傳說中的那個...
深度學習!
深度(Deep)學習(Learning) - DL
Arvin Liu
About me
- 台大資工大四老人- QAQ
- 機器學習及其深層結構化(深度學習)ㄉ助教
- 當過新竹&台北人工智慧學校ㄉ講師
- 專長於資訊安全跟機器學習!

這個slide沒講的深窩
詳情請見講義(?)
人工智慧
(Artificial Intelligence)
什麼是人工智慧(AI)呢?
AI =
讓機器展現人類的智慧(?)
wiki 的定義
怎麼樣才算的上是一個AI呢?
def add(a,b):
return a+b
這也可以?
def add(a,b):
return 0
蛤?這也可以?
Siri 怎麼做的?
Siri的小範例
Solution?

Large Database
Q: 你是誰? A:我是Siri。
Q: 你喜歡做什麼? A:我喜歡做我喜歡做的事情。
Q: 現在時間? A: [打開時鐘App]

Q: 你是誰?

A: 我是Siri
這樣真的行...?
不行。

具體上來說
- 他只會背東西,不會舉一反三。
- 東西太多了!
看起來連我阿嬤都會寫。
機器學習
(Machine Learning)
什麼是機器學習(ML)呢?
讓機器自己看著數據學習一個公式!
(or函式)
初階機器學習 -
迴歸直線!
什麼是迴歸直線?
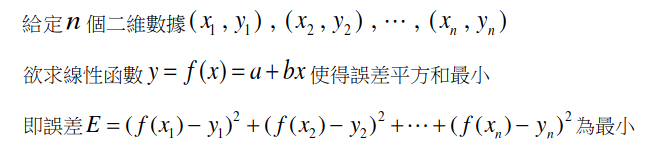
一個小小例子
假設:

IQ-髒話比例的資料點
| 髒話因子 | IQ |
|---|---|
| 15.35 | 80 |
| 14.35 | 81 |
| 13.9 | 85 |
| 10.7 | 90 |
| 18.4 | 91 |
| 12.20 | 95 |
| 15.606 | 101 |
| 17.70 | 102 |
| 20.33 | 110 |
解出迴歸直線
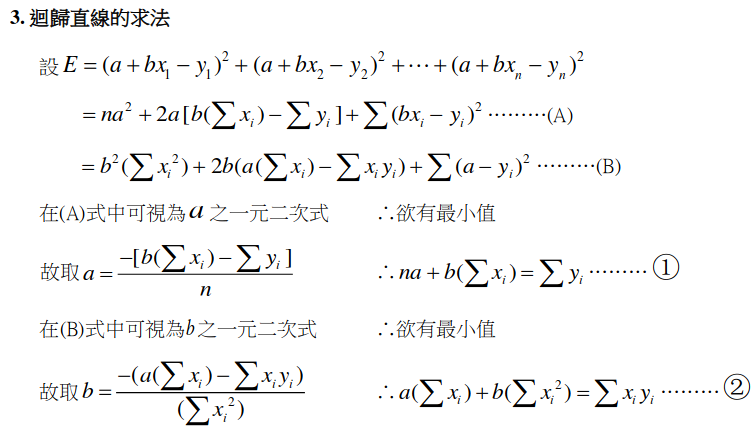
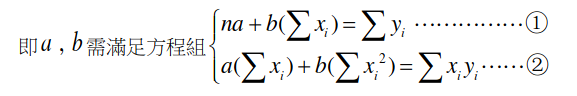
總之有辦法解就對了。
用迴歸直線來預測!
直線:IQ = 3.33x髒話因子+50
有人髒話因子是20,推出他的可能IQ:
IQ = 3.33(20)+50 = 116.6
可是資料只有一個x也?
x也可以把它當一個數組窩!
例如x = (a,b,c)
ㄨㄛˋ!
大家其實都會機器學習!
機器學習要什麼?
1. 資料
純粹數字
圖片
音訊


2. 模型假設
3. 目標
均方誤差(Mean Square Error)
(其實就只是最小平方法再除n而已)
平均絕對誤差(Mean Absoulte Error)
總之就是一個公式
4. 算出最合適的參數!
用魔法 - 靠數學直接解出來。
(迴歸直線的話就是算出那個a跟b)

真的就這樣?
真的。
萬一算不出來怎ㄇ辦QQ?
15 mins
Gradient Desent
(梯度下降法) - 可以用在幾乎所有平滑連續的模型上。
首先... 什麼是切線?

