Representando Palavras & Embeddings
Tokenização
Tokenizar um texto é quebrar ele em elementos menores, em tokens com os quais podemos trabalhar e atribuir significado.
from tensorflow.keras import layers
layers.experimental.preprocessing.TextVectorization(
max_tokens=None,
standardize=LOWER_AND_STRIP_PUNCTUATION,
split=SPLIT_ON_WHITESPACE,
ngrams=None,
output_mode="int",
output_sequence_length=None,
pad_to_max_tokens=True,
**kwargs
)
-
Redes Neurais não entendem letras, apenas números
-
ASCII e UTF-8 não carregam nenhum significado sobre palavras, frases ou contexto.
-
Como podemos representar texto de uma maneira que carregue informação?
"Eu gosto de batata doce."
One Hot Encoding
Eu gosto de batata.
Cada palavra/token é representada por um vetor de dimensão igual ao vocabulário.
Eu
[1,0,0,0]
gosto
[0,1,0,0]
de
[0,0,1,0]
batata
[0,0,0,1]
One Hot Encoding
from tensorflow.keras import layers
layers.experimental.preprocessing.TextVectorization(
max_tokens=None,
standardize=LOWER_AND_STRIP_PUNCTUATION,
split=SPLIT_ON_WHITESPACE,
ngrams=None,
output_mode="int",
output_sequence_length=None,
pad_to_max_tokens=True,
**kwargs
)
Bag of Words
Eu gosto de batata.
Eu gosto de estudar.
Vocabulario: [“Eu”, “gosto”, “de”, “batata”, “estudar”]
[1,1,1,1,0]
[1,1,1,0,1]
Batata gosto de eu.
Não leva em conta ordem, só uma sacola de palavras soltas:
[1,1,1,1,0]
Bag of Words
from tensorflow.keras import layers
layers.experimental.preprocessing.TextVectorization(
max_tokens=None,
standardize=LOWER_AND_STRIP_PUNCTUATION,
split=SPLIT_ON_WHITESPACE,
ngrams=None,
output_mode="binary",
output_sequence_length=None,
pad_to_max_tokens=True,
**kwargs
)
Podemos usar essa abordagem para anotar frequências e não só presença de tokens.
Vocabulario: [“Eu”, “gosto”, “de”, “batata”, “e”, “estudar”, “bicicleta”, “morango”]
Eu gosto de batata e gosto de estudar
[1,2,2,1,1,1,0,0]
from tensorflow.keras import layers
layers.experimental.preprocessing.TextVectorization(
max_tokens=None,
standardize=LOWER_AND_STRIP_PUNCTUATION,
split=SPLIT_ON_WHITESPACE,
ngrams=None,
output_mode="count",
output_sequence_length=None,
pad_to_max_tokens=True,
**kwargs
)
n-grams
Eu nasci em São Paulo.
Um token passa a ser um conjunto de n palavras ao invés de apenas uma única palavra.
2-grams: Eu nasci, nasci em, em São, São Paulo.
3-grams: Eu nasci em, nasci em São, em São Paulo
4-grams: Eu nasci em São, nasci em São Paulo
from tensorflow.keras import layers
layers.experimental.preprocessing.TextVectorization(
max_tokens=None,
standardize=LOWER_AND_STRIP_PUNCTUATION,
split=SPLIT_ON_WHITESPACE,
ngrams=None,
output_mode="binary",
output_sequence_length=None,
pad_to_max_tokens=True,
**kwargs
)
n-grams
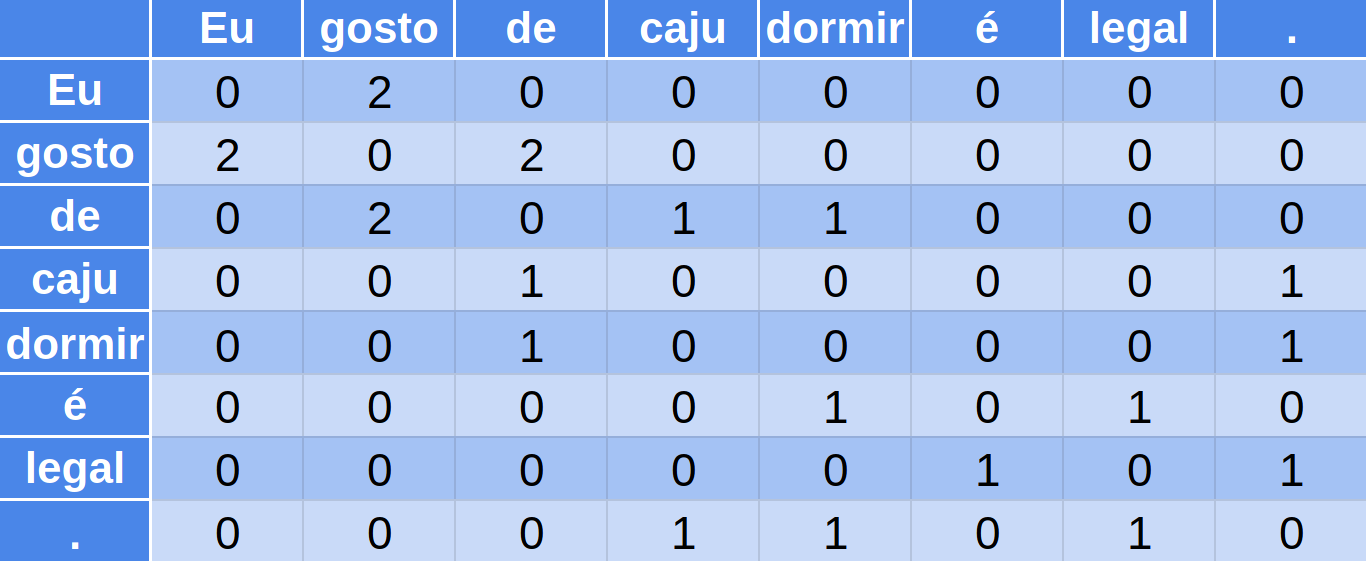
Matriz de Co-ocorrência
-
Eu gosto de caju.
