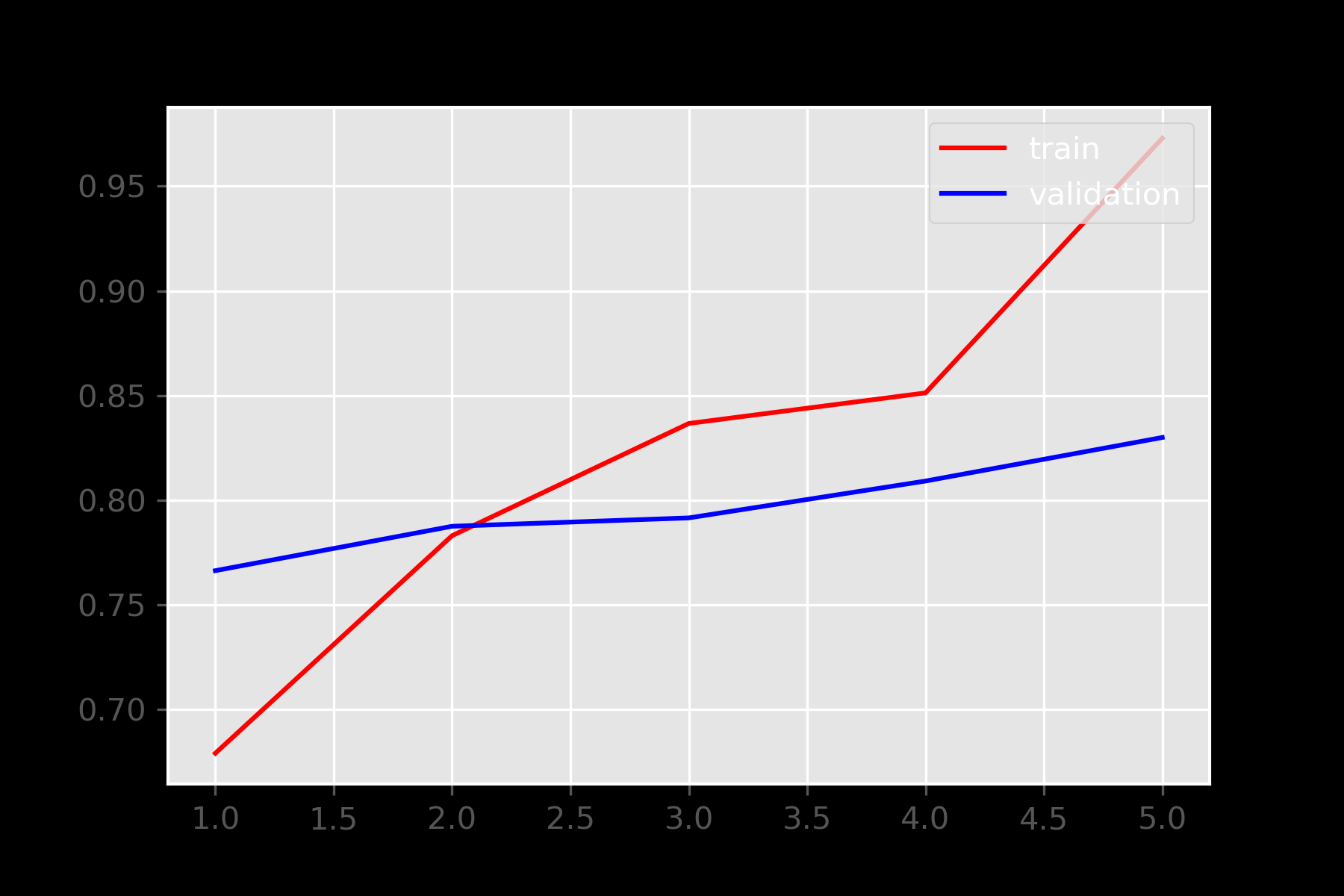
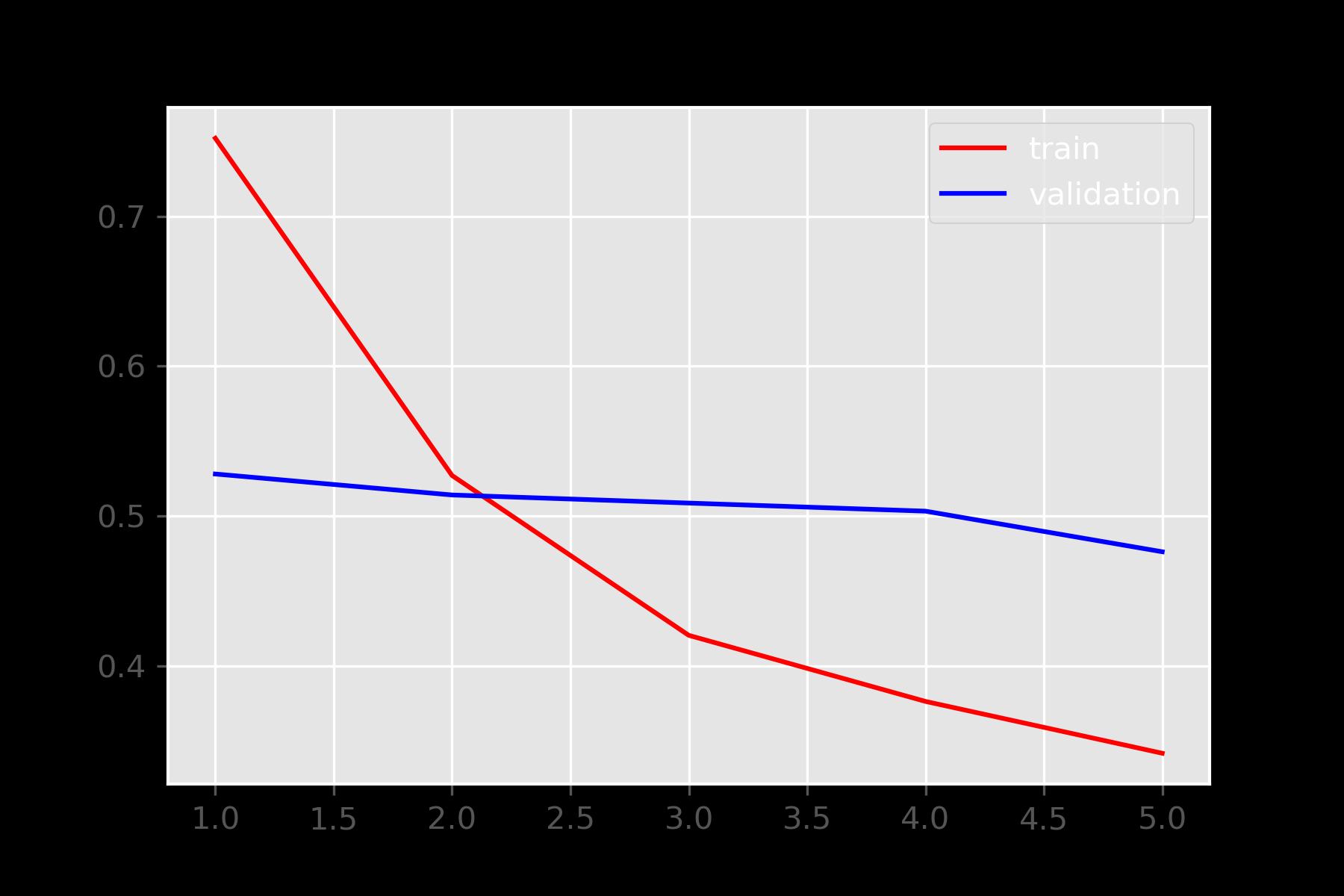
Left Graph is for Loss and the Right graph is for Accuracy
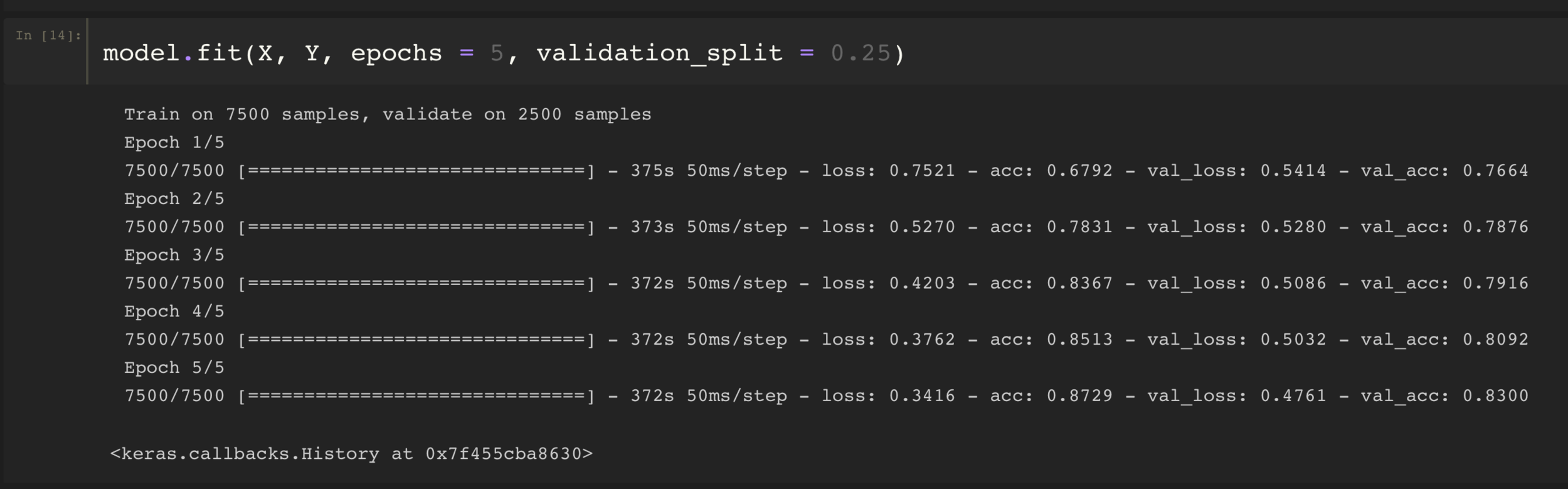
WORKING ON DATASET
We got an accuracy of 66% when running a epoch across the whole dataset.
We looked for all the possible errors that might have occured during the process and concluded on a few pointers.
- One of the possible reasons was that we ran the model with high validation dataset size.
- The other being that due to the high frequency of stop words that could not be removed prior fitting, might have drastically reduced the accuracy of the model.
Accuracy
66%
RF
Random Forests
PROBLEM UNDER FOCUS
To analyse the reviews from the Yelp Dataset and classify them as being positive, negative or neutral reviews using the Random Forest Model.