來玩個數學小遊戲吧!
遊戲規則
進入140.112.30.39:12721
輸入隊伍編號
每個關卡都會給密碼
Login! (會等個10s)
遊戲規則
座標圖
輸入一個x,伺服器會給你f(x)和他的切線。
(會大約等個10s)
以前猜的紀錄
遊戲規則
座標圖:
每次猜都會拿到一個座標根切線。
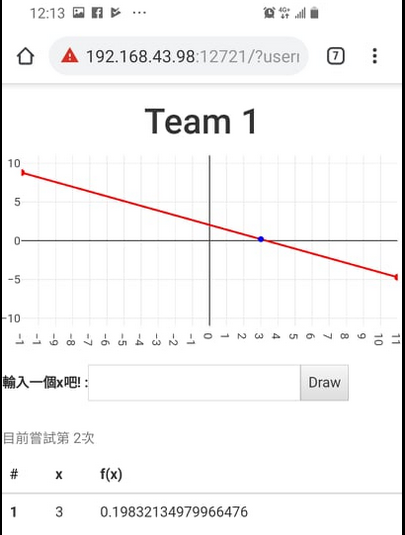
- 你們的目標是想辦法拿到最低的f(x),
- 結算後
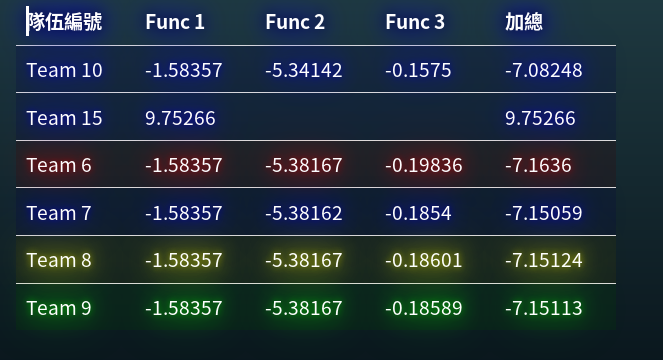
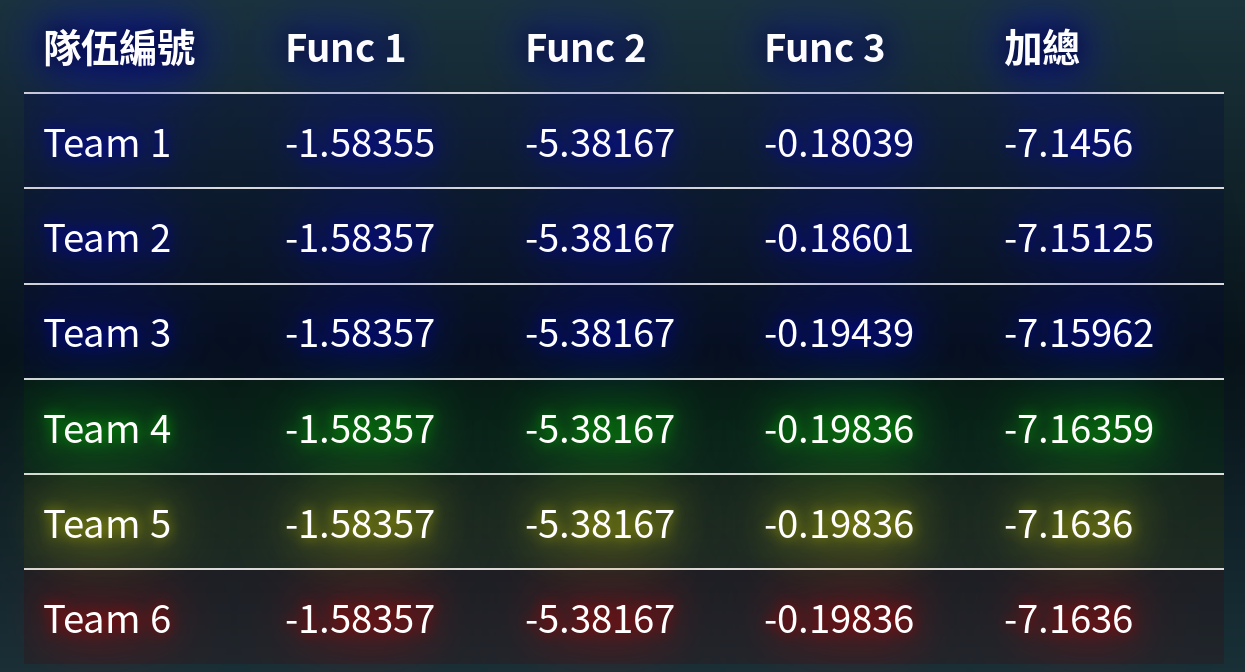
Function 1
Function 2
Function 3
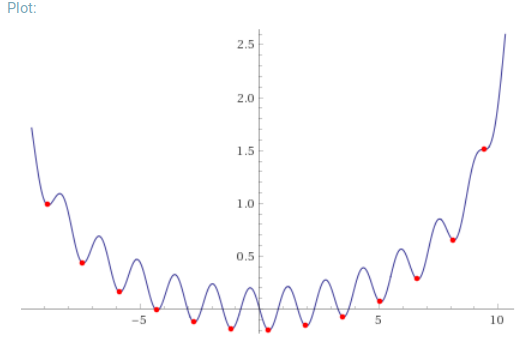
梯度下降法
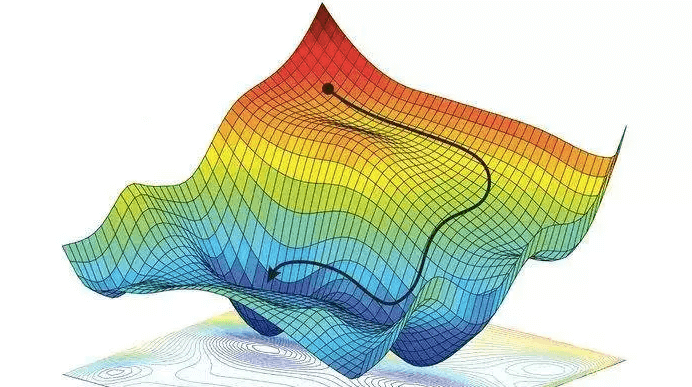
順著斜率往下找到最低點!
梯度下降法
GD裡面,x軸就是模型的參數,y軸就是目標損失
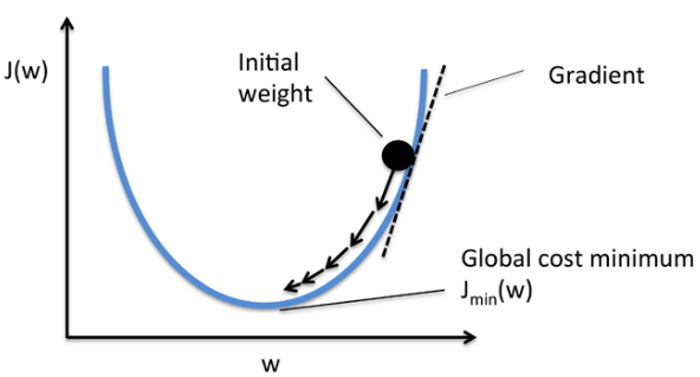
梯度下降法
有沒有感受到梯度的力量了呢?
- 在機器學習裡面
- 參數就是剛剛的x
- 剛剛的f(x)就是誤差
- 用迴歸直線來看:
- ax+b的a,b就是參數。
- 最小平方法得出的數字就是誤差。
慣性/動量 Momentum
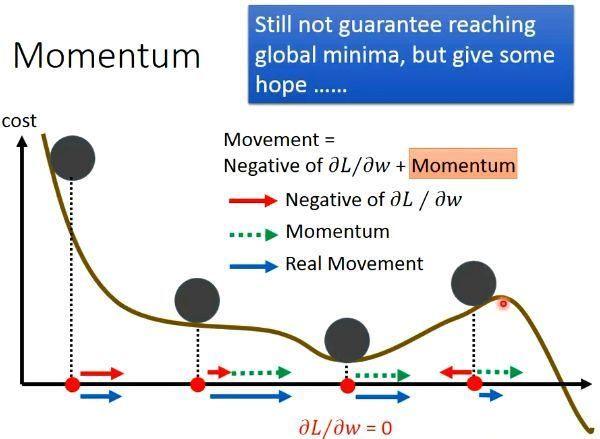
卡住靠慣性!
所以如何解出最適參數?
看起來好算的出來的:

