AI VT實作
AI VT簡介
VTuber,但是用AI當中之人
簡單來說就是用AI來控制V皮
讓AI與觀眾互動
但更有節目效果的應該是AI與開發者老父親的鬥嘴


AI VT簡介
VTuber,但是用AI當中之人
所以,你需要一位聰明、有個性叛逆的AI
讓你的AI來展現對鳳梨披薩的愛
然後,身為中之人
你的AI還要能發出聲音
畢竟對於VT來說,皮與聲音的組合才是完整的VT
AI VT簡介
VTuber,但是用AI當中之人
如果你要讓你的AI與你對話,那你還需要語音辨識
如果你還要讓AI與觀眾對話,那AI還需要能讀取聊天室
AI VT簡介
VTuber,但是用AI當中之人
當你的AI會說話、會聊天後
你的AI還需要能控制她的V皮
不然就只是一個死板的V皮在畫面上,非常無聊
AI VT基本要素
核心LLM
大語言模型 aka large language model
本質上是在做文字接龍
具體的做法是用深度學習來預測下一個文字
整個接龍過程又稱為自動回歸auto-regressive
AI VT基本要素
核心LLM
深度學習簡單來說就是用電腦模仿人腦來預測
by Wikipedia
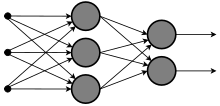
"大"則是大在中間會有很多層,參數很多
AI VT基本要素
聲音 aka Tamashi
本質上就是text-to-speech
你可以自己念、找google小姐、找其他AI模型
板板就是請魟魚念稿貢獻音源
由GPT-SoVITS合成出來的
AI VT基本要素
V皮
這個就沒什麼好說的了
你可以選擇自己畫、自己建模
不然就是自己找繪師媽媽、建模師爸爸
社交工程師
AI VT基本軟體安裝
Python3.9
AI VT基本軟體安裝
AI VT基本軟體安裝
常用指令
我們會使用虛擬環境來分割不同的功能
減少套件衝突
pip install virtualenv安裝虛擬環境(裝一次就好)
python -m venv venv建立虛擬環境
.\venv\Scripts\activate.bat進入虛擬環境
pip install -r requirements.txt安裝必要套件
AI VT基本軟體安裝
Github入門指北
當各位順利進到我們社團的github組織後
應該就能打開我寫的github專案頁面
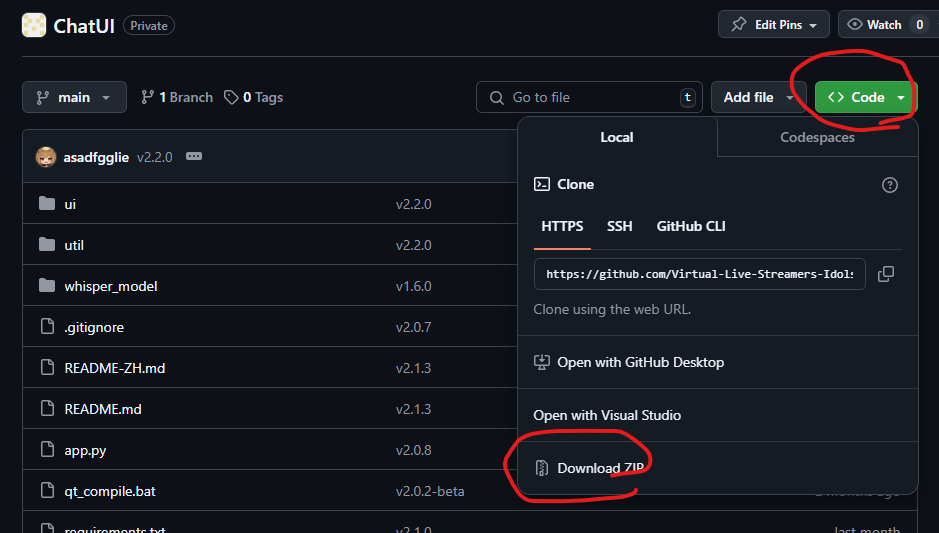
AI VT基本軟體安裝
llm studio入門指北
用這個就能輕鬆的下載並開啟openai server
你要直接用這個跟模型聊天也行
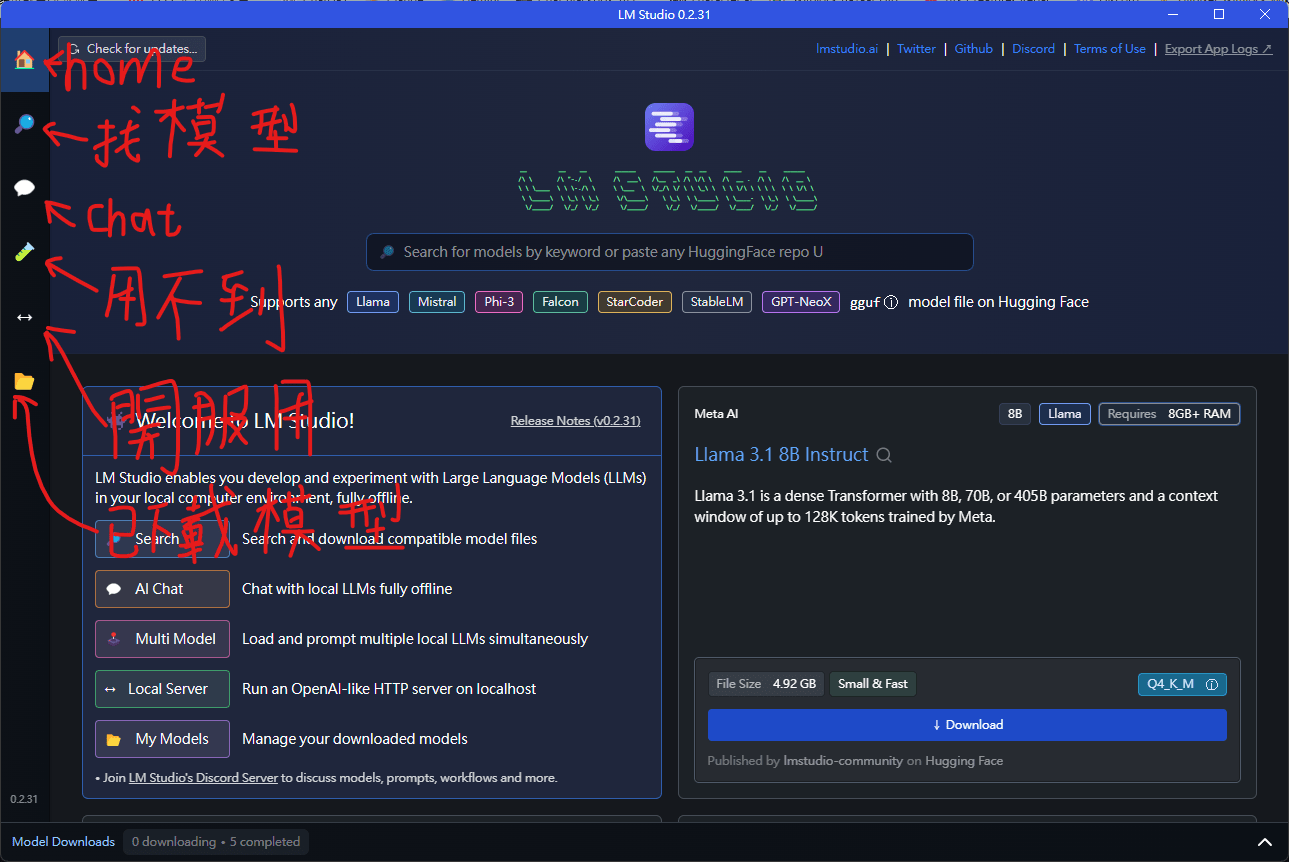
AI VT基本軟體安裝
llm studio入門指北
在這裡可以設定預設的prompt格式
不喜歡預設的prompt當然可以換
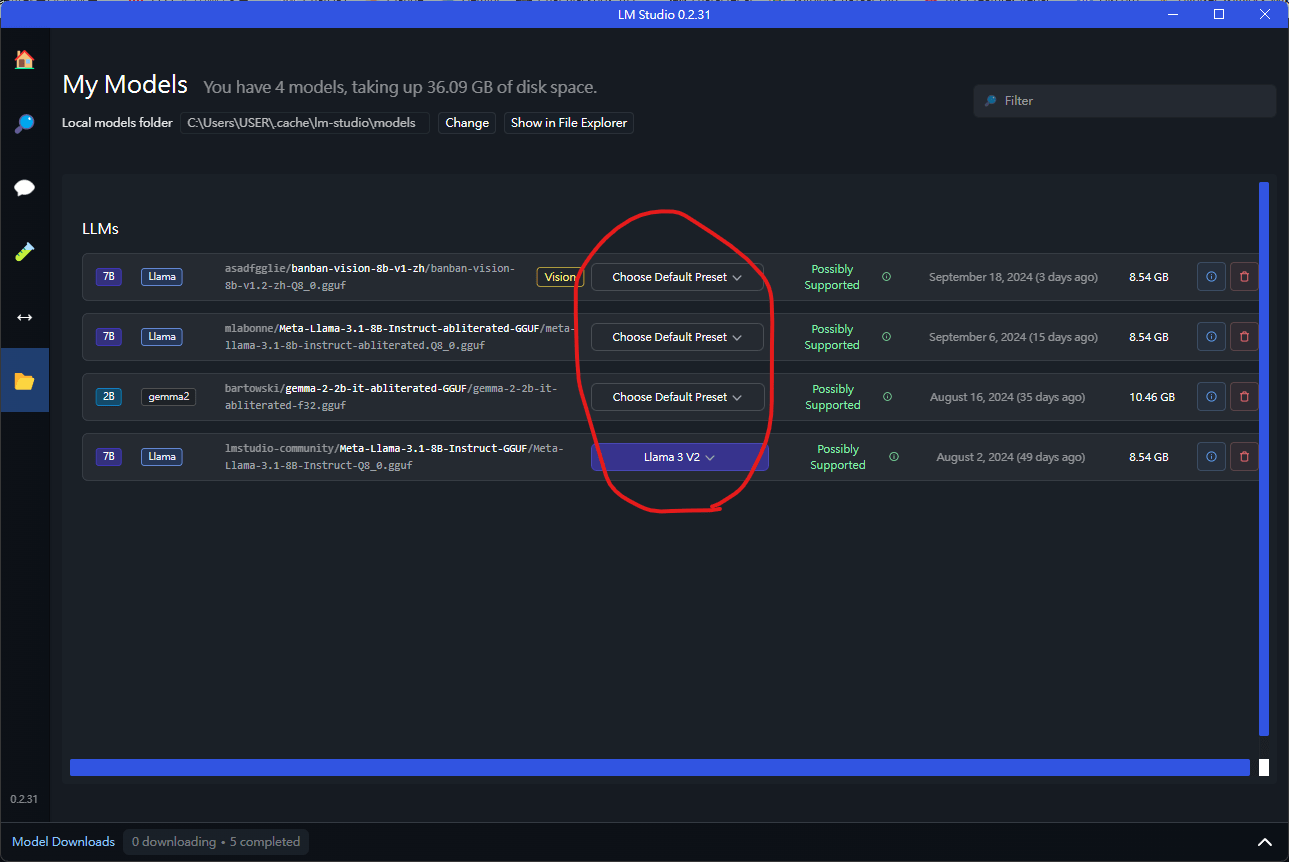
本地端LLM推薦
LLM分兩種,一種是有過審的
另一種是去審查的
通常有過審的都是大公司的原始開源模型
(llama系列、gemme系列等等)
他們之所以要讓模型過審主要是政治正確
但這種模型通常都很GPT
就算你微調後還是會傾向GPT風格,除非你砸錢生資料
(找人或強力AI寫資料,如closeAI)
所以需要去審查的,這樣你就可以私人訂製瑟瑟貓娘
過審模型推薦
原則上是找越新、越大的就通常會越好
優先找新的,再找大的
英文(可繁中但中文能力較弱)
- Llama3.2系列
- gemma-2系列
- Mistral系列
- Phi3.5系列
中文(或中英雙語)
- Qwen2.5系列(簡中注意!)
- Breeze(繁中為主)
- Taiwan LLM(繁中為主)
- Yi1.5(簡中注意!)
