How to approach a Machine Learning problem using Python ?
YouTube Like Count Prediction

ayush0016






Ayush Singh
-
Data Preprocessing -
Data Exploration & Analysis -
Feature Engineering -
Feature Selection
General Workflow/Pipeline
MODEL
-
Model selection -
Evaluation Metrics -
Cross Validation -
Parameter Tuning -
Plotting Curves
DATA
DATA PREPARATION
-
Data Collection -
Data Sources
Problem ?
Predicting YouTube Video Like Count given any video.


DATA

Data Collection
-
Public/Private Dataset -
Data Scraping -
API -
Internal databases


YouTube Data API
- Easy to use
- Good quota limit
- Quite extensive data
- ~22-24k across 15 categories
- Videos between 2010-2016
- ~0.35 Million
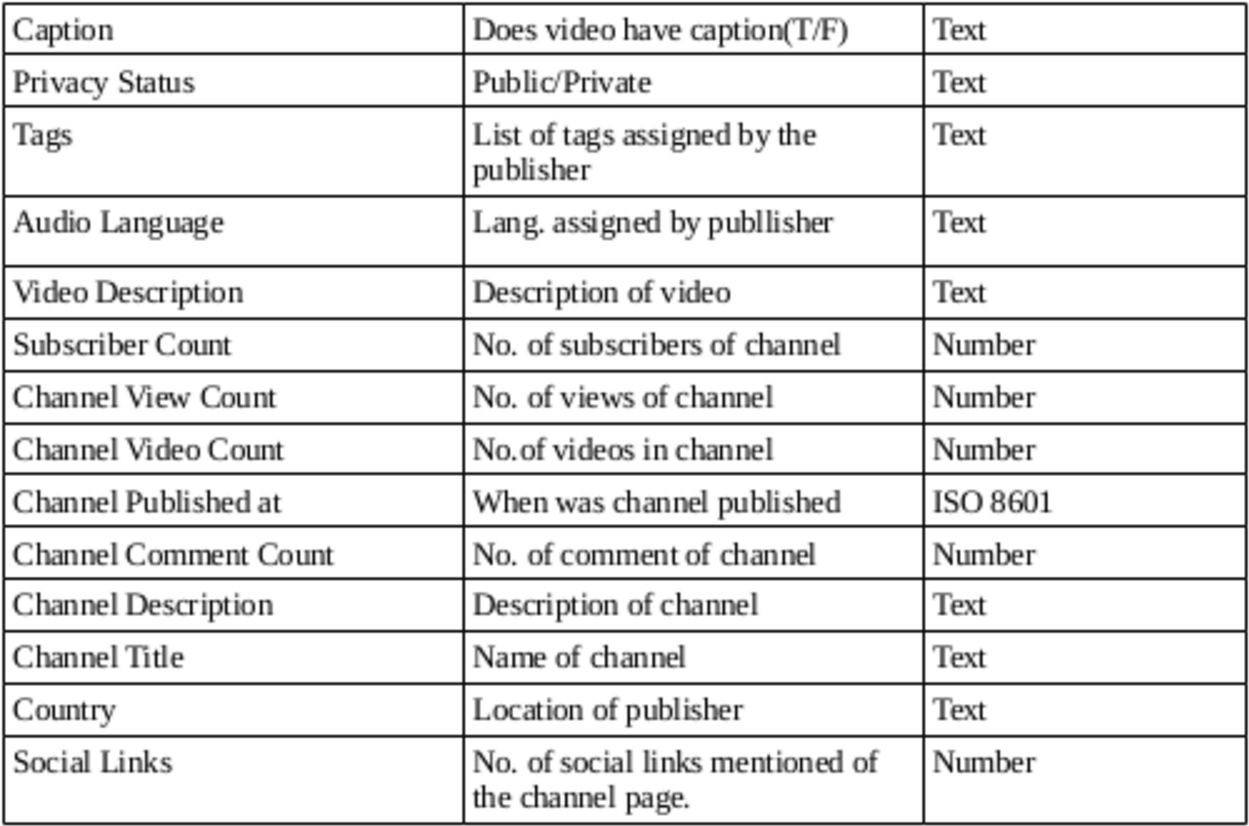
Dataset
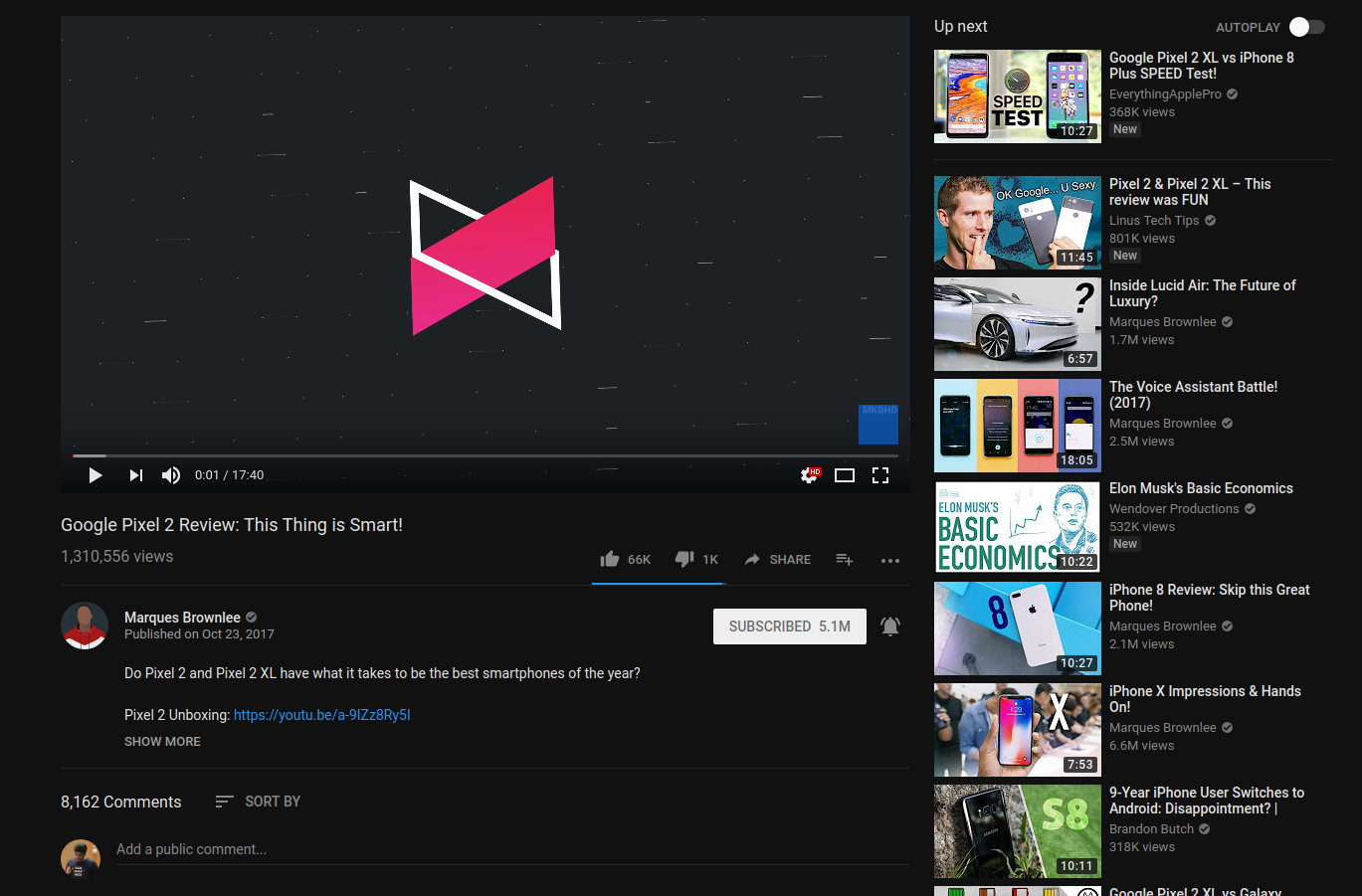
What all can we see ?