看起來不好算的
(或是你懶的算的話):
就直接用數學解!
用梯度下降法!
現在一堆套件可以幫你做梯度下降法,
不用擔心(?)
Ex: Tensorflow / pyTorch / Keras
中場複習 - I
機器學習四個零件
資料
模型
目標
很多的(x,y)
f(x)=ax+b
最小平方法
用算的!
算出最適參數
來個不一樣的!
貓狗判斷器!

機器學習 - 判斷貓狗
資料
模型
目標
算出最適參數
圖片和它是貓?
神經網路
讓交叉熵最小
梯度下降法
總之就是一個公式
蛤?神經網路?
神經網路
(Neural Networks)
Neural Network
(傳說中的神經網路!)

心理學上有個神經擴散觸發 -> 你會有聯想/聯覺等等
聯覺?



心理學上有個神經擴散觸發 -> 你會有聯想/聯覺等等
如果用數學+生物看呢?
10
3.1
0.1
4.8
0.3x+0.1
-0.1x+1.1
0.5x-0.2
0.1x+0
0.4
5.5
0.1x+0.08
20x-0.5
x-0.8
...
受到刺激的神經
一般神經
還是一般神經
其他感官神經之類的
動器之類的
如果用數學+程式看呢?
10
3.1
0.1
4.8
0.3x+0.1
-0.1x+1.1
0.5x-0.2
0.1x+0
0.4
5.5
0.1x+0.08
20x-0.5
x-0.8
...
輸入的資訊:例如圖片
一般神經
還是一般神經
結果!
結果!
化簡一下神經網路!
10
3.1
ax+b
0.4
1. 輸入的資訊
一般神經
結果!
cx+d
0.5
真正的結果QQ
3. 目標差距
(loss)
4. 靠梯度下降法
更新參數
(這裡指a,b,c,d)
四個零件:
1. 資料
2. 模型
3. 目標
4. 算出最佳參數
2. 這就是整個模型
所以...
來設計神經網路模型吧!
設計你的神經網路!
疊積木!

真的就是疊積木
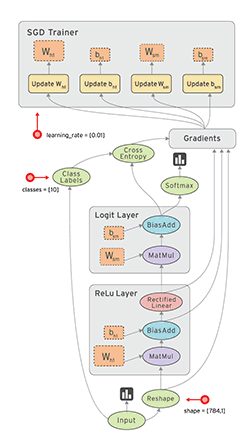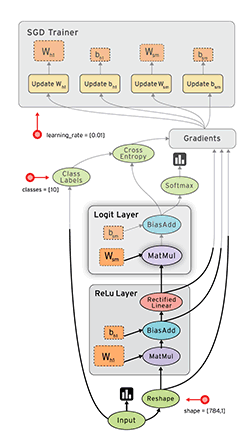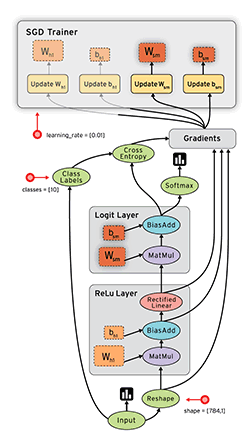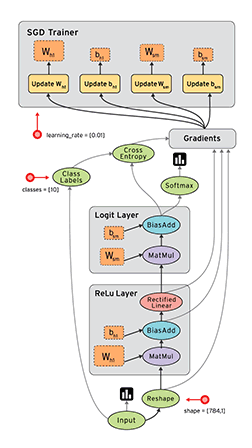
疊到Google也來疊積木
那有什麼積木零件呢?
常見積木/Layer
Input Layer
輸入層
Input Layer (輸入層)-
資料長怎樣?
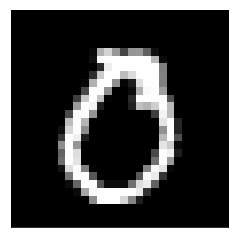
(28x28x1)
(256x256x3)