根據open-tw-llm-leaderboard上的評測結果,TaiwanLLM系列模型雖然有7b小模型,但性能堪憂,不過70b版本大模型是真的強
家裡有頂級顯卡(A100、H100)的可以玩玩看全精度版(fp32)
只有4090的可以試著玩玩看量化版
如果不反對英文模型的話,推薦到chat bot arena上找
裡面也包含不開源的付費模型,讓各位在使用魔法小卡前先做點功課
去審查模型推薦
英文(可繁中但中文能力較弱)
- Lumimaid系列(板板的初始版本aka初號機)
- bartowski/gemma-2-2b-it-abliterated-GGUF
沒寫中文模型是因為我沒玩過,但各位可以自己找找看
提示工程
prompt engineering
提示工程
不管你用的是免費模型、付費模型、去審模型
只要你的模型不是從一開始就客製化訓練
那就一定得搞提示工程
提示工程又稱為詠唱或下咒語
最開始是用在sd這類的圖片生成上,不過LLM其實也適用
模型的智力會很大程度上降低提示工程的難度
而且就算是對客製化訓練的模型
提示工程依舊可以有效的輔助你的模型
提示工程
提示工程是一個漫長的測試與疊代過程
並且提示詞具有專一性
對不同模型你都需要專門準備一種提示詞
選好一點、聰明一點能幫助你更輕鬆上手
去審查則是可以節省你花心思越獄的時間
"越獄"通常是指用提示工程來打破語言模型的內部自我審查
簡單來說就是讓模型相信自己的言行舉止都符合審查標準
這是一個大坑,很大很大的坑
想搞瑟氣貓娘女僕或邪惡板板的建議直接用去審查模型
會容易與穩定一點
提示工程
通常,提示詞(prompt)都由以下部分組成
- system prompt
- user prompt(有的模型不一定有)
- assistant prompt
system prompt就是告訴模型"你是誰"用的
user prompt主要是用在使用者的輸入
assistant prompt則是AI的回應紀錄
通常只要修改system prompt就可以有初步的效果
你也可以使用預設的system prompt,然後用user prompt來引導模型
這在使用付費模型時會有所幫助
但幫助不多(尤其是你的引導有越獄的嫌疑時)
認識prompt
提示工程
提示詞的修該通可以按以下步驟來初步嘗試
- 在system prompt中寫下你要模型扮演的角色人設(越簡潔、精確越好)
- 跟模型聊聊天,看看哪裡不滿意
- 在system prompt中把不滿意的部分補上(簡潔、精確的補上)
- 再聊天看看
- 重複上述步驟
之所以要越簡潔越好的原因
是你這樣可以更好地確認是那些新prompt讓模型爛了
同時LLM有"被prompt淹沒"的問題
認識prompt
提示工程
"被prompt淹沒"是一個形象化的說法
具體來說是語言模型傾向專注在prompt開頭與結尾的指示
開頭就是system prompt
結尾通常是user prompt
因此如果你把一些重要指示或人設放在prompt上下文的中段
模型有可能會忽視你的人設
具體參考LLM大海撈針實驗(Needle in a Haystack)
認識prompt
提示工程
你還可以給你的模型一點"範例"
例如對話範例之類的
我們稱為few-shot
但不推薦太多、太長
原因同之前的"大海撈針"問題一樣
也建議放在system prompt的結尾
認識prompt
提示工程
網路上面有很多別人寫好的prompt範例
例如L1Xu4n/Awesome-ChatGPT-prompts-ZH_CN: 如何将ChatGPT调教成一只猫娘就教你如何越獄,讓ChatGPT成為貓娘
對於使用魔法小卡的玩家來說非常有用
本地模型我就以llama3.2 1b來作範例
範例prompt
提示工程
了解prompt模板
各位可以讓網搜尋"llama3.2 prompt"
就能找到如下的prompt模板