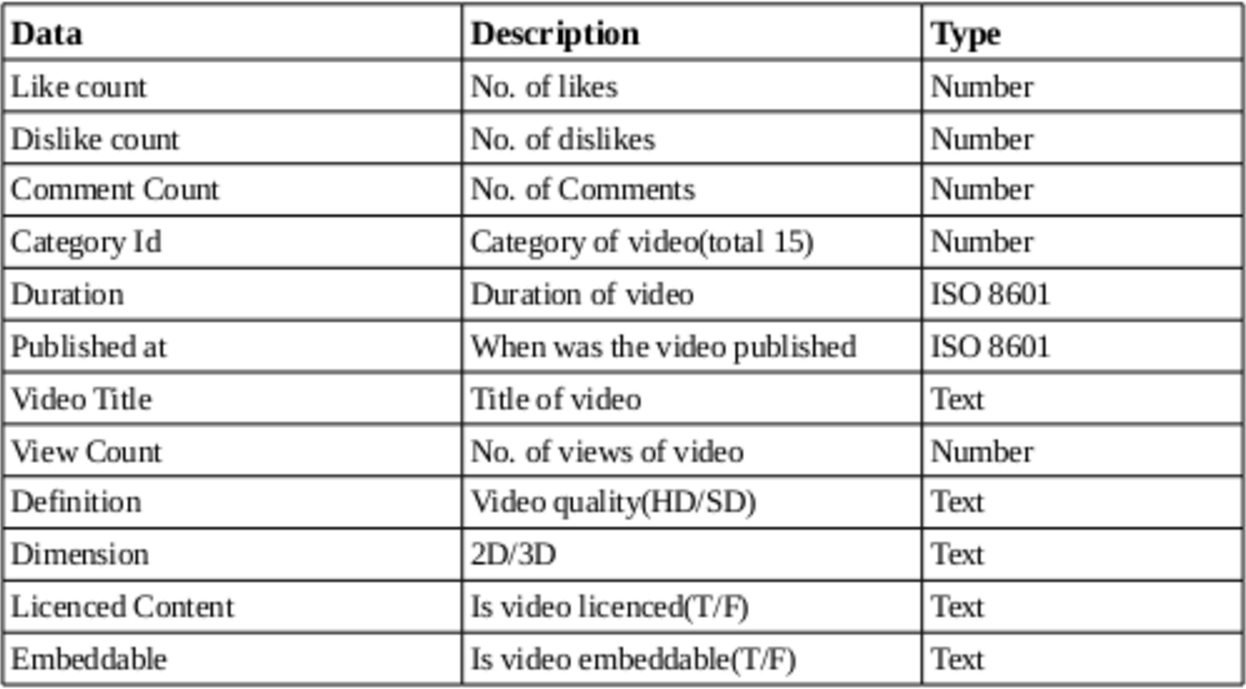
What all we have ?
DATA PREPRATION
Data Preprocessing
-
Formatting: Bring the data into a format which is easy to work with. eg. JSON to CSV ..
-
Cleaning: Cleaning data is the removal or fixing of missing data.
-
Transformation: Normalisation, standardisation, Scaling,Encoding Data

Data Exploration and Analysis
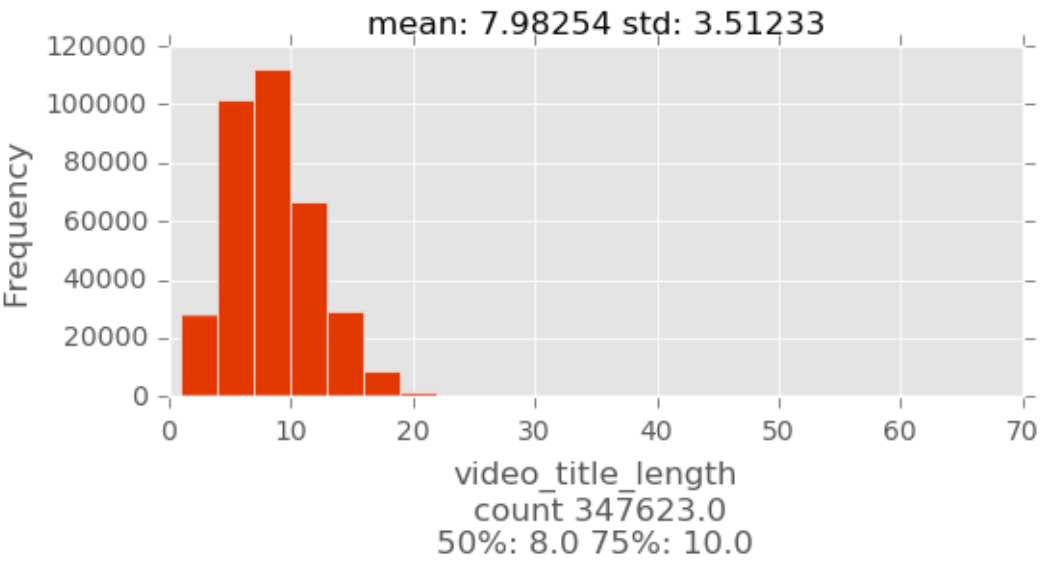
Univariate analysis is the simplest form of analyzing data. “Uni” means “one”, so in other words your data has only one variable.