就是n
個數字
(n)
Output Layer
輸出層
Output Layer (輸出層) -
你想做到什麼樣的事情?
(1)
預測y
圖像生成
(256x256x3)
貓狗判斷
(1)或(2)
用神經網路看迴歸直線
輸入層
(1個)
輸出層
(1個)
ax+b
Dense Layer
夫哩卡內梯得(Fully-Connected / FC)層 / 全連(接)層
Dense Layer (全連層) -
就是n*m個ax+b箭頭!
ax+b
前一層
的神經
(2個)
Dense(1)
(下一層只有
一個神經)
ax+b
前一層
的神經
(1個)
Dense(3)
(下一層有
三個神經)
cx+d
cx+d
ex+f
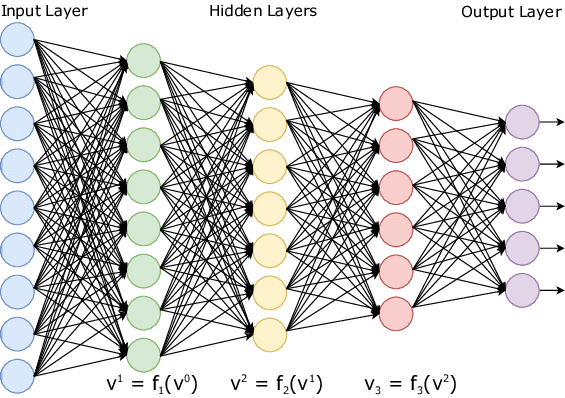
深度神經網路 -
Deep Neural Networks
輸入層
(2個)
全連層
Dense(2)
全連層Dense(3)
輸出層
(1個)
比較大一點的深度神經網路
Activation Layer
激活層 / 獎勵層
生物上的神經閾值
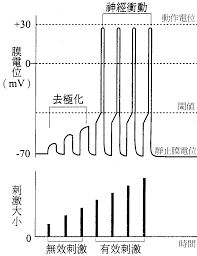
-
要有強烈的輸入
才會受到刺激
-
神經網路也可以模仿這個!
常見的激活層 - ReLU
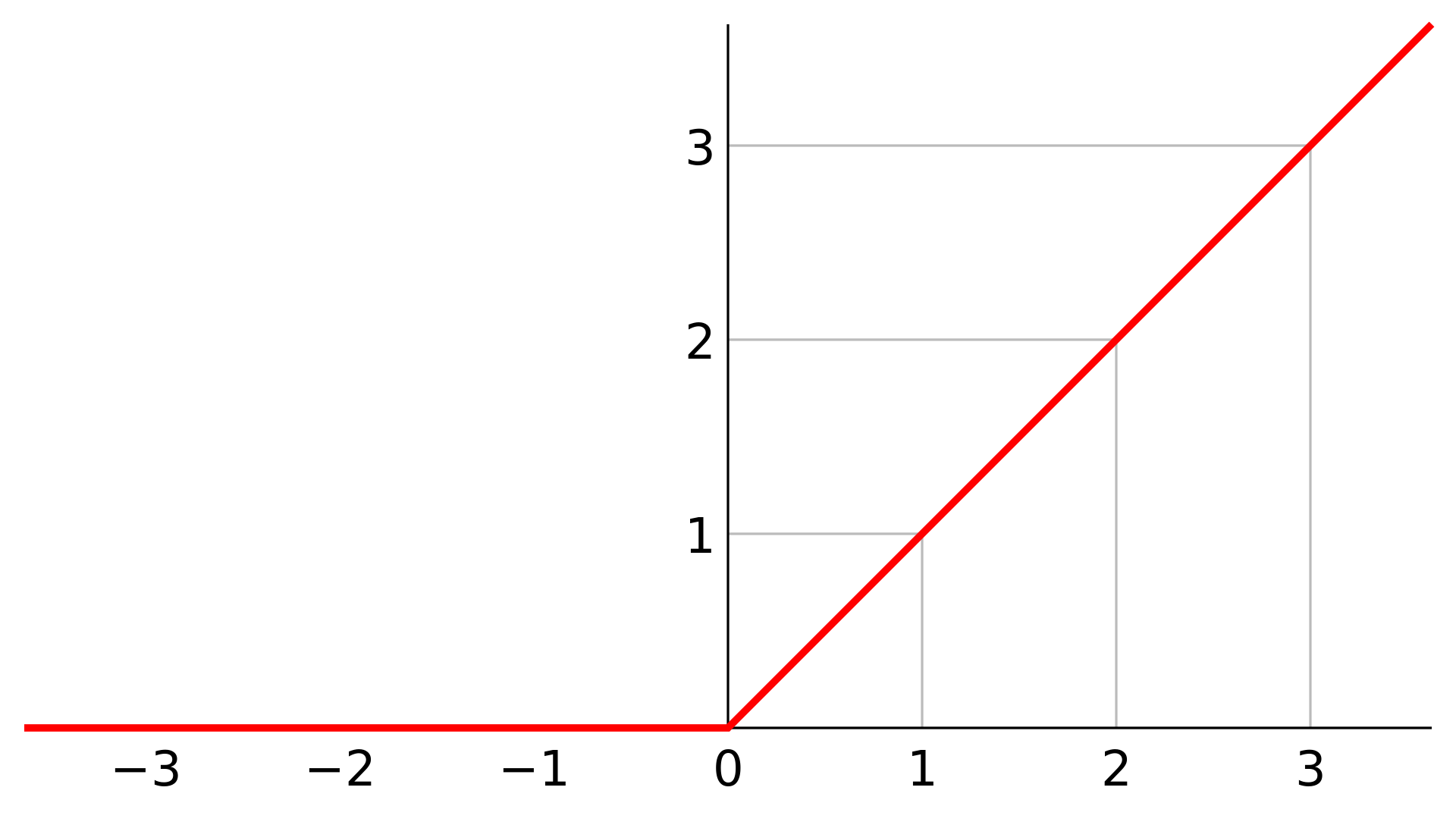
-
神經的數字要超過0才會繼續傳下去
線性整流函數(Rectified Linear Unit, ReLU)
小小ReLU例子
0.1x+1
前一層
的神經
(1個)
Dense(3)
0.2x
-1x+8
10
-2
2
2
2
2
ReLU
0
它死了
不會再往前傳了QQ
還在的繼續傳下去:D
*小提醒
Dense全連層其實箭頭只有ax而已,不會+b。
他們是最後加總後每個神經再+b。
ax
全連層Dense(1)
cx
+b
最後你的神經網路...
一個深度神經網路的py範例
輸入層(10)
model.add(Input((10,)))
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dense(32))
model.add(Dense(1))Dense(128)
ReLU
Dense(64)
ReLU
Dense(32)
輸出層
Dense(1)