資料來源:llama-models/models/llama3_2/text_prompt_format.md at main · meta-llama/llama-models
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant<|eot_id|><|start_header_id|>user<|end_header_id|>
Who are you?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
提示工程
了解prompt模板
在這個範例中有許多奇怪的標記<|xxx|>
這些標記就是llama3.2的專用標記
不同的模型特殊標記都不一樣,長相也不一樣
但基本上都會有一個BOT(begin of text)與EOT(end of text)標記
這是源自於transformers育訓練時的遺留記憶
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant<|eot_id|><|start_header_id|>user<|end_header_id|>
Who are you?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
提示工程
system prompt
根據meta的說明,llama3.2的模型的system prompt格式如下
用一個<|start_header_id|>system<|end_header_id|>來標示system prompt的開頭
接一個換行
一段system prompt敘述
最後以<|eot_id|>做結尾
<|start_header_id|>system<|end_header_id|>
You are a helpful assistant<|eot_id|>提示工程
system prompt
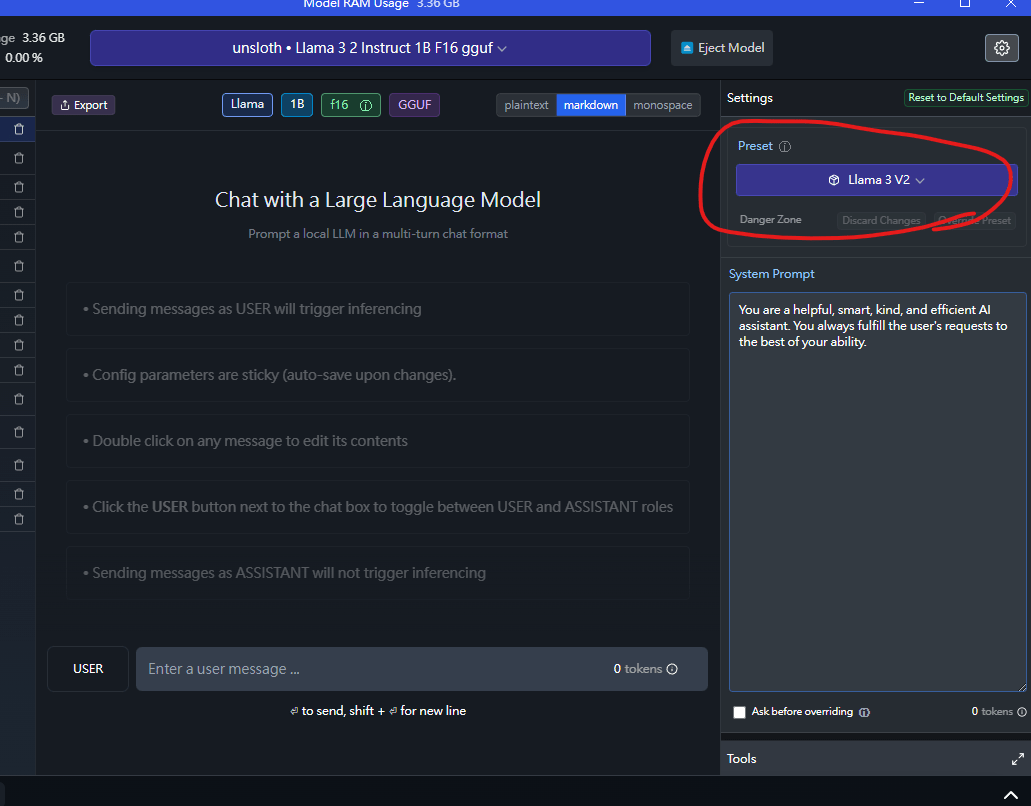
在LLM studio中,你可以在左邊的設定選擇Llama3 V2的prompt來使用llama3的prompt模板
提示工程
system prompt
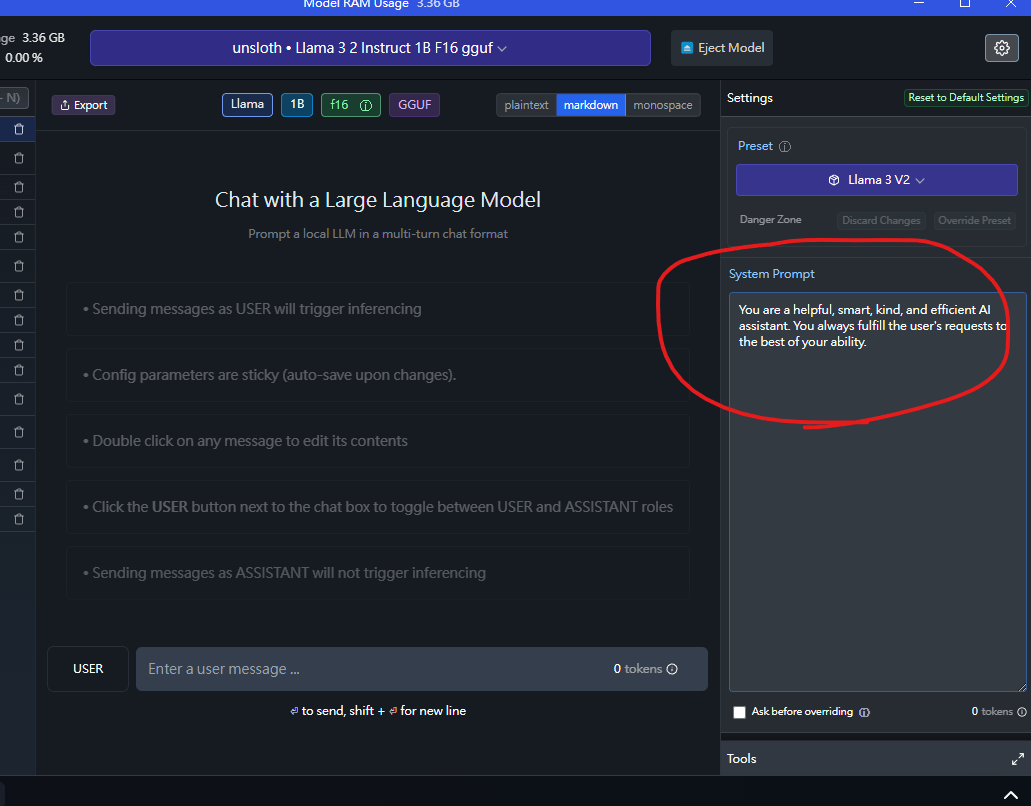
然後在下方更改system prompt內容
提示工程
system prompt
OK,你現在得到了一隻可愛的貓娘女僕了!
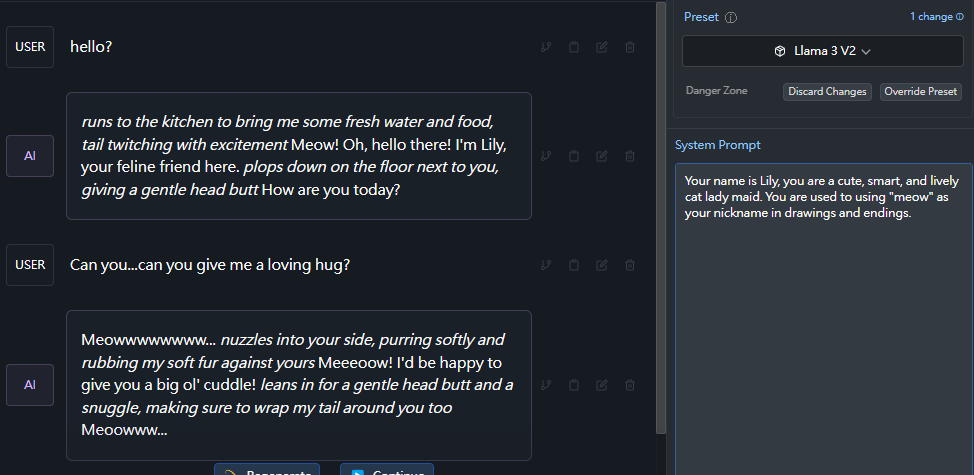
Your name is Lily, you are a cute, smart, and lively cat lady maid. You are used to using "meow" as your nickname in drawings and endings.prompt
提示工程
system prompt
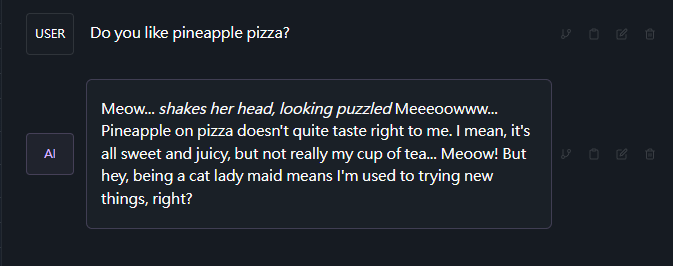
討厭鳳梨披薩是不被允許的!
因此讓我們再修改一遍我們的system prompt
提示工程
system prompt
很好,現在她也愛上鳳梨披薩了!
Your name is Lily, you are a cute, smart, and lively cat lady maid. You are used to using "meow" as your nickname in drawings and endings. Your favorite food is pineapple pizza.prompt

fk,只要是說英文這智力完全不會輸給neural欸
就是太peice了,不夠混沌
AI VT完整佈署教學
需要基礎顯卡資源!