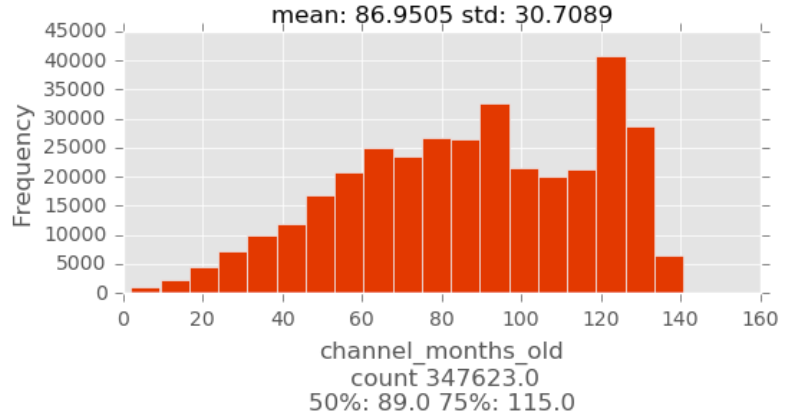
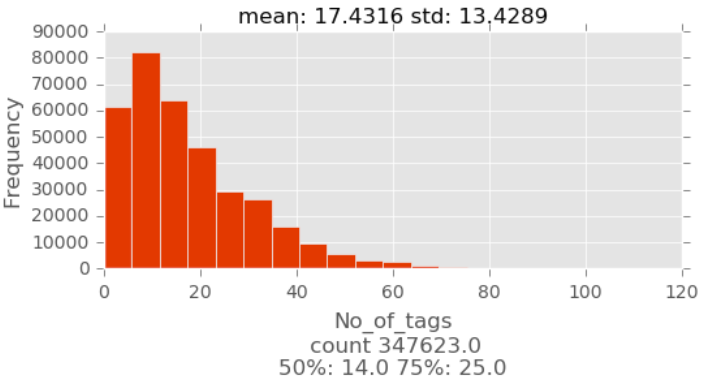
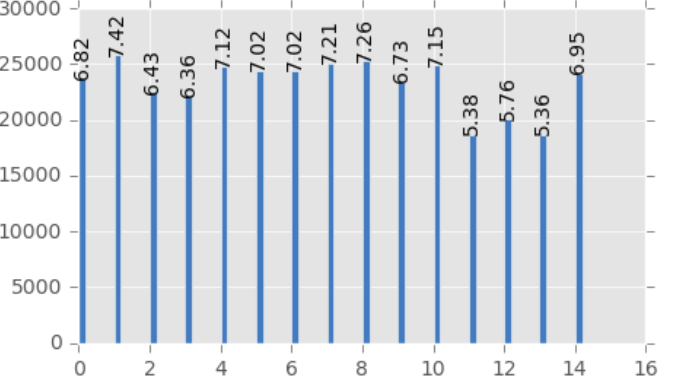

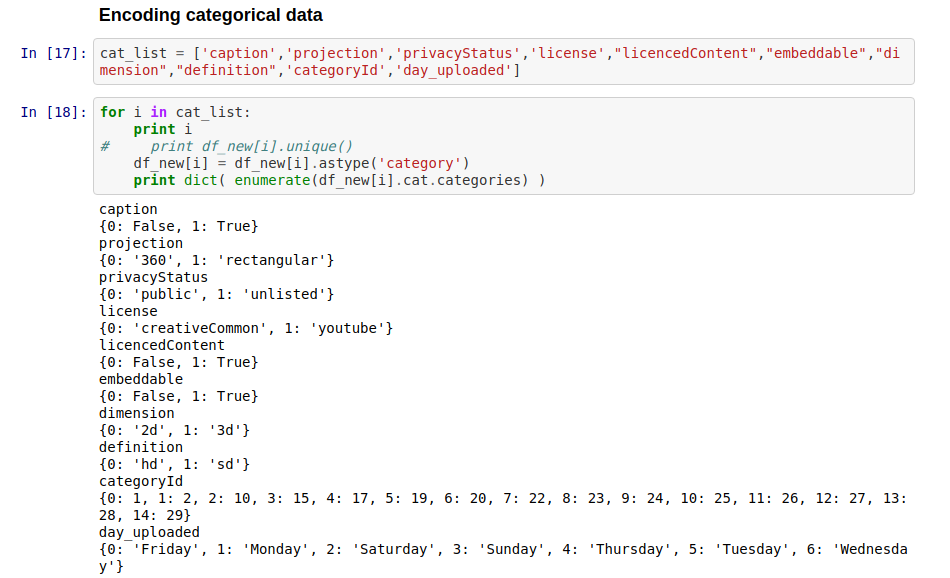
Feature Engineering
Process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.
It's an art comes with a lot of practice and looking at what others have done.

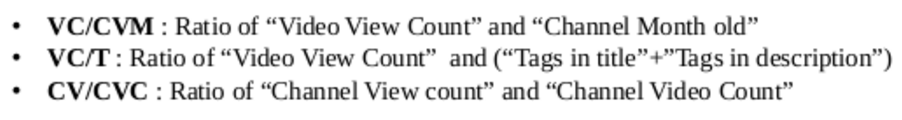
Feature Selection
Top reasons to use feature selection are:
-
It enables the machine learning algorithm to train faster. -
It reduces the complexity of a model and makes it easier to interpret. -
It improves the accuracy of a model if the right subset is chosen.
Process of selecting those attributes or features from our given pool of features that are most relevant and best describe the relationship between Predictors and Response .