圖像辨識
MNIST 手寫數字資料庫

*每張圖都是 28*28,總共764個px
資料其實就是這樣
(28x28x1)

用784維Dense下去!
療癒的fu~ (綠色表示非0)
Wasay!
這樣其實就可以了XD
深度學習
(Deep Learning)
Deep Learning
(很有深度的深度學習)
其實就只是比較深的
神經網路辣!
剛剛你看到的
神經網路模型
也算深度學習窩!
AI & ML & DL
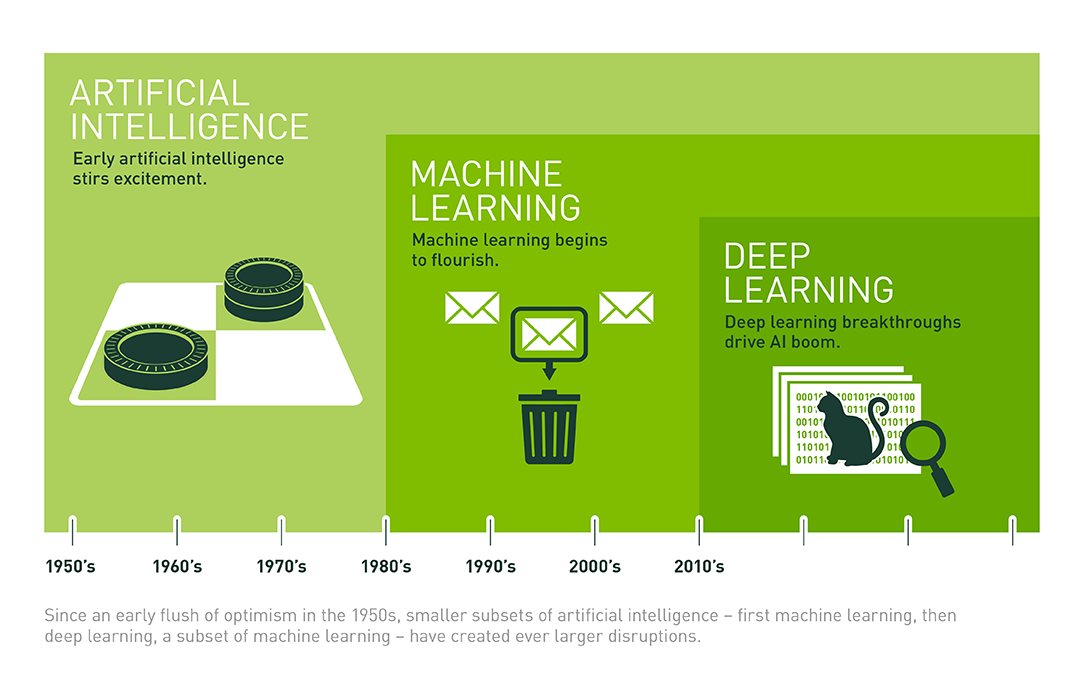
DL vs SN
Deep Learning vs Shallow Networks
深層網路
(深度學習)
淺層網路
各種推論
世界上有很多要推論很多次才可以理解的事情。
層層推論 -> 層層積木
事實
推論
結果
推論2
多層 = 可以透過層層推論得出節論
單層 = 一次把事實和結果連起來 (不聰明QQ)
所以...
淺的網路也可以,只是他不聰明
濾鏡/Filter
B612 - 濾鏡功能