-
Eu gosto de dormir.
-
dormir é legal.
TF-IDF
TF-IDF ou Term Frequency – Inverse Document Frequency é uma medida de relevância de um termo para um dado texto.
Um termo que aparece frequentemente deve ser importante, mas se esse é um termo comum em textos num geral (como preposições e artigos) ele não deverá ser tão importante.
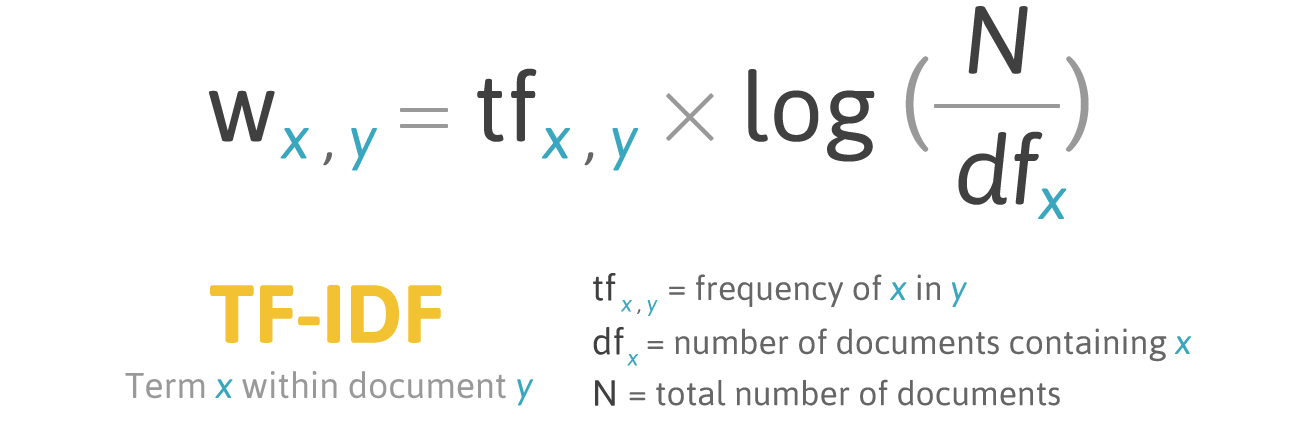

Gato
x4
x1000
10.000.000
Documentos
Documento com
100 palavras
TF-IDF
from tensorflow.keras import layers
layers.experimental.preprocessing.TextVectorization(
max_tokens=None,
standardize=LOWER_AND_STRIP_PUNCTUATION,
split=SPLIT_ON_WHITESPACE,
ngrams=None,
output_mode="tf-idf",
output_sequence_length=None,
pad_to_max_tokens=True,
**kwargs
)
Em todos estes métodos, a representação e uso de memória crescem conforme o tamanho do vocabulário.
Palavras similares possuem representações ortogonais. Não existe noção de similaridade.
Interface Sintaxe-Semântica
Fenômeno: a cada árvore sintática atribui-se um significado (potencialmente) distinto.
Problema:
- Como atribuir significado a uma árvore sintática?
- O que é “significado”?