Filter Method
Statistical test to infer the relationship between the response and predictors
Wrapper Methods
The learning algorithm (estimator) itself is used to perform the Feature Selection and select the top features .
-
Forward Selection -
Backward Elimination -
Recursive Feature elimination
| Feature\Response | Continuous | Categorical |
|---|---|---|
| Continuous | Pearson' Corr. | LDA |
| Categorical | Anova | Chi-square |
Bivariate Data Analysis
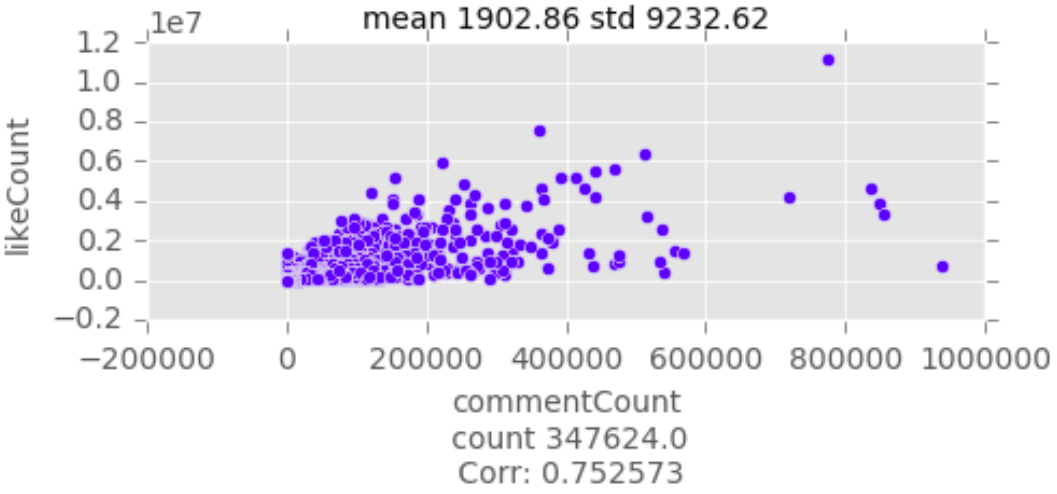
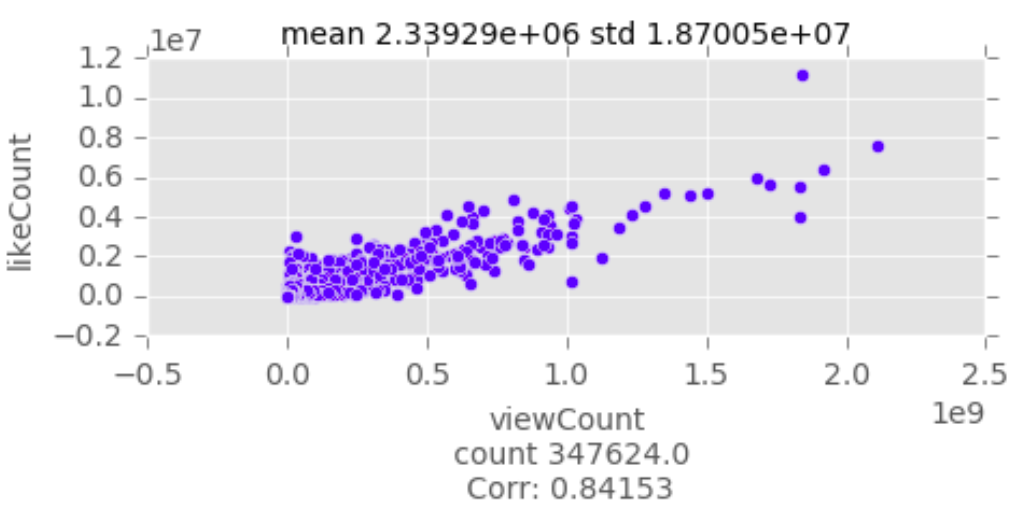
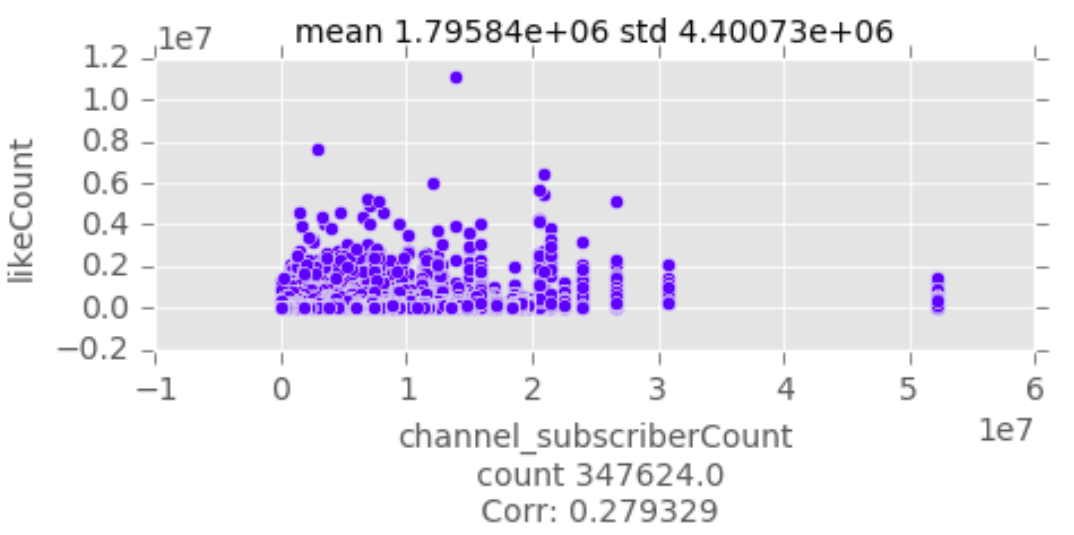

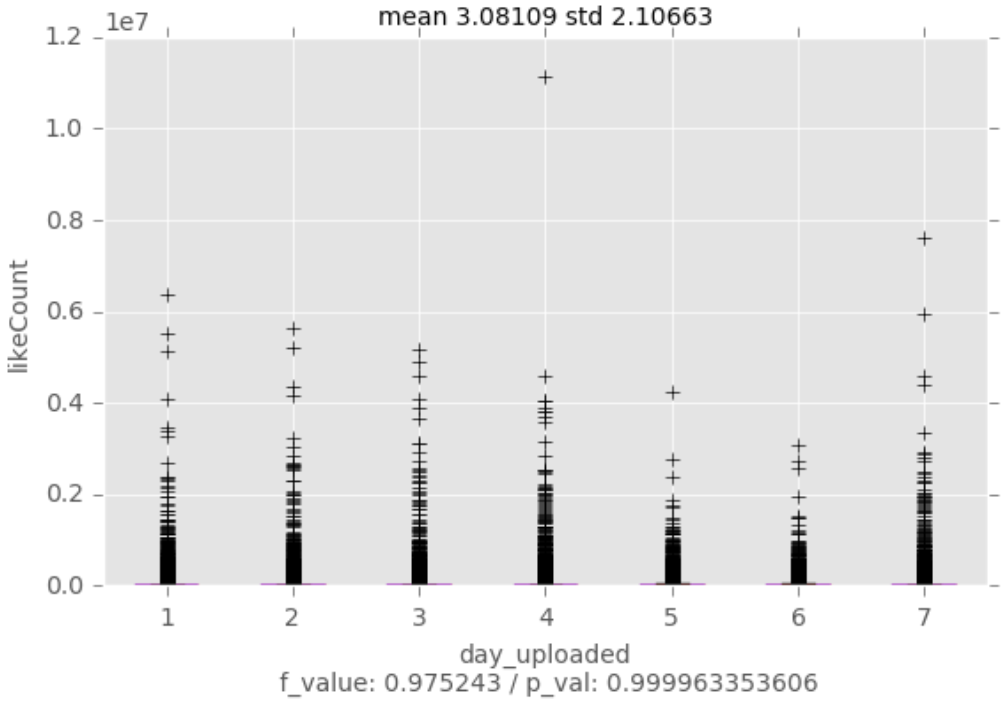
Recursive Feature Elimination
from sklearn.feature_selection import RFE
from sklearn.ensemble import RandomForestRegressor