原本的圖片 * Kernel(卷積核):
把Kernel疊上去,每個獨自相乘後加總。

Convolution (卷積) 運算
用卷積當濾鏡

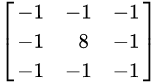

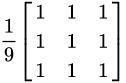


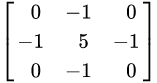
卷積
卷積
卷積
邊邊探測
模糊化
銳利化
因為如果
顏色都一樣,
卷積會變0。
因為結果的圖是上一張圖的周圍混在一起。
把中間的特色跟周圍突顯出來!
(因為它加強自己扣掉周圍)
Convolution (卷積) 運算
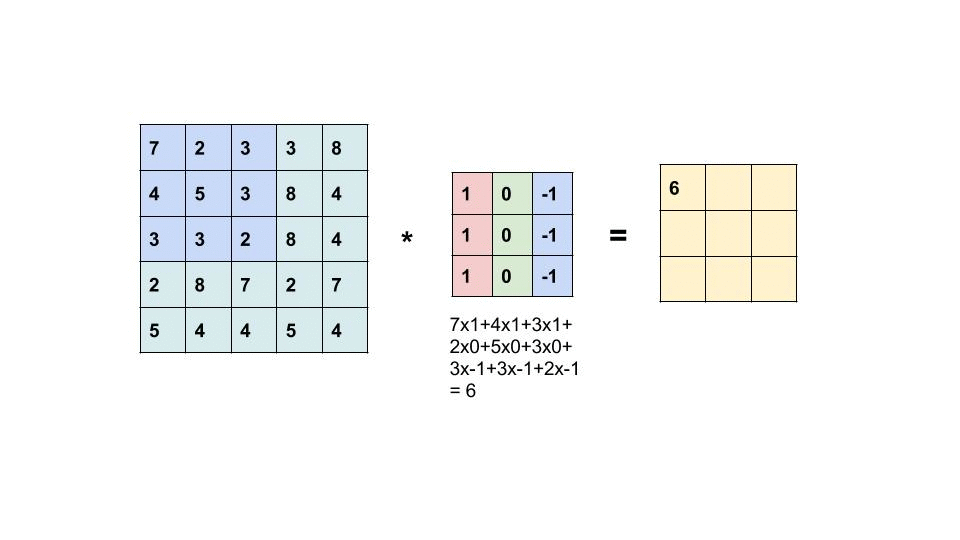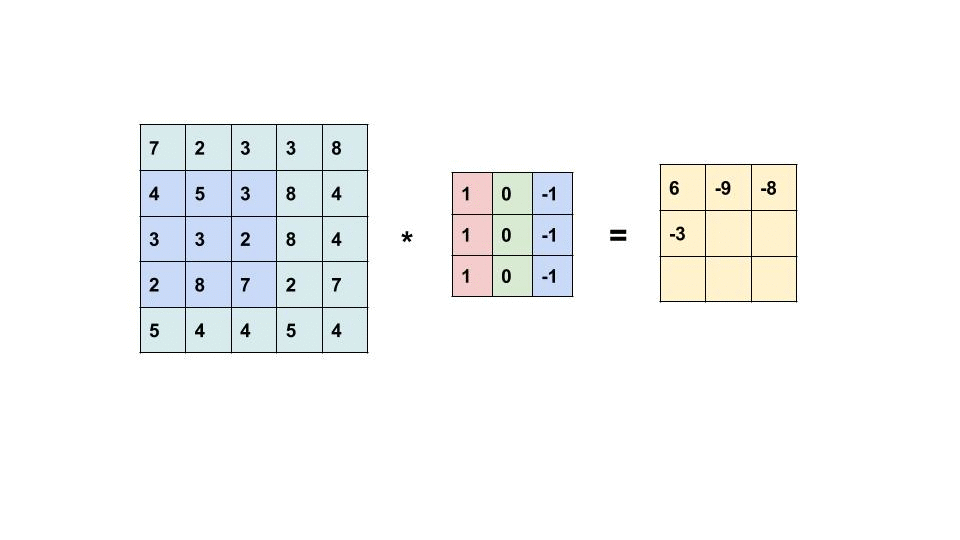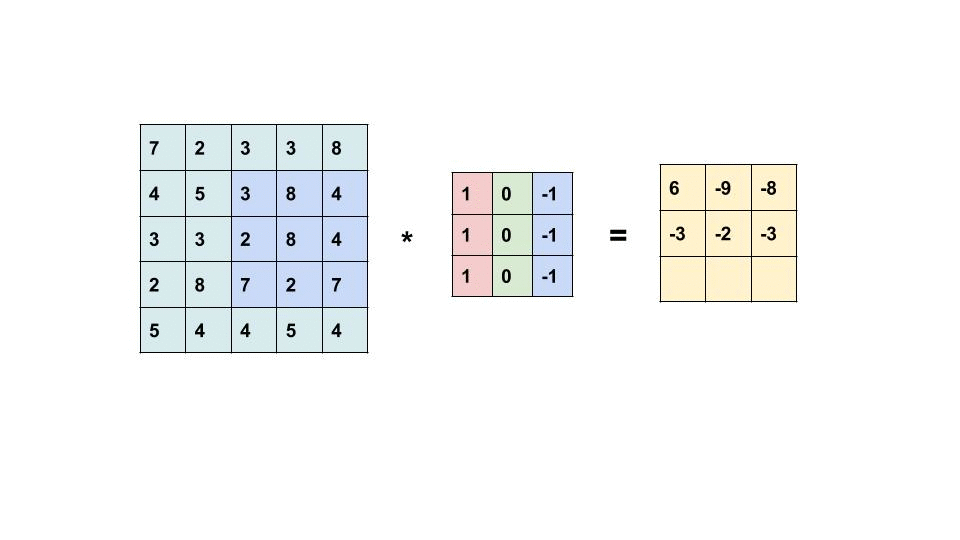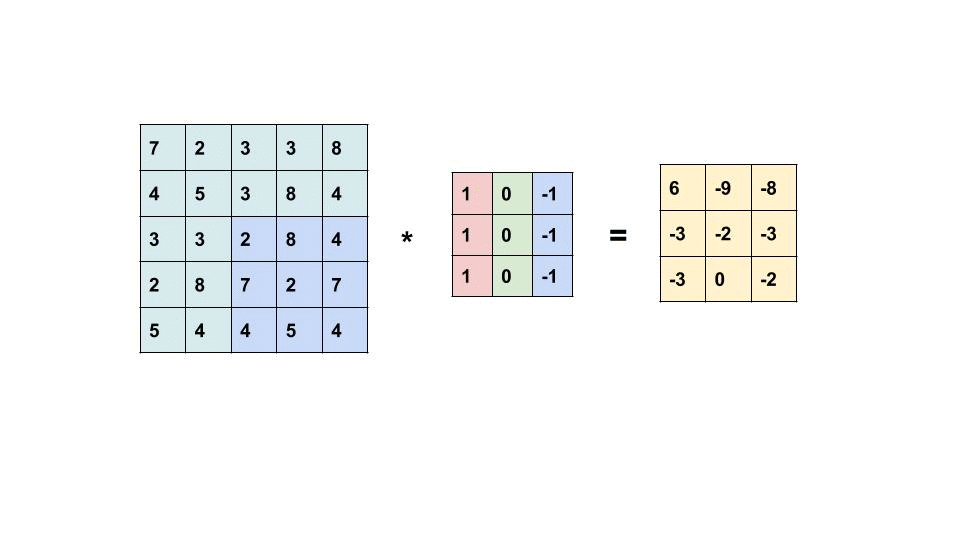
再看一次: 每次運算都是把捲積核疊起來,每一格數字各自相乘後的加總丟給第二張圖。
講這個幹麻?
讓老人來跟你講個故事...
有個古老的圖像特徵抽取方法
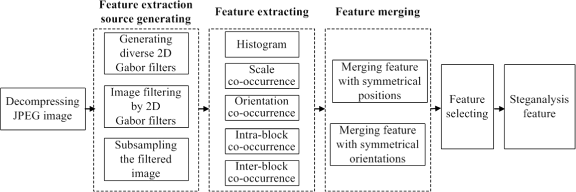
幾乎都是先人自己定好的kernel後
跟圖片卷積來抽取特徵的
都這個年代了
讓NN自己學kernel啊!
Convolution Layer
卷積層
Convolution Layer (卷積層)
看不懂可以看久一點,真的看不懂也沒關係XD
Conv(2,(3,3)) => 2個3x3的卷積核
| a1 | b1 | c1 |
|---|---|---|
| d1 | e1 | f1 |
| g1 | h1 | i1 |
| a2 | b2 | c2 |
|---|---|---|
| d2 | e2 | f2 |
| g2 | h2 | i2 |
R
G
B
卷積後加起來+b1
?
卷積後加起來+b2
?
Maxpool Layer
最大池化層
Maxpool (最大池化層) -
把地區老大抓出來
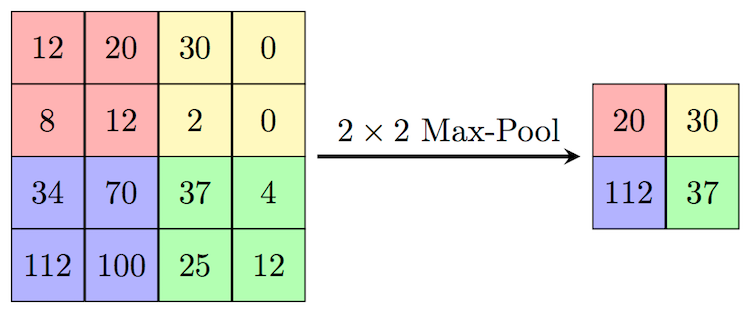
就這樣XD
所以新的圖片會變小窩!
Convolutional Neural Networks (CNN)
卷積神經網路
其實就是...
有用到卷積層的都算(?)
所以大家都會
DNN和CNN了!