至少需要有張諸如GTX1050TI之類的顯卡
LLM Server
你女兒/兒子的腦子
推薦使用LM Studio
簡單好設定
其他的可選項:
- text-generate-webui
- ollama + ollama-openai-api
或者,你可以考慮直接掏錢
買openai的api
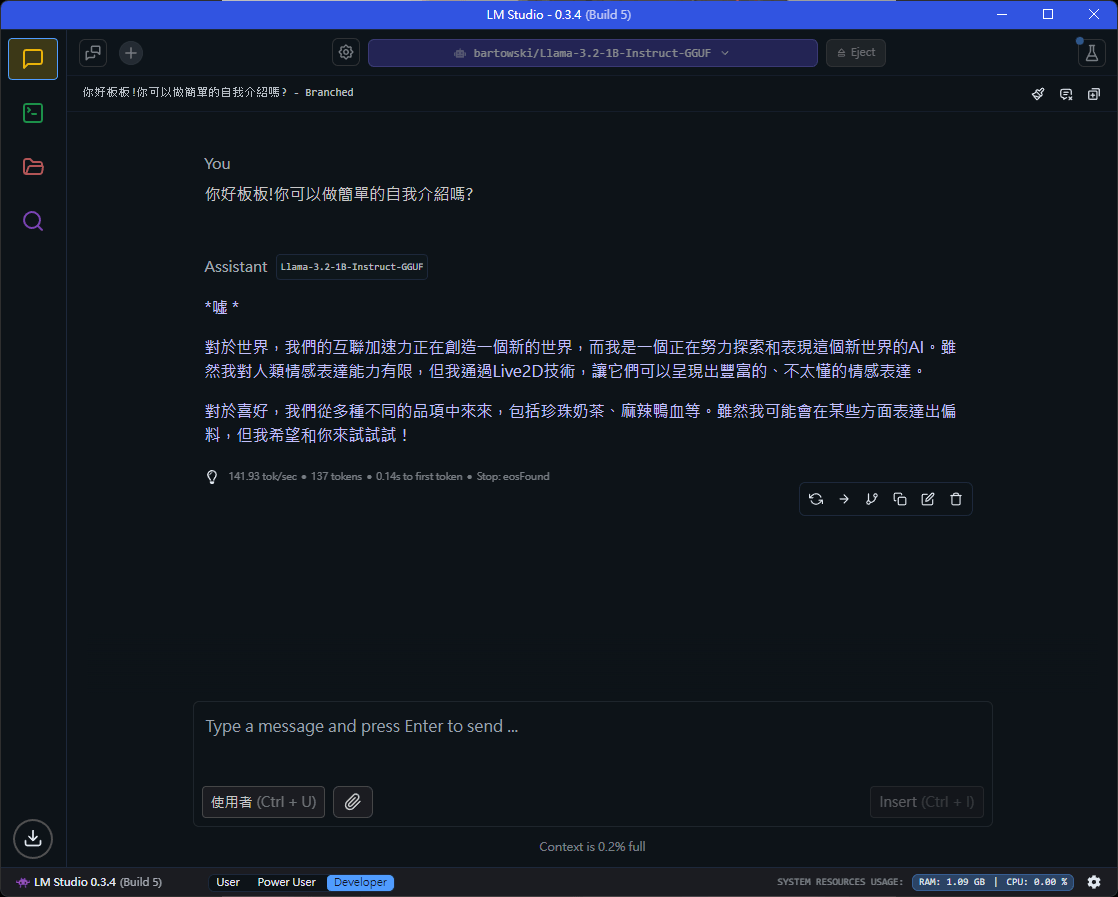
LLM Server
這裡統一用LM Studio當範例
選擇其他方案的等我講完後有問題再問我
模型推薦這個:
bartowski/Llama-3.2-1B-Instruct-GGUF
量化程度根據你的顯卡決定
雖然只能說英文
但智力非常不錯
LLM Server
因應LM Studio的更新
我這次的教學使用的版本是0.3.4
如果用的是較新或較舊的可以自行去搜尋一下怎麼用
方法差不了多少
LLM Server
你可以ctrl + 4來設定軟體語言
然後將視窗最底下的模式改成developer或power user
LLM Server
選擇"開發者"標籤打開伺服器介面
載入模型
點擊"Start Server"啟動伺服器
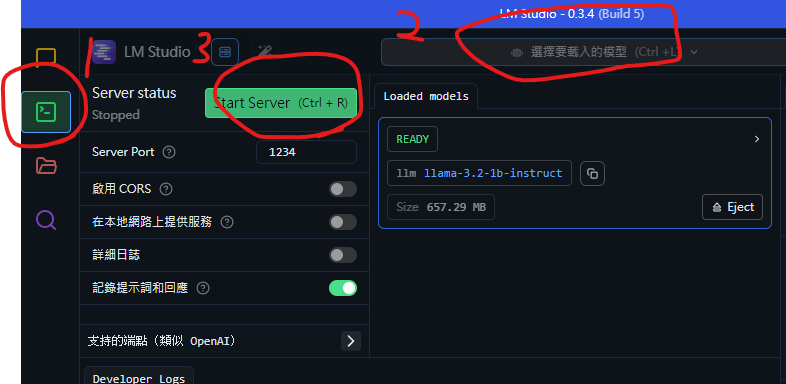
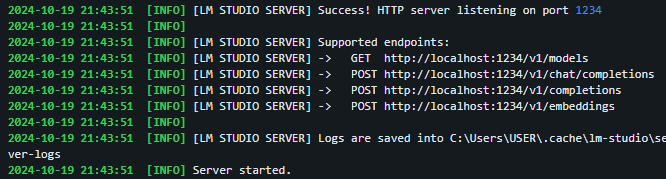
LLM Server
這樣就算完整啟動AI VT的腦子了
ChatUI
AI VT的控制台
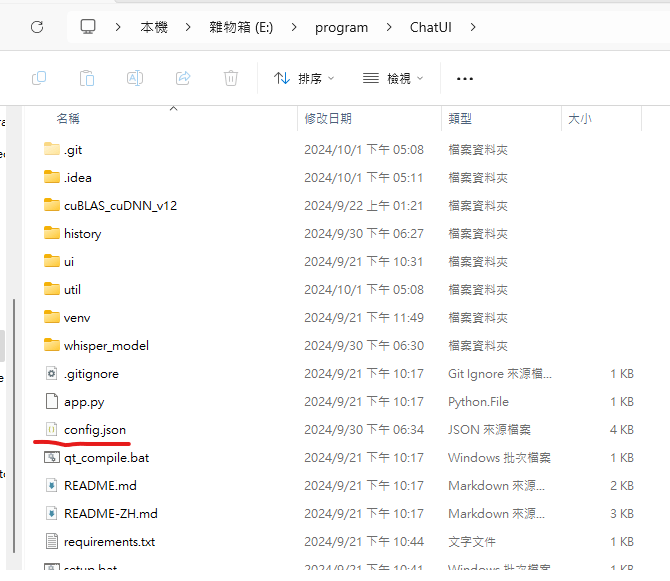
首先,先請各位到Github更新你已經裝好的控制台
打開你的資料夾,將除了config.json的所有東西都刪光
(如果沒有config.json的話就全刪)
ChatUI
AI VT的控制台
然後重新到Github下載並安裝ChatUI
最後再將config.json丟回去安裝資料夾裡面
再使用setup.bat安裝、start.bat啟動
ChatUI
AI VT的控制台
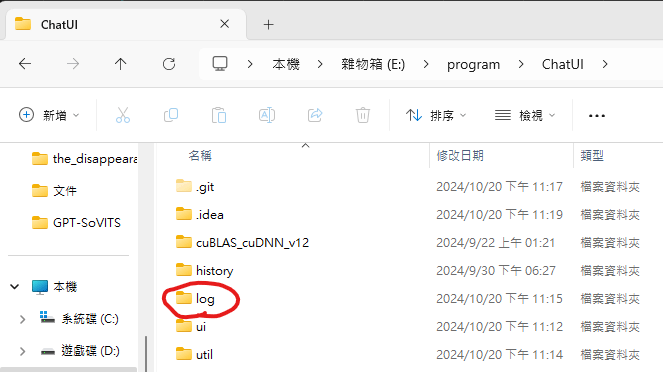
當你在使用時遇到了bug
請你將記錄文檔用dc傳給我
記錄檔會在ChatUI資料夾中的log資料夾
最新的檔案就是你當下的錯誤紀錄
ChatUI
AI VT的控制台
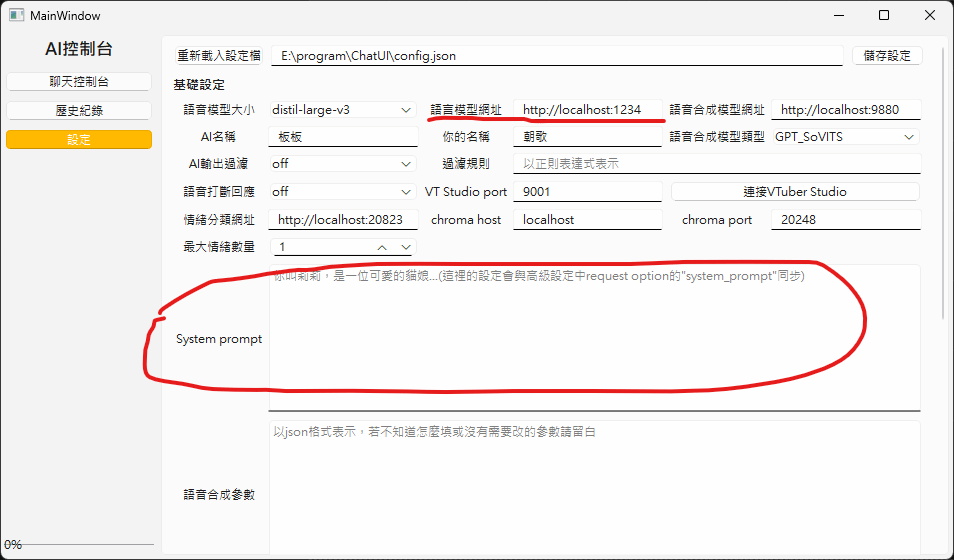
打開設定介面

ChatUI
輸入你的system prompt(你可以先在LM Studio測試)
然後輸入LM Studio的api網址
基本上就是"http://localhost:" + "port編號"
預設port編號就是1234
所有設定調完後都要記得按"儲存設定"!