"Marcelo chegou atrasado"

"Ele nunca chega na hora"
Semanticas Formais
- Representação matemática formal do significado
- Composicionalidade: O significado de um elemento é uma composição dos significados de suas partes
- Gramáticas Categóricas baseadas em Lógicas Categóricas e Cálculo Lambda
- Ponte formal para a interface Sintaxe-Semântica
Semanticas Contextuais
- Expressões com significados semelhantes ocorrem m contextos semelhantes
- O contexto é a semântica, a semântica é um padrão
- Inserção (embedding) em espaços vetoriais n-dimensionais
- Pontos próximos representam conceitos semanticamente semelhantes
- Exploram propriedades dos espaços vetoriais no processamento

Marcelo
Ele
Rocambole
Embeddings
Um embedding, ou uma imersão, é uma representação em \(\mathbb{R}^n\) das palavras.
Cada palavra existe como um ponto em um espaço vetorial de dimensão menor que o tamanho do vocabulário.
Batata
Ônibus
[ 2.34, 4.75, 17.01, -0.223]
[-2.31, 3.34, 1.425, -9.354]
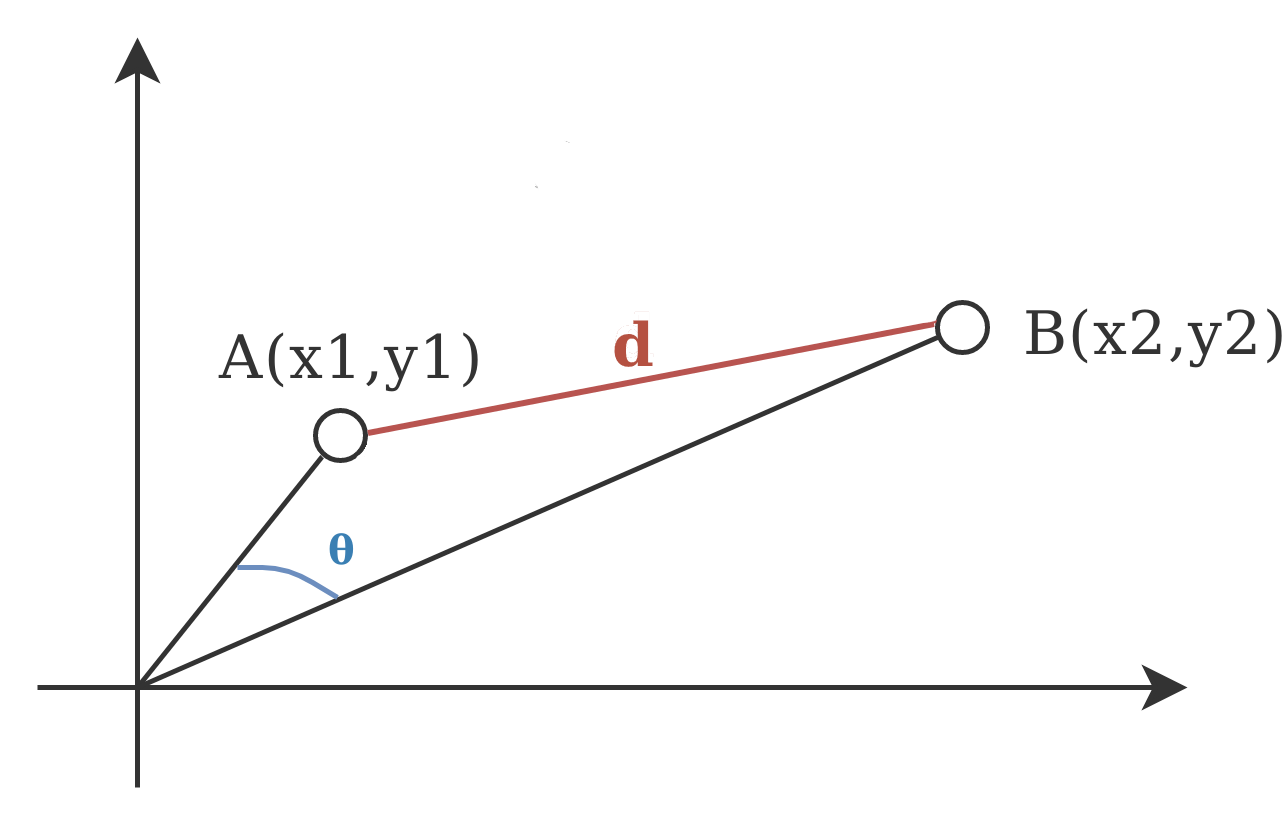
Distancia Euclidiana
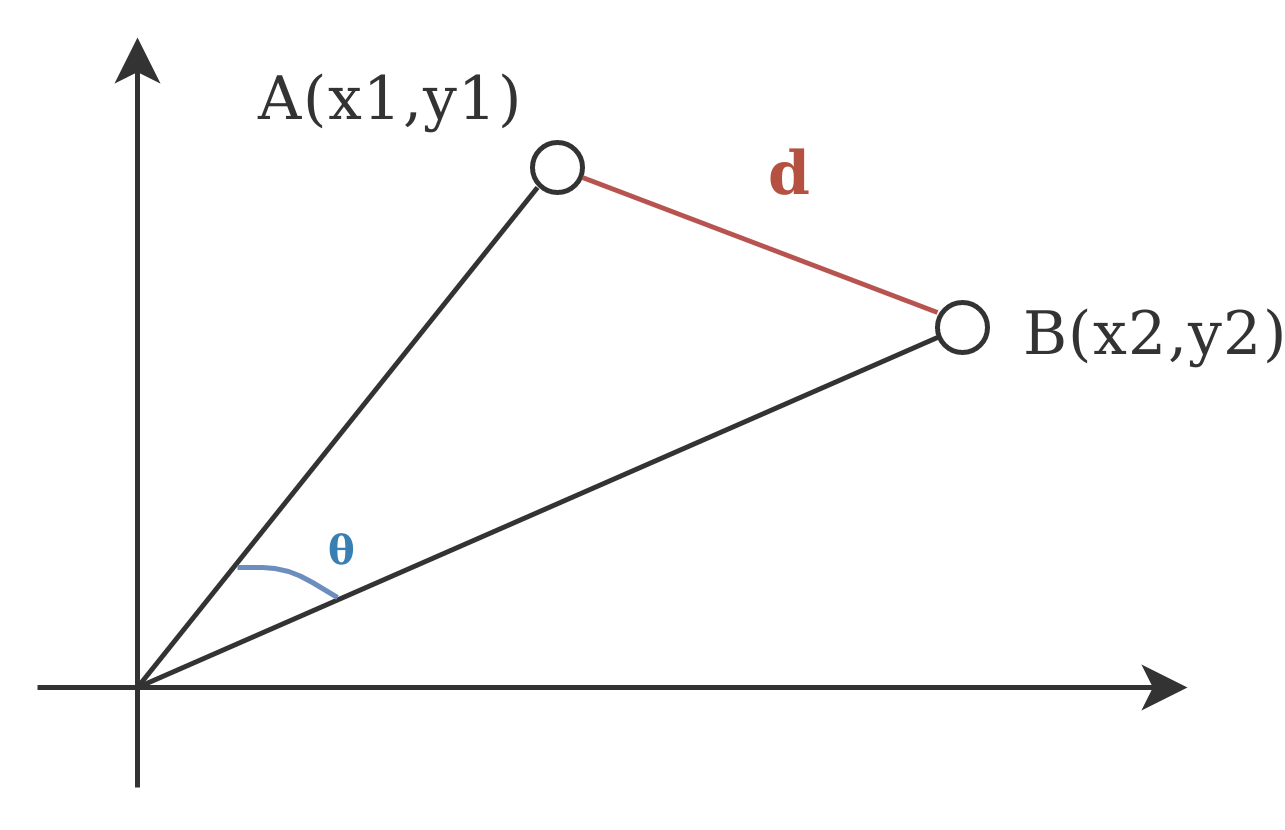
Similaridade Cosseno
Similaridade Cosseno
Similaridade Cosseno é utilizada quando a magnitude do vetor não é relevante ou pode não carregar um significado real.
Embedding LookUp Table
Dimensão de Embedding n
Tamanho do
Vocabulário m
Como gerar um embedding?