SENTIMENT
ANALYSIS
WHat is RANDOM FOREST?
An ensemble learning method of for classification and regression tasks.
Outputs the mode of the classes (classification) or mean prediction (regression) of the individual trees
Random forests use a modified tree learning algorithm that selects, at each candidate split in the learning process, a random subset of the features. This process is sometimes called "feature bagging".
WHY USE RANDOM FOREST?
Accuracy : Almost always better than Decision Trees.
The accuracy can be improved or tweaked by changing the max-depth parameter that limits the problem of overfitting, while other parameters like max-leaf-nodes, min_samples_split, min_samples_leaf etc. will help, to a certain extent for pruning process.
Robust : doesn’t suffer the instability problems of decision trees.
WORKING
Unlike decision tree, finding root node and splitting feature nodes will happen randomly
It works in 2 stages:
- Creation of rf
- Prediction of created rf
Creation of rf
- RANDOMLY select “k” features from total “m” features (k<<m)
- Of the k features, select node “d” using best split
- Split the node into daughter nodes
- Repeat the above 3 steps till a single node has been reached (tree) Repeat the above 4 steps to create “n” number of trees
PREDICTION IN rf
- Take test features and use rules of each randomly created trees to predict outcome
- Calculate votes for each predicted target
- Consider high voted predicted target as final prediction from RF also
SENTIMENT ANALYSIS
This section deals with the preprocessing of the training dataset such that the data can be fitted over the Model under focus.