卷積神經網路
深度神經網路
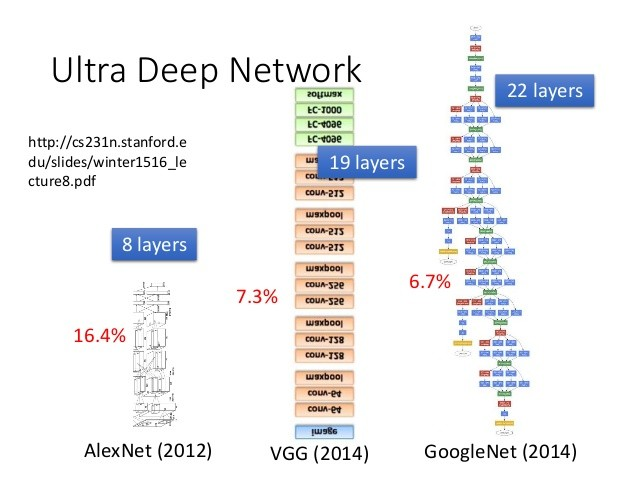
你看得懂大部分的GoogLeNet了!
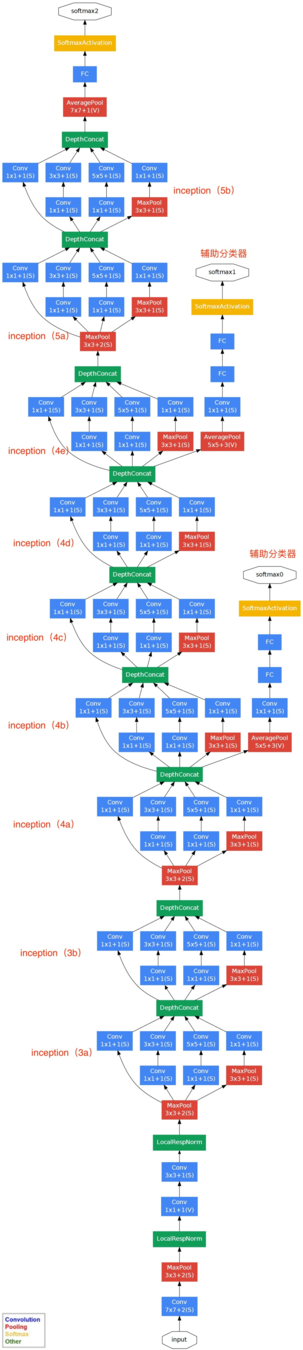
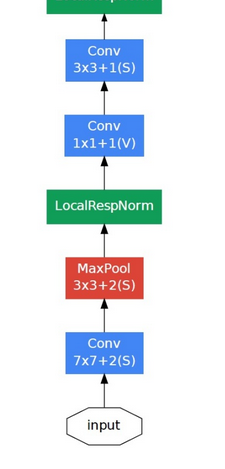
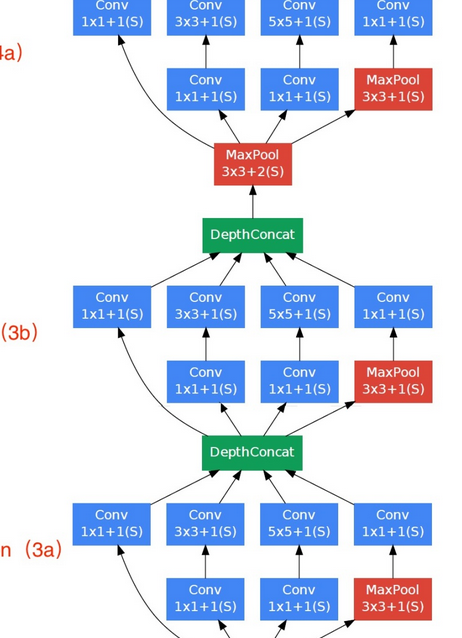
中場複習 - II
NN的精髓
疊模型
還是疊模型
依舊還是疊模型
資料乾淨 & Loss設計
NN的各種積木
輸入層
輸出層
激活/獎勵層 - 例如ReLU
密密麻麻全連接 - Dense
卷積 Conv / 最大池化 Maxpool
模型和資料是不是沒有關係ㄚ?
簡單的任務還真的沒什麼關係,
一個model拿來萬用
學了這麼多積木
然後怎麼疊比較好啊?
隨便疊!
基本上就是靠經驗去疊。
有沒有奇怪的準則呢? 有。
- 全連層後都會接 激活 / 獎勵層。
- 輸入後不要 激活 / 獎勵層。
- 參數不要太爆炸(例如對於簡單的任務要1e個)
- 等等等等等....
例如祕密配方:
Conv + Maxpool + Activation