''' Use Random Forest as the model . '''
Classifier = RandomForestRegressor()
''' Rank all features, i.e. continue the elimination until the last one . '''
Rfe = RFE(Classifier, n_features_to_select=5)
Rfe.fit(X,Y)
print Rfe.ranking
The final ones...
ViewCount, CommentCount, DislikeCount,
ViewCount/VideoMonthOld, SubscriberCount/VideoCount
MODEL
Training Set:
Testing Set:
a set of examples used by model for learning
a set of examples used only to assess the performance of a fully-trained estimator
Validation Set:
a set of examples used to tune the parameters of a model
Terminology
Model Selection
We generally use the following algorithms in the process of selecting a machine learning model:
Classification
Regression
-
Random Forest -
GBM -
Logistic Regression -
Naive Bayes -
Support Vector Machines -
k-Nearest Neighbors -
Neural Networksa
-
Random Forest -
GBM -
Linear Regression -
SVR -
Neural Networks
and many more...
Evaluation Metrics
Quatifying the quality of prediction
Regression
-
Mean absolute error
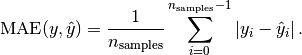
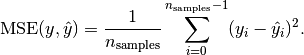
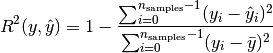
-
Mean squared error
-
R^2 Score
Classification
-
Accuracy
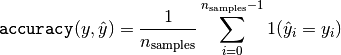
-
Precision,Recall
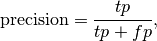
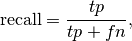
-
Log-Loss
Cross Validation
K Fold Cross Validation
Model evaluation technique to see how well the model is performing on unseen data and learning parameters.