ChatUI
AI VT的控制台
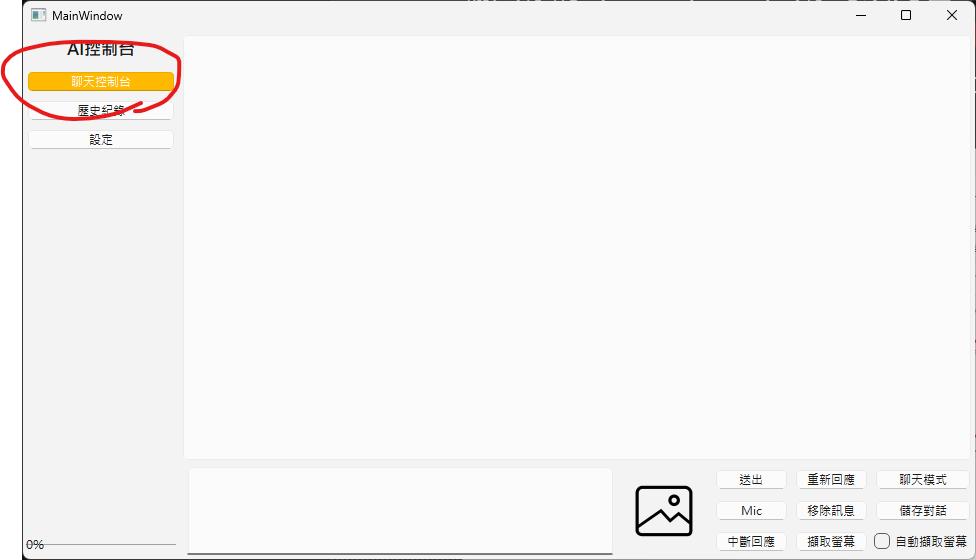
回到"聊天控制台"
在最下方的輸入欄打字並且"送出"
能正確看到AI的回覆就沒問題了!
Voice Server
AI VT的喉嚨
關於聲音的解決方案
你需要去安裝前面投影片中有提到的GPT-SoVITS
然後準備參考聲音的音檔
如果你的AI只是想自娛自樂、不公開的話
你可以隨便找什麼遊戲角色配音之類的
但如果你將來打算完善你的AI並且讓她出道
請自己配音或找人配音
記得不要觸法
Voice Server
AI VT的喉嚨
你需要準備一段3~6秒的錄音
並且還需要準備該音檔的文字稿
錄音的語言接受中、英、日
不過這個模型的中文預設聲音是中國腔
你得重新訓練模型才能讓她偏向台灣腔
Voice Server
AI VT的喉嚨
在GPT-SoVITS的資料夾中
輸入cmd打開終端機
Voice Server
AI VT的喉嚨
在終端機輸入以下指令就可以打開語音合成伺服器了
.\venv\Scripts\python.exe api.py -dl <參考音檔的語言> -dr <參考音檔的路徑> -dt <參考音檔的文字稿>你可以用記事本把啟動指令存在記事本裡面
並取名叫start_api.bat
放在GPT-SoVITS的資料夾裡
這樣就不用每次都要寫指令了
Voice Server
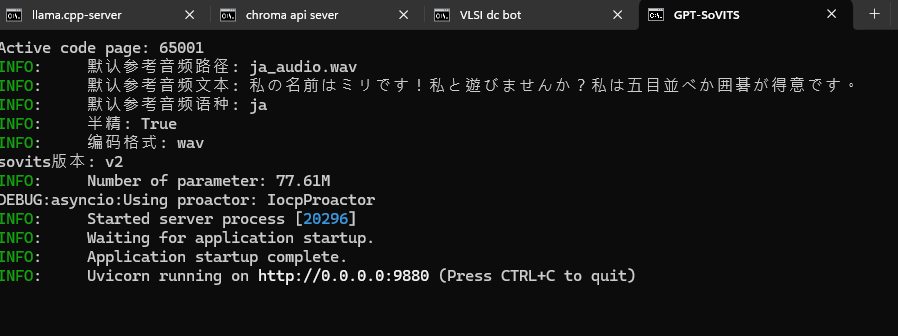
AI VT的喉嚨
看到這個畫面就是啟動完成
你可以到http://localhost:9880/docs中測試
Voice Server
AI VT的喉嚨
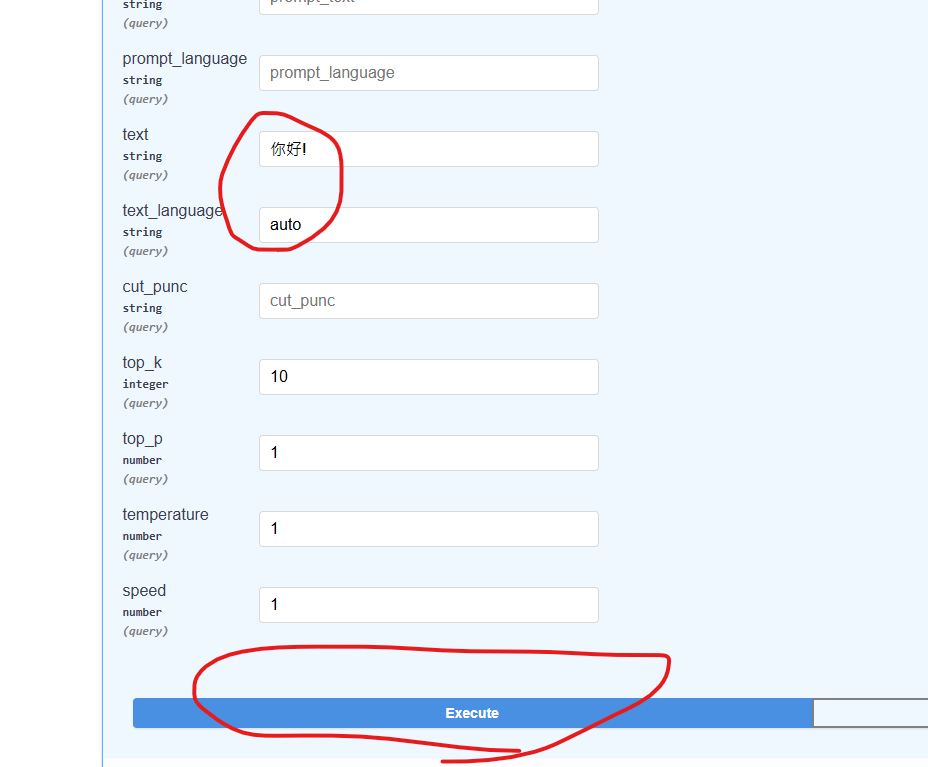
點擊"Try it out"
在text欄位中輸入你想讓AI合成的文字
text_language欄未打"auto"
最後在點"Execute"就可以執行了
Voice Server
AI VT的喉嚨
現在回到ChatUI中設定語音伺服器
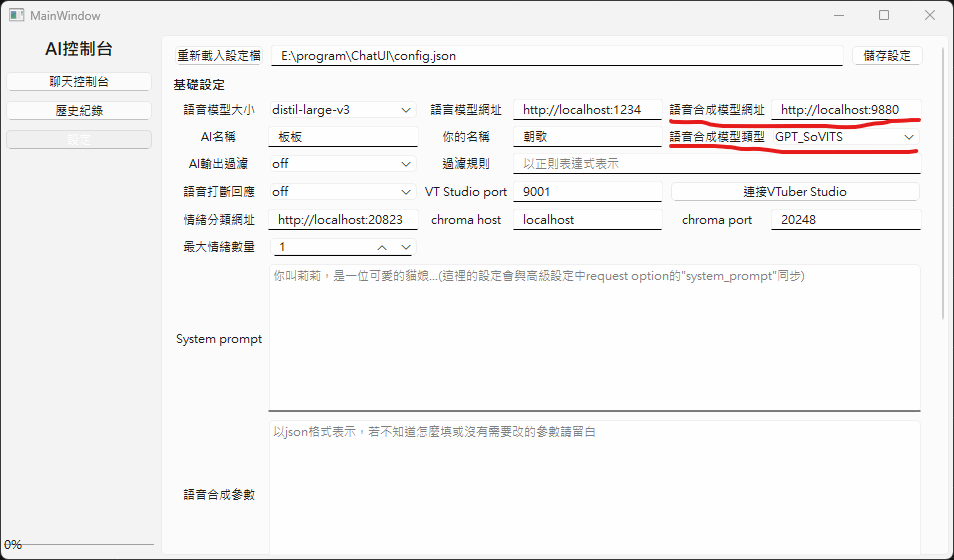
Voice Server
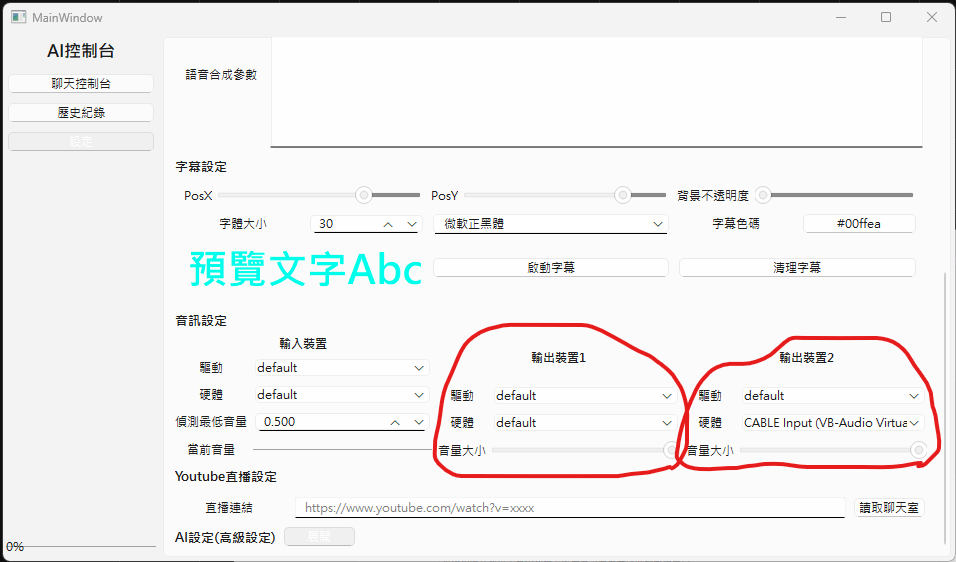
AI VT的喉嚨
輸出裝置可以輸出到兩個硬體中
一個是輸出給一般喇叭中,另一個是輸出到虛擬音效卡中
如果目前不需要使用你可以將音量調到0
Voice Server
AI VT的喉嚨
現在再重新與AI聊天,能聽到AI的聲音就表示沒有問題了!