DATA PREPROCESSING
CHECKING DATA
First Check if any null values exist in the dataframe.
If found, drop any row found with inconsistency.
Now follow the Steps as mentioned in the Feature Text Preprocessing Section.
Accuracy
74%
NB
Multinomial Naive Bayes
PROBLEM UNDER FOCUS
To analyse the reviews from the Yelp Dataset and classify them as being positive, negative or neutral reviews using the Multinomial Naive Bayes Model.
SENTIMENT
ANALYSIS
WHat is naive bayes?
A classification algorithm.
Follows supervised learning approach.
Models a problem probabilistically.
Based on an assumption that all the attributes are conditionally independent.
Can solve a problem involving categorical attributes.
WHY USE MULTINOMIAL NB?
Multinomial Naive Bayes is a specialized version of Naive Bayes that is designed more for text documents. Whereas simple Naive Bayes would model a document as the presence and absence of particular words, multinomial naive bayes explicitly models the word counts and adjusts the underlying calculations to deal with in.
So, to classify into multiple categories, (3) Multinomial NB is used.
SENTIMENT ANALYSIS
This section deals with the preprocessing of the training dataset such that the data can be fitted over the Model under focus.
DATA PREPROCESSING
CHECKING DATA
First Check if any null values exist in the dataframe.
If found, drop any row found with inconsistency.
Now follow the Steps as mentioned in the Feature Text Preprocessing Section.
sentiment analysis
To verify that the model is accurately predicting the expected result for the test data set along with the validation accuracy that is obtained with the validation data set and the training dataset.
plotting
the model
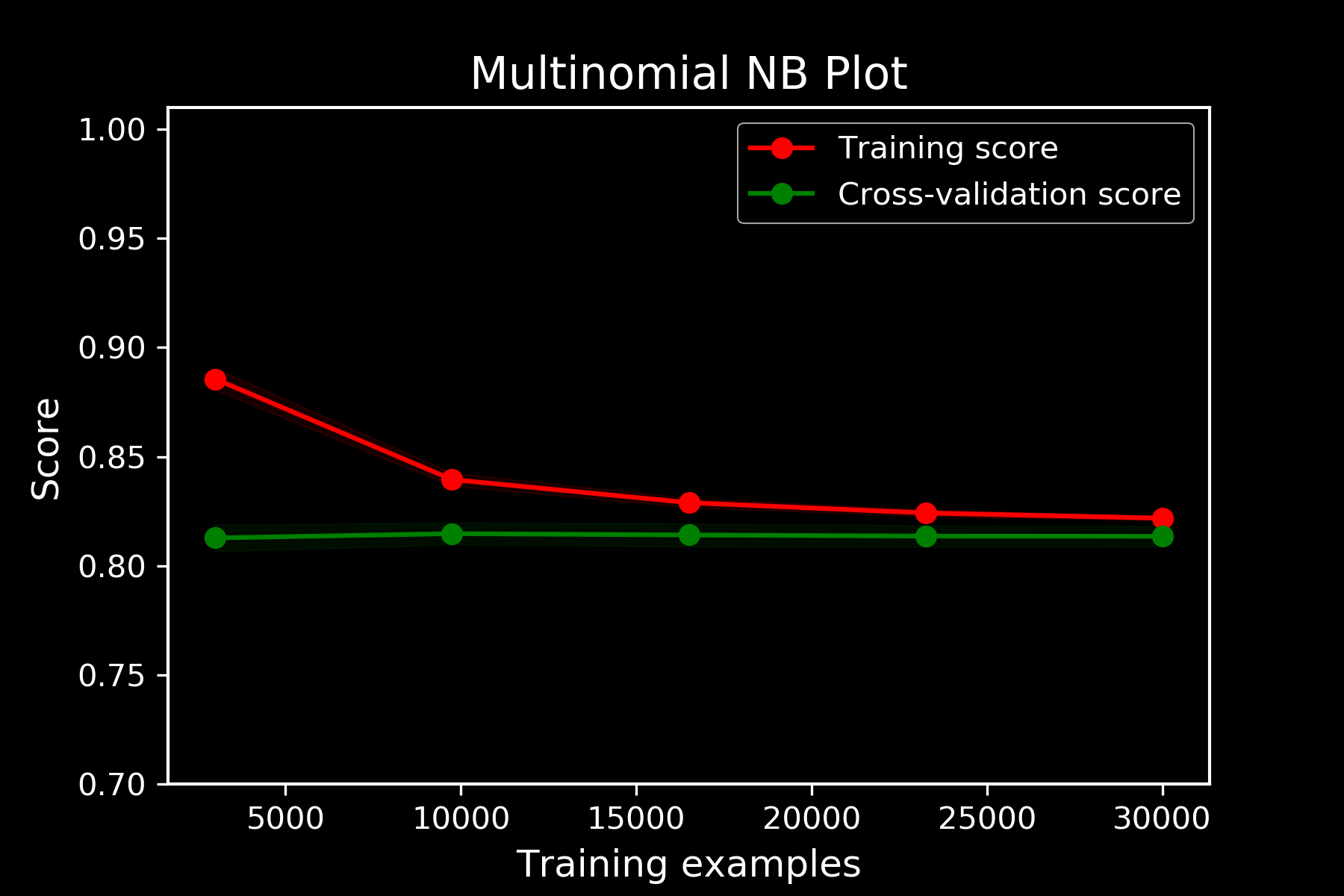
LEARNING CURVES OVER TRAIN
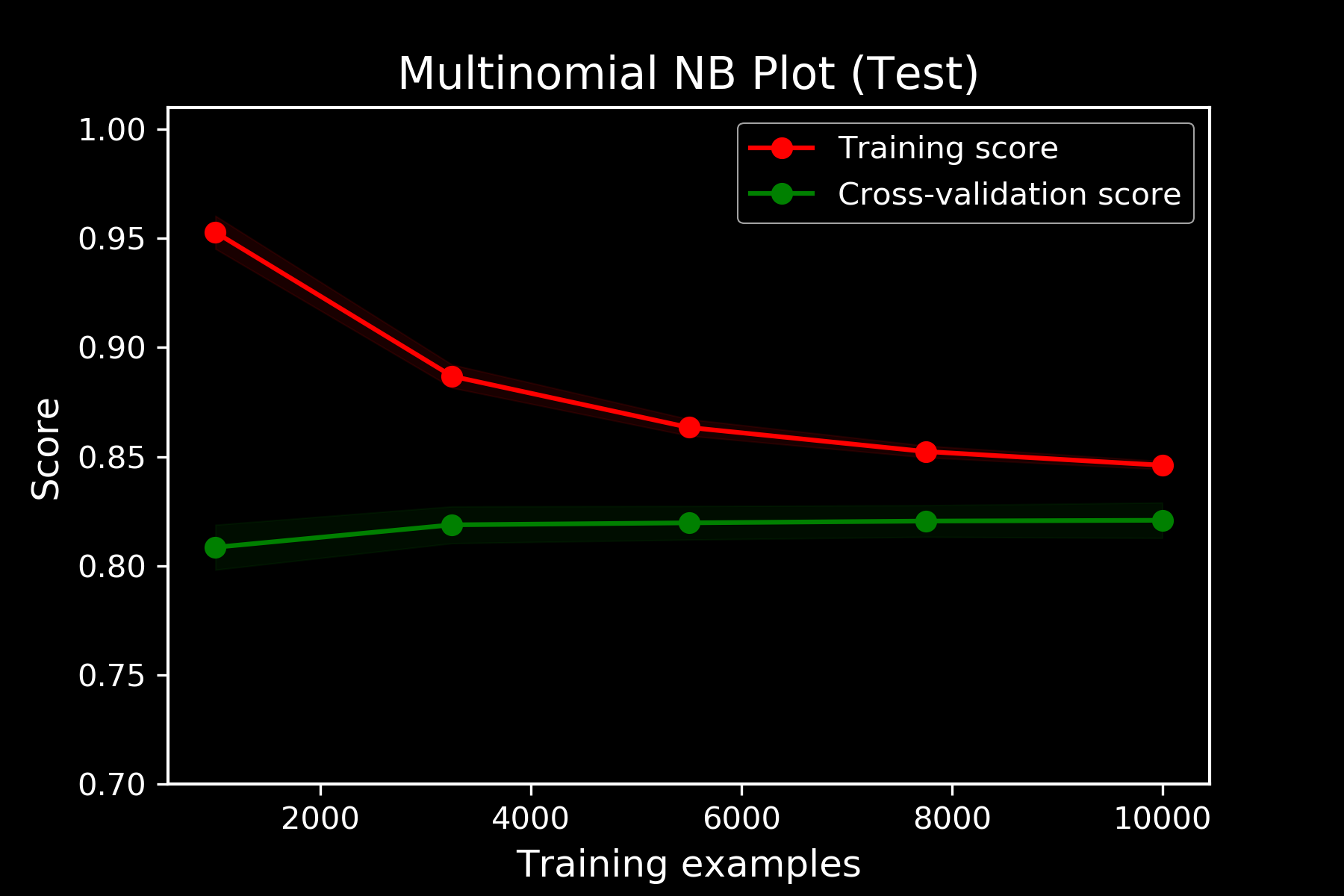
LEARNING CURVES OVER TEST
Accuracy
81.5%
SVM
Support Vector Machines
PROBLEM UNDER FOCUS
To analyse the reviews from the Yelp Dataset and classify them as being positive, negative or neutral reviews using the Support Vector Machine Model.
SENTIMENT
ANALYSIS
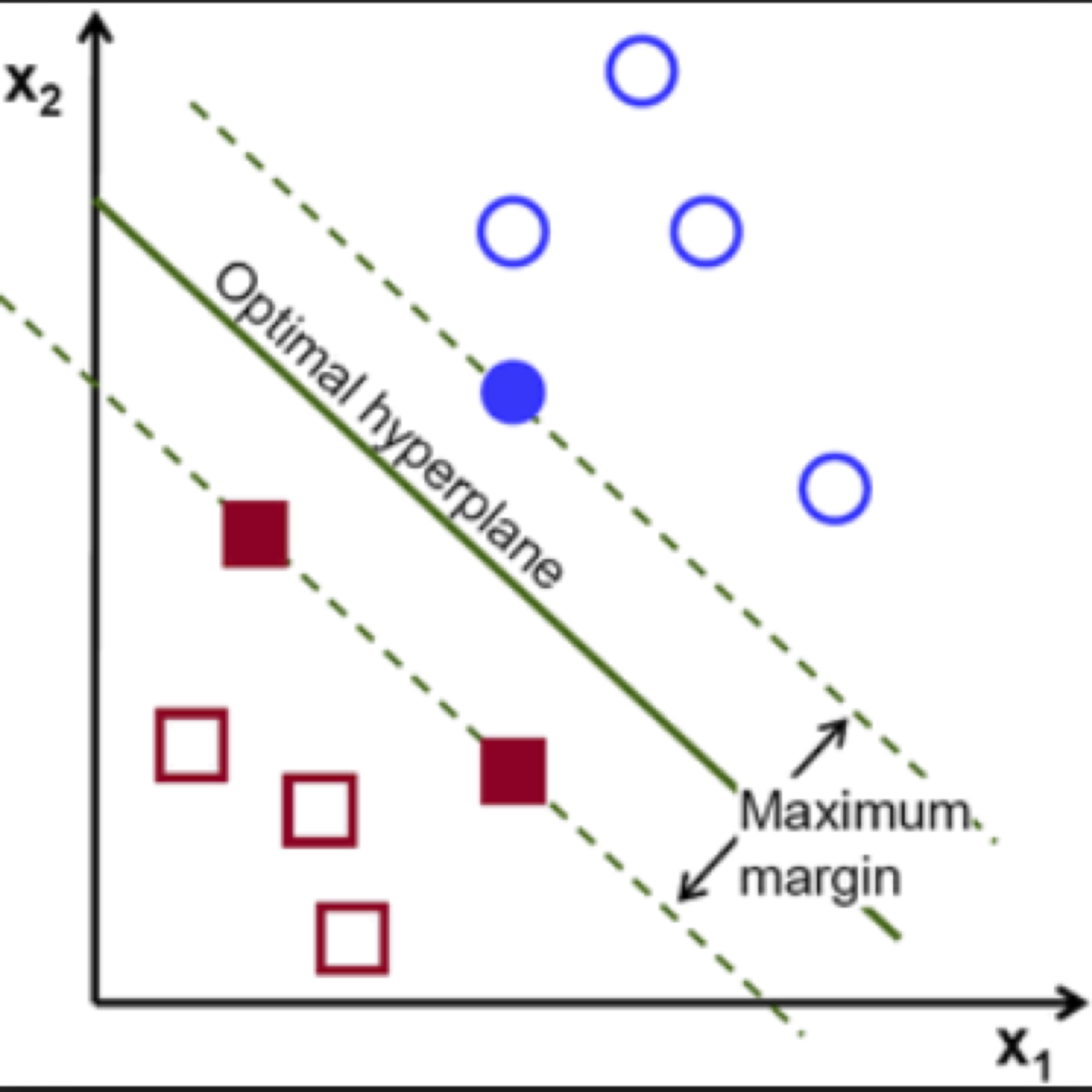