Hyper Parameter Tuning
Grid Search
Exhaustive search over specified parameter values for an estimator.
Hyperparameters are parameters whose values are set prior to the commencement of the learning process.
They vary with different models.
pipeline= Pipeline([
('clf',RandomForestRegressor())
])
parameters={
'clf__n_estimators':([50,100]),
'clf__max_depth':([15,25,30]),
'clf__min_samples_split':([15,100]),
'clf__min_samples_leaf':([2,10])
}
grid_search = GridSearchCV(pipeline,parameters,n_jobs=15,verbose=1,scoring="r2")
grid_search.fit(X,Y)Plotting Curve
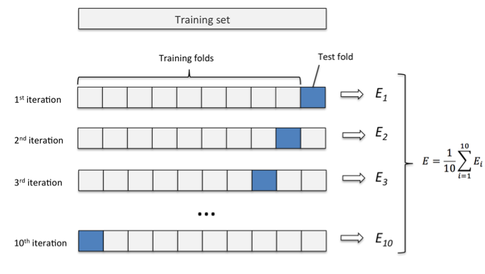
Helps in visualising the progress of an estimator and how well it's learning.
-
Underfitting – Validation and training error high -
Overfitting – Validation error is high, training error low -
Good fit – Validation error low, slightly higher than the training error
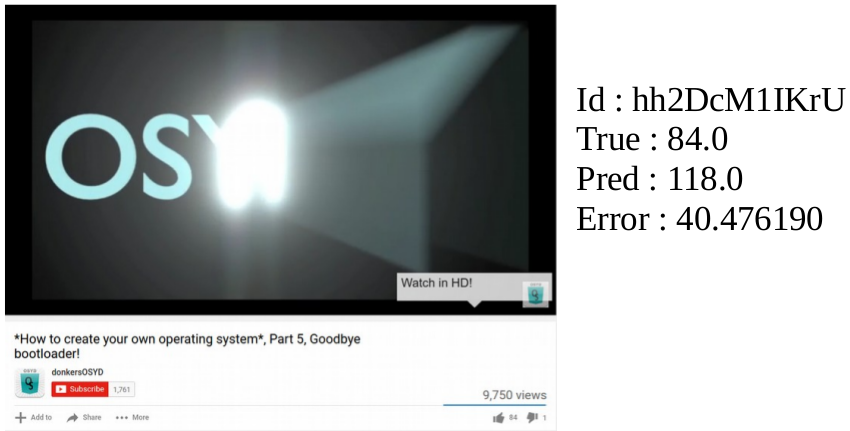
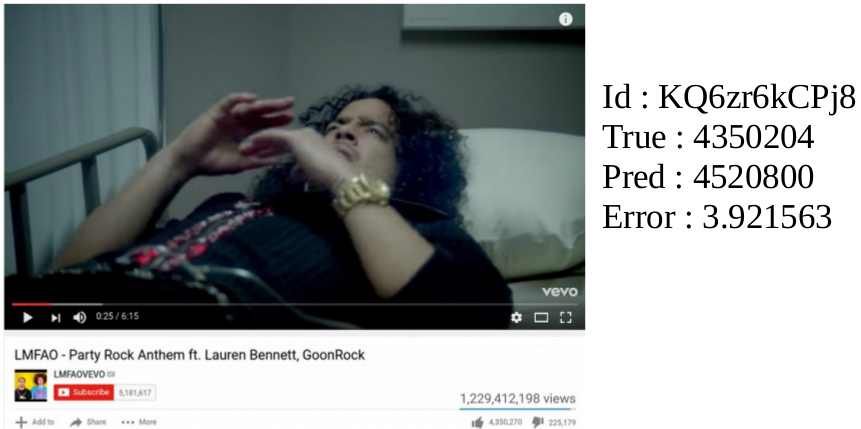
Final Results
Evaluation metric : R^2 score
Cross-Validation score : 0.95
Training Score : 0.96
Testing Score : 0.90

Questions?
https://github.com/ayush1997/YouTube-Like-predictor

ayush0016
ayush1997

ayushsingh97
https://slides.com/ayush1997/ml-3/

ayushkumar97