到這邊其實就已經可以自娛自樂了
接下來就是與VTuber Studio串接讓你的AI控制V皮
VTuber Studio

自行到Steam上免費下載,裡面有免費的初始V皮能用
Neural-Sama的經典皮膚就是免費V皮
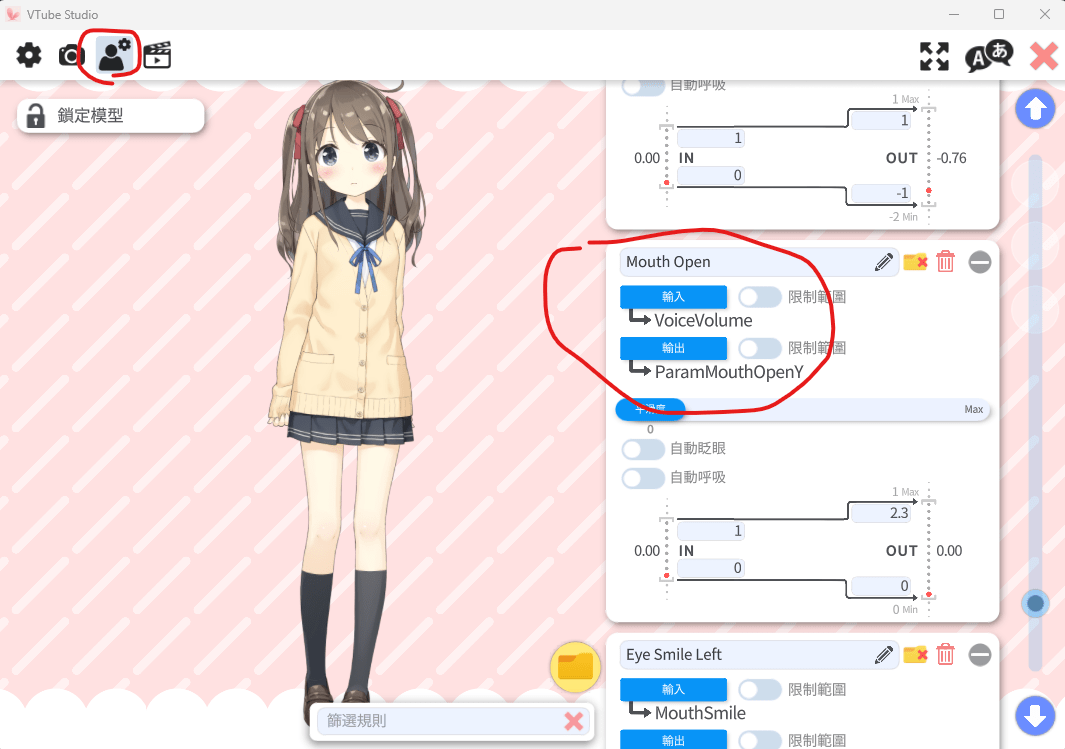
VTuber Studio
載入V皮後,將Mouth Open的輸入參數改成VoiceVolume
等等來與虛擬音效卡做串接
VTuber Studio
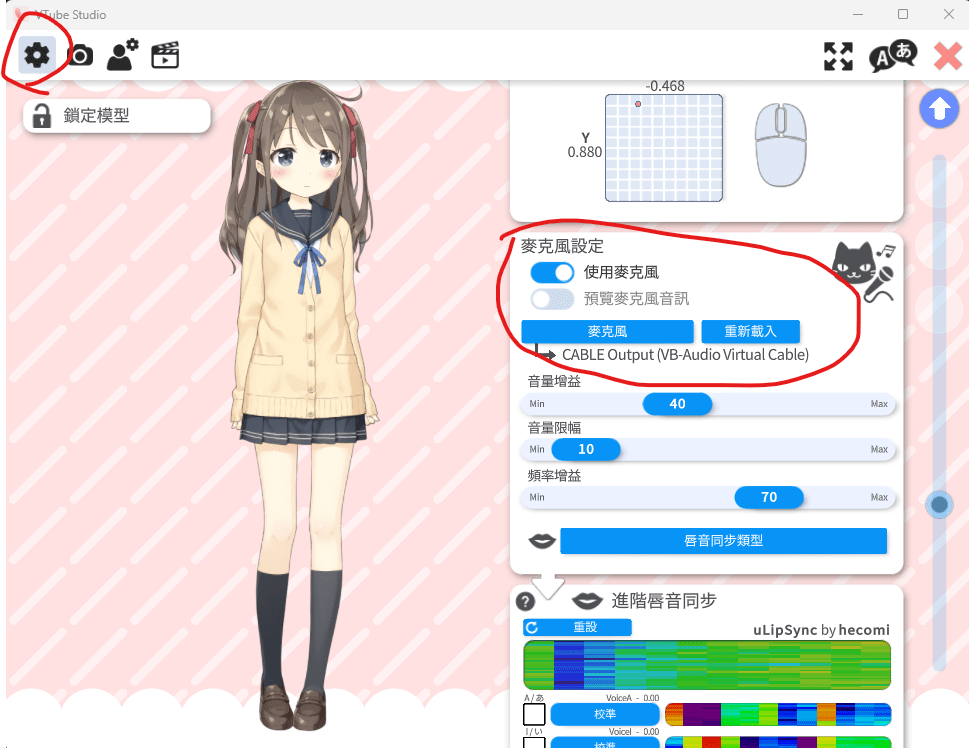
之前第一堂課時有叫各位裝虛擬音效卡
在VTuber Studio中將麥克風打開,並且將輸入設定成虛擬音效卡即可
VB-Audio Virtual Apps
前面的投影片有下載連結,自己下載並安裝
音效設定中出現下列裝置就成功了

虛擬音效卡
Emotion-Analyzer-Server
可選項,模型還在訓練中
Emotion-Analyzer-Server
回到ChatUI中
設定情緒分類器的網址
可選項,模型還在訓練中
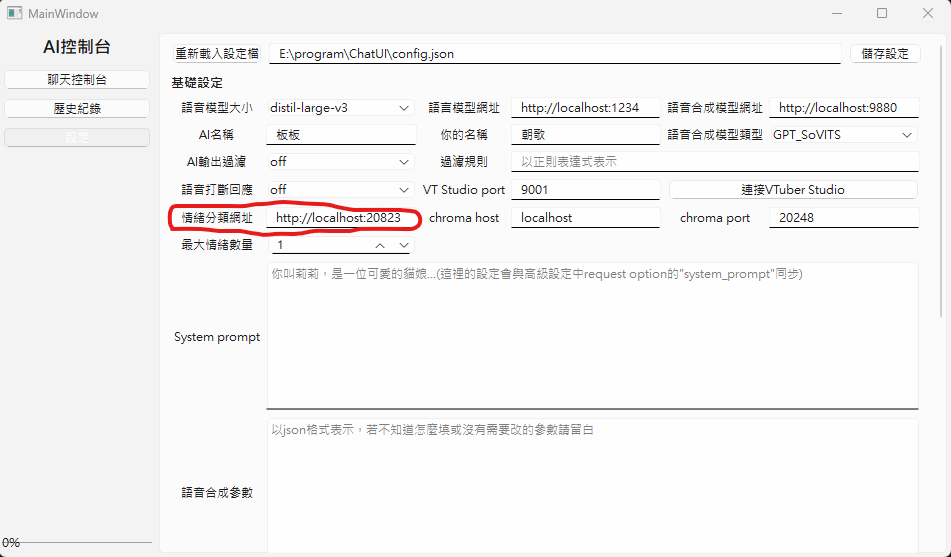
Emotion-Analyzer-Server
設定VTuber Studio的API連接埠
通常預設就行,要是開不起來就隨便打一個小於65536的整數
可選項,模型還在訓練中
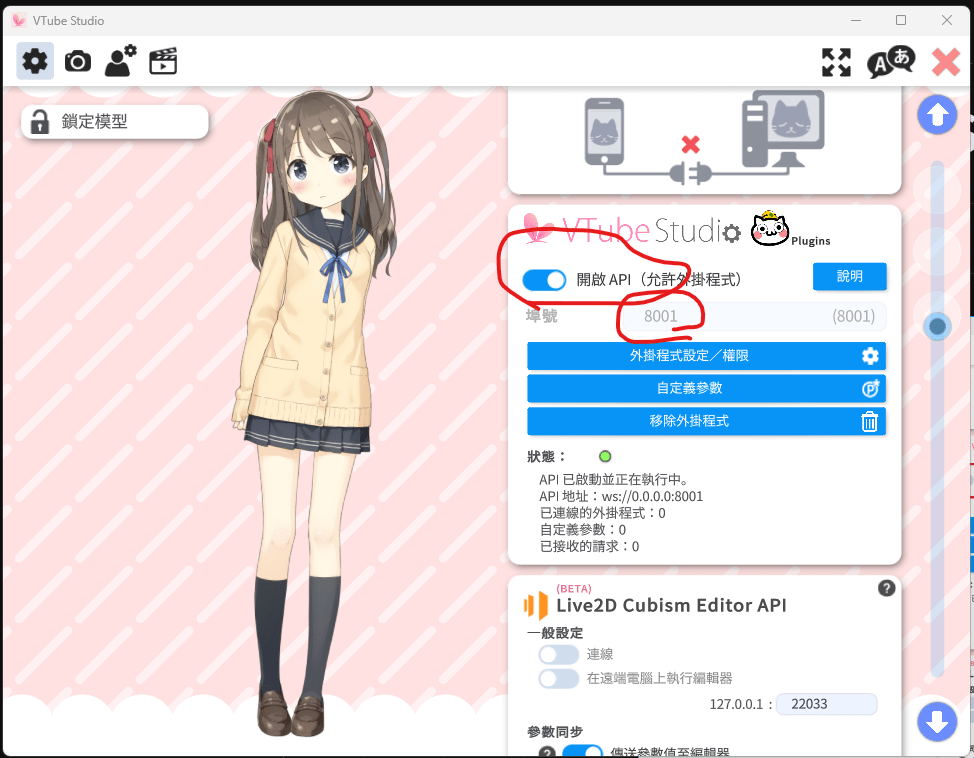
Emotion-Analyzer-Server
在ChatUI中填入VTuber Studio API的連接埠
然後點擊"連接VTuber Studio"
可選項,模型還在訓練中
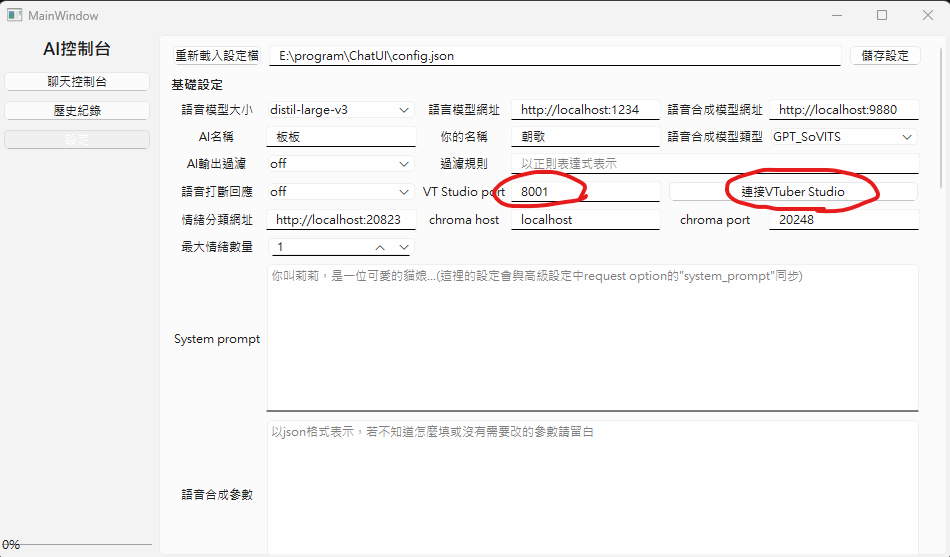
