Streams
A story about streaming MySQL results
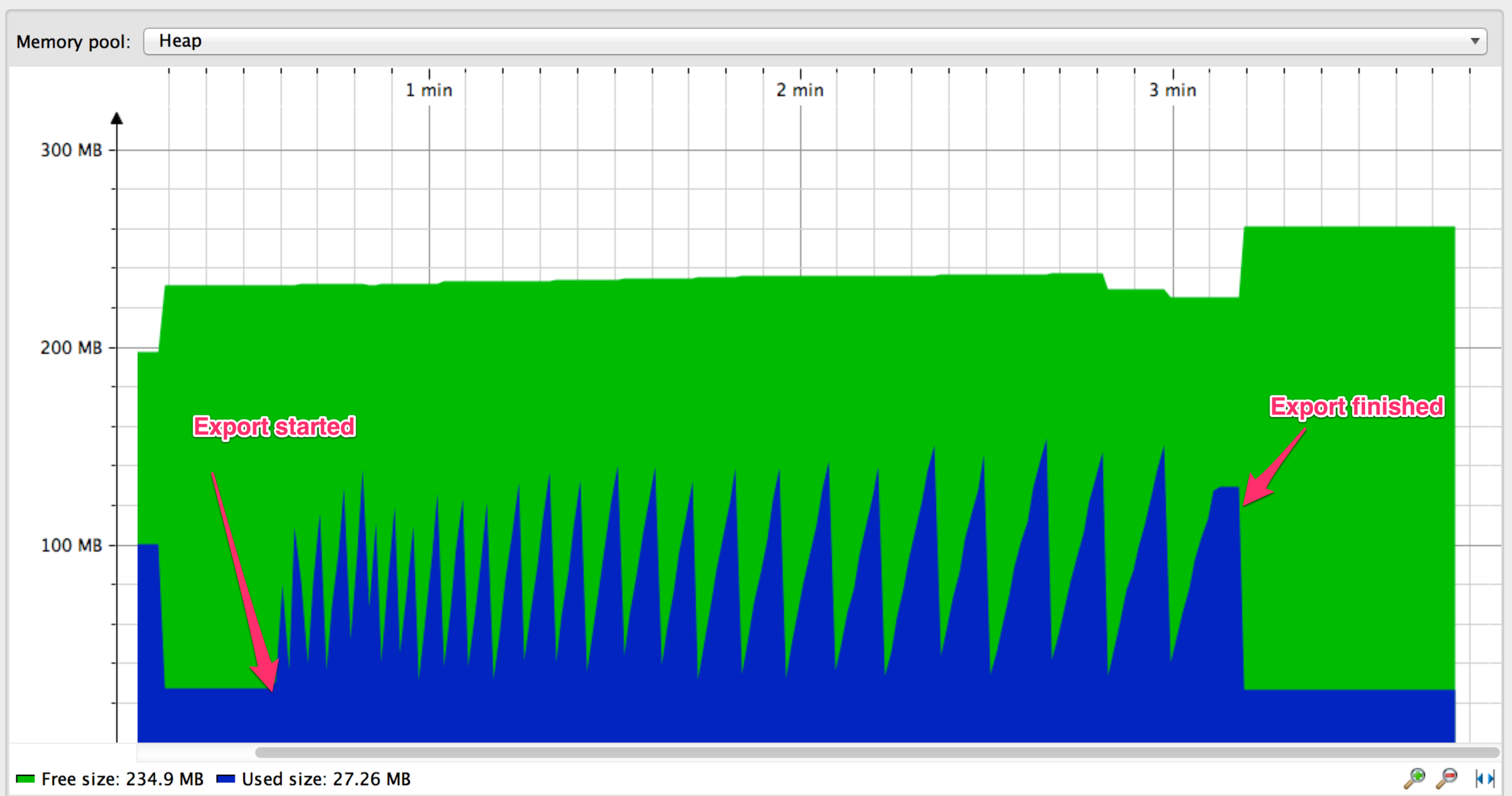
Paginated query -> slow
A story about streaming MySQL results
Streamed query -> overload memory
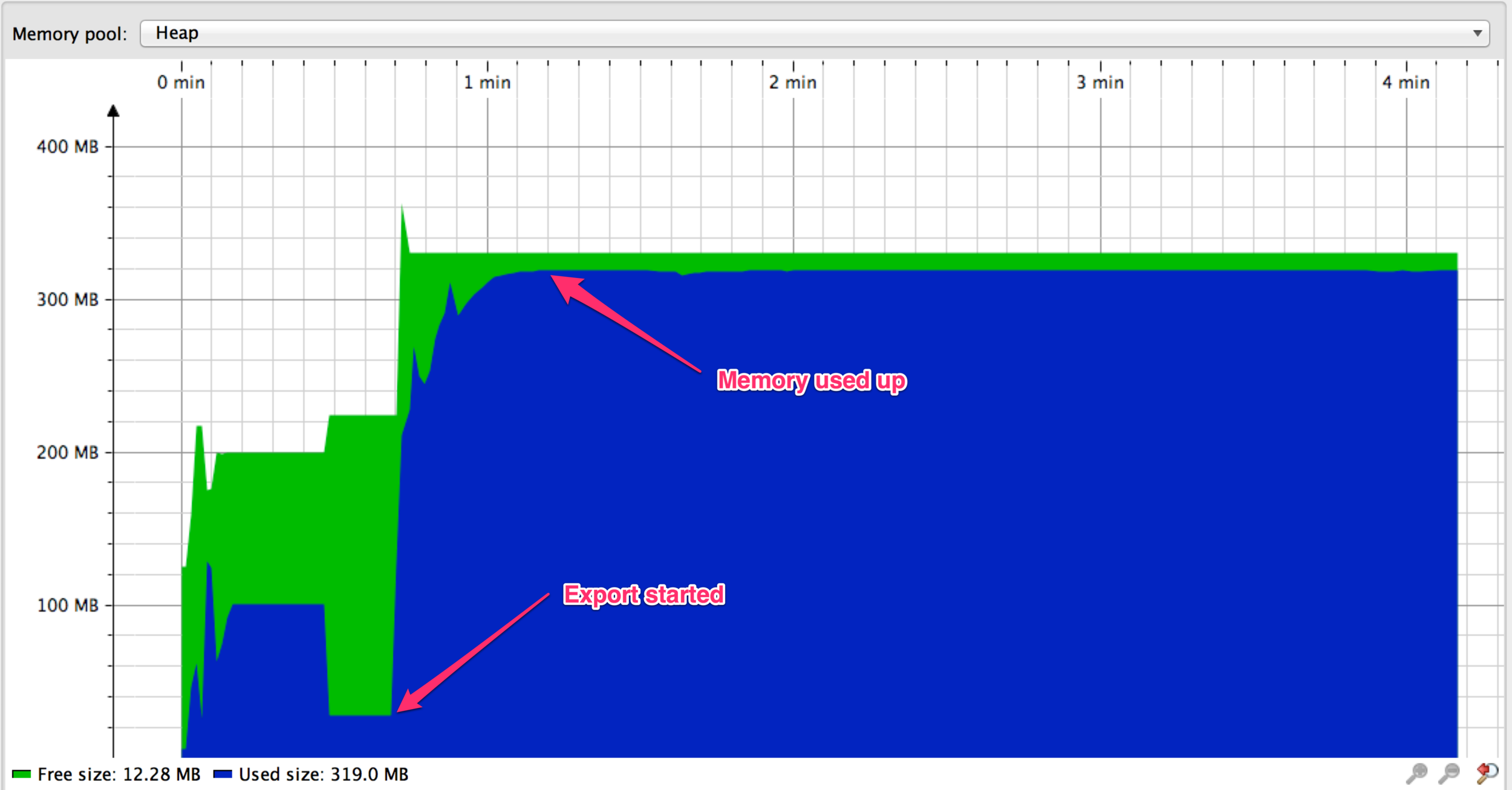
A story about streaming MySQL results
Streamed query with setting fetch size -> 15 times faster
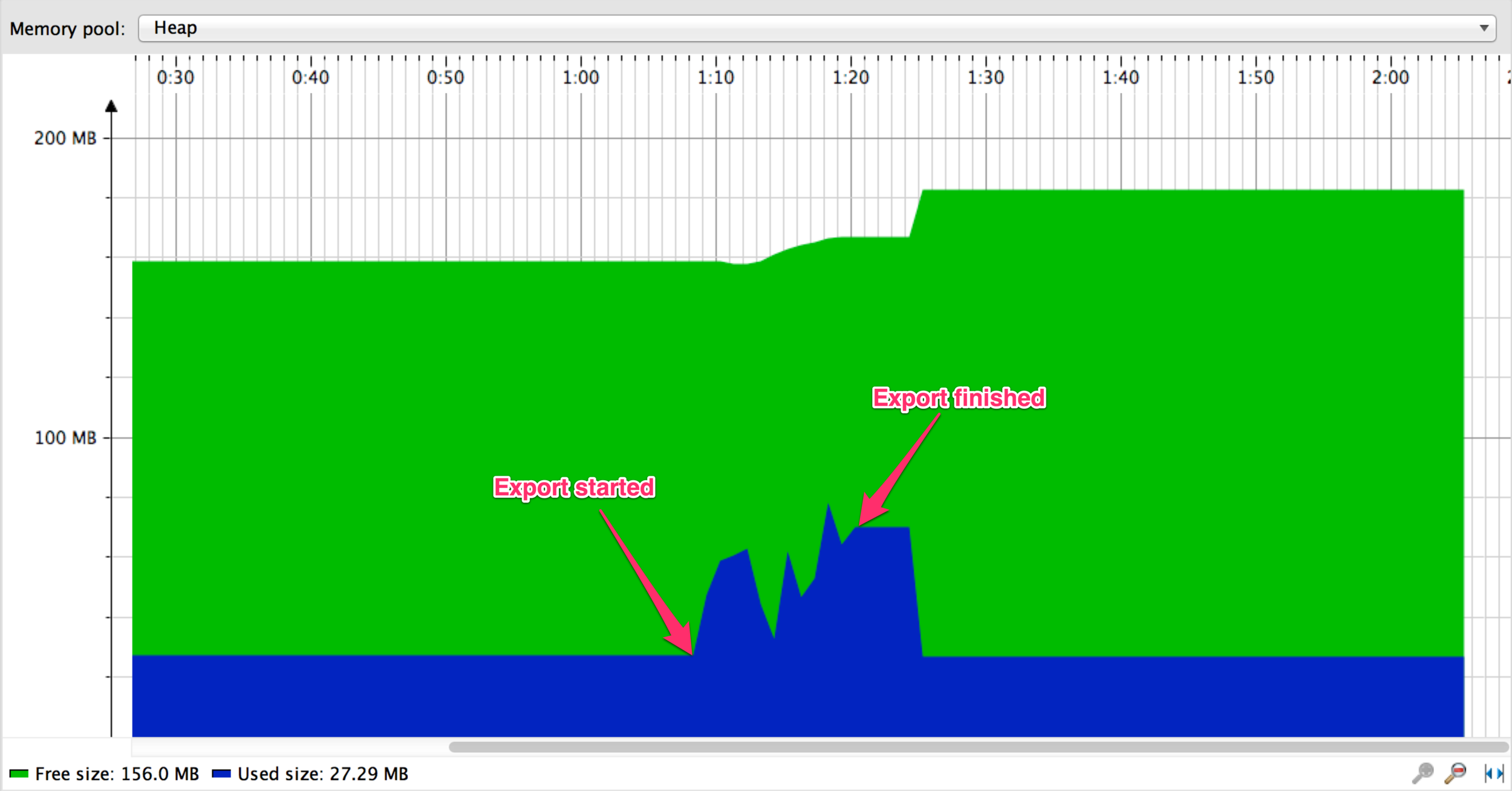
Motivations
Use case 1: Huge inputs
- Huge inputs are likely to be transported by several chunks
- Loading all before processing is a waste of time
- Loading all before processing is a waste of memory
- Input chunks can be processed asap
- Input stream can be paused to limit memory consumption and prevent crashes
Use case 2: Composing processes
- Data flows can often be designed as composable independent scalable processes
- Streams can be composed by piping streams to others with backpressure
Examples
- HTTP requests and responses
- TCP sockets
- File system
- zlib
- crypto
- process (also child processes)
Concepts
Streams
- are event emitters
- implement readable, writable, or both interfaces
