Web Crawler
~ Overview ~
Types
Indexing / Listing
Scraping Content
Process
- Fetch
- Parse
- Analyse
Options
Service
Headless
String
DOM
Service
Import, kimono & Co.
[+] simple |
[-] external
Headless
PhantomJS (WebKit)

SlimerJS (Gecko)

triffleJS (Trident)
[+] extensive
|
[-] resources
String
Regular Expression
[+] community |
[-] complex
DOM
/** Count all of the links from the Node.js build page **/
var jsdom = require("jsdom");
var url = "http://nodejs.org/dist/"
libs = ["http://code.jquery.com/jquery.js"];
jsdom.env( url, libs, function (errors, window) {
console.log("there have been %s nodejs releases!", window.$("a").length);
});
[+] flexible |
[-] manual
TOOL
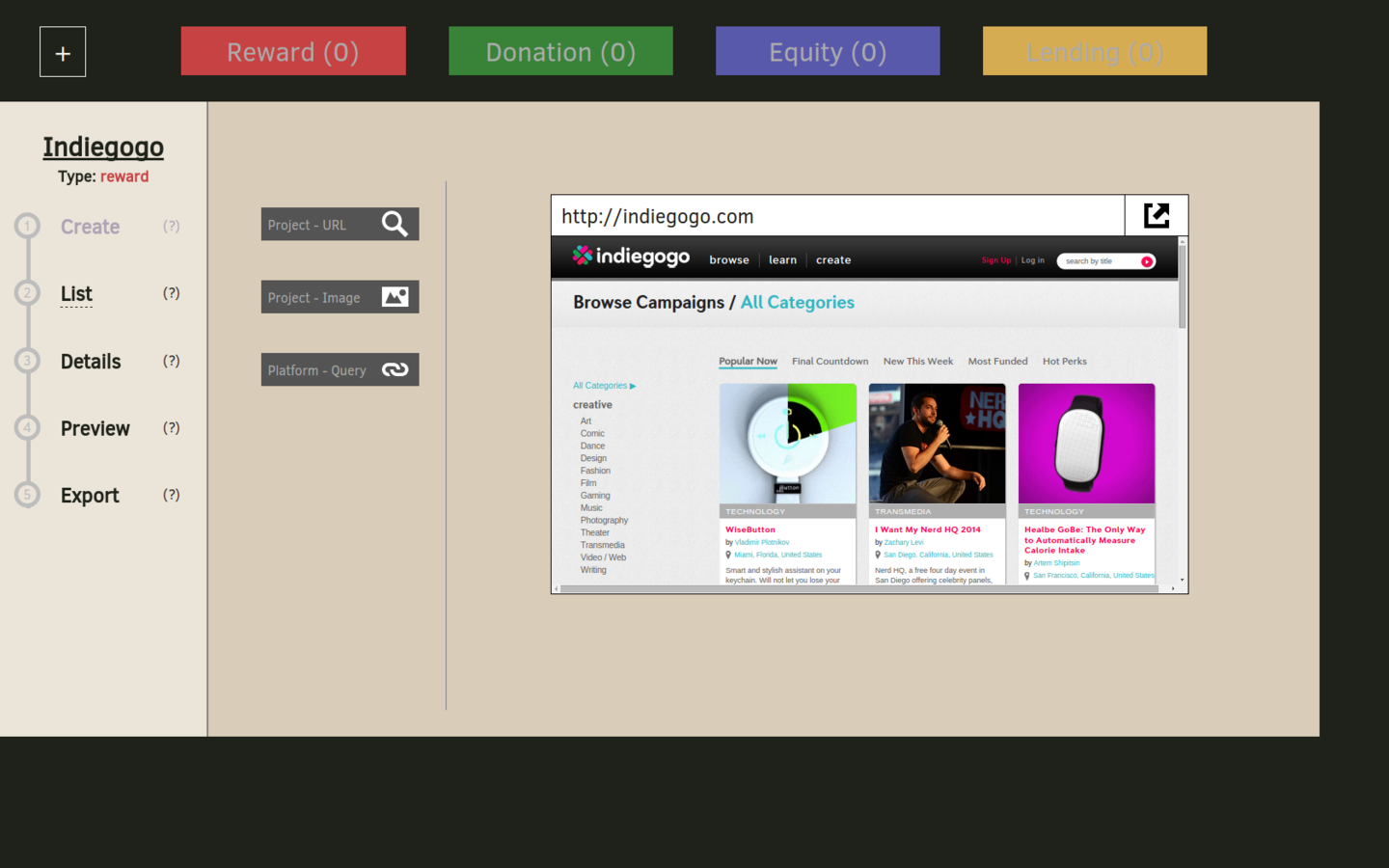
Crawl - Editor
System
Application (Client)
|
Application (Server)
+ CouchDB
|
Crawler
(pool)
+LevelDB
+LevelDB
+LevelDB
+LevelDB
-
-
-
-
Worker
Worker
Worker
Worker
|
queue
queue
|
queue
queue
|
queue
queue
|
queue
queue
Task
Task
Task
Task
Task
Task
Task
Task
1 {
2 {
3 {
4 {
5 {
Best Practice
- respect HTTP
- identify the crawler
- regard restrictions
- robot.txt
- min. delay 1sec
source: W3C
- minimize traffic (gzip, re-use socket)