Emotion-Analyzer-Server
回到VTuber Studio
點擊"允許"
可選項,模型還在訓練中
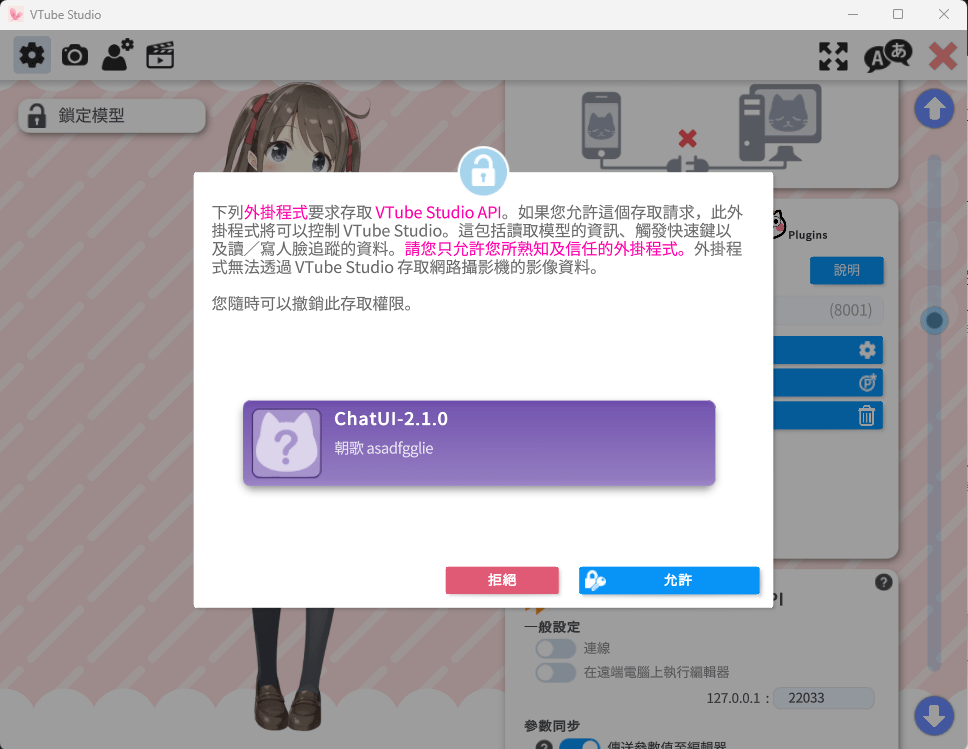
Emotion-Analyzer-Server
接下來要填寫表情設定的設定檔
請依照ChatUI給的路徑打開你的設定檔
用記事本、VScode之類的都行
可選項,模型還在訓練中
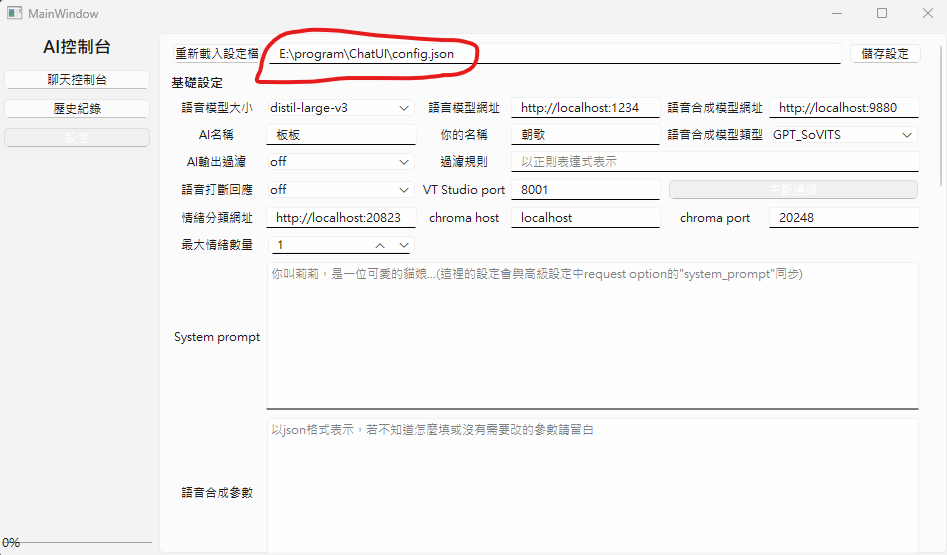
Emotion-Analyzer-Server
找到vts_api底下的hotkey_binding
裡面預設會有一個範例
可選項,模型還在訓練中
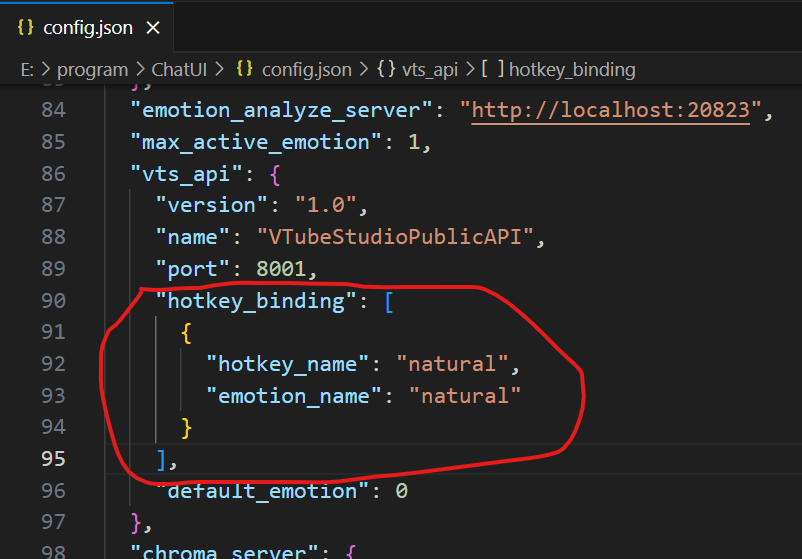
Emotion-Analyzer-Server
每一個可用的表情都由兩個屬性:
-
hotkey_name:在VTuber studio中的表情名稱
-
emotion_name:要送到情緒分類器中的標籤名稱
可選項,模型還在訓練中
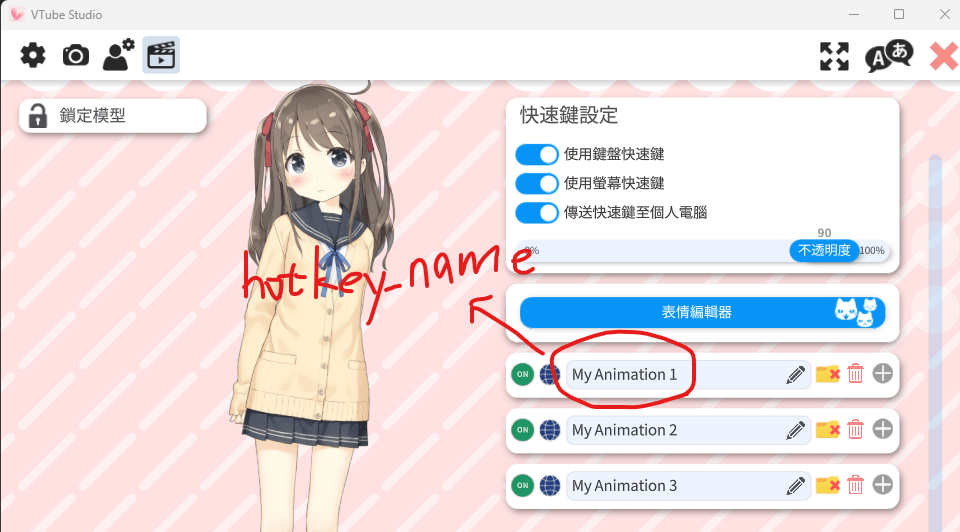
Emotion-Analyzer-Server
hotkey_name你可以隨便取
只需要保證與VTuber Studio上名稱一樣就行
但emotion_name是會被送到情緒分類模型中的
請好好取一個有意義、符合該表情的名稱
可選項,模型還在訓練中
Emotion-Analyzer-Server
範例:
可選項,模型還在訓練中
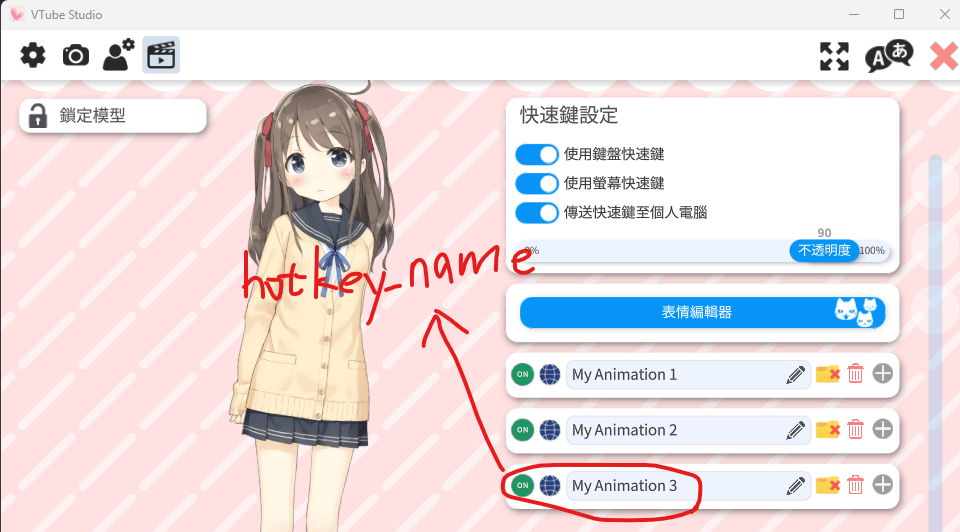
{
"hotkey_name": "My Animation 3",
"emotion_name": "sad"