Seria interessante termos um embedding que apresente noções de similaridade entre as palavras. Palavras similares estarão próximas nesse espaço.
Podemos tratar a camada de embedding de nossa rede como mais uma camada a ser treinada. A matriz que representa os embeddings será atualizada a cada iteração assim como os outros parâmetros da rede.
tf.keras.layers.Embedding(
input_dim, output_dim, embeddings_initializer='uniform',
embeddings_regularizer=None, activity_regularizer=None,
embeddings_constraint=None, mask_zero=False, input_length=None, **kwargs
)
Padding
Redes Neurais necessitam de inputs de tamanho constante. Se cada frase é um input, como garantimos isso?
Eu fui no parque e comprei um sorvete
Eu tirei um cochilo <PAD><PAD><PAD><PAD>
Mesmo
comprimento
Uma solução é definir um token especial <PAD> que serve para deixar sentenças de comprimento diferente com um mesmo tamanho:
Padding
from tensorflow.keras import layers
layers.experimental.preprocessing.TextVectorization(
max_tokens=None,
standardize=LOWER_AND_STRIP_PUNCTUATION,
split=SPLIT_ON_WHITESPACE,
ngrams=None,
output_mode="int",
output_sequence_length=None,
pad_to_max_tokens=True,
**kwargs
)
OOV - Out of Value
Como lidar com palavras fora do vocabulário?
<OOV> Serve como um token especial para onde todas as palavras encontradas que não pertencem ao nosso vocabulário são mapeadas.
É possivel definir multiplos buckets OOV para que os outliers não sejam todos mapeados para o mesmo token.