WHat is SVM?
- Supervised learning models with associated learning algorithms that analyze data used for classification and regression analysis.
- Given a set of training examples, each marked as belonging to one or the other of two categories, an SVM training algorithm builds a model that assigns new examples to one category or the other. However, they can be used for multiclass classification as well.
- An SVM model is a representation of the examples as points in space, mapped so that the examples of the separate categories are divided by a clear gap that is as wide as possible.
- New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall.
WORKING
- Support Vector Machine(SVM) has been chosen for the classification in the experiments. The support-vector machines is a learning machine for two-group/multiclass classification problems
- It is used to classify the texts as positives, neutral or negatives. SVM works well for text classification due to its advantages such as its potential to handle large features
- Another advantage is SVM is robust when there is a sparse set of examples and also because most of the problem are linearly separable. Support Vector Machine have shown promising results in previous research in sentiment analysis
PROS and CONS
- Works well with even unstructured and semi structured data like text, Images and trees
- The risk of overfitting is less in SVM
- It scales relatively well to high dimensional data
- Unlike in neural networks, SVM is not solved for local optima
- Major disadvantage is Large Training Time for Large Datasets
Accuracy
89.7%
LR
Logistic Regression
WHat is LOGISTIC REGRESSION?
Applied to binary dependent variable.
The binary logistic regression model can be generalized to more than two levels of the dependent variable: categorical outputs with more than two values are modelled by multinomial logistic regression
sentiment analysis
To verify that the model is accurately predicting the expected result for the test data set along with the validation accuracy that is obtained with the validation data set and the training dataset.