- initially transport buffers or strings
- have an object mode to transport arbitrary values
Readable streams
- can be read
- can end
- can be piped to a writable stream
- can be paused
Writable streams
- can be written
- can be finished
Events
Readable streams
- readable
- data
- error
- end
- close
Writable streams
- drain
- pipe/unpipe
- error
- finish
- close
Streams (from implementer side)
Additionally, the stream implementer can
- implement _read method of Readable streams
- implement _write method of Writable streams
- implement _transform method of Transform streams
Dive deeper
Understand backpressure with pipes explanation
We scratch the surface. To dive deeper, you can read this stream handbook (quite old though)
Examples
Built-in streams: process
process.stdin
.pipe(process.stdout);Pipe stdin to stdout
process.stdin
.pipe(new stream.PassThrough())
.pipe(process.stdout);Same with an identity transform
Built-in streams: fs
fs.createReadStream('./package.json')
.pipe(process.stdout);package.json content written to stdout
// write what you are typing in a file
process.stdin
.pipe(fs.createWriteStream('./test.txt'));
stdin written to a file
Built-in streams: child_process
// write js files line counts to a file
child_process
.exec("wc -l `find -name '*.js'`")
.stdout.pipe(fs.createWriteStream('./line-count.txt'));
shell command output written to a file
Built-in streams: TCP sockets
// client.js
const net = require('net');
const client = new net.Socket();
client.on('connect', () => {
console.log('client has connected');
});
process.stdin.pipe(client);
client.on('end', () => {
console.log('client has disconnected');
});
client.connect(3000, 'localhost');
// server.js
const net = require('net');
const server = net.createServer(socket => {
console.log('client has connected');
socket.on('data', chunk => {
console.log('received chunk', chunk);
});
socket.on('end', () => {
console.log('client has disconnected');
});
});
server.listen(3000, 'localhost');Community libraries
Whole libraries
- highland
- ...
Collections
Core streams mirror
- readable-stream
- ...