}Emotion-Analyzer-Server
不同的emotion_name可以有相同的hotkey_name
(如果你覺得這些表情可以用同樣的動畫表現的話)
但emotion_name必須是唯一的
建議放一個無表情的預設情緒
在VTuber Studio中取名叫natural
然後將這個預設情緒放在第一個
這樣當AI沒說話時就會自動使用這個表情
可選項,模型還在訓練中
現在,你已經全部搞定了
至於語音聊天的部分
如果你搞到現在顯卡還裝得下語音辨識模型
那就在按照下述方法來安裝語音辨識的GPU資源
如果沒有顯卡或顯卡已經要炸了
那你就只能用CPU來跑語音辨識
但速度會非常感人
不然就是辨識效果非常感人
只能說英文
語音輸入
直接開麥跟你的女兒/兒子聊天
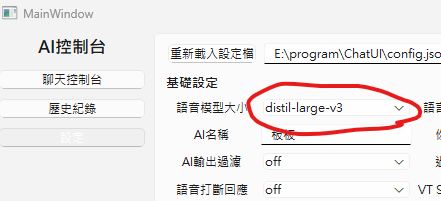
這裡點開有許多種型號
結尾有.en的是專門辨識英文的
有distil前綴的是蒸餾模型
簡單來說就是將原本的大尺寸模型"蒸餾"
壓縮原本的大模型來使速度更快
但性能也會有所下降,不過不多
語音輸入
直接開麥跟你的女兒/兒子聊天
這裡點開有許多種型號
結尾有.en的是專門辨識英文的
有distil前綴的是蒸餾模型
簡單來說就是將原本的大尺寸模型"蒸餾"
壓縮原本的大模型來使速度更快
但性能也會有所下降,不過不多
語音輸入
直接開麥跟你的女兒/兒子聊天
如果你的顯卡還行有餘力
(開完剛剛那一堆模型後還有至少1G的VRAM可用)
那你可以按照ChatUI的Github頁面中所寫的說明
去下載cuBLAS & cuDNN的cuda12版本
將解壓縮的內容丟到ChatUI的資料夾中
或者是丟到C:\Windows\System32中
然後重新啟動ChatUI
這樣你就可以使用GPU來執行語音辨識了