plotting
the model
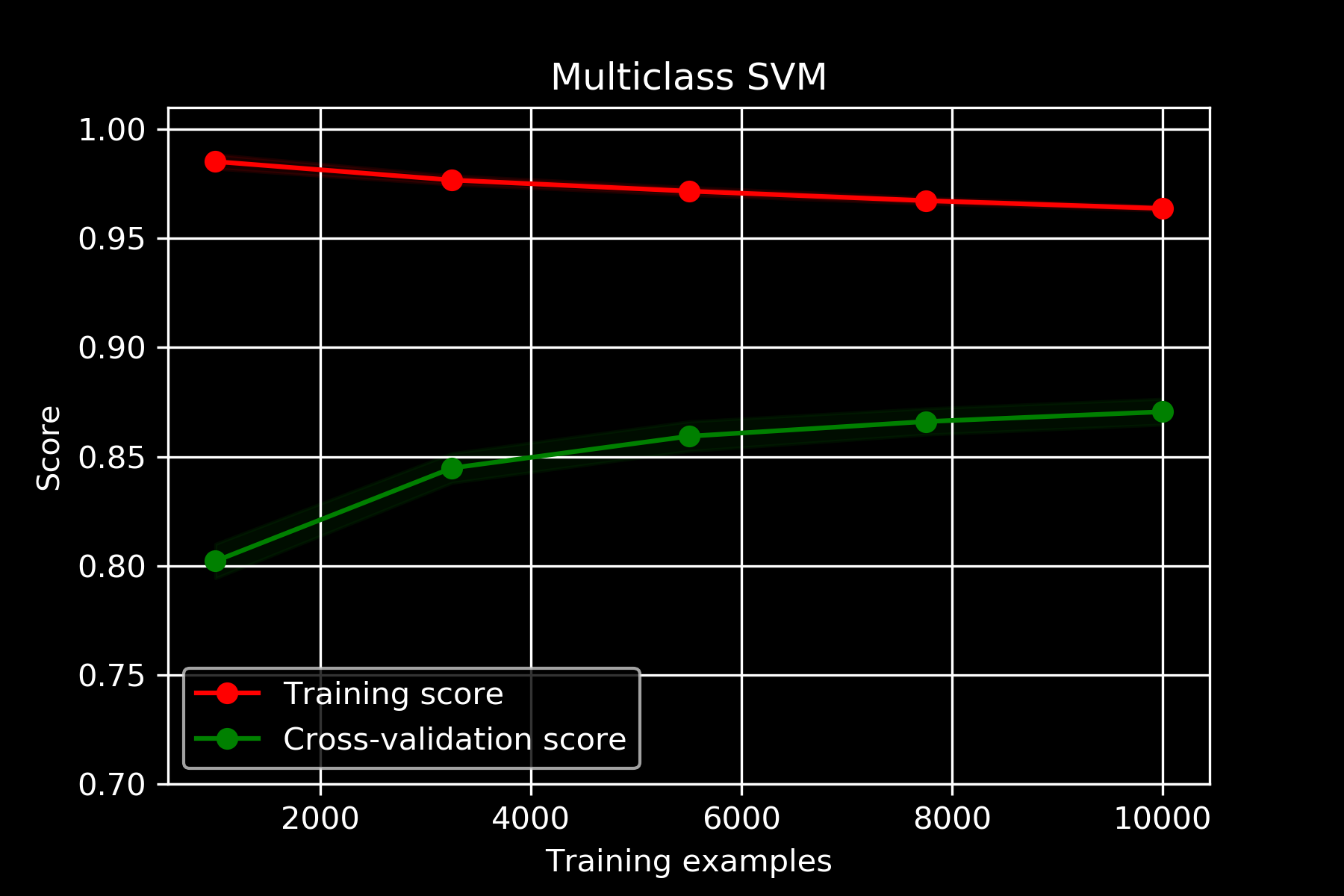
TRAINING TEST VALIDATION
Accuracy
90.7%
WHY LOGISTIC ?
- For classification tasks there are three widely used algorithms; the Naive Bayes, Logistic Regression / Maximum Entropy and Support Vector Machines.
- We have already seen how the Naive Bayes works in the context of Sentiment Analysis. Although it is more accurate than a bag-of-words model, it has the assumption of conditional independence of its features.
- This is a simplification which makes the NB classifier easy to implement, but it is also unrealistic in most cases and leads to a lower accuracy. A direct improvement on the N.B. classifier, is an algorithm which does not assume conditional independence but tries to estimate the weight vectors (feature values) directly.

Shefali Bansal
Tanya Sharma
Arvind Srinivasan
Aarushi Sharma
Arkav Banerjee
Simran Singh