卷積層
最大池化層
獎勵/激活, 通常ReLU系列
深度學習各種應用
某個古老的AlphaGo

某個古老的AlphaGo
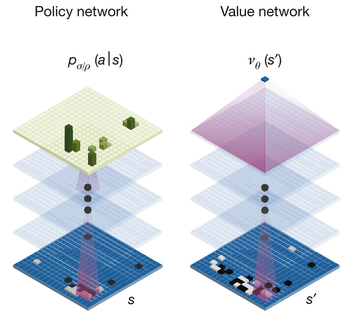
AlphaGo的算法中,
有決策網路估價網路
(看現在棋盤怎麼樣)
其中決策網路
就是個有12個卷積層的CNN!
天眼系統 - 人臉辨識

各種純粹的數據 - CIFAR 10

1.資料
2. CNN為主 3. 交叉熵 4. 很像GD的東西
各種語音辨識 - Speech Recog
1.資料
2. RNN為主 3. CTC Loss 4. 很像GD的東西
或是將音訊轉成類似圖片的東西,就可以用CNN惹!
RNN: 遞歸神經網路,總之就是一種神經網路
CTC Loss: 總之就是一個公式。
深度學習要會什麼?
創造力 - 想出一個神奇Model



數學 - 目標設計等等

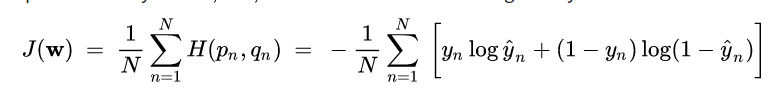
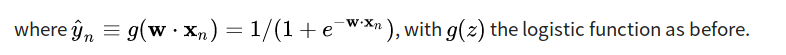
$$ - 訓練模